Download to read offline

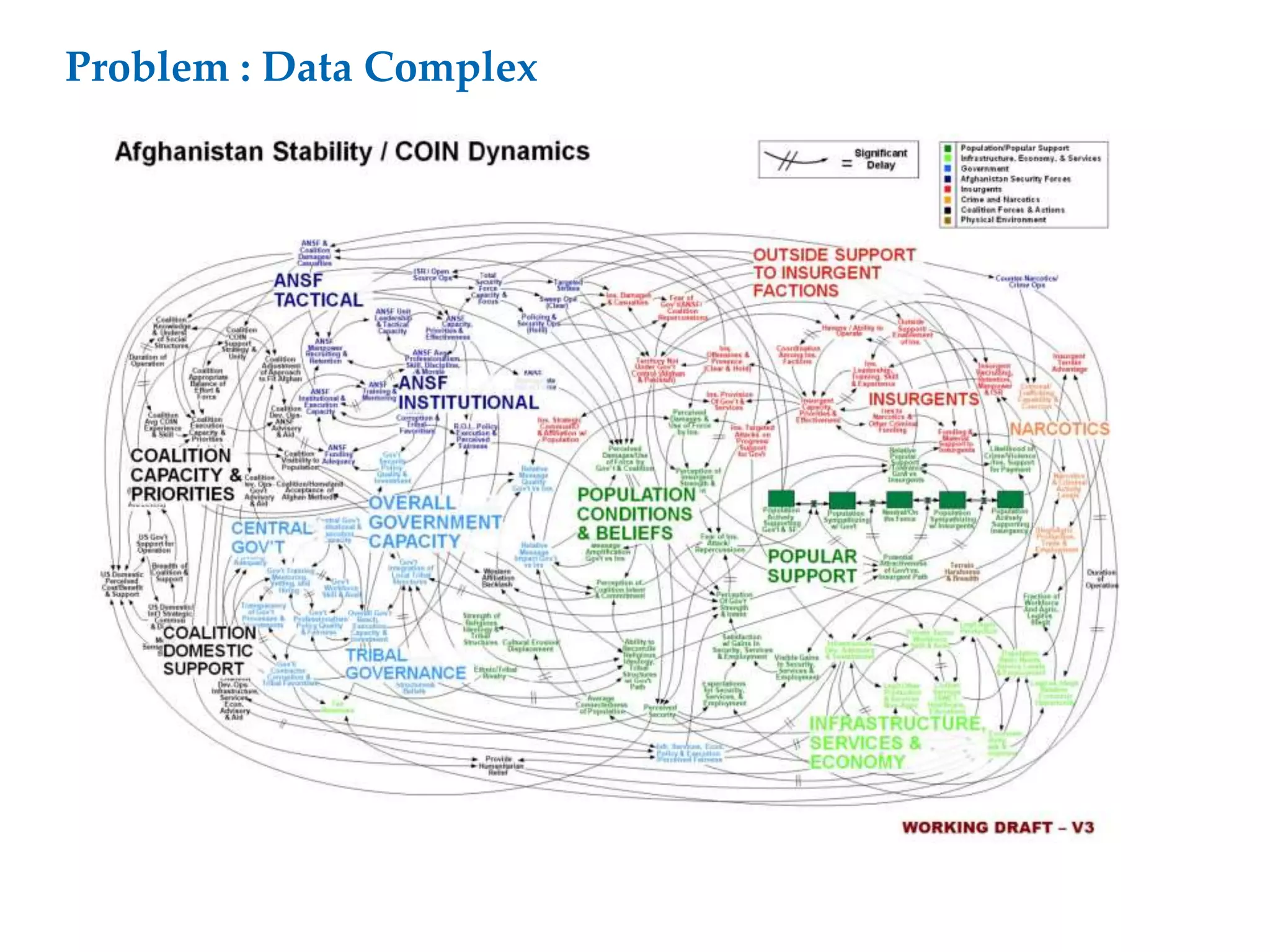

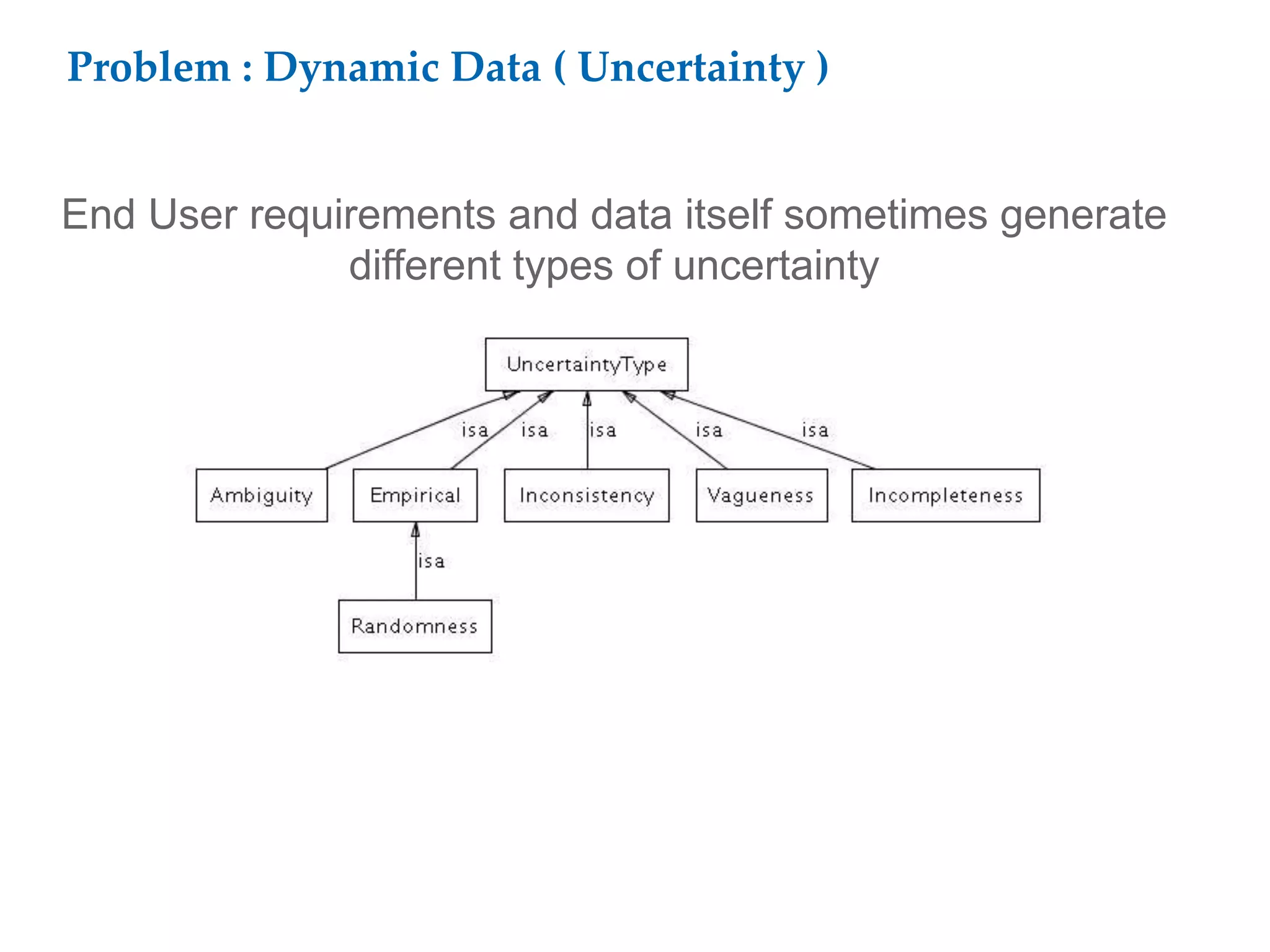










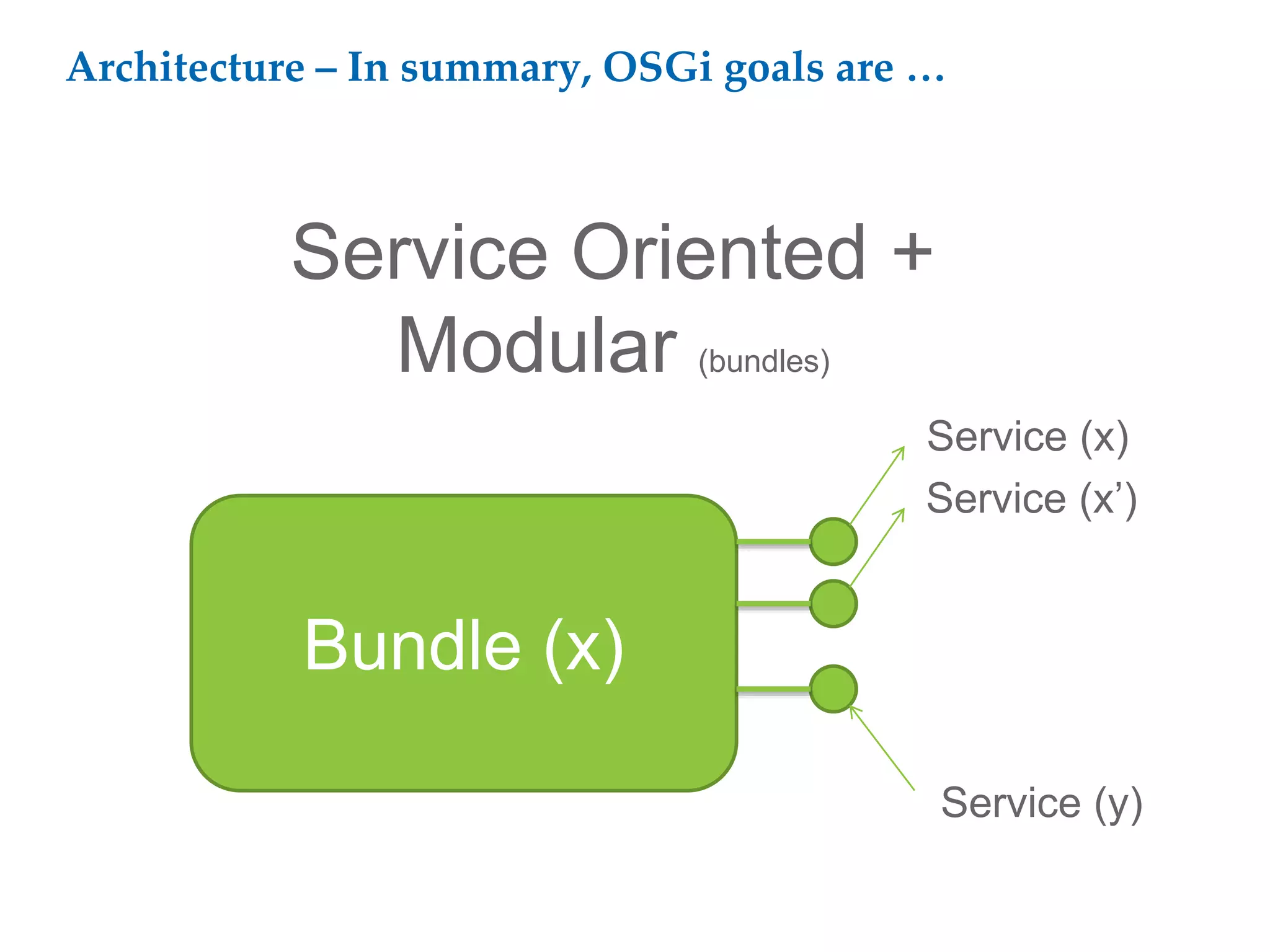
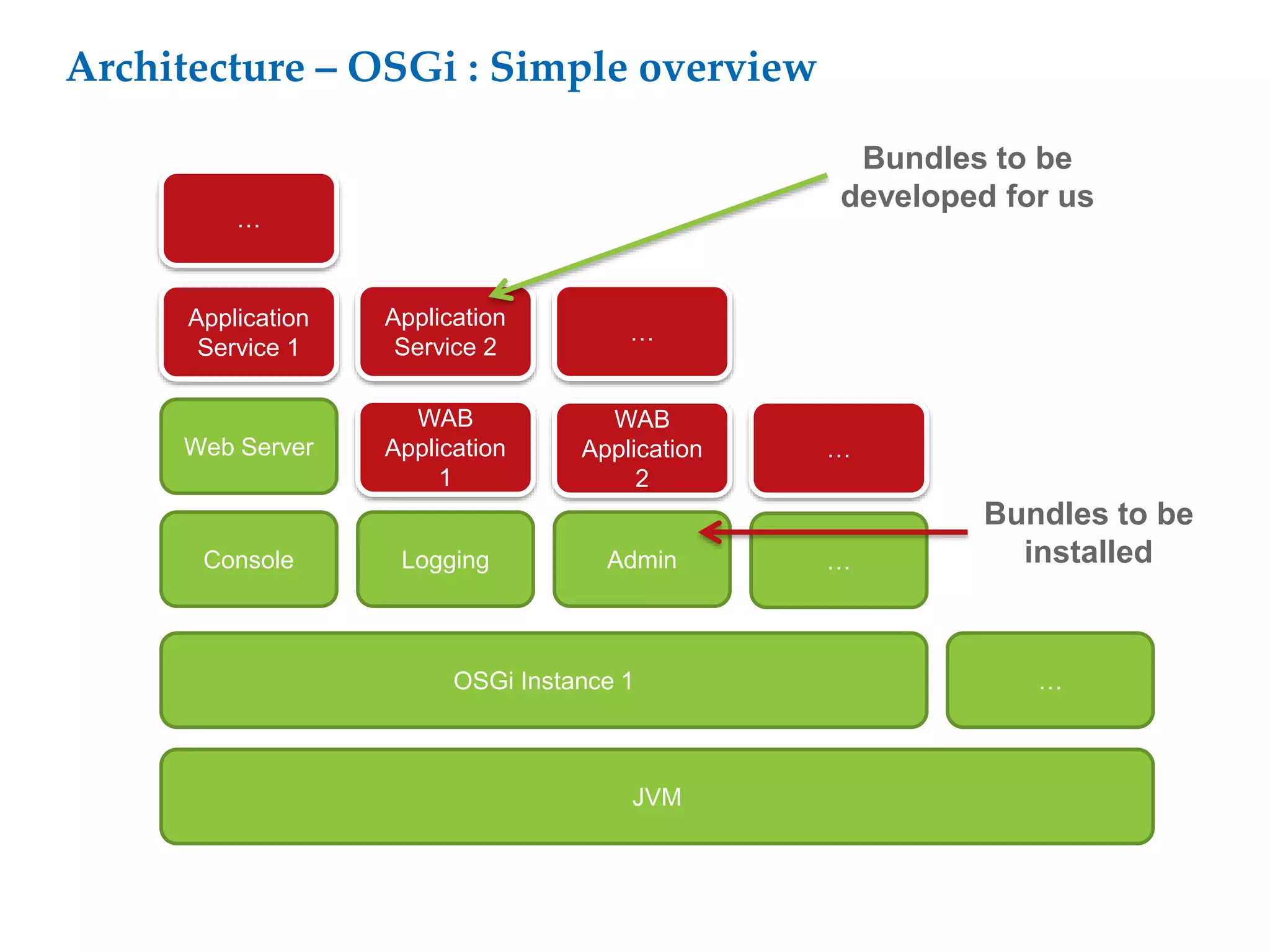



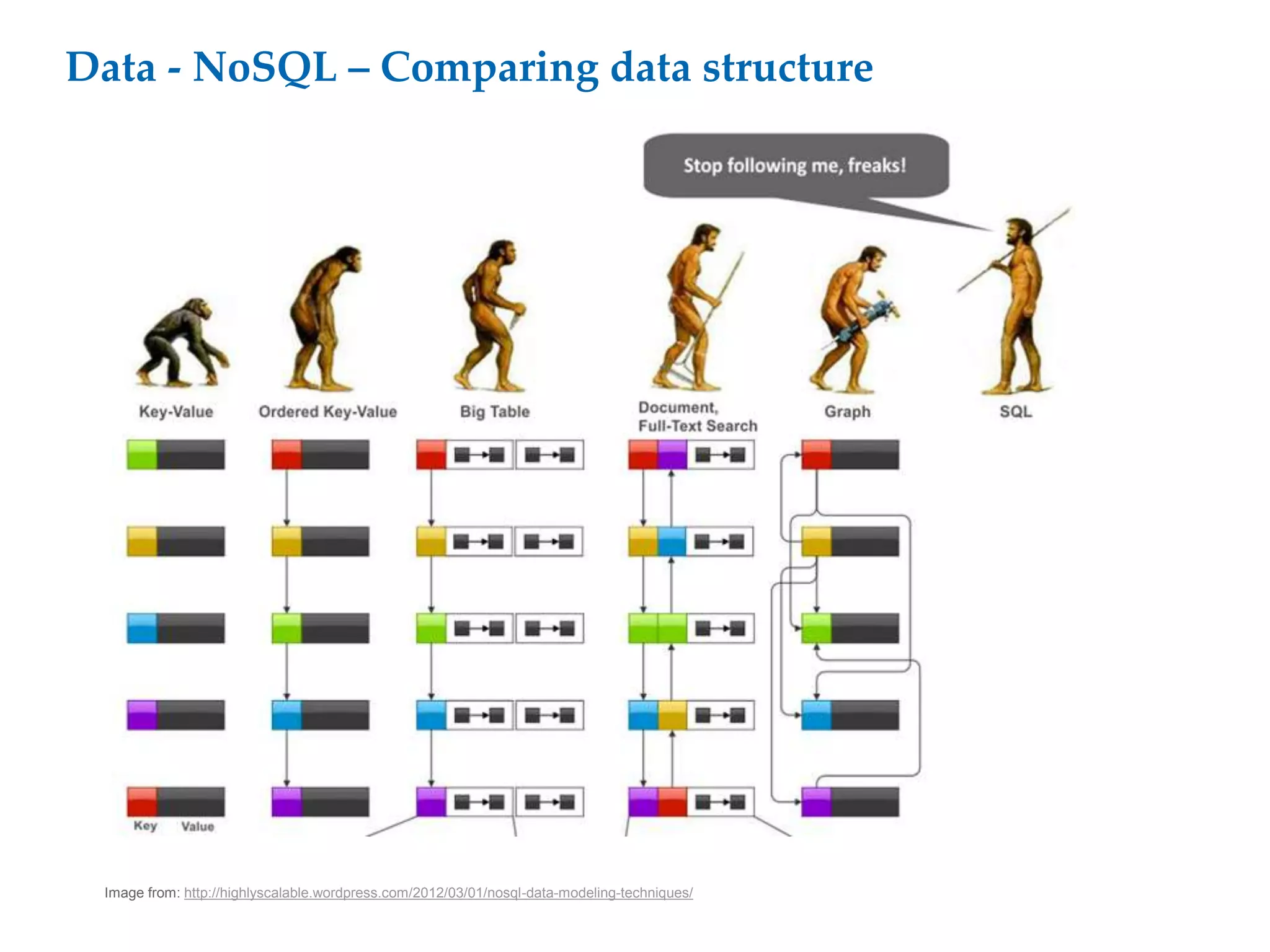
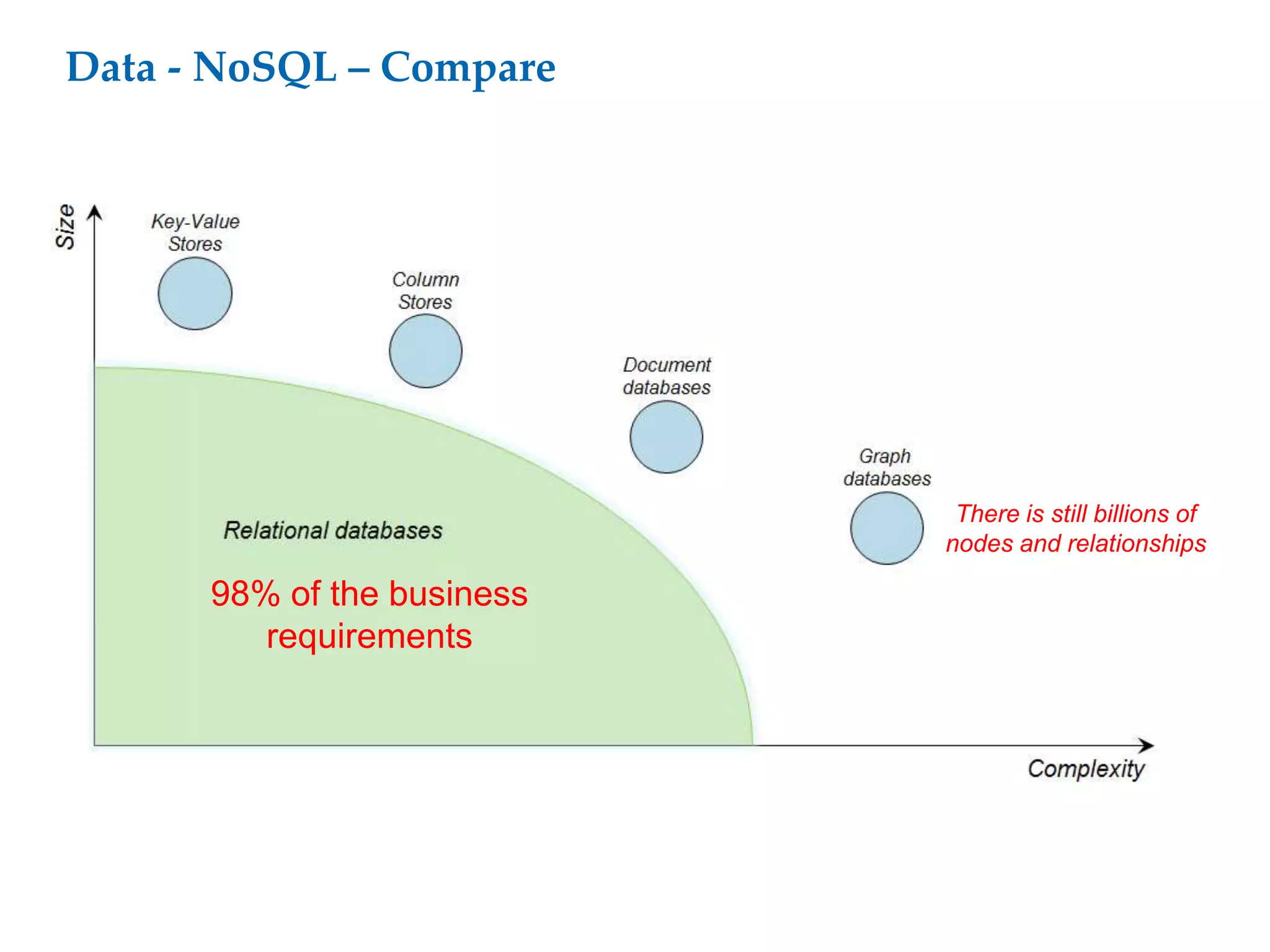

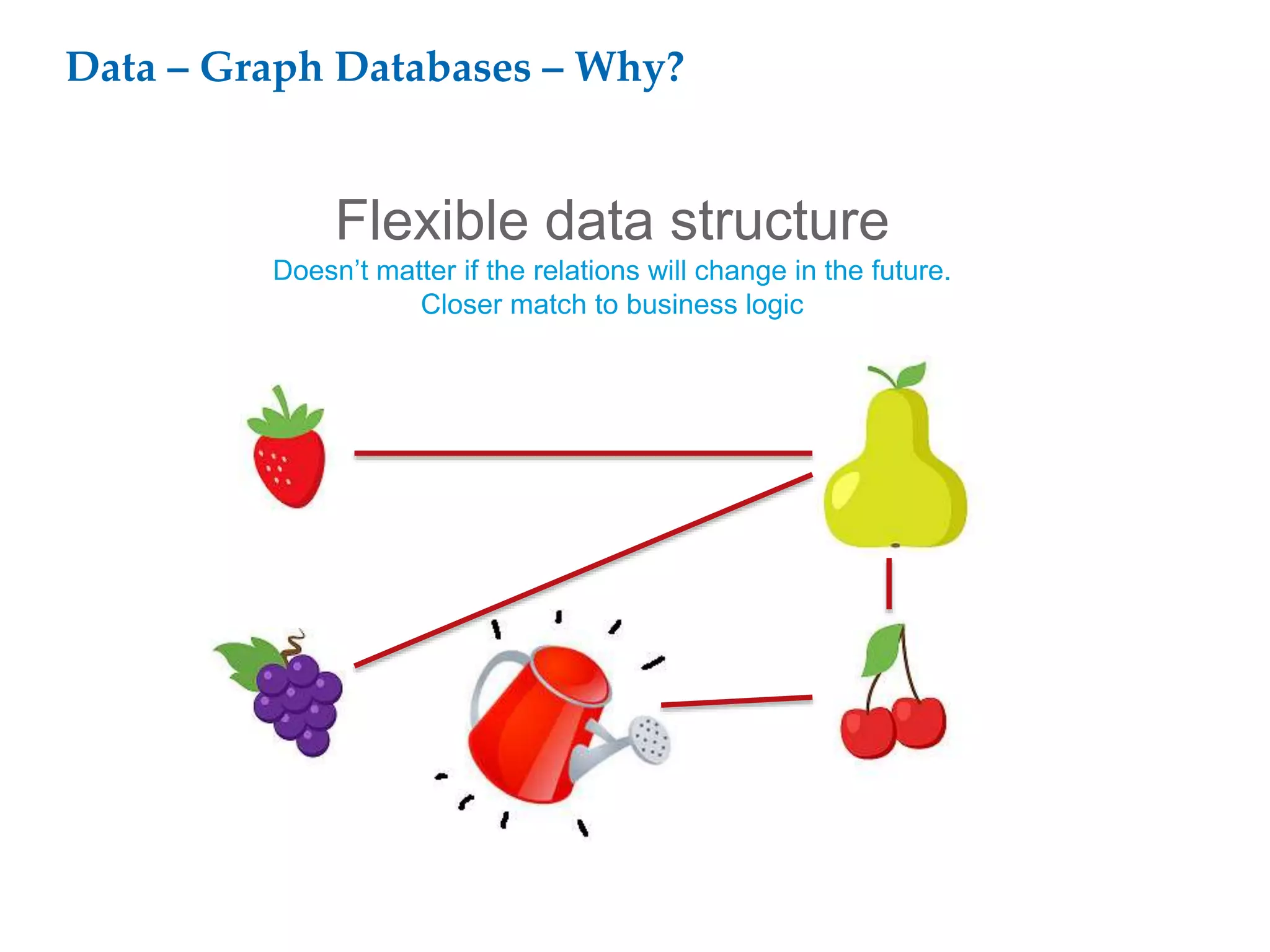



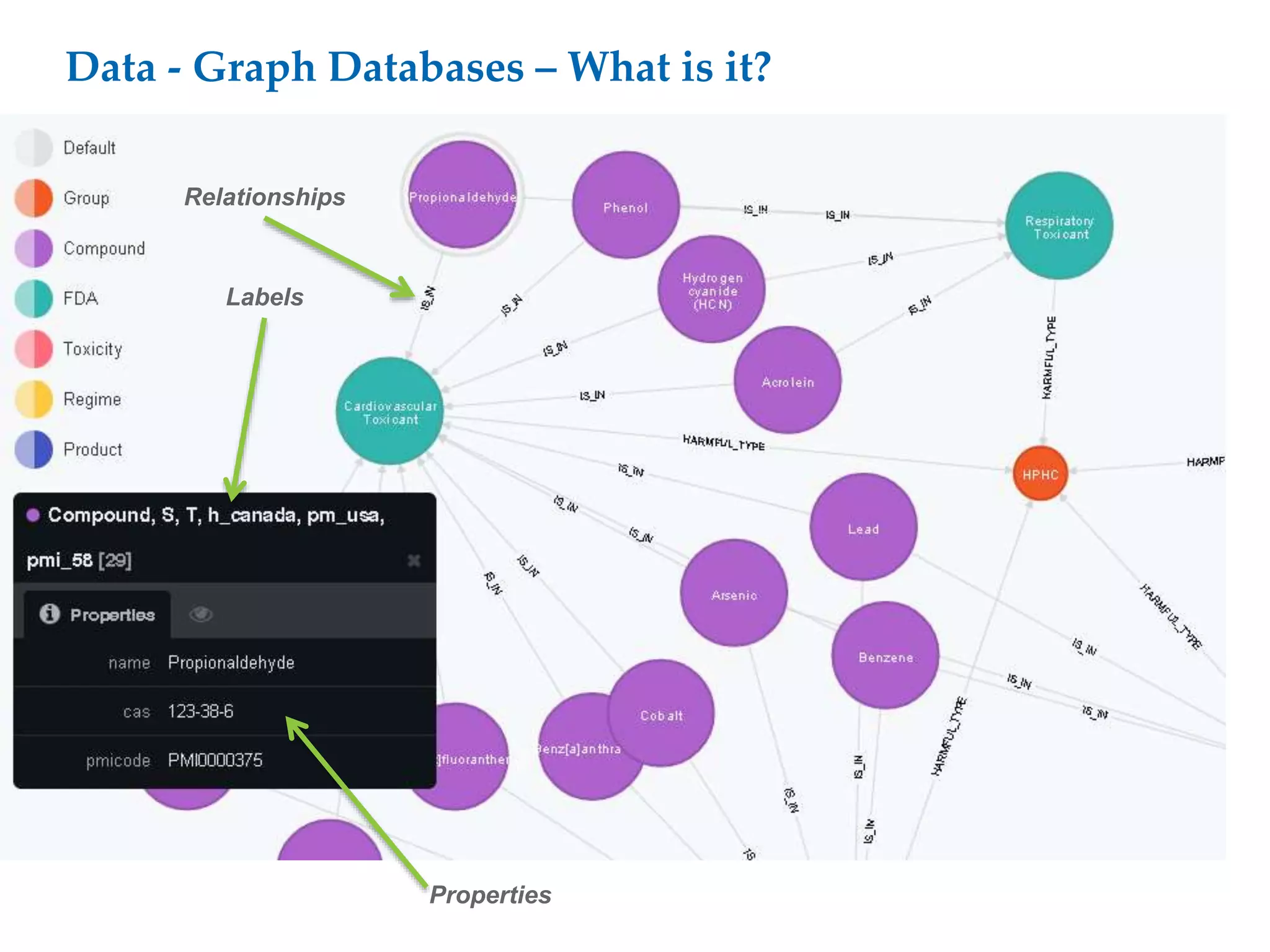

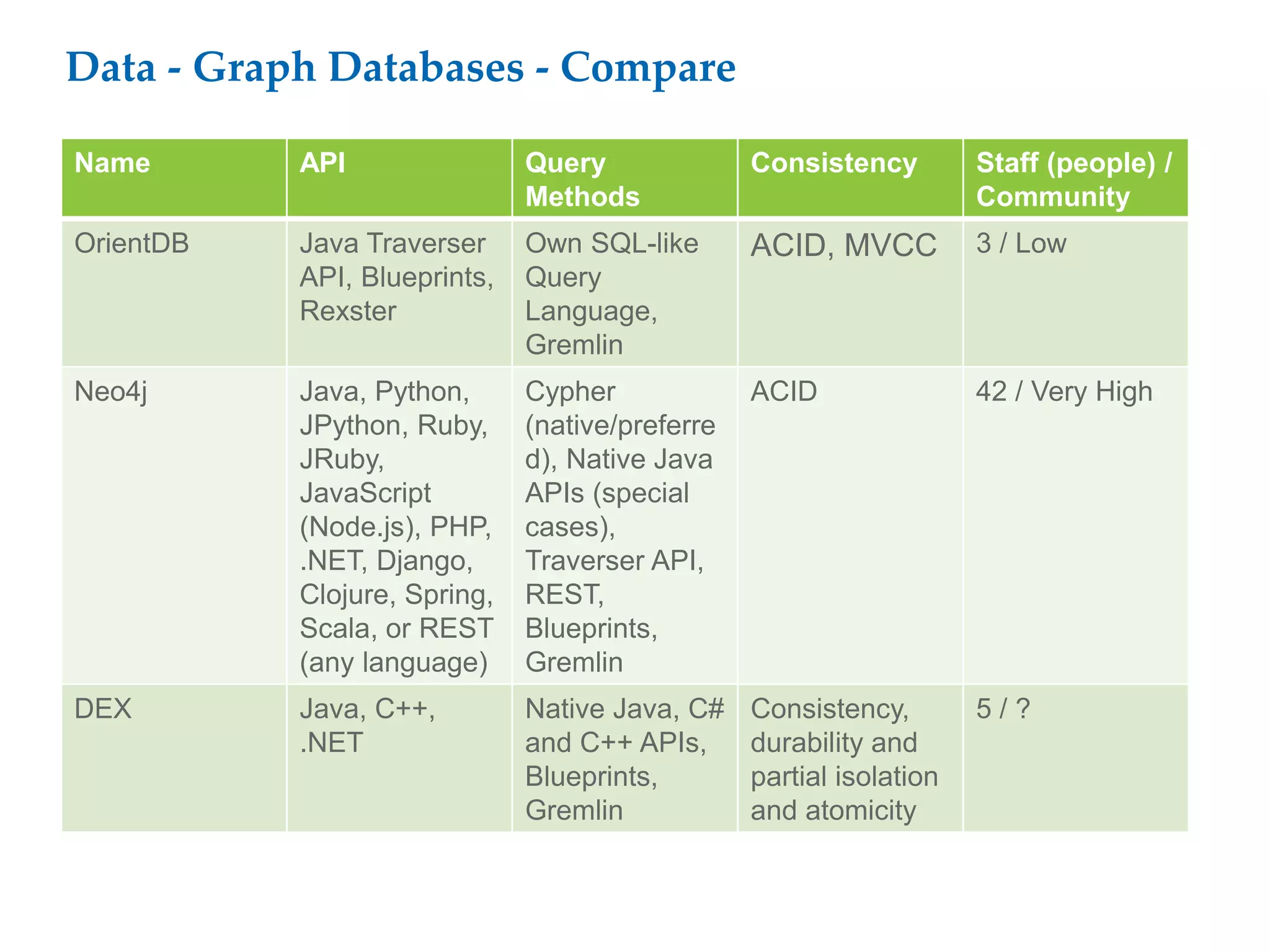
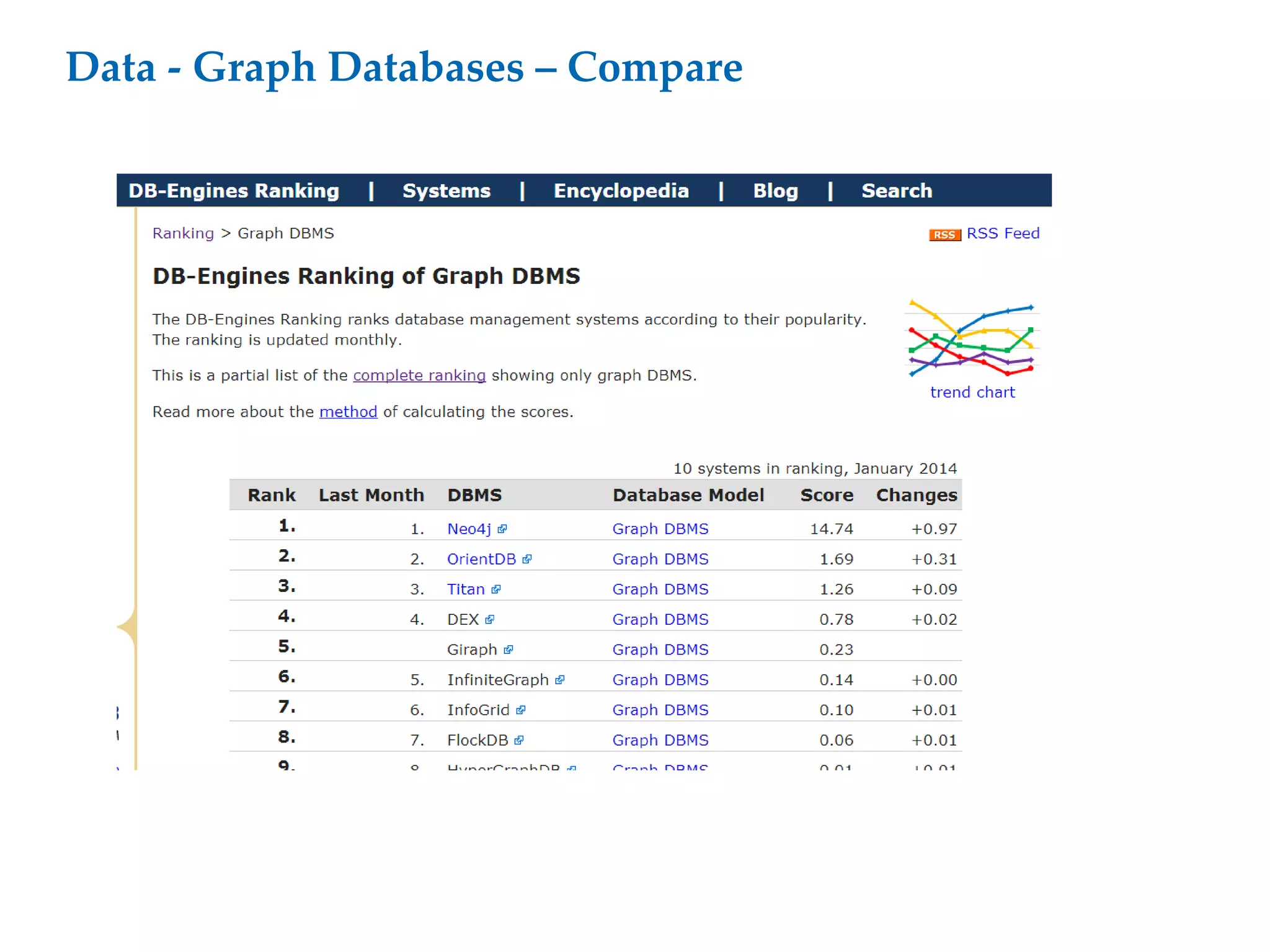





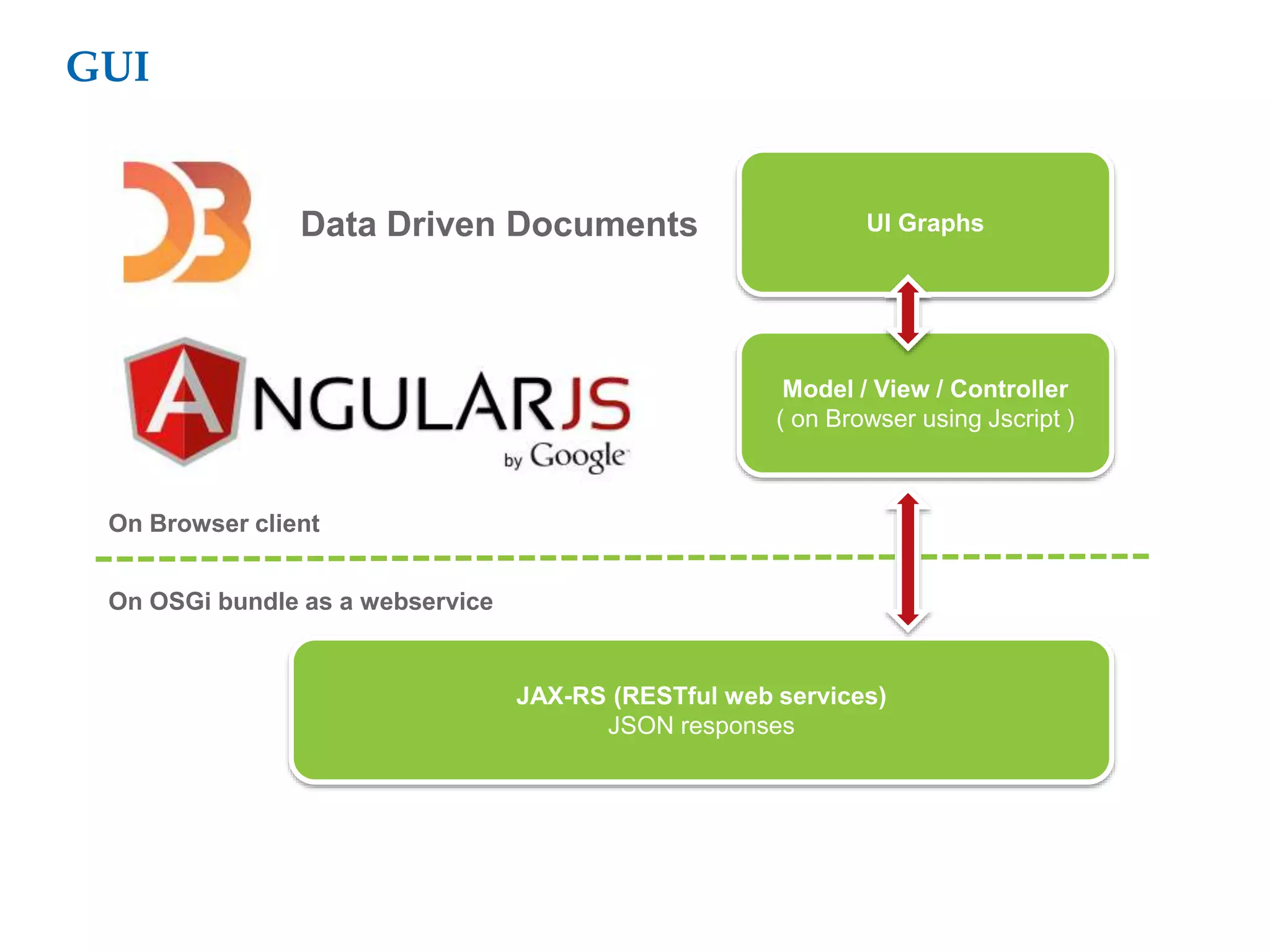



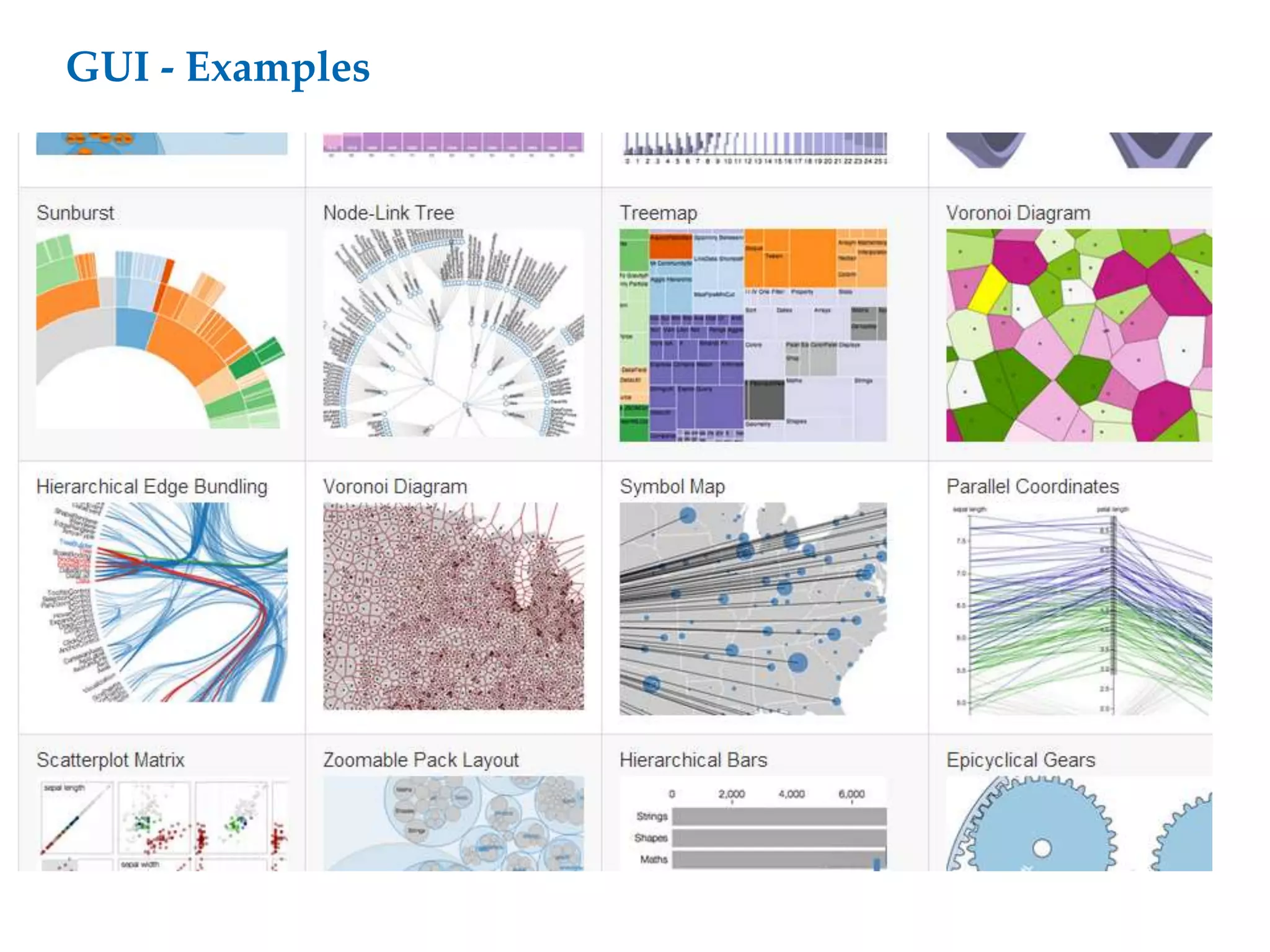


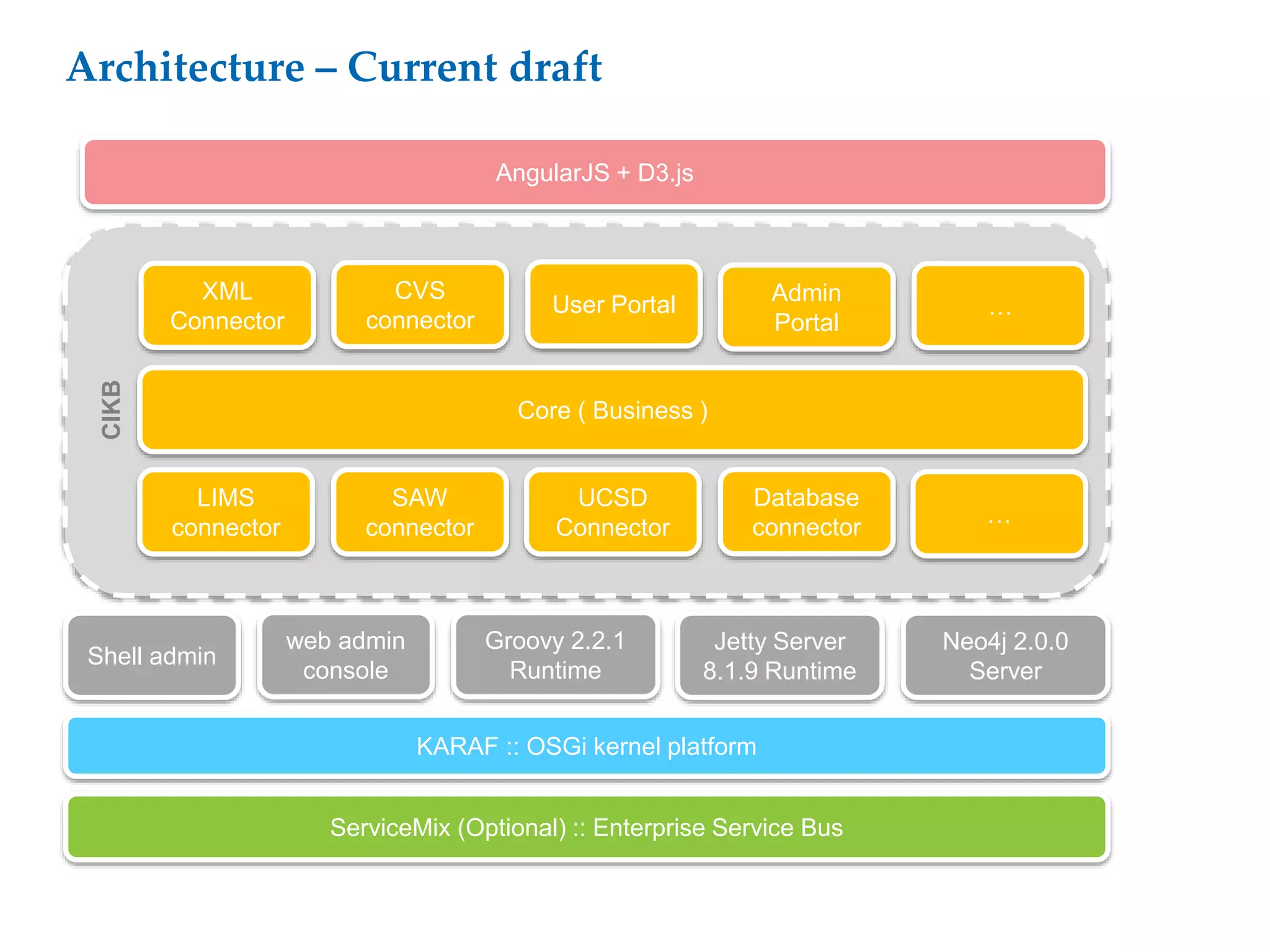

This document proposes a software architecture to address complex and dynamic data modeling challenges. The proposed solution has four main components: [1] An OSGi-based architecture for modularity, reusability and dynamic updates. [2] A graph database (Neo4j) to flexibly store relationships and enable natural queries. [3] A user interface built with AngularJS and D3.js for rich, data-driven visualization. [4] The use of a "mad developer" to implement the architecture. The architecture aims to reduce complexity, support dynamic data and provide a flexible yet user-friendly interface.



























