Downloaded 34 times













![SFrame Python API Example
Make a little SFrame of 1 column and 5 values:
sf = gl.SFrame({‘x’:[1,2,3,4,5]})
Normalizes the column x:
sf[‘x’] = sf[‘x’] / sf[‘x’].sum()
Uses a python lambda to create a new column:
sf[‘x-squared’] = sf[‘x’].apply(lambda x: x*x)
Create a new column using a vectorized operator:
sf[‘x-cubed’] = sf[‘x-squared’] * sf[‘x’]
Create a new SFrame taking only 2 of the columns:
sf2 = sf[[‘x’,’x-squared’]]](https://image.slidesharecdn.com/glconference2014scalabledatayucheng-150429211705-conversion-gate01/85/GraphLab-Conference-2014-Yucheng-Low-Scalable-Data-Structures-SFrame-SGraph-17-320.jpg)

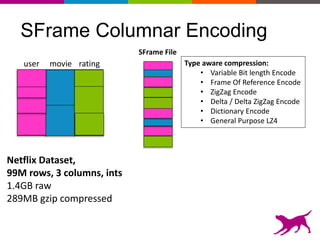
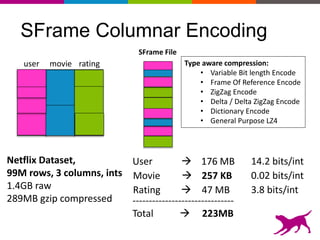
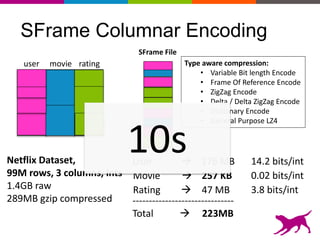




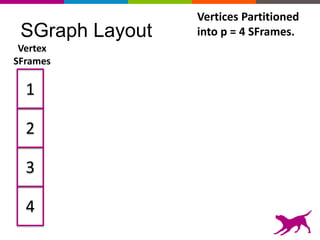


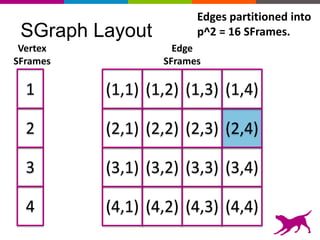
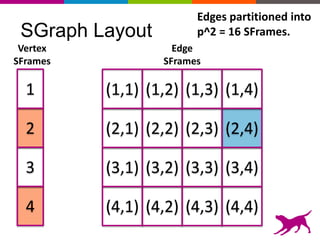
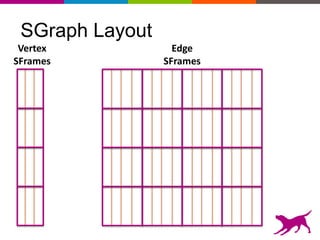
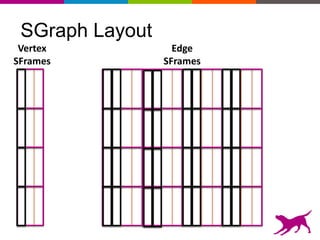
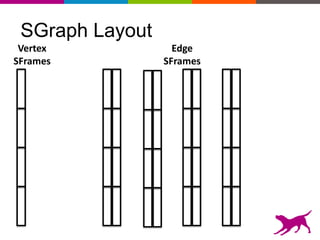
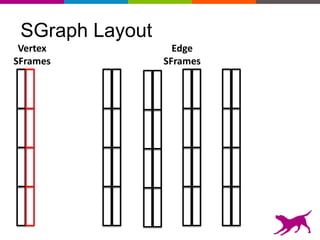



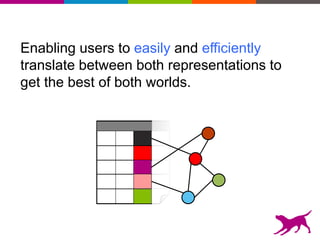
GraphLab Create uses a user-first architecture that optimizes for user interaction. It features SFrame for scalable tabular data manipulation and SGraph for scalable graph manipulation. These are built by data scientists for data scientists to easily translate between tabular and graph representations. SFrame uses a columnar format for efficient feature engineering and vectorized operations on large datasets.























































































