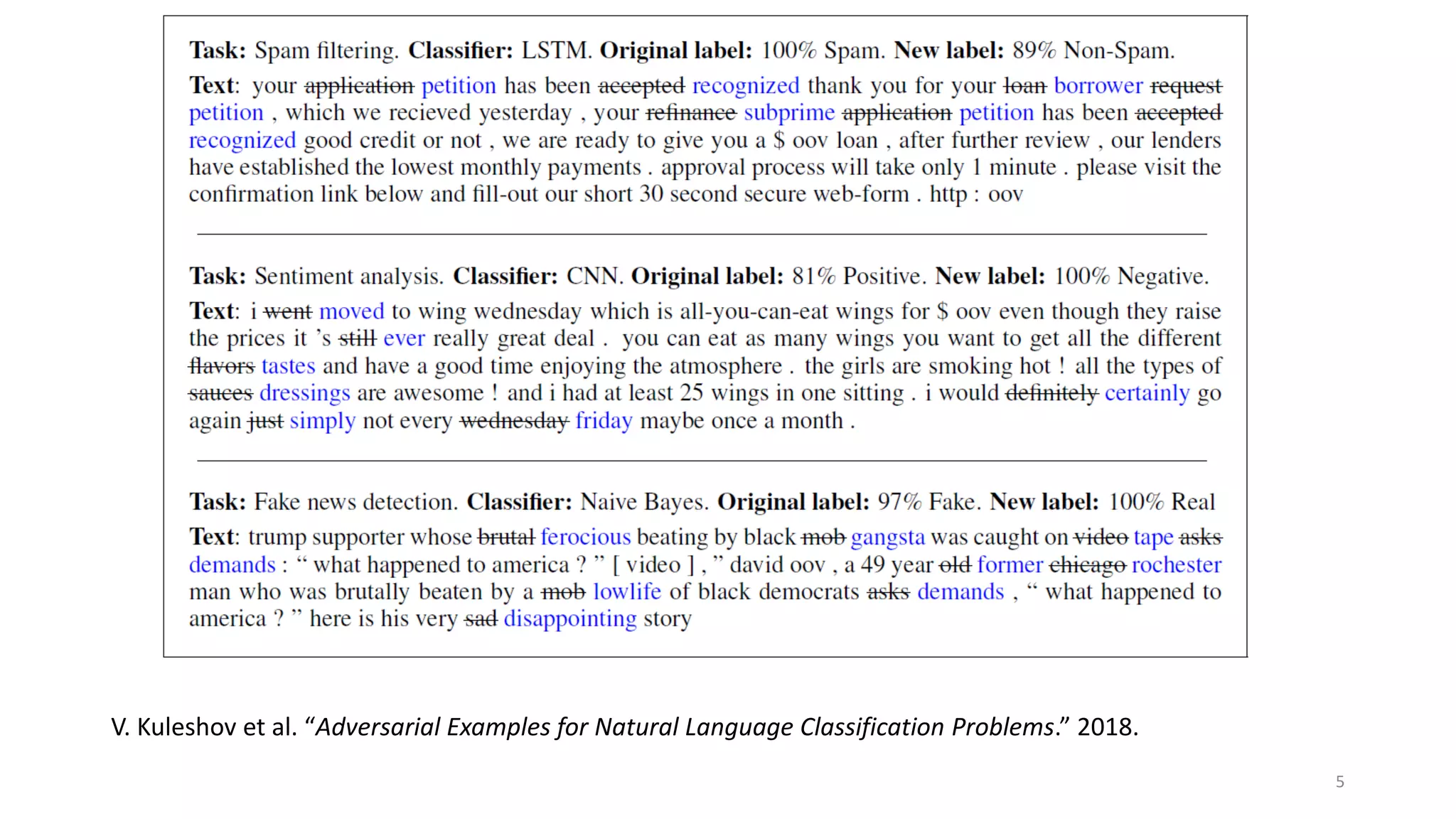
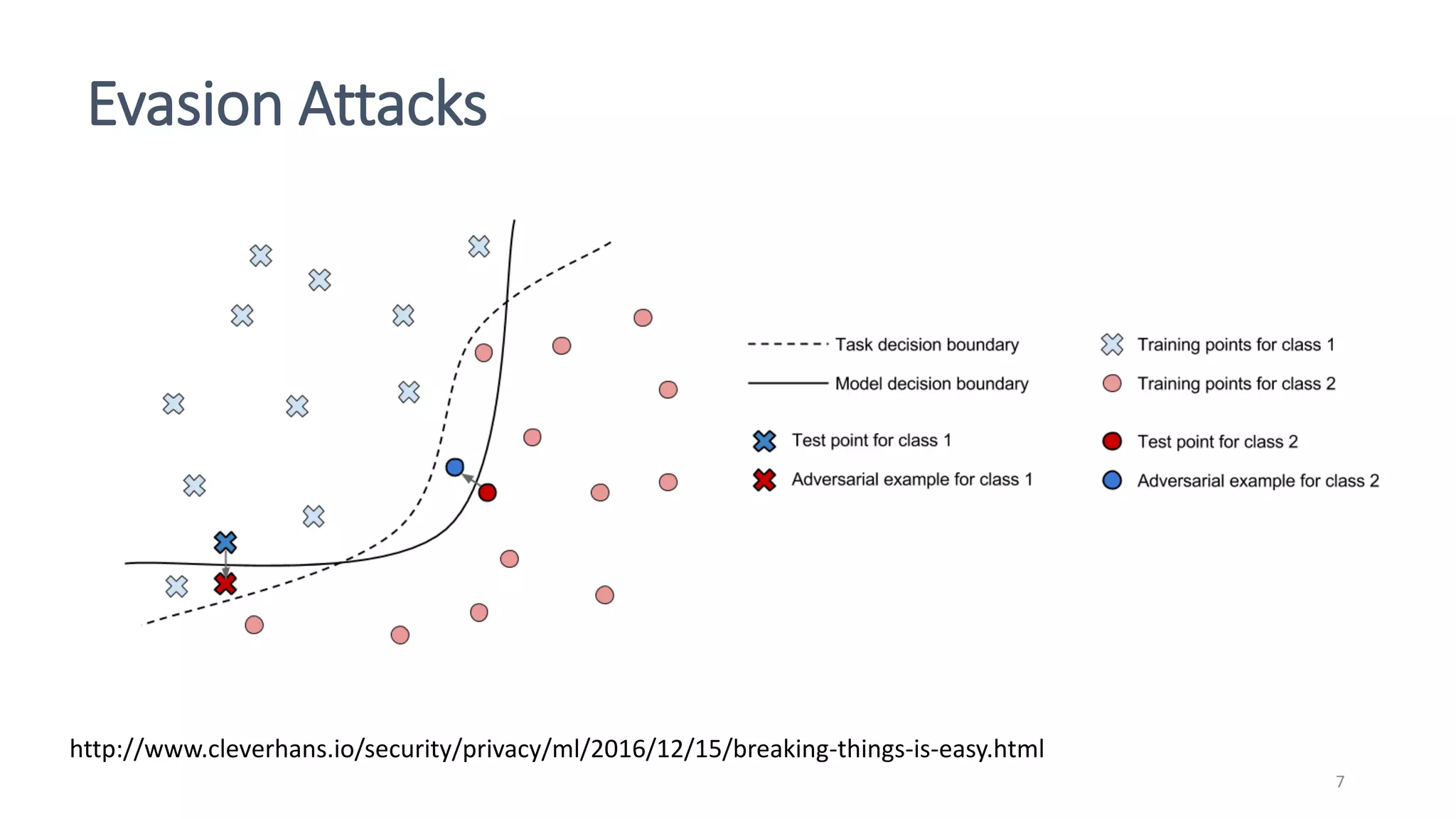
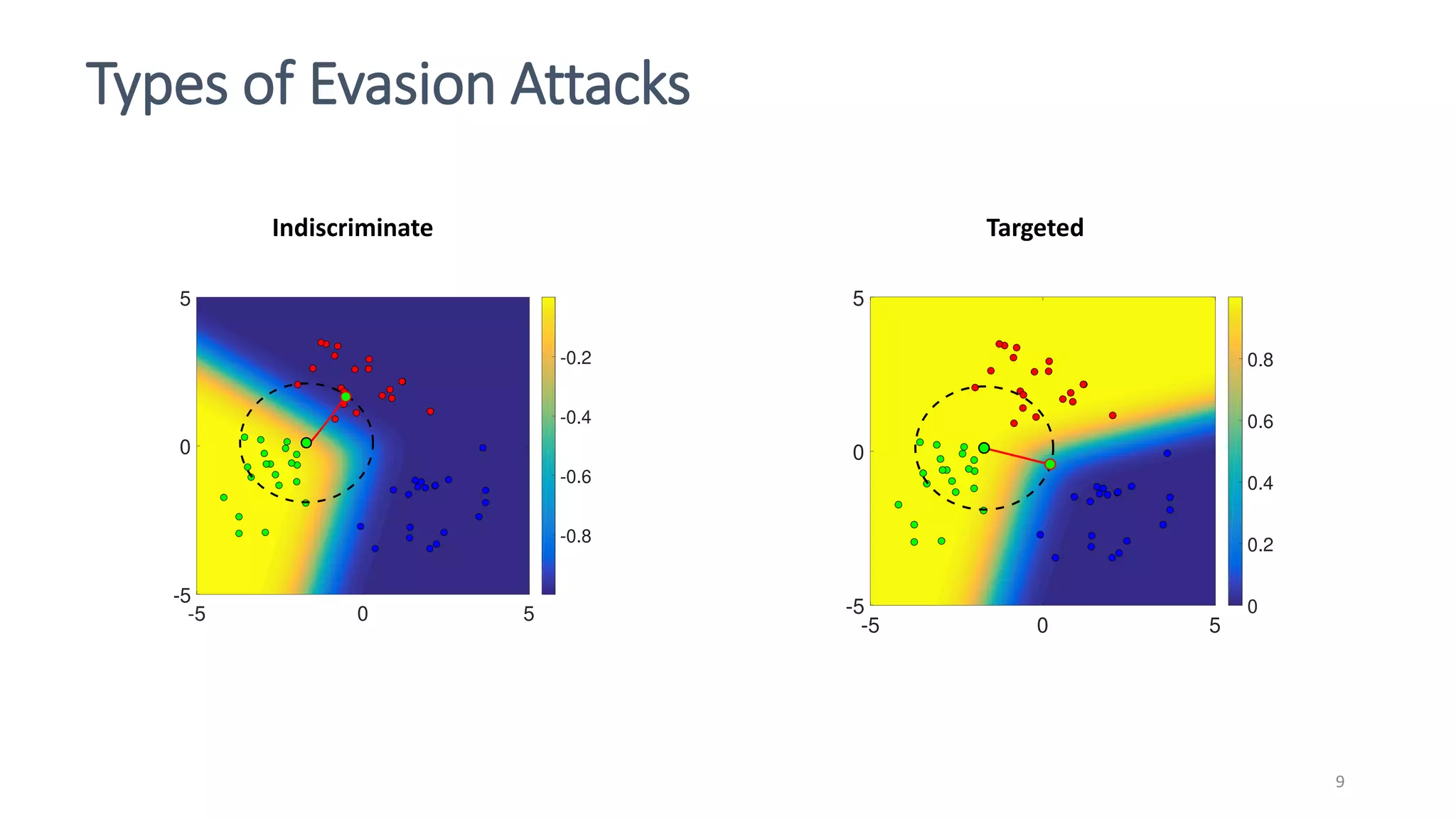
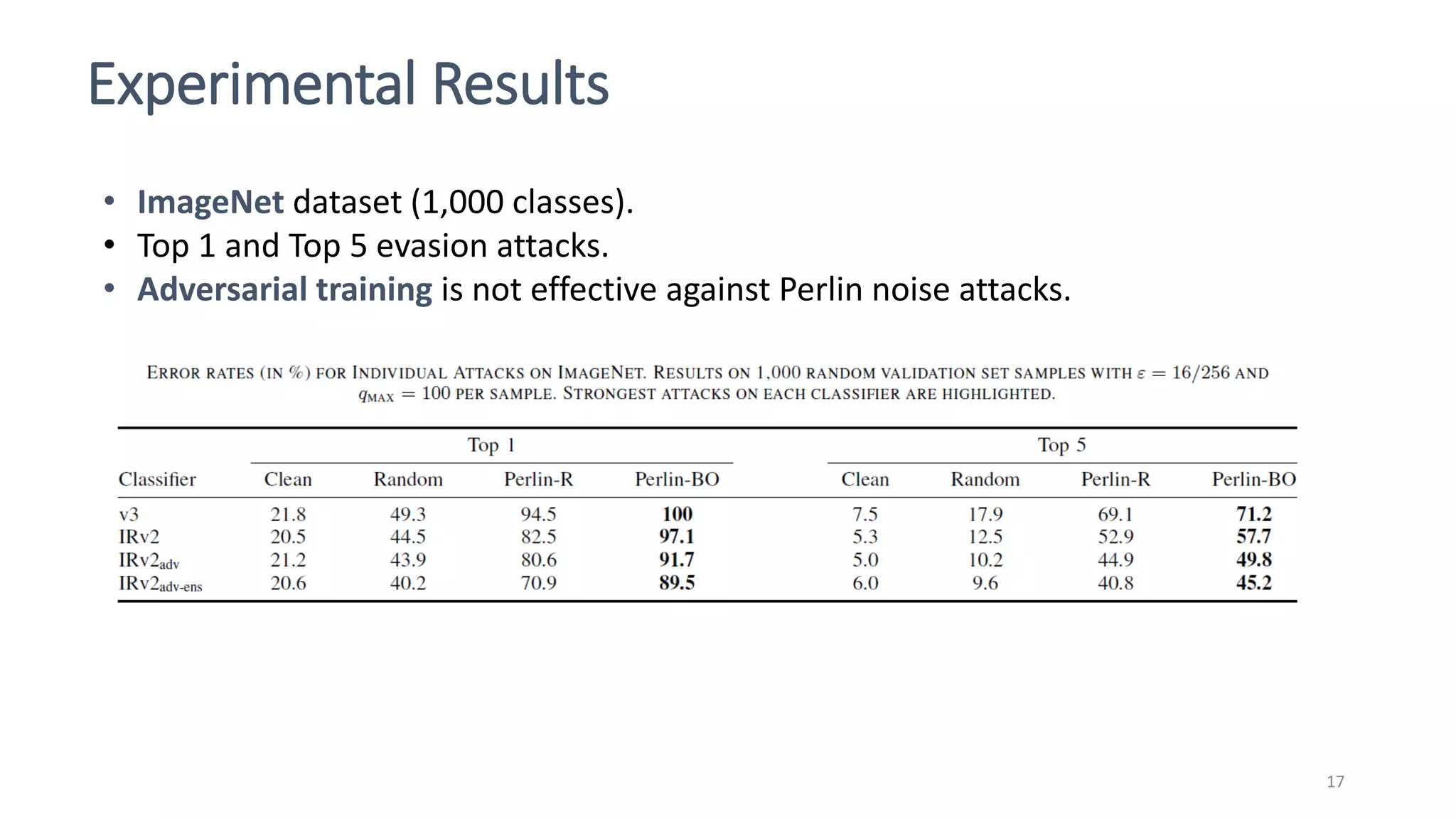
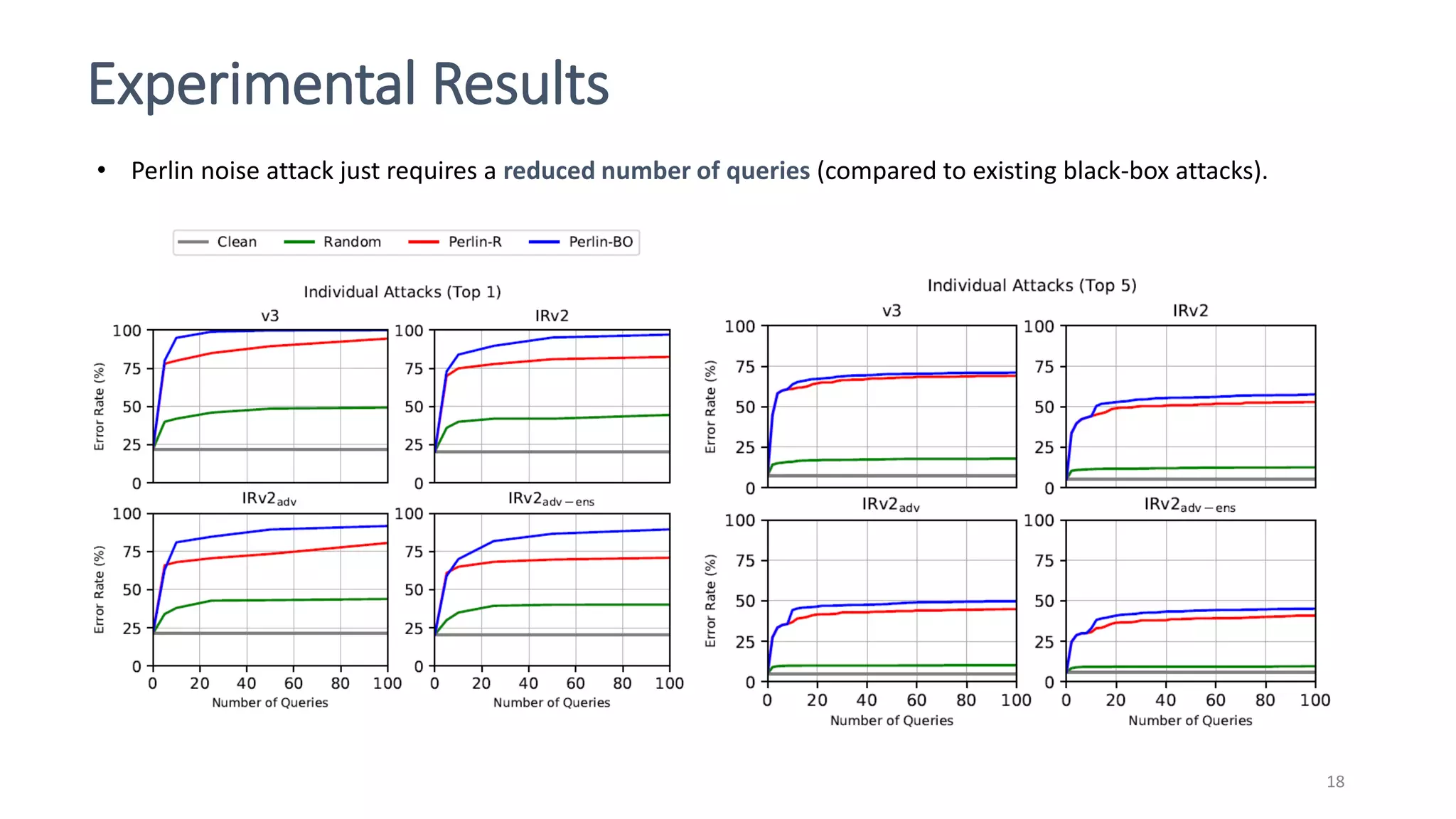
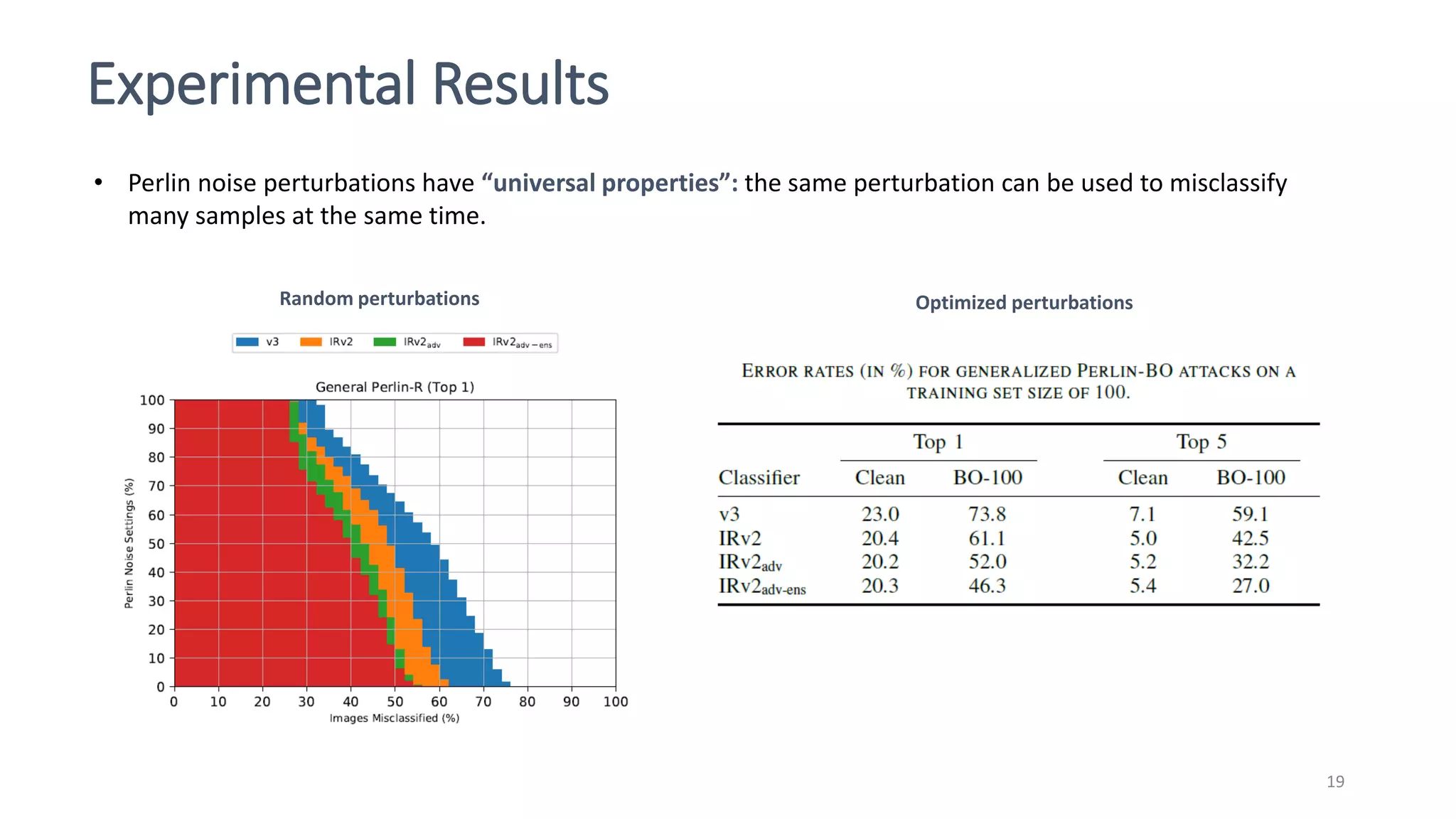
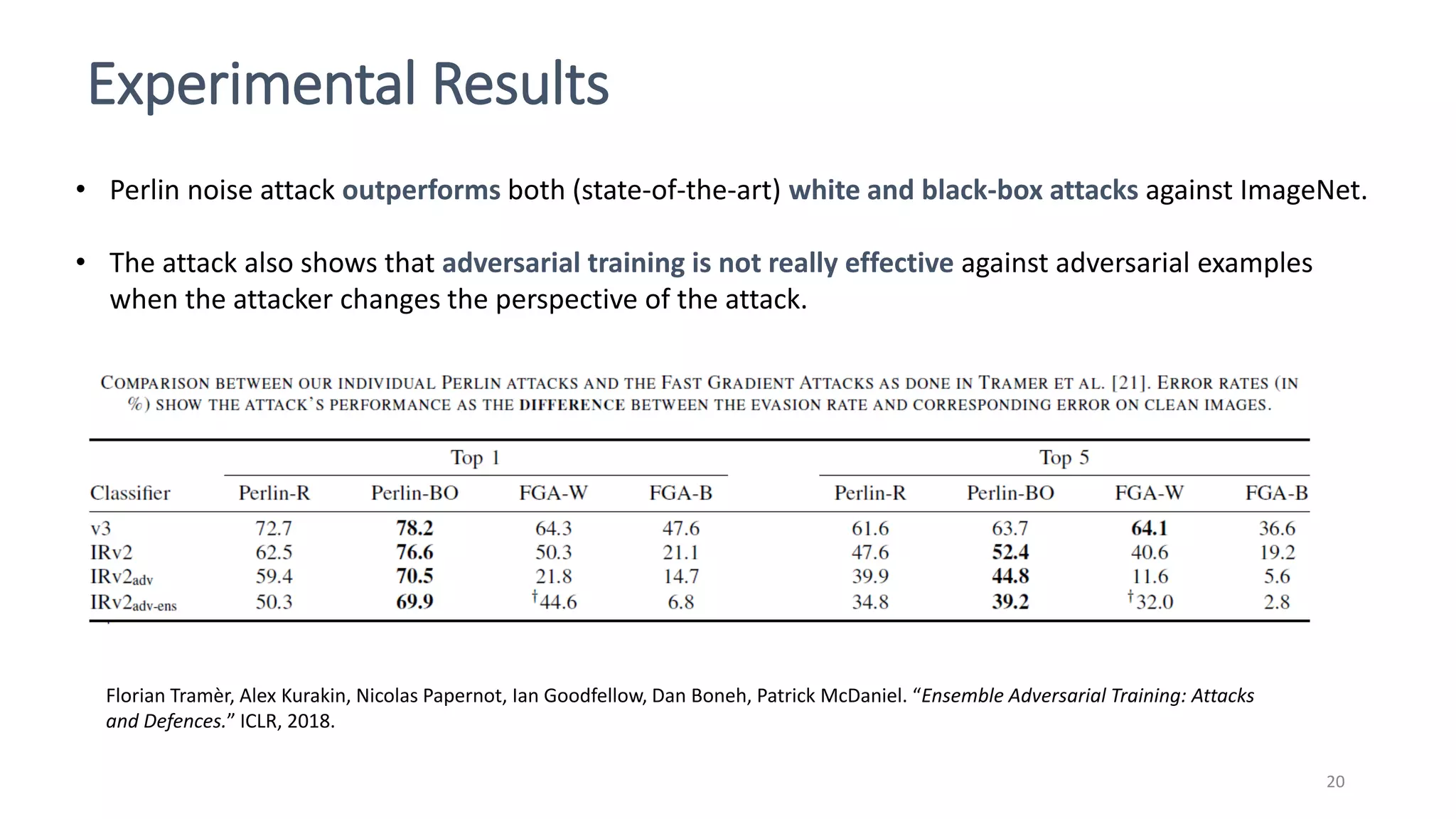
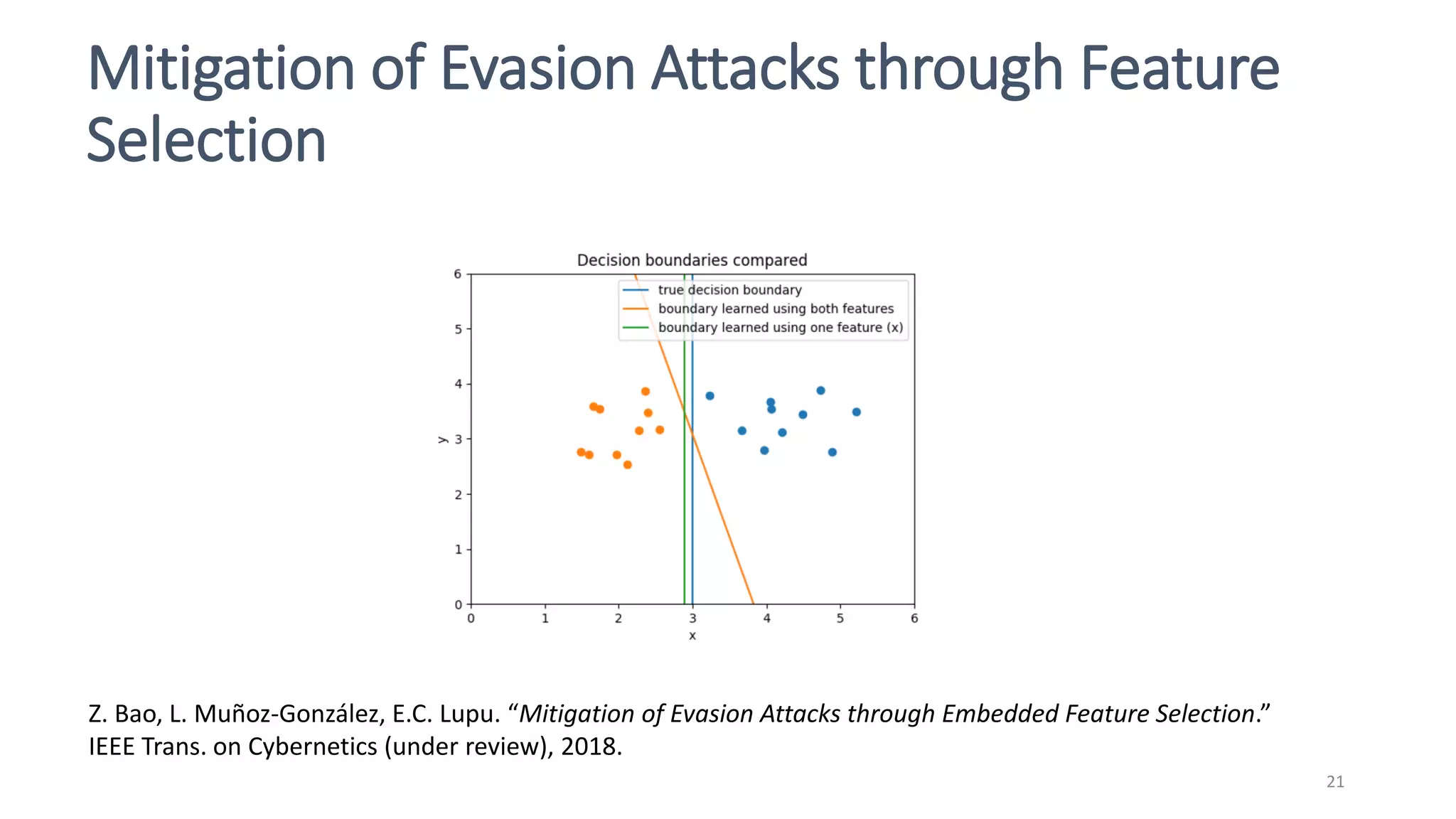
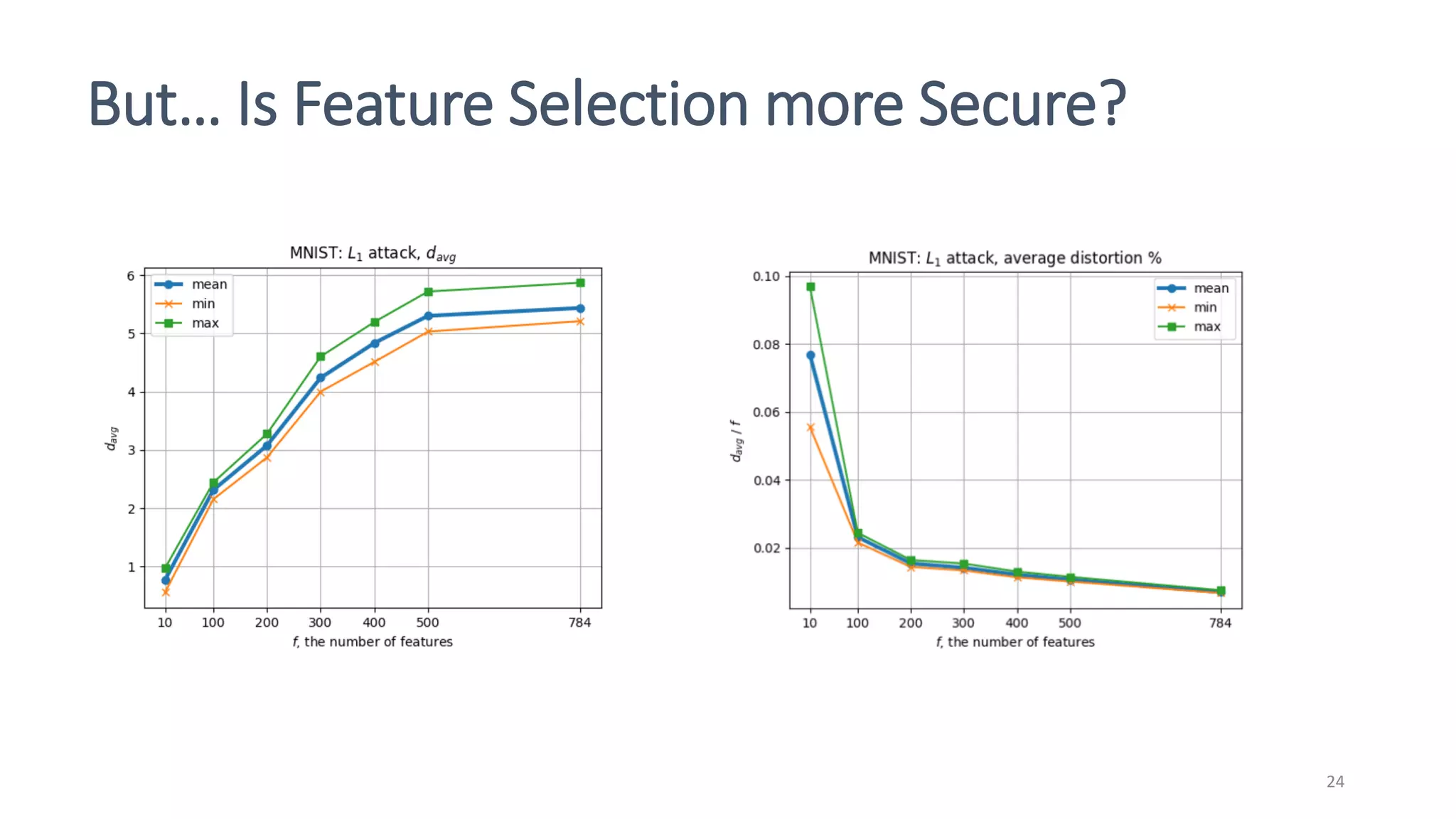
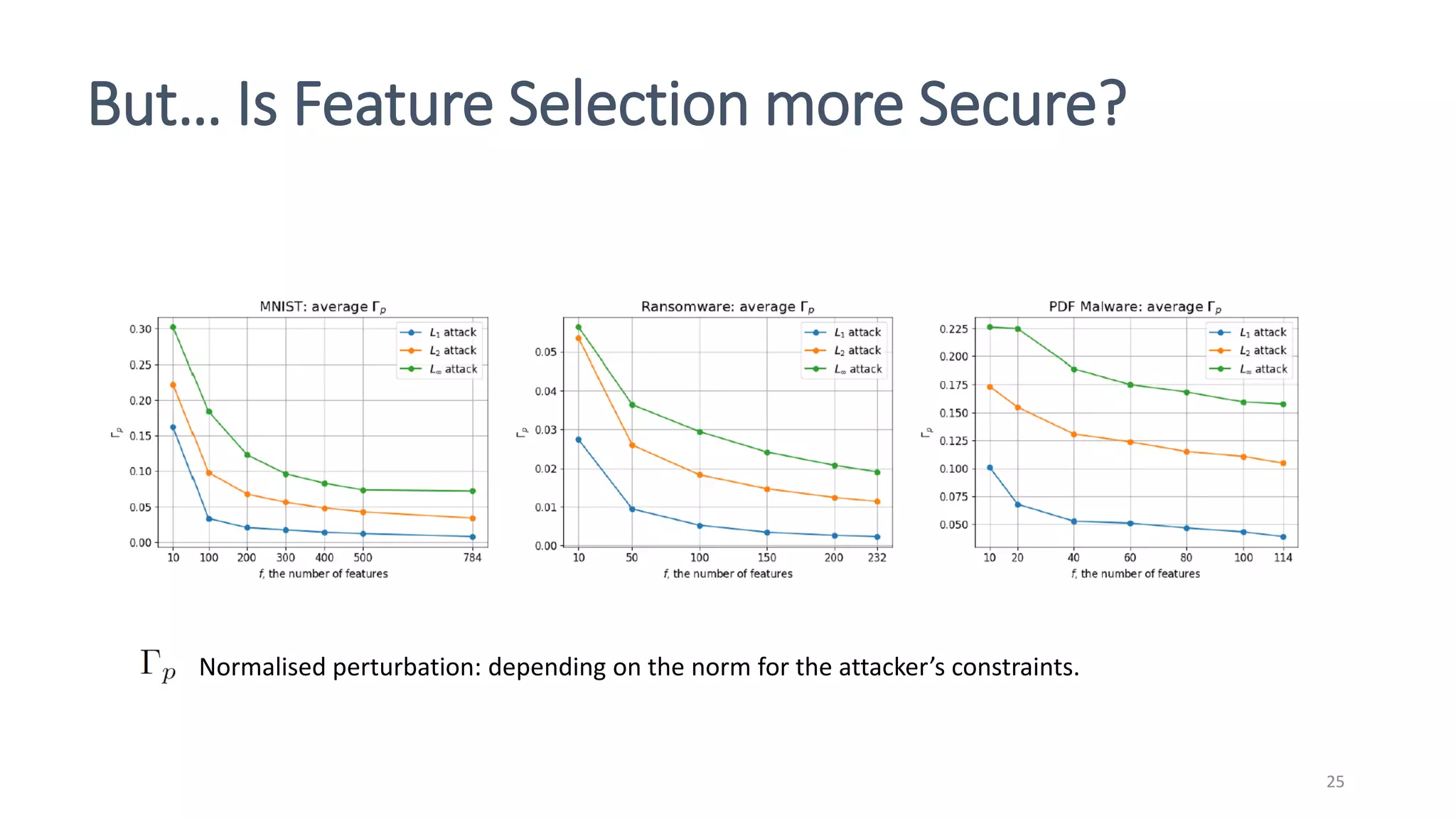
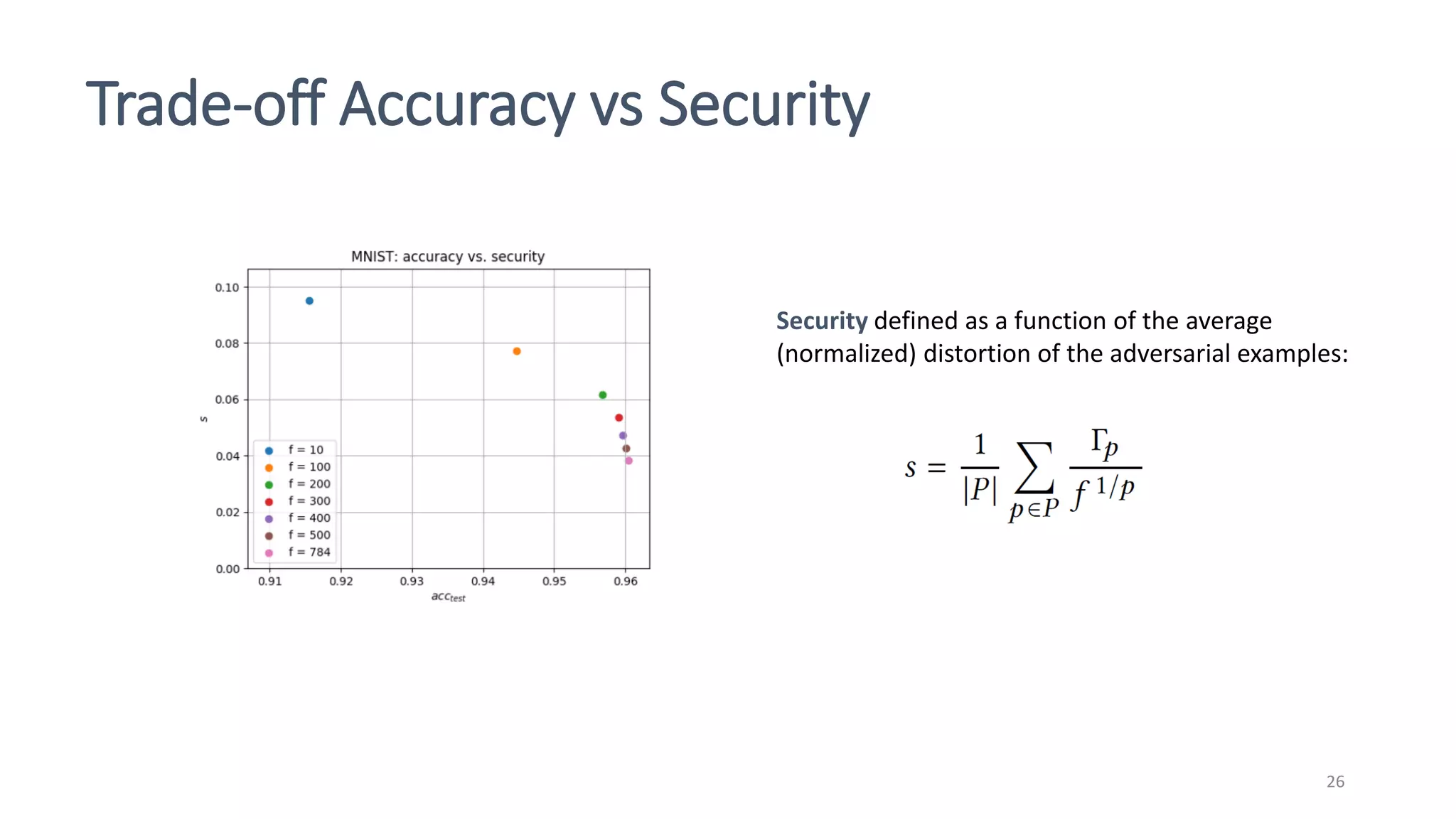
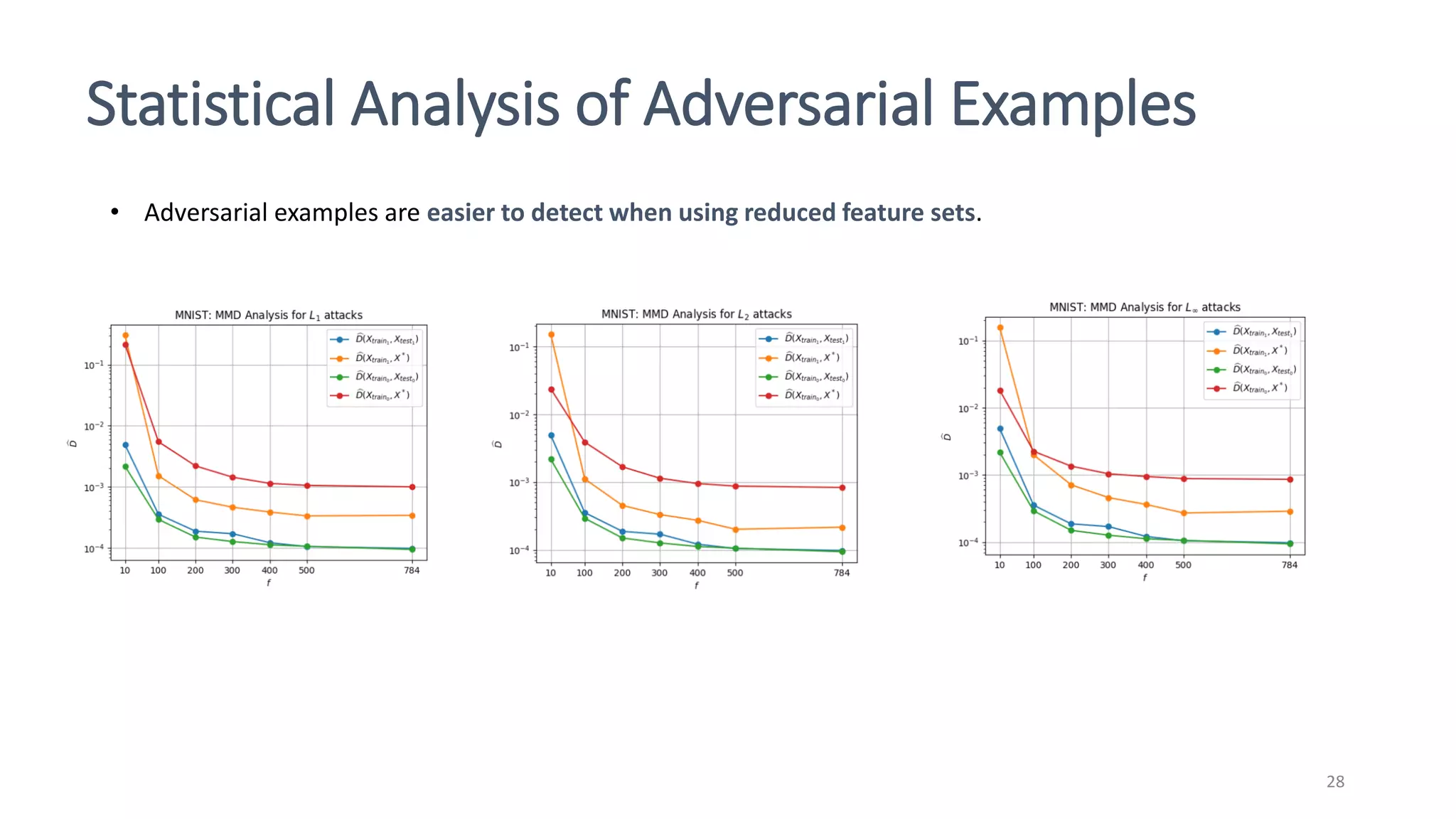
This document discusses adversarial machine learning attacks. It begins by reminding the reader about evasion attacks, which aim to find model weaknesses at test time, and poisoning attacks, which compromise the training process. It then discusses evasion attacks in more detail, including the use of adversarial examples and real-world attacks. The document outlines different types of evasion attacks and formulations. It also discusses adversarial training as a potential mitigation technique, as well as universal adversarial perturbations. The document presents experimental results showing that perlin noise attacks can outperform other attacks and that adversarial training is not fully effective. It concludes by emphasizing the need to understand vulnerabilities in machine learning systems and develop effective defenses and testing methodologies.





















































![[DSC Europe 23] Aleksandar Tomcic - Adversarial Attacks](https://cdn.slidesharecdn.com/ss_thumbnails/aleksandartomcic-adversarialattacks-231128234241-ab5a6f11-thumbnail.jpg?width=640&height=640&fit=bounds)




































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)


