The document discusses the integration of artificial intelligence (AI) in healthcare, emphasizing the rapid advancement of AI technologies and their transformative potential across various medical fields such as genomics, diagnostics, and imaging. It highlights the challenges faced by healthcare institutions, including data overload, application chaos, and cost management, while outlining a framework for AI implementation that leverages high-performance computing and cloud infrastructure. Ultimately, the document stresses the importance of modernizing data analysis processes to enhance patient care and operational efficiency in the healthcare sector.
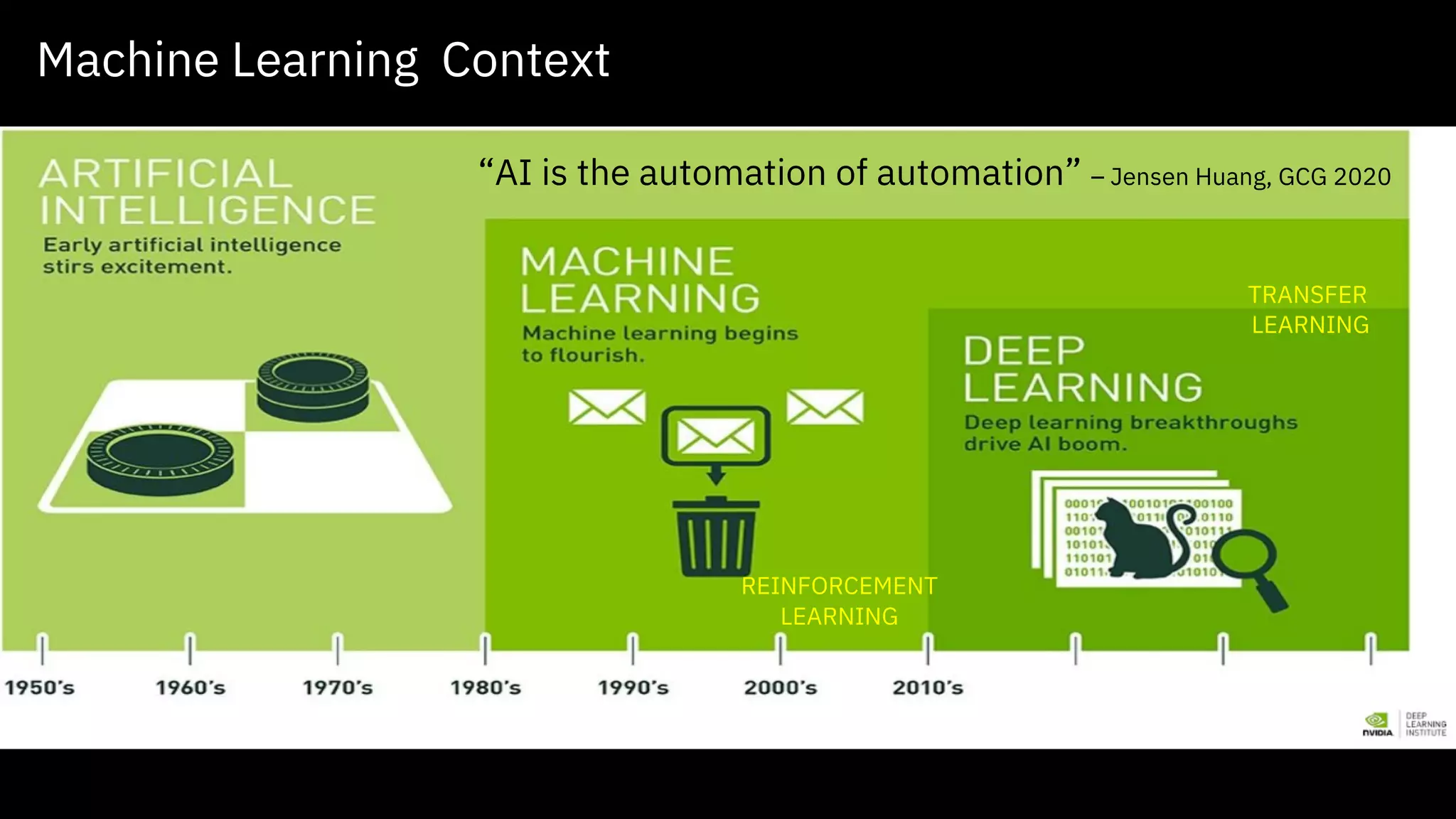
Introduction to AI's role in healthcare, including agenda, use cases, and infrastructure.
AI as a growing workload; insights from data analytics leading to actionable healthcare outcomes.
Framework for AI infrastructure including orchestration and high-performance computing applications. Categories of AI use cases, including computer vision and natural language processing across various industries.
Key challenges in healthcare data management such as data overload, app chaos, and cost management.
Optimizing medical imaging for enhanced diagnosis accuracy and efficiency using deep learning.
High volume imaging technology needs and accelerated analysis with advanced computational resources.
Large-scale molecular dynamics simulations utilizing HPC for research and drug discovery enhancements.
Optimizing genomics analysis for improved computational efficiency and resource utilization in healthcare.
AI Ladder methodology for modernizing healthcare data systems and enhancing analytics capabilities.
Diverse data sources including public, proprietary, and transaction data, and the role of metadata.
AI software landscape, frameworks, and openness in infrastructure for enhancing AI deployment.
Closing remarks and gratitude for engagement in exploring AI applications in healthcare.
5
Analytics Modernization: FromData to Actions
010101010101010111100010011001010111
0000000000010101010100000000000 111101011
11000 000000000000 111111 010101 101010 10101010100
Prescriptive
What should
we do ?
Descriptive
What Has
Happened?
Cognitive
Learn
Dynamically
Predictive
What Will
Happen?
ACTION
DATA
HUMAN INPUTS
<
< >
< >
>
>
delivering faster insights with greater efficiency to impact more lives
6.
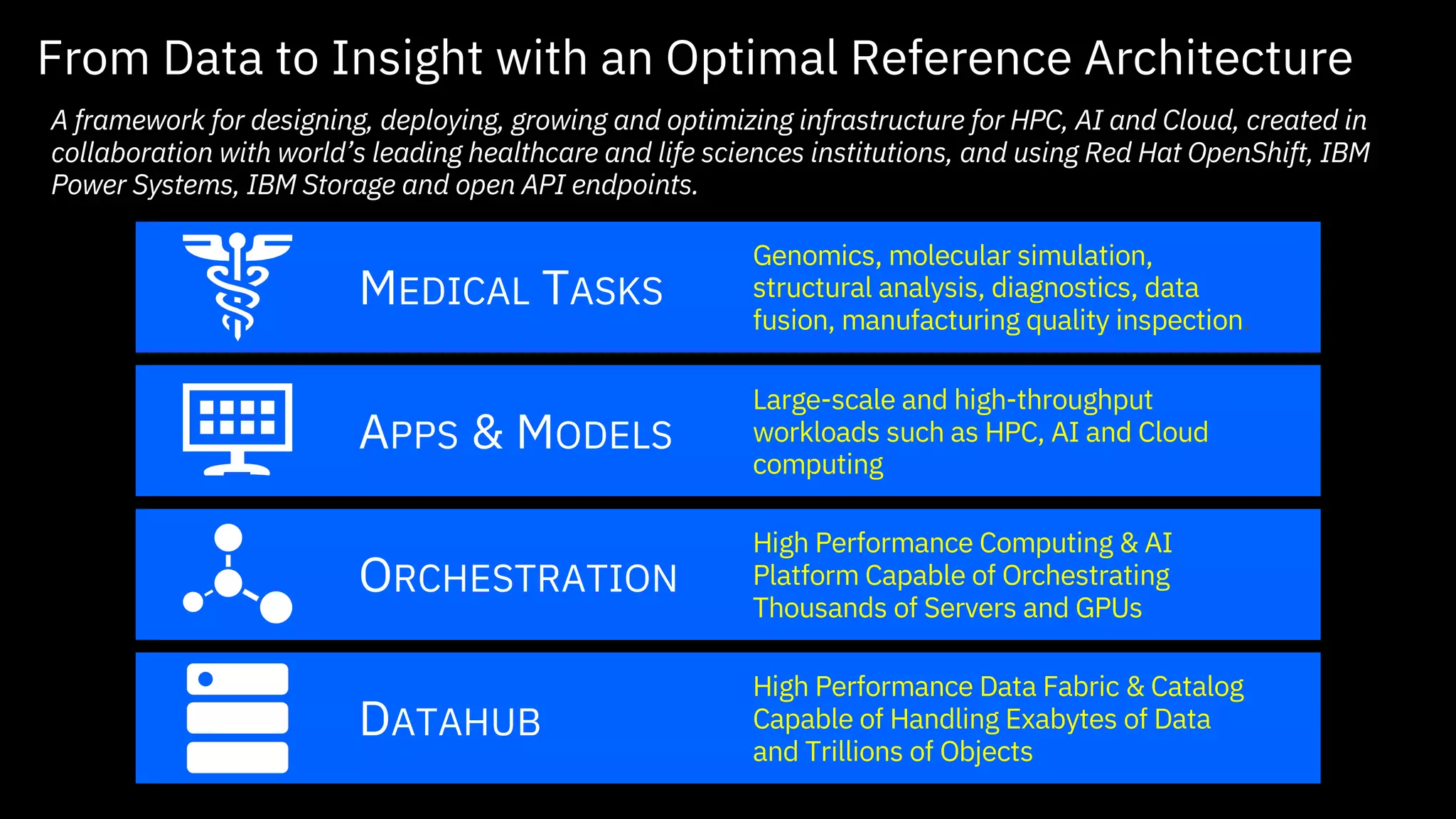
A framework fordesigning, deploying, growing and optimizing infrastructure for HPC, AI and Cloud, created in
collaboration with world’s leading healthcare and life sciences institutions, and using Red Hat OpenShift, IBM
Power Systems, IBM Storage and open API endpoints.
From Data to Insight with an Optimal Reference Architecture
DATAHUB
High Performance Data Fabric & Catalog
Capable of Handling Exabytes of Data
and Trillions of Objects
ORCHESTRATION
High Performance Computing & AI
Platform Capable of Orchestrating
Thousands of Servers and GPUs
APPS & MODELS
Large-scale and high-throughput
workloads such as HPC, AI and Cloud
computing
MEDICAL TASKS
Genomics, molecular simulation,
structural analysis, diagnostics, data
fusion, manufacturing quality inspection.
7.
Three broad categoriesof AI Use Cases
“Structured” Data Use Cases
Computer Vision Use Cases
- Big Data (Rows and Columns)
- Available AI Software More Accuracy !
This is sort of “Magic”
- a deep learning Model is trained to detect and classify objects
Natural Language Processing Use Cases
- A Model learns to read, hear and “understand” language
10
Smart loves problems,and there has never been a bigger
problem facing our world.
Biomolecular Structure
Molecular Simulation
Genomics Medical Diagnostics AI
Data Fusion and AI
Bio-Informatics
Artificial intelligence and high-performance computing have already begun to attack the
virus, assisting in molecular drug discovery, genomics and medical image processing.
11.
Data
Overload
Oceans of data
arisefrom rapid
digitization and
instrumentation
of healthcare.
App Chaos
Thousands of
applications,
workflows and
models are not
all following the
same rules.
Adoption
Vertically
integrated
toolsets with
heavy
customization
and vendor lock-
in create work
silos.
Performance
When scaling up
or out, most
institutions
cannot diagnose
or analyze the
performance
problems they
face.
Cost
Demanding
workloads
require well-
orchestrated
infrastructure to
manage, monitor
and control
costs.
Five key challenges to progress remain despite advances
Optimizing Medical Imaging
Enhanceimage identification with deep learning
to assist physicians and benefit patients
1300 MRI images trained by IBM Power
Systems and IBM Storage in just two hours,
compared to forty hours on traditional
architectures
15
Advances in instrument
design,sample preprocessing
and mathematical methods
have enabled high volume
throughput imaging at atomic
scale.
Cryogenic electron
microscopes generate an
average of 5 TB of image data
per day
BIOMOLECULAR STRUCTURE
Massive Data Sets Require Massive Processing Capability
16.
Accelerating Cryo-EM ImagingAnalysis
Reduced time-to-completion for high resolution image
analysis jobs while increasing resource utilization
Using IBM AC922 cluster, more than 100 cryo-EM
high resolution image workload analysis jobs running
in parallel on Satori cluster
BIOMOLECULAR STRUCTURE
17.
Simulation of millionsof atoms requiring large computational
resources
Large scale simulation includes millions of
atoms
• Virus molecules
• Ribosomes
• Bioenergy system and complex
Solution
• High performance computing CPU and
GPUs accelerating performance
• Optimal memory and network bandwidths
scaling performance to hundreds of nodes
• Techniques to reduce number of simulations
Receptor
ligand
Virus molecule simulation Receptor-ligand fit
Cryptic binding site prediction Binding energy prediction
MOLECULAR SIMULATION
18.
Molecular Dynamics SimulationComputational Intensity
A) Using NAMD to simulate influenza
B) virus (left)and Covid-19 (right)
B) Drug discovery:
protein receptor
C) In silico prediction of protein cryptic binding site D) Predicting protein receptor
ligand binding energy
Receptor
ligand
Large scale simulation
includes millions of atoms
• Virus molecules
• Ribosomes
• Bioenergy system and complex
Solution
• High performance computing
CPU and GPUs accelerating
performance
• Optimal memory and network
bandwidths scaling performance
to hundreds of nodes
• Techniques to reduce number of
simulations
19.
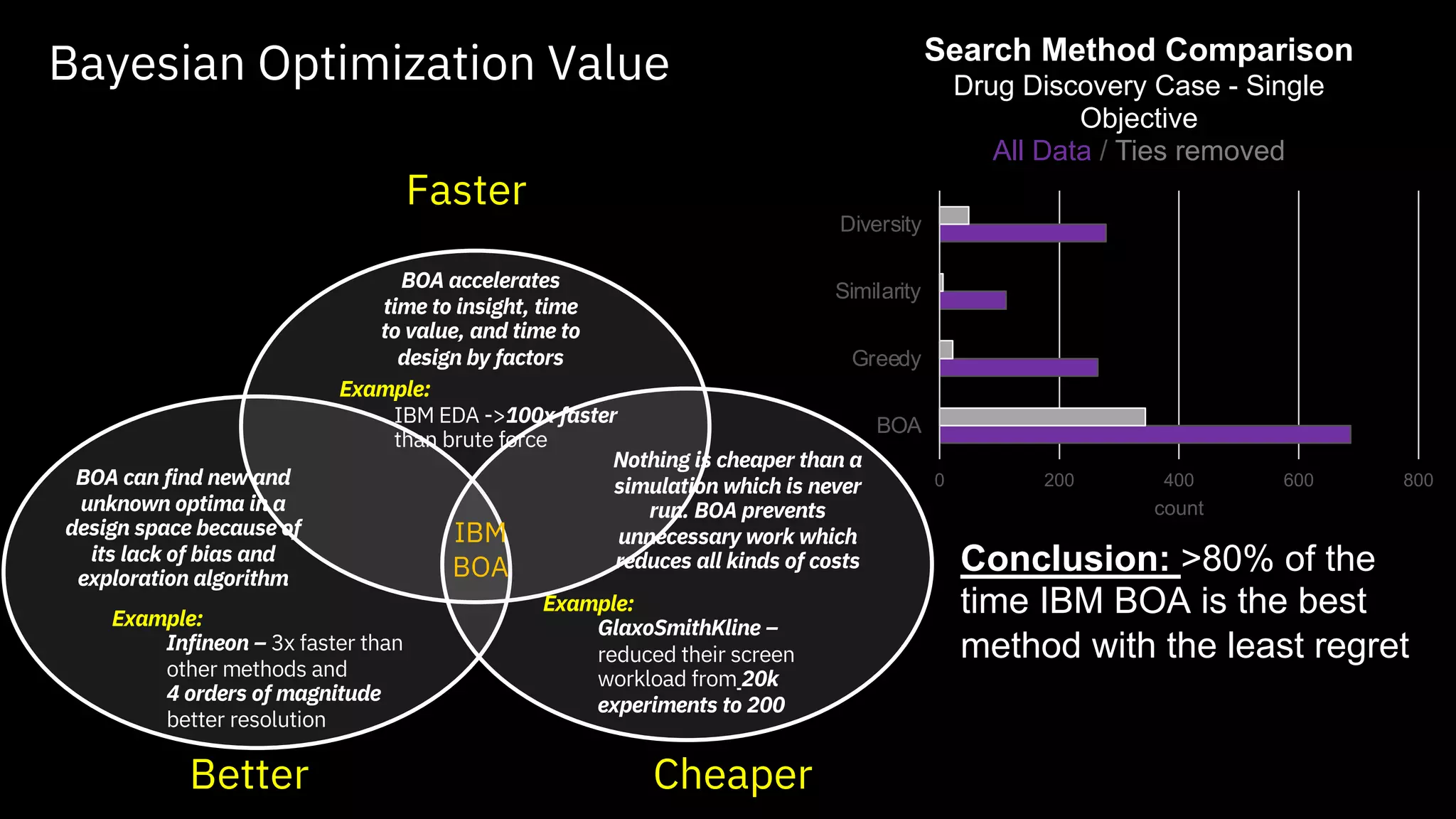
Bayesian optimization
accelerated workflow
uses1/3 of the
calculations to achieve 4
orders of magnitude
resolution increase
Optimizing Molecular Modeling
Achieves human level
performance in days
instead of months.
Accelerated Force Field Tuning Intelligent Phase Diagram Exploration
20.
Faster
Better Cheaper
BOA accelerates
timeto insight, time
to value, and time to
design by factors
Example:
IBM EDA ->100x faster
than brute force
BOA can find new and
unknown optima in a
design space because of
its lack of bias and
exploration algorithm
Example:
Infineon – 3x faster than
other methods and
4 orders of magnitude
better resolution
Nothing is cheaper than a
simulation which is never
run. BOA prevents
unnecessary work which
reduces all kinds of costs
Example:
GlaxoSmithKline –
reduced their screen
workload from 20k
experiments to 200
IBM
BOA
Bayesian Optimization Value
0 200 400 600 800
BOA
Greedy
Similarity
Diversity
count
Search Method Comparison
Drug Discovery Case - Single
Objective
All Data / Ties removed
Conclusion: >80% of the
time IBM BOA is the best
method with the least regret
21.
Optimizing Precision Genomics
Reducedtime-to-completion for long-running
jobs while increasing resource utilization
Using IBM, Sidra has completed hundreds of
thousands of computing tasks comprising
millions of files and directories, without
experiencing system downtime.
The Data: BiologicalData Analytics
Biological
Data Analysis
Biomarker
Identification
Biodata
modeling and
Statistical
Analysis
Biodata
Visualization
Medical Images
Data analysis
Structural
Bioinformatics
Genomics
Sequence data
analysis
Biological Data Analytics
q Genomic Sequence Data: an explosive growth of biodata
q Sequence alignment
q Variant discovery and characterization
q Genomic profiling and pattern discovery
q Biomarker Identification: gene expression profile, RNA-seq, ChIP-
seq, microarray identification and validation, etc.
q Structural Bioinformatics: identify and predict 3D biomolecule
structures, such Cryo-EM data refinement, molecular dynamic
simulation, NMR, x-Ray crystallographic data, etc.
q Biodata Modeling & Statistical Analysis: biological pathways
analysis, Gene, clinical data cohorts study, data extraction, etc.
q Medical Image Processing: image segmentation, registration,
statistic modeling.
q Biodata Visualization: 3D molecule structures, genomics sequences
visualization, etc.
Ruzhu Chen @ 2019
24.
High performance
and highthroughput
storage hierarchy
required for data
loading, extraction
and computation.
Tertiary storage
required for archive
and store. Storage
tools for data
indexing, discovery
and governance.
Computation
High performance
and efficiency of
software tools and
applications for
genomic variants and
biomarkers analysis,
drug discovery,
medical image
processing and
molecule structure
modeling, data
visualization.
High throughput
and optimized
workload pipelines
to accelerate
biodata analysis
with highly
optimal and
parallel I/O,
memory, CPU and
GPU
computations.
Solutions
Large volume
and variety of
data around
genomic sequences,
gene expression,
images, structural
biomolecules,
clinical and
healthcare
information,
personized medicine
data
Data Storage
The Challenges: Analyzing Explosive biological data
Data Explosion
Ruzhu Chen @ 2019
Metadata-Fueled Data Analysis
LargeScale Data Ingest
• Scan records at high speed
• Live event notifications
• Capture system-level tags
• Automatic indexing
Business-Oriented
Data Mapping
• Custom data tagging
• Content-inspection via APIs
• Policy-driven workflows
Data Activation
• Data movement via APIs
• Extensible architecture
• Solution Blueprints
Data Visualization
• Query billions of records
in seconds
• Multi-faceted search
• Drilldown dashboard
• Customizable reports
29.
Common AI DataConsiderations
Data Compute
Legacy Data
Stores
IoT, Mobile
& Sensors
Collaboration
Partners
New Data
Ingest Inference
Training
Preparation
Iterative Model training to improve accuracy
Champion
Challenge
r
-”Data Center”
- At Edge
Trained
Model
§ Ease to Massively Scale
§ High Performance
§ Tiered / Archive
§ Secure
§ High Performance
§ Metadata Tagging
§ Single Name Space
Low Latency
Dev & Inference Stack
- Open Source
- Stable and Supported
- Auditable
Productivity
Performance
Robustness
Considerations
Anaconda Environment forApplications
• Use anaconda enterprise network
(AEN) to manage cryo-EM software
repository on server.
• Easy to use and update software
Anaconda Architecture for Cryo-EM Analysis
Computation
Web Interface
Repo Install
Software
Control
Authentication
Anaconda Server
Compute Nodes
Database Users
32.
Anaconda Environment forApplications
• Use anaconda enterprise network
(AEN) to manage cryo-EM
software repository on server.
• Easy to use and update software
Anaconda Architecture for Cryo-EM Analysis
Computation
Web Interface
Repo Install
Software
Control
Authentication
Anaconda Server
Compute Nodes
Database Users
33.
OpenPOWER is atechnical community
dedicated to expanding the the IBM Power architecture ecosystem
https://github.com/open-ce
Open-CE
Minimize time to value for
foundational ML/DL packages
Provide a flexible source-to-image
solution to provide a complete and
customizable AI environment.