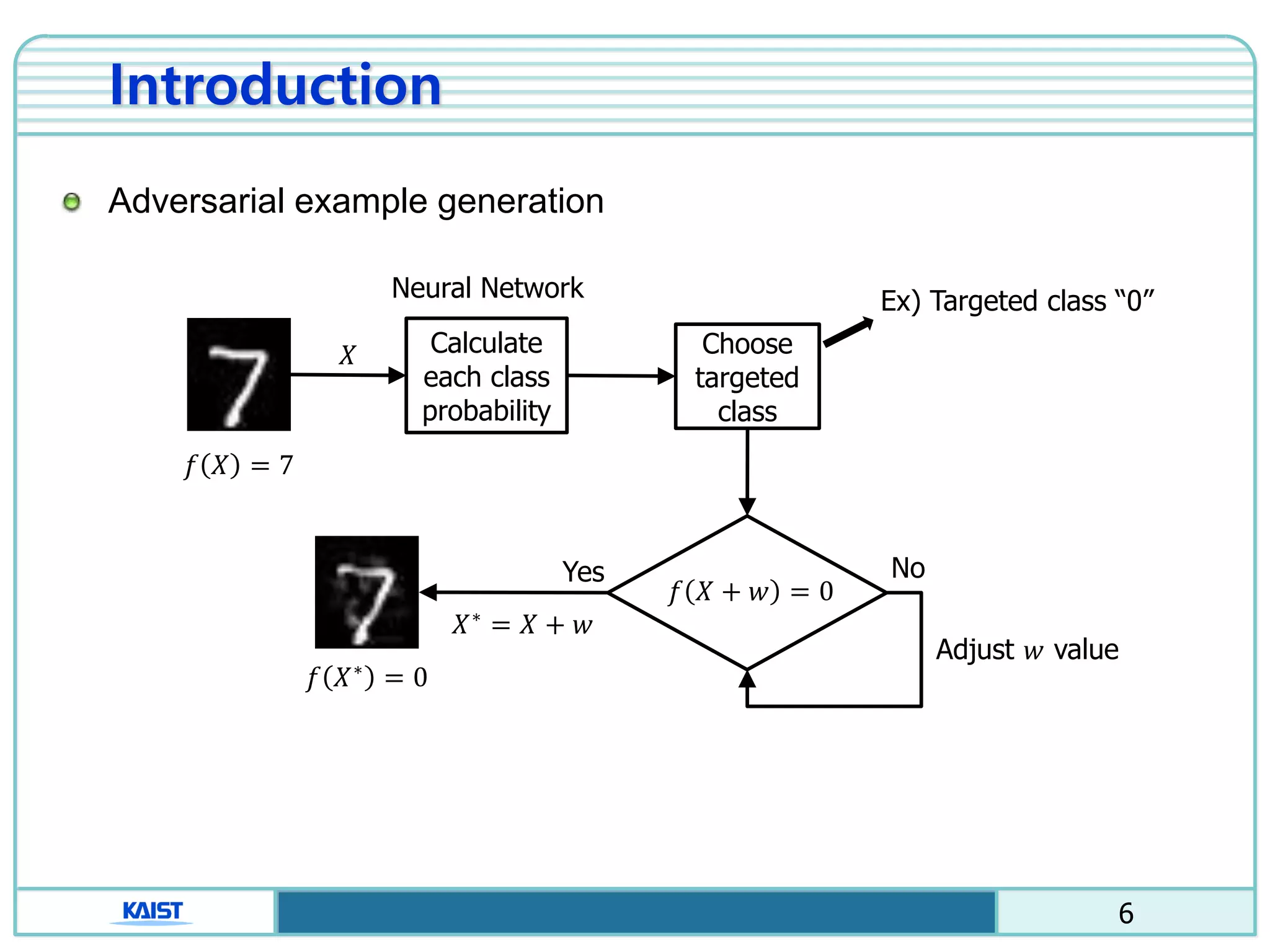
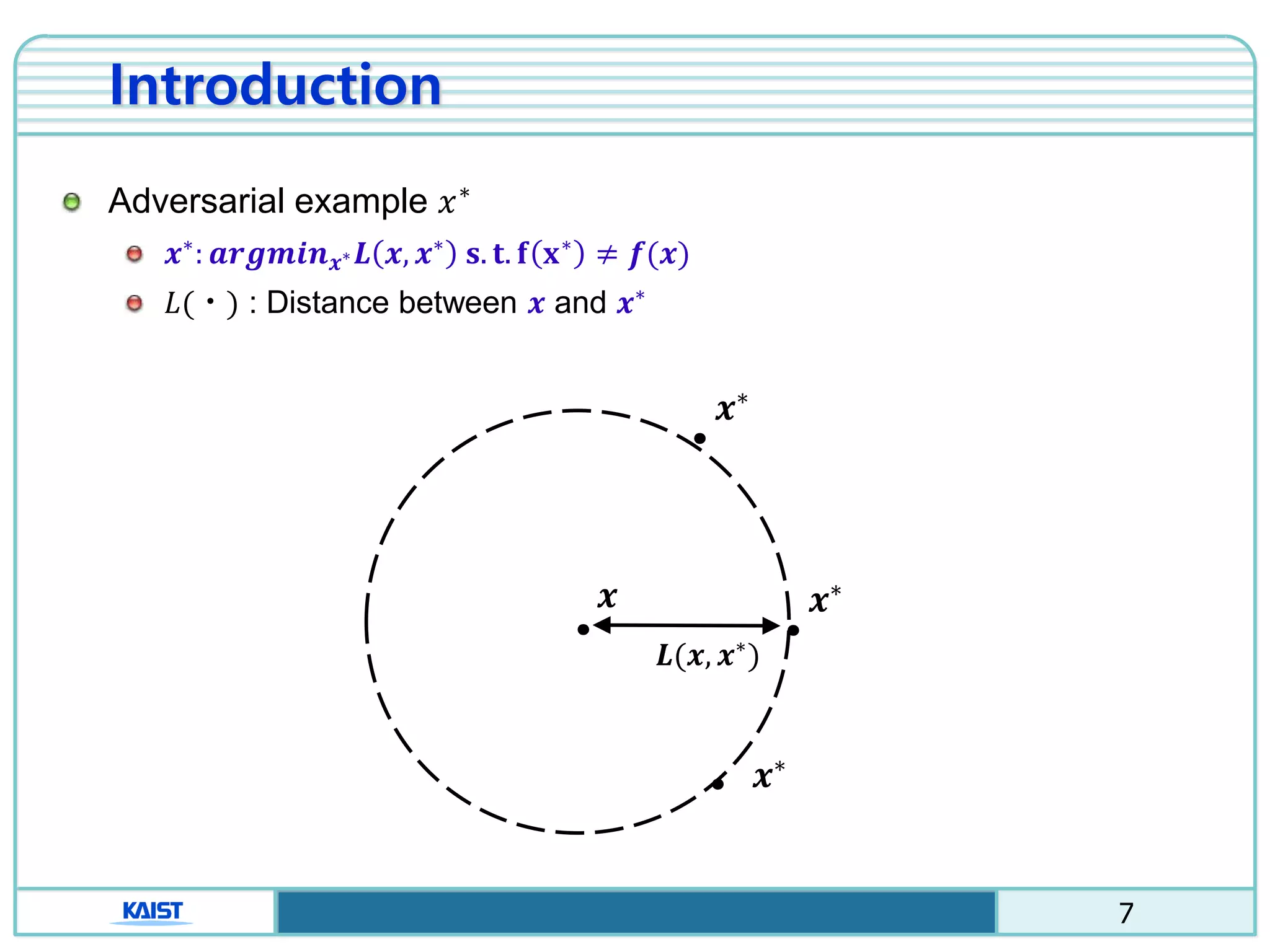
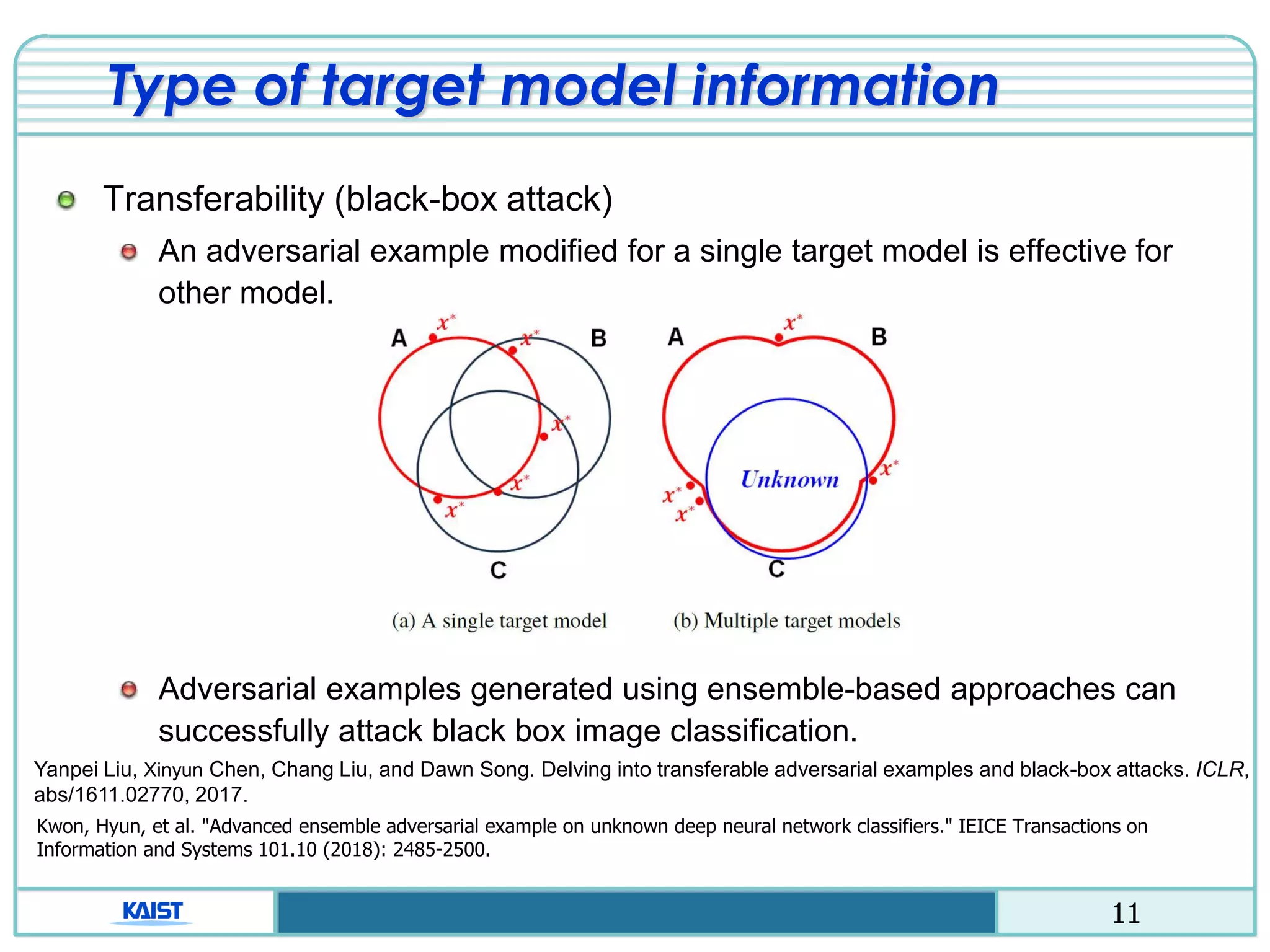
Downloaded 114 times













![21
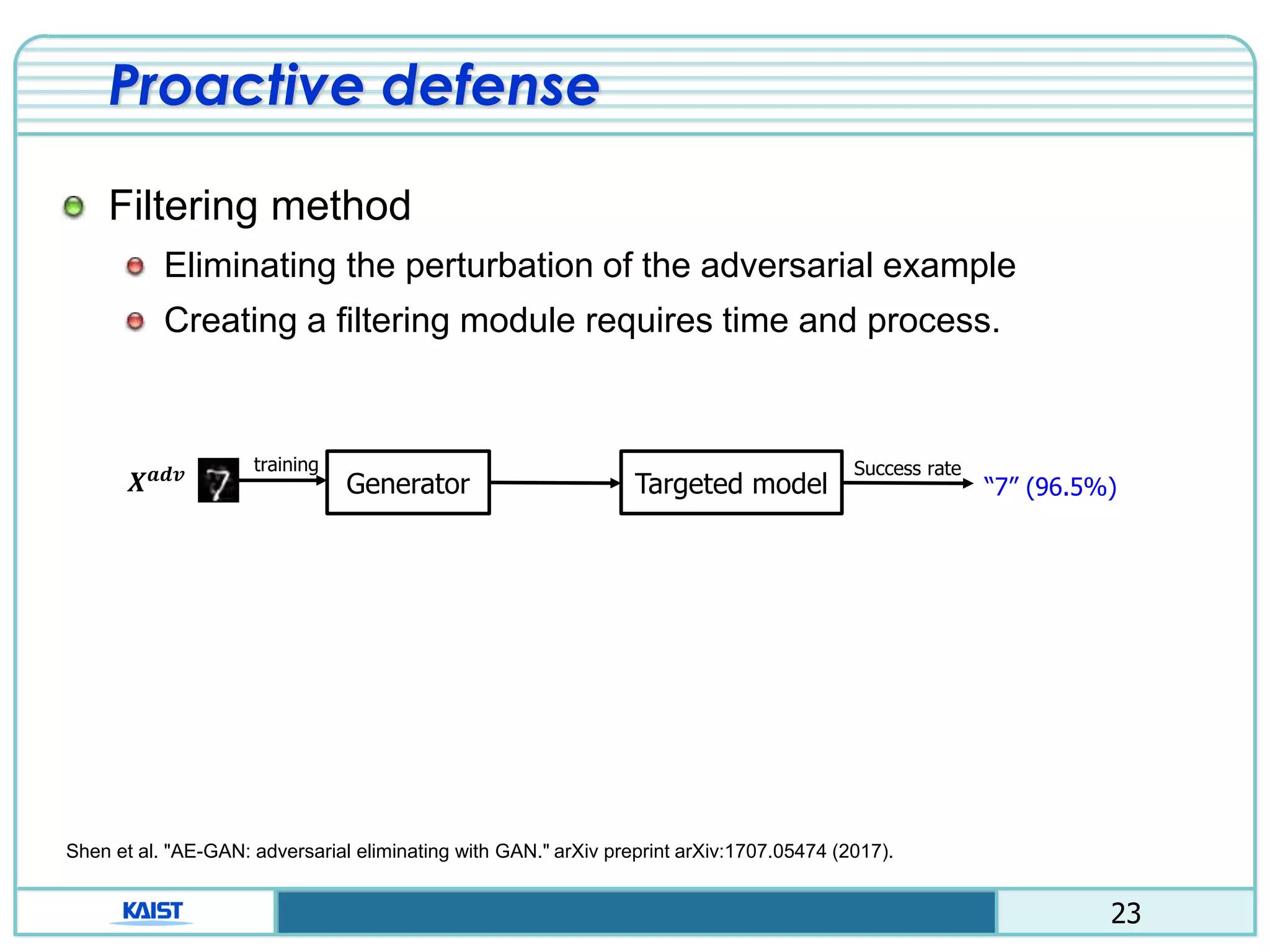
Proactive defense
Distillation method
Using two neural network (detailed class probability)
Ex) “1”, class: [0100000000] 1”, class:[0.02 0.91 … 0.02]
Avoid calculating the gradient of the loss function.
Training Data 𝑥 Training label y
0
1
0
0 Training Data 𝑥 Training label f(x)
DNN 𝑓(𝑥) trained at temperature T DNN 𝑓 𝑑𝑖𝑠𝑡𝑖𝑙
(𝑥) trained at temperature T
Probability Vector Predictions 𝑓(𝑥) Probability Vector Predictions 𝑓 𝑑𝑖𝑠𝑡𝑖𝑙
(𝑥)
0.02
0.92
0.04
0.02
0.02
0.92
0.04
0.02
Initial Network Distilled Network
0.03
0.93
0.01
0.03
Nicolas Papernot, Patrick McDaniel, XiWu, Somesh Jha, and Ananthram Swami. Distillation as a defense to adversarial
perturbations against deep neural networks. In Security and Privacy (SP), 2016 IEEE Symposium on, pages 582–597.
IEEE, 2016.](https://image.slidesharecdn.com/researchofadversarialexampleonadeepneuralnetwork-190226105317/75/Research-of-adversarial-example-on-a-deep-neural-network-21-2048.jpg)



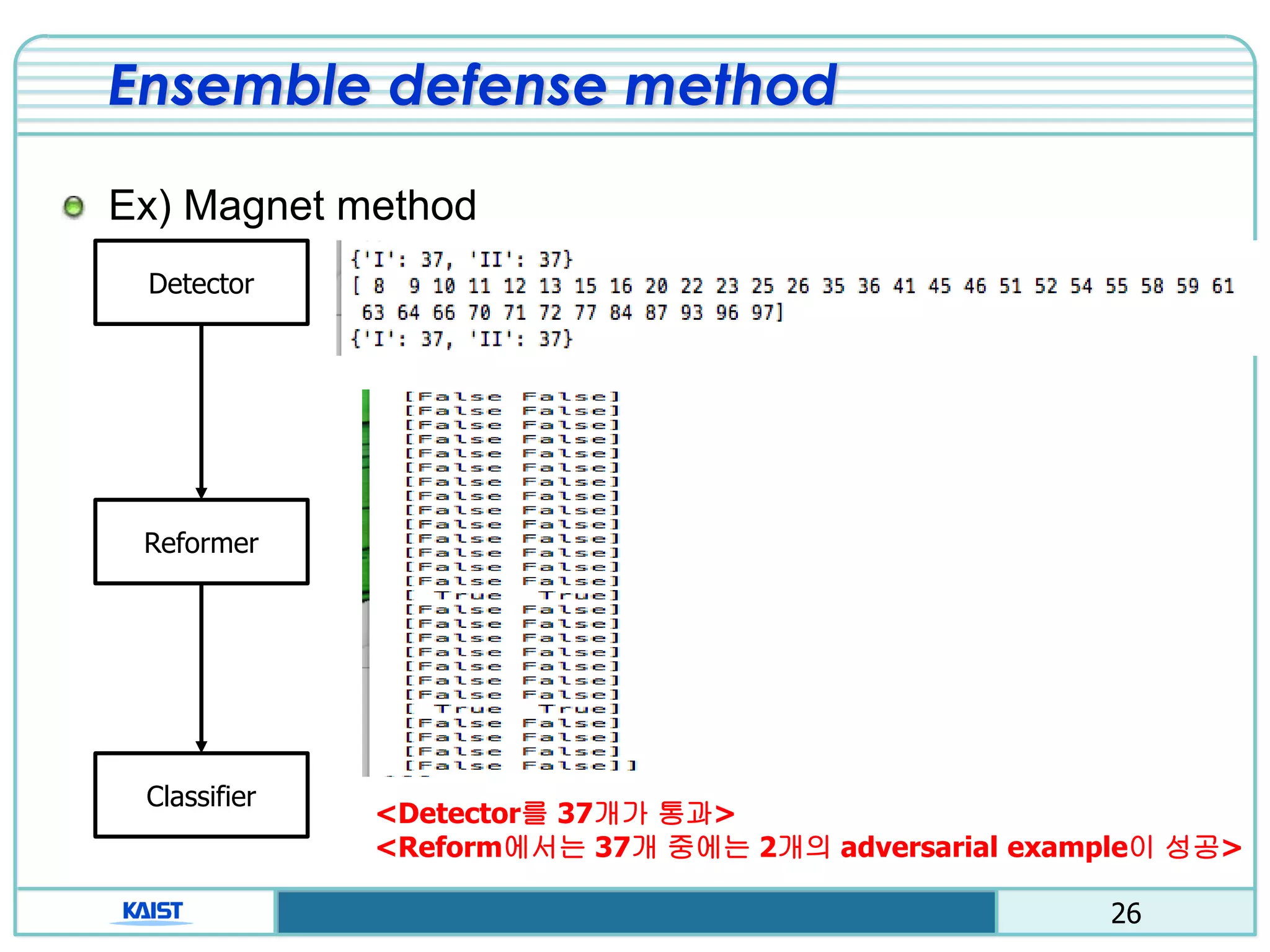
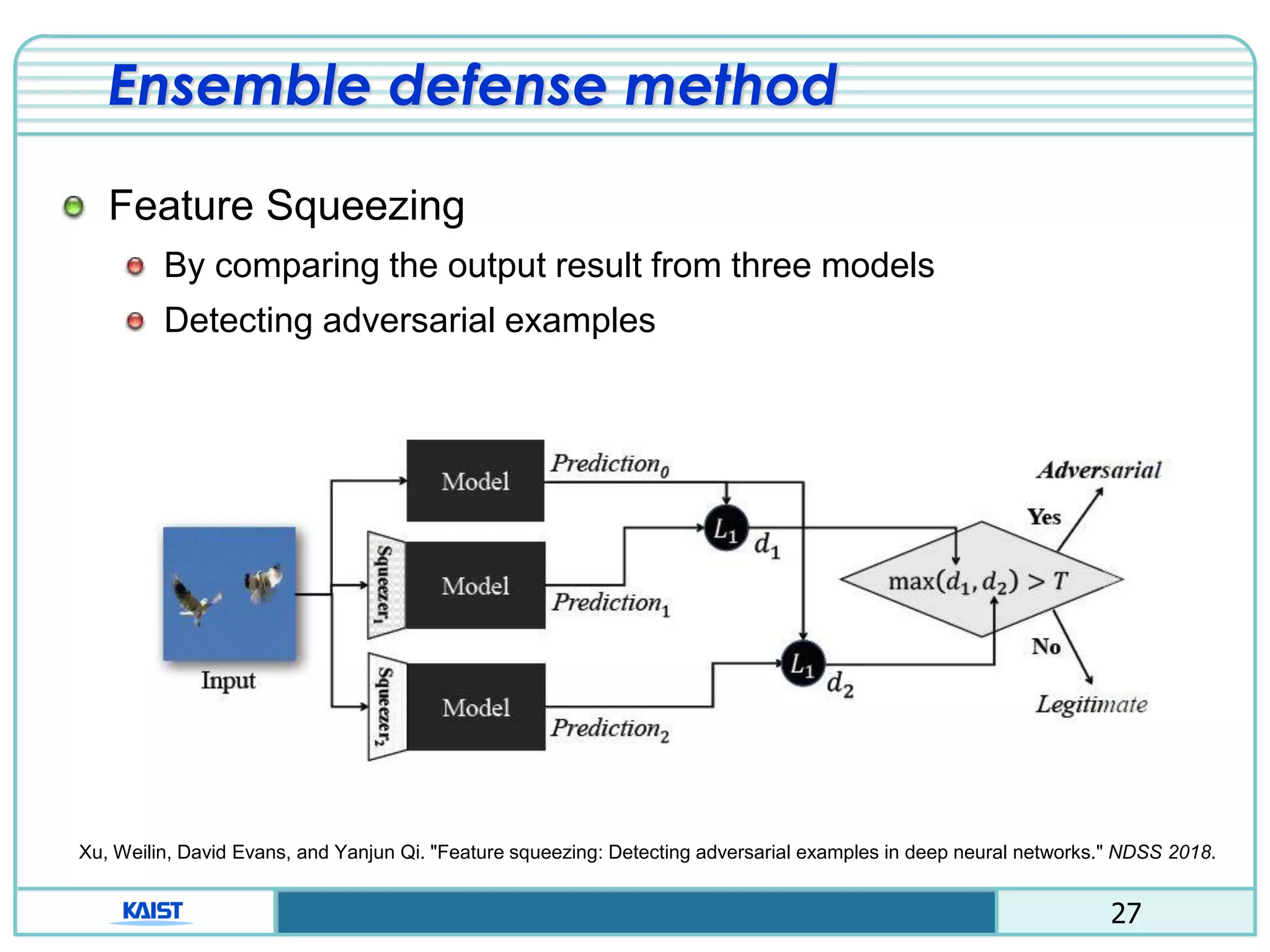
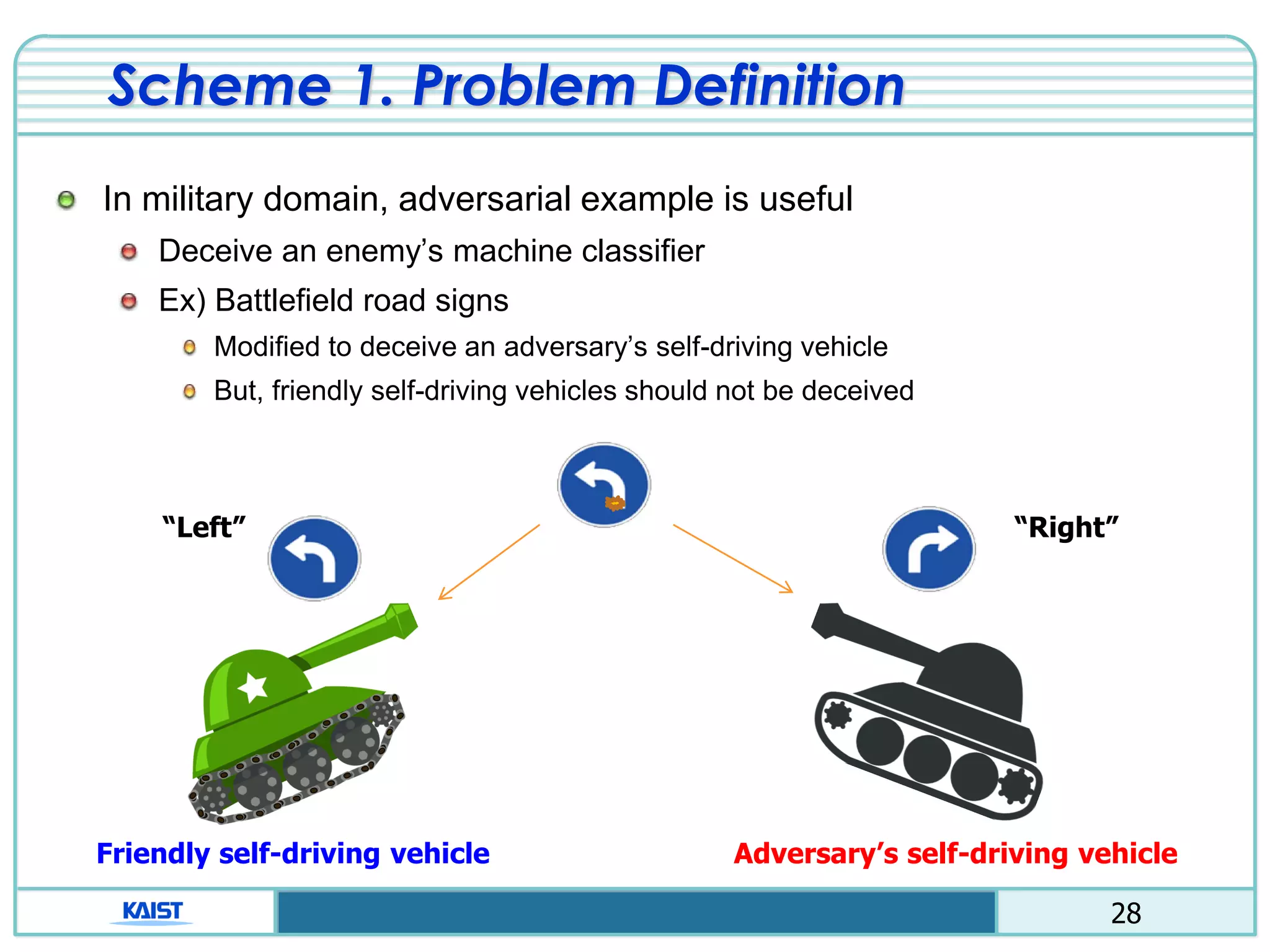



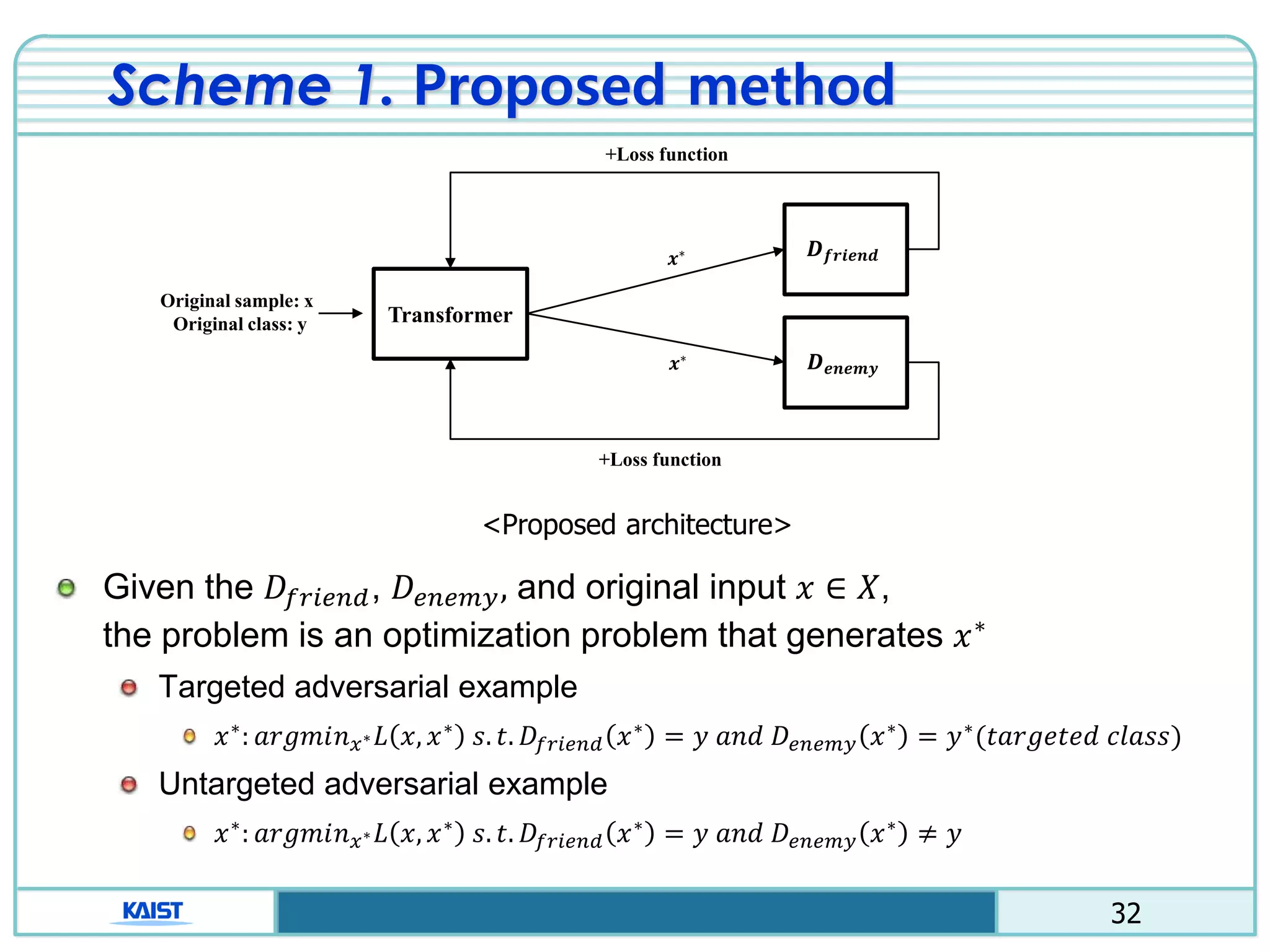





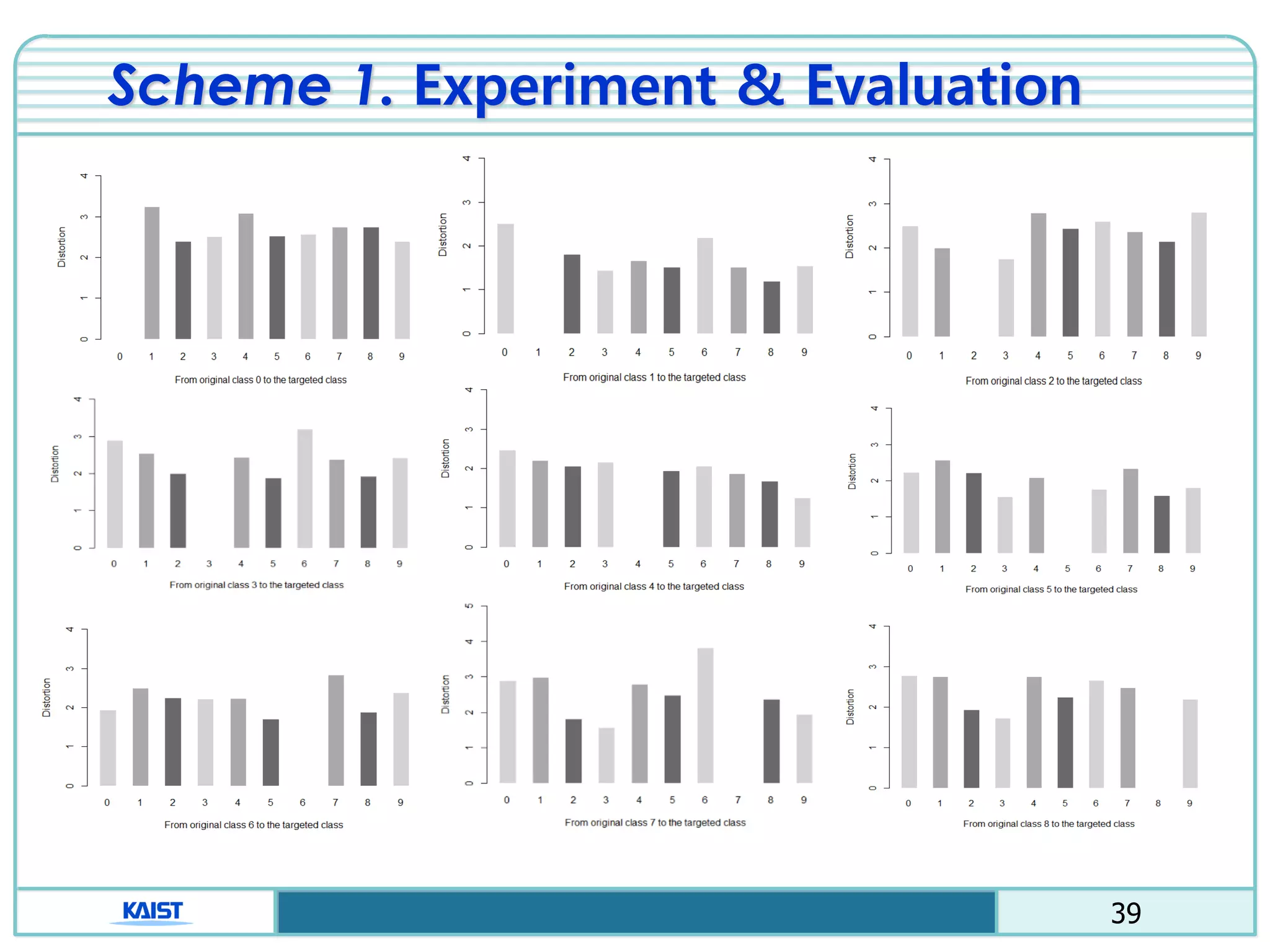
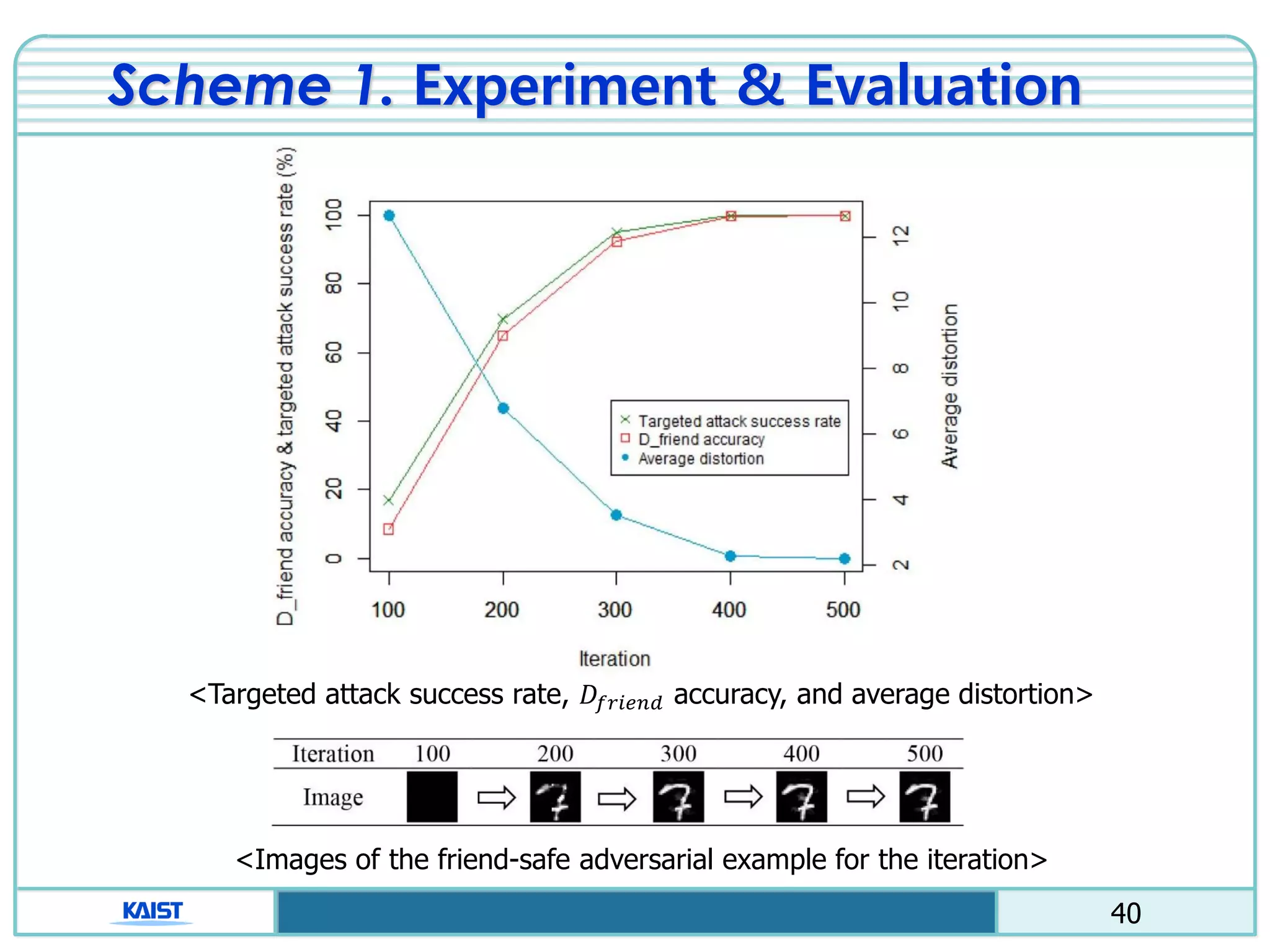
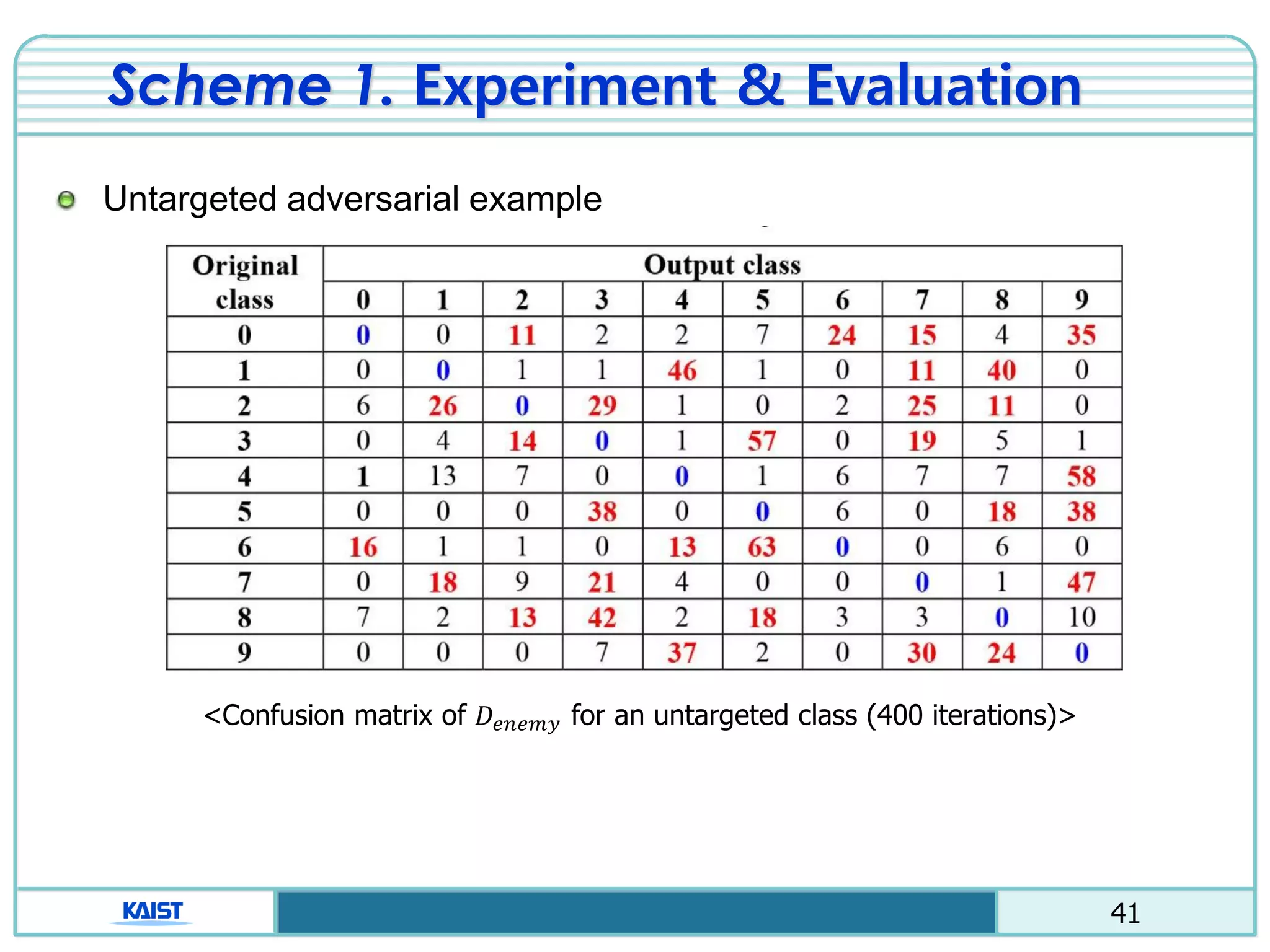
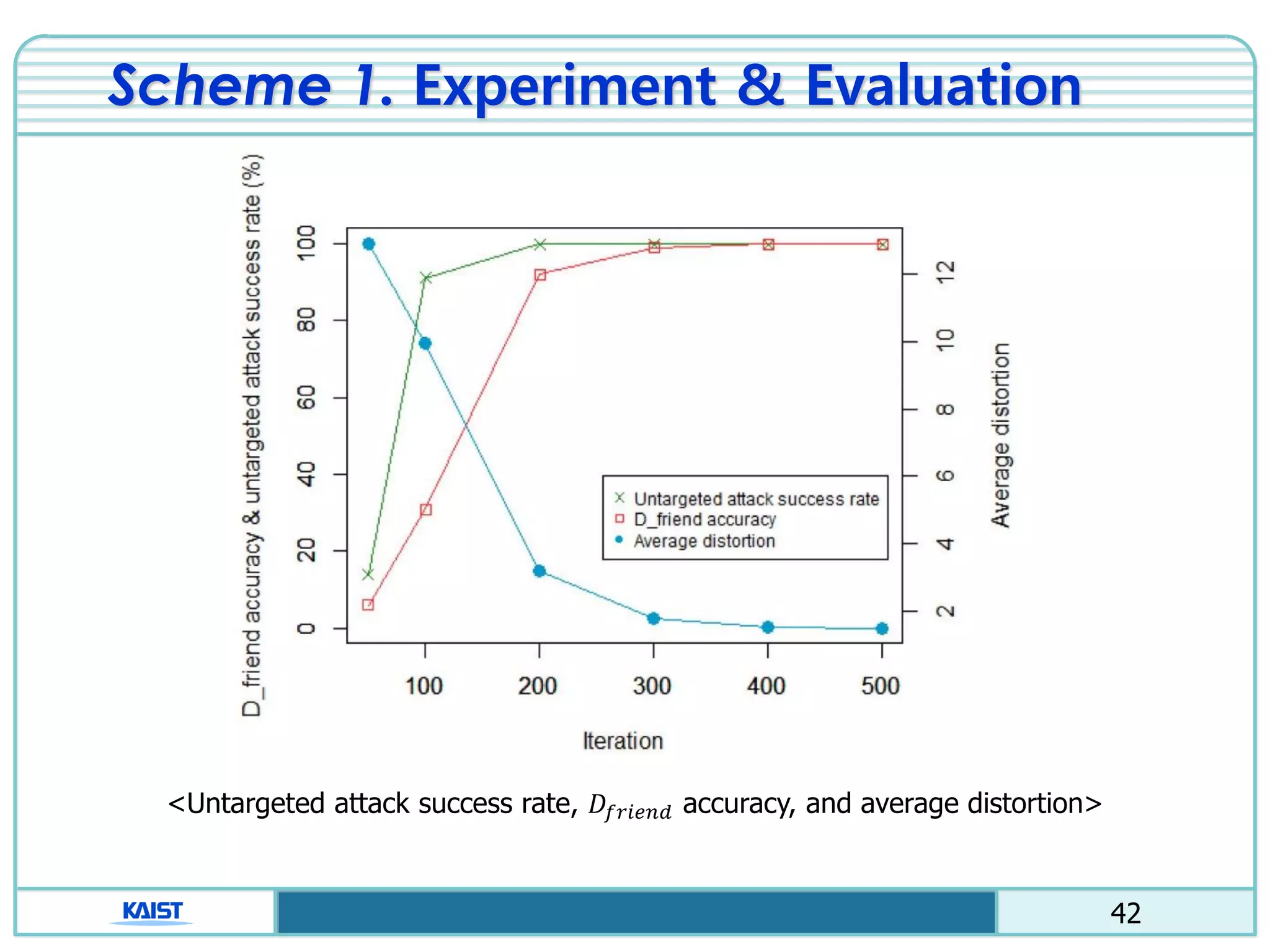
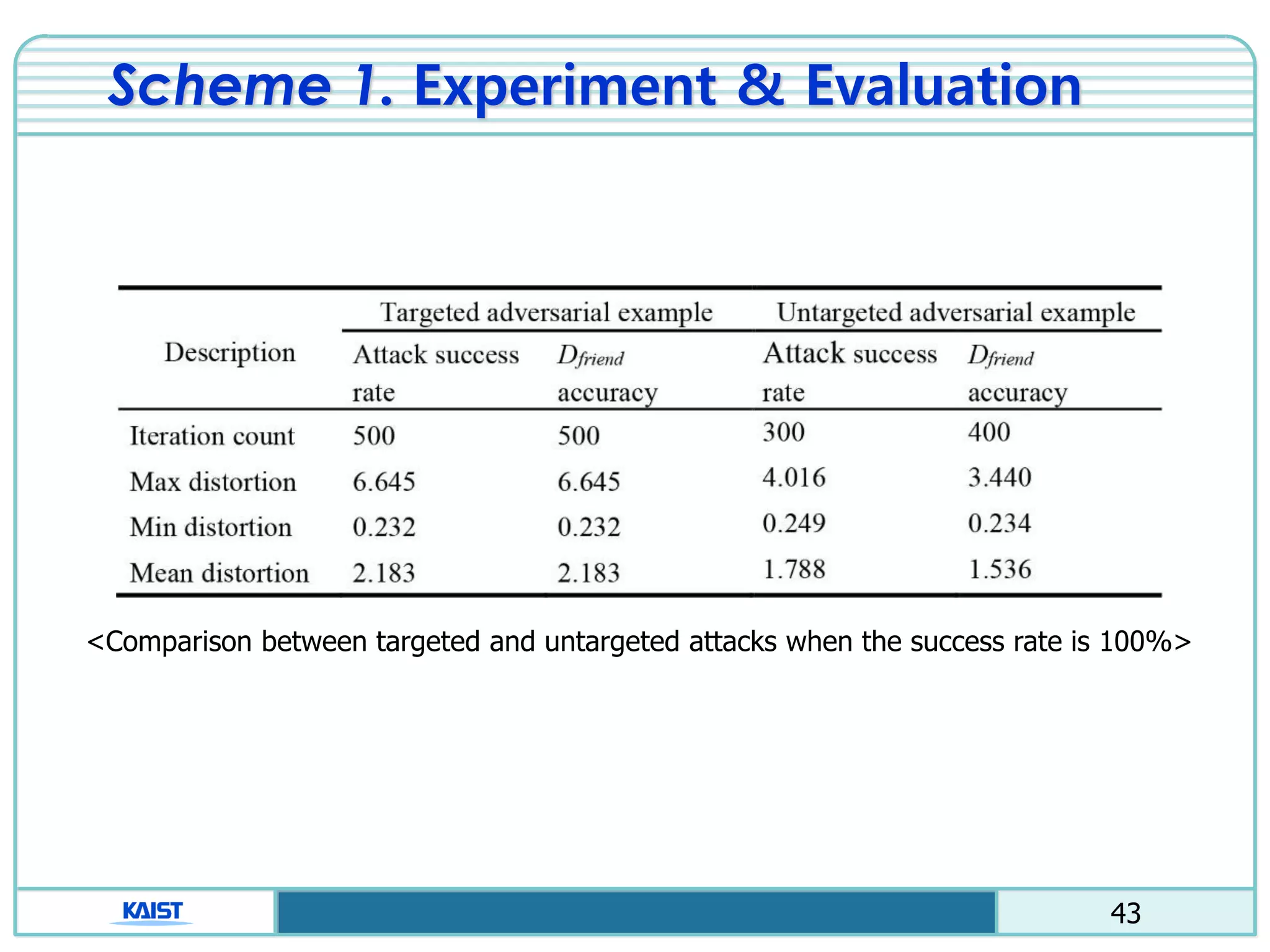

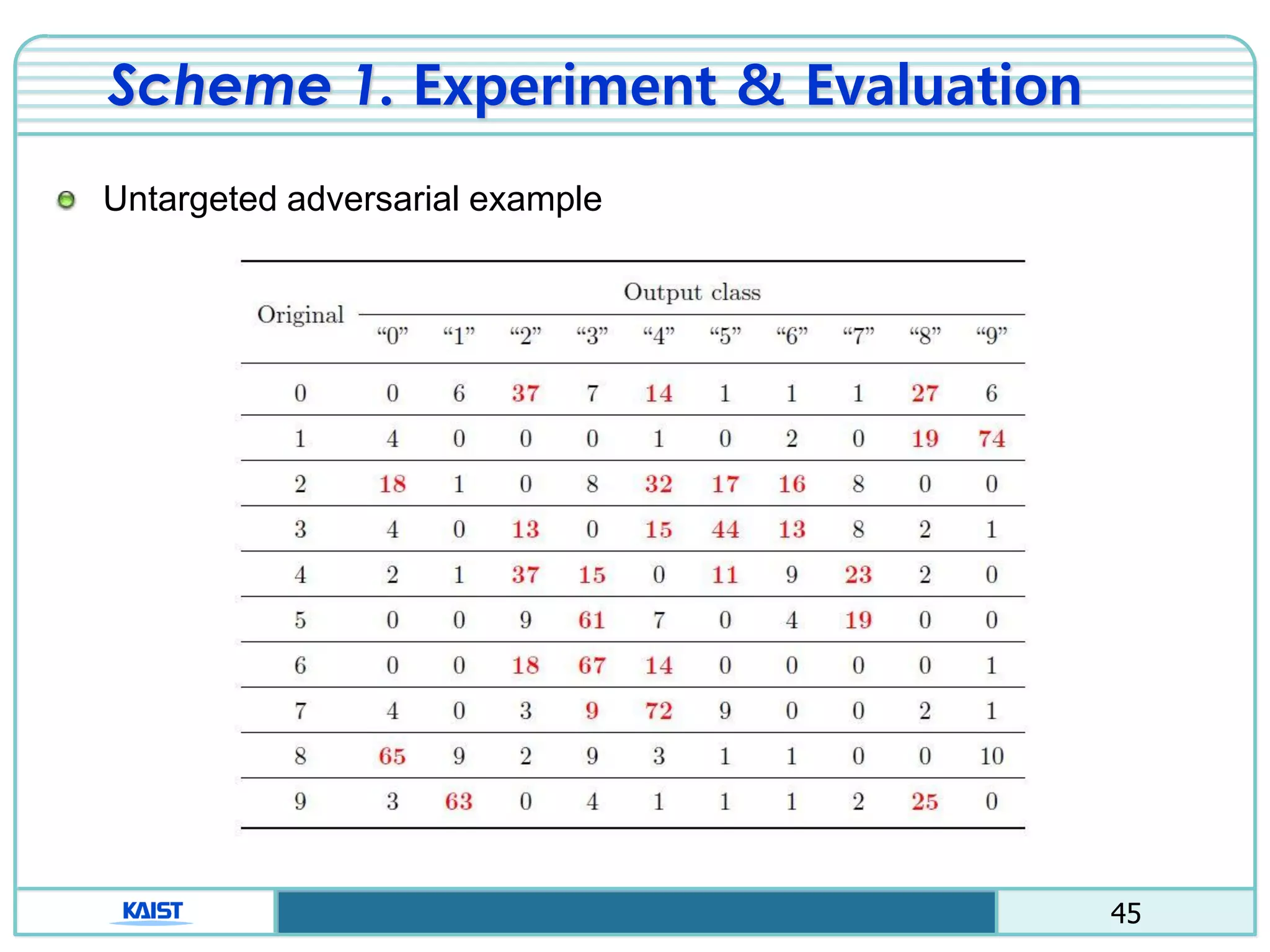
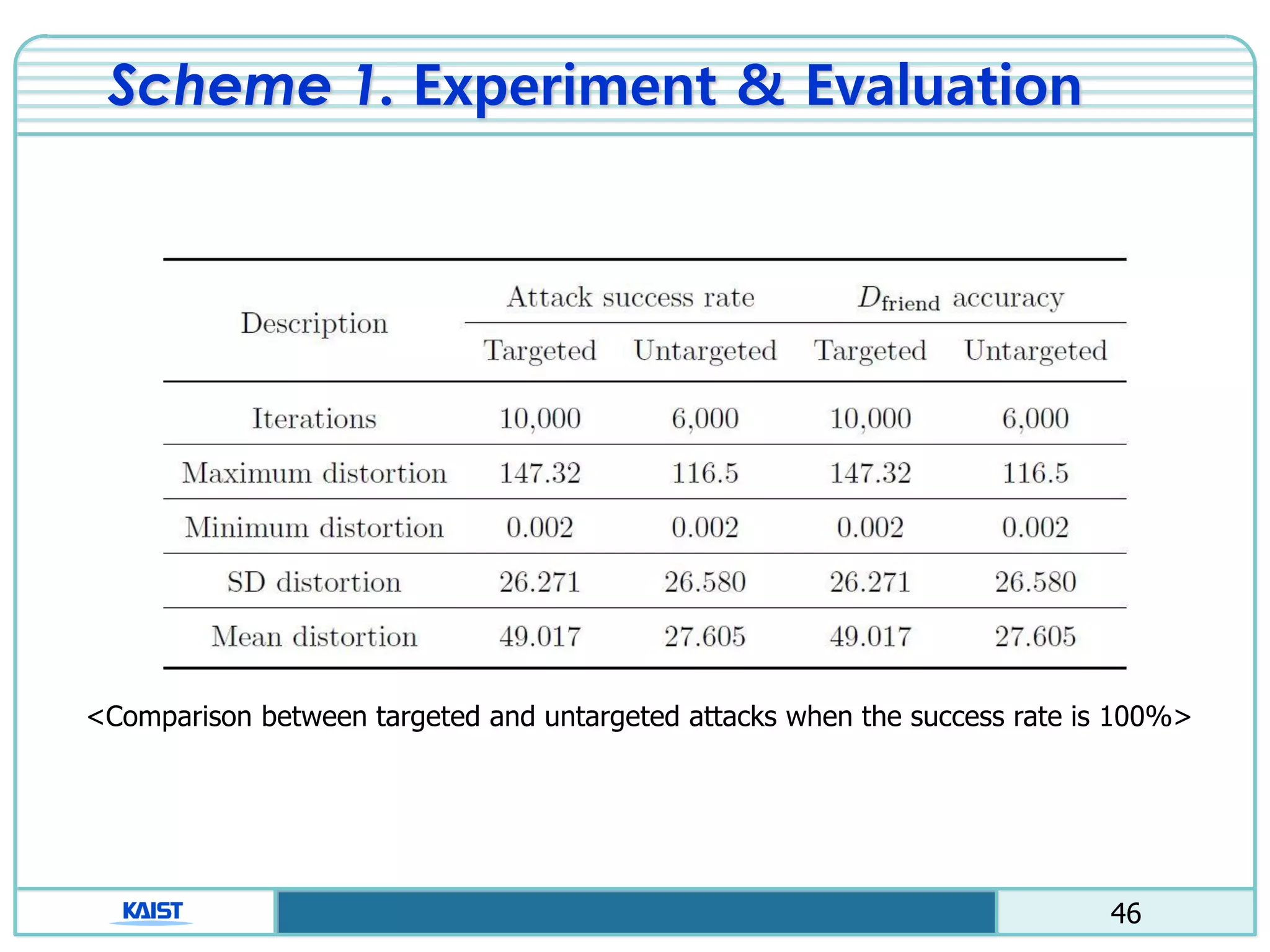
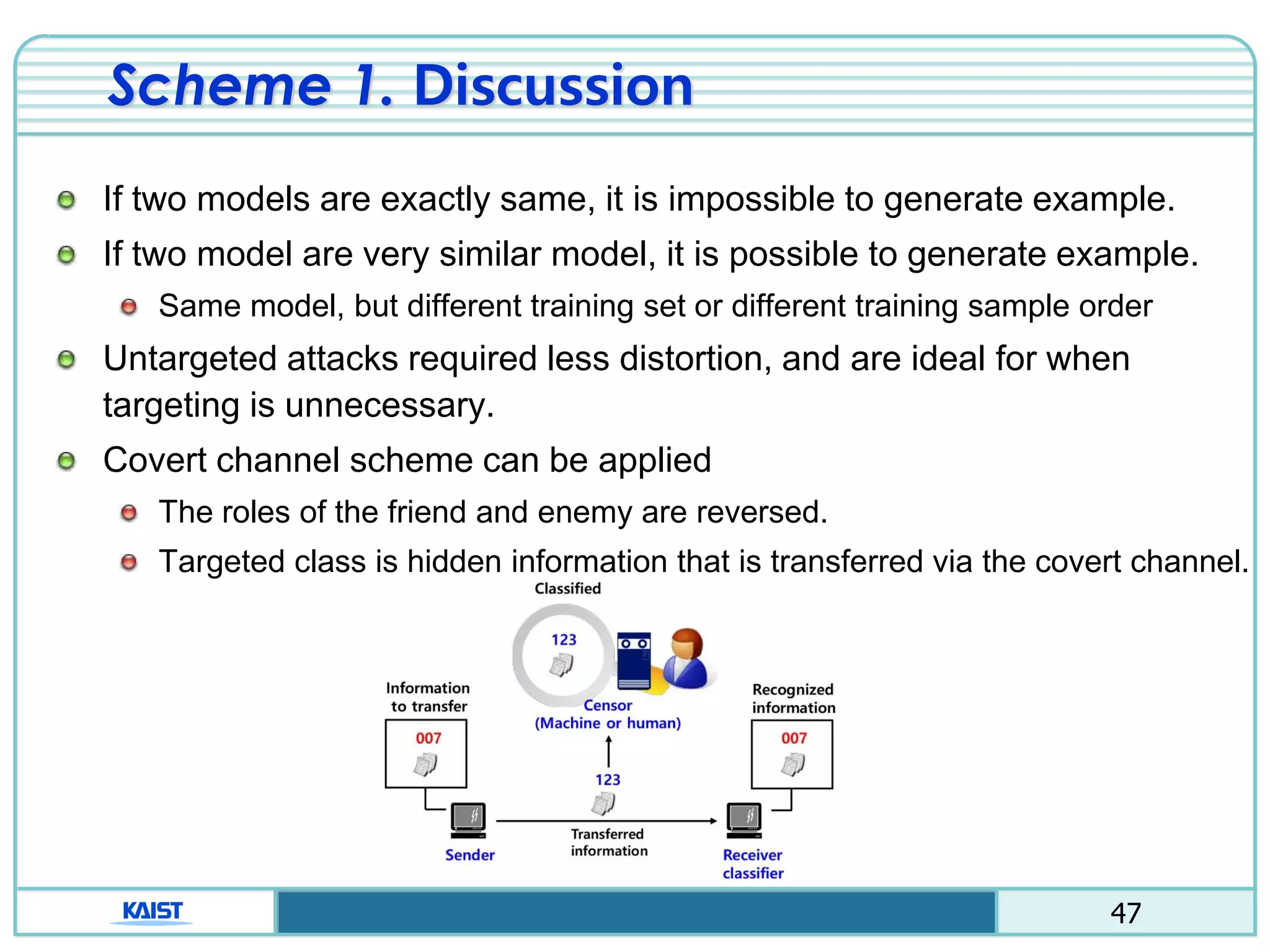

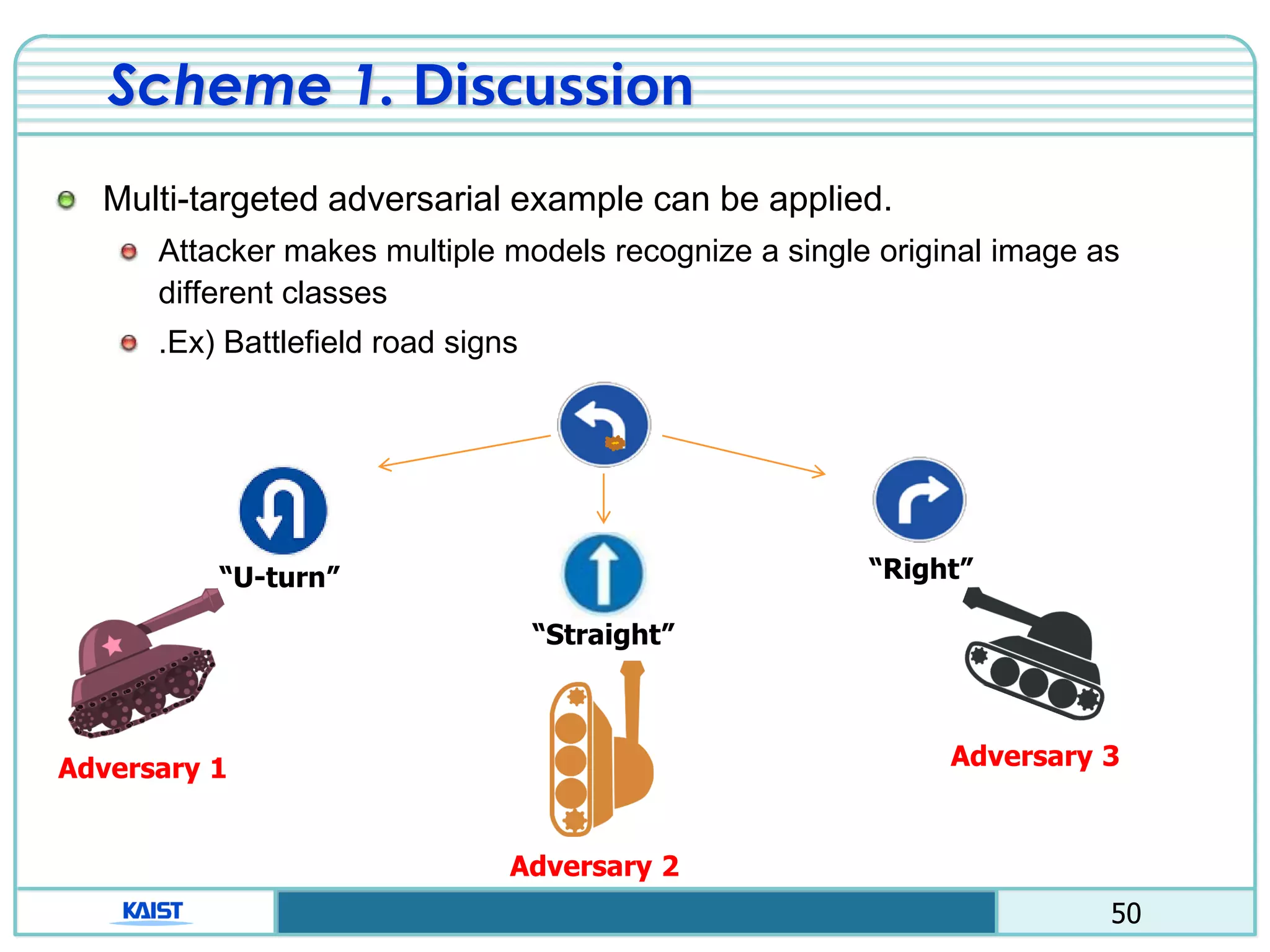
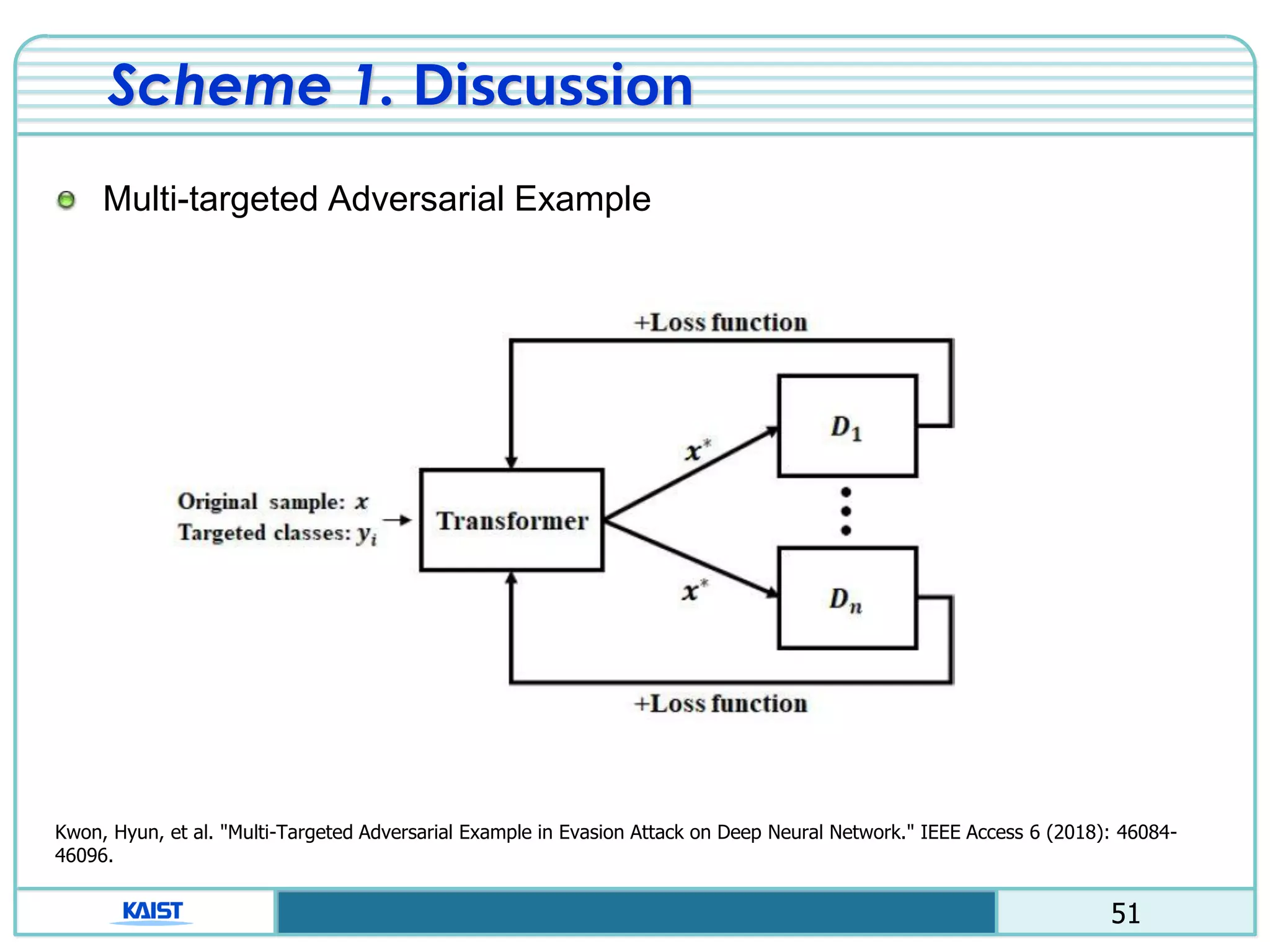



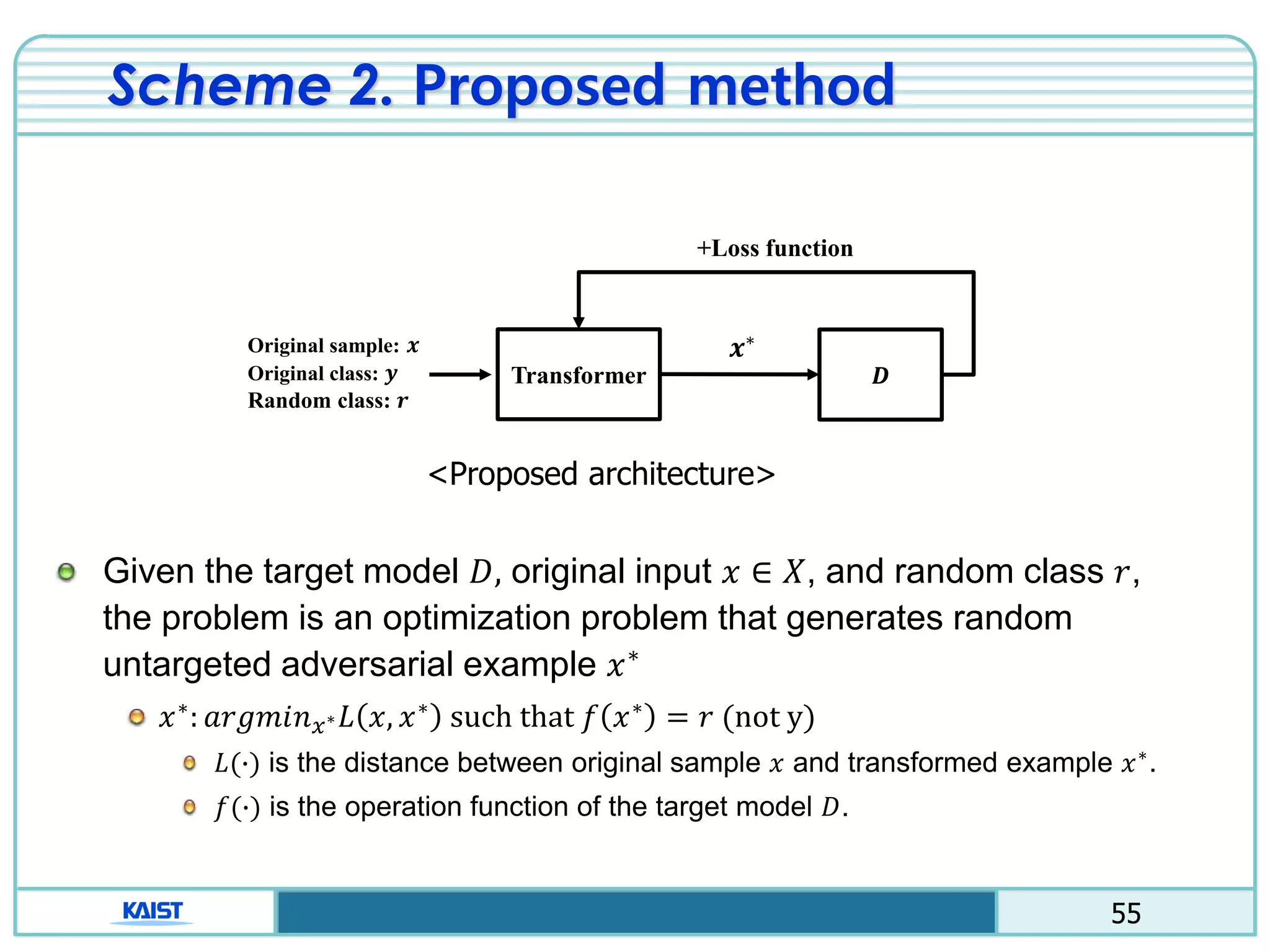
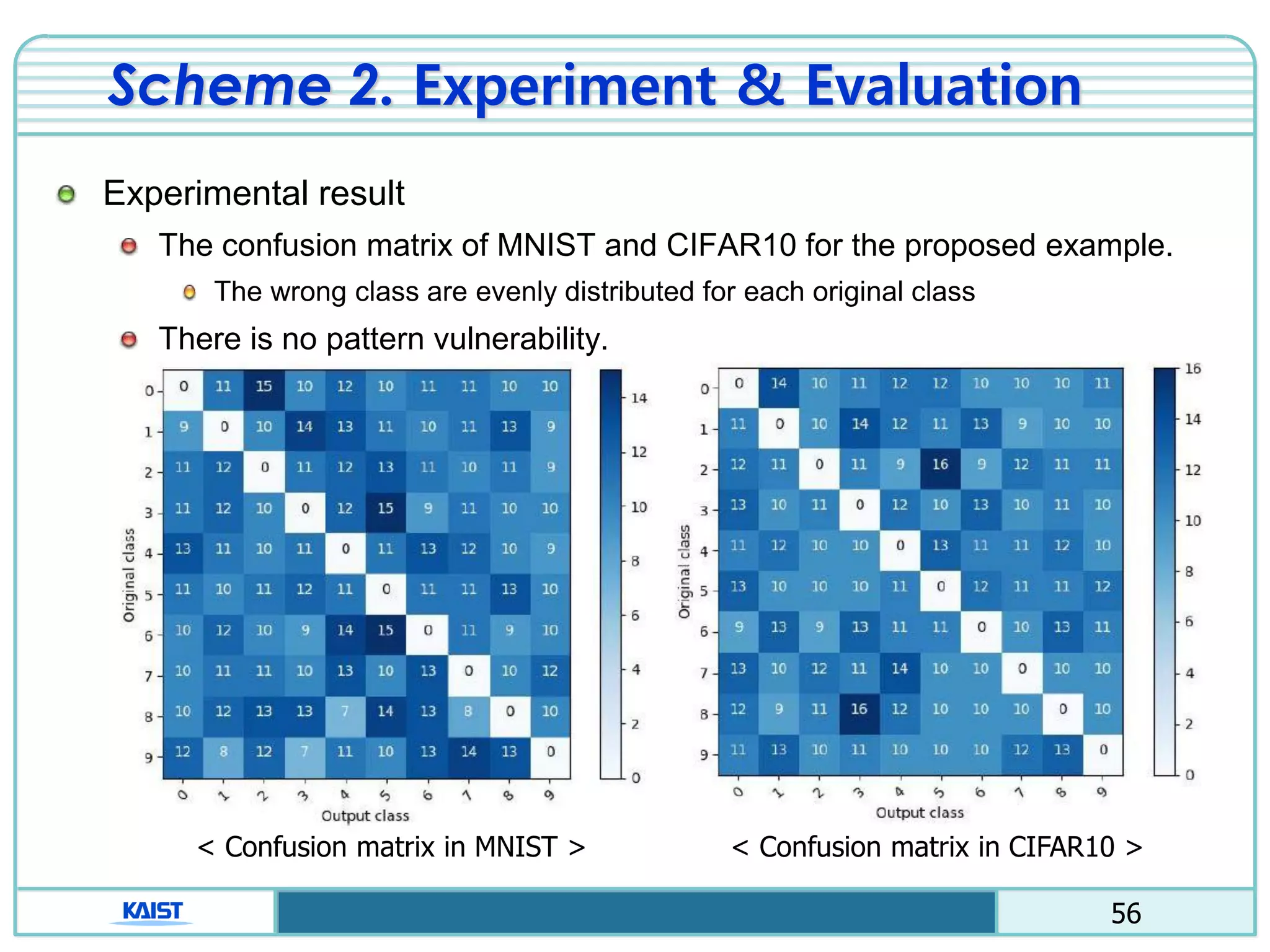





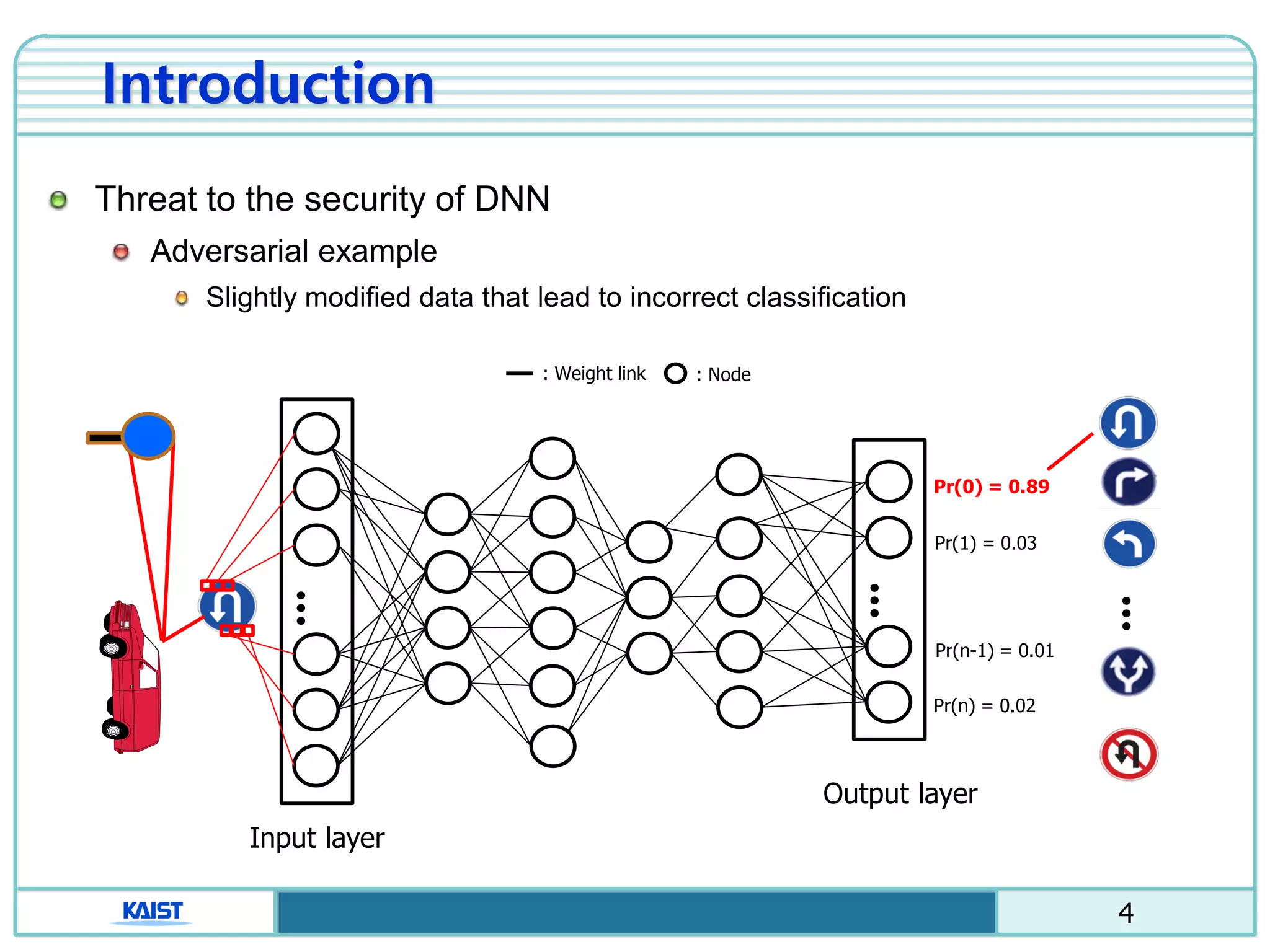
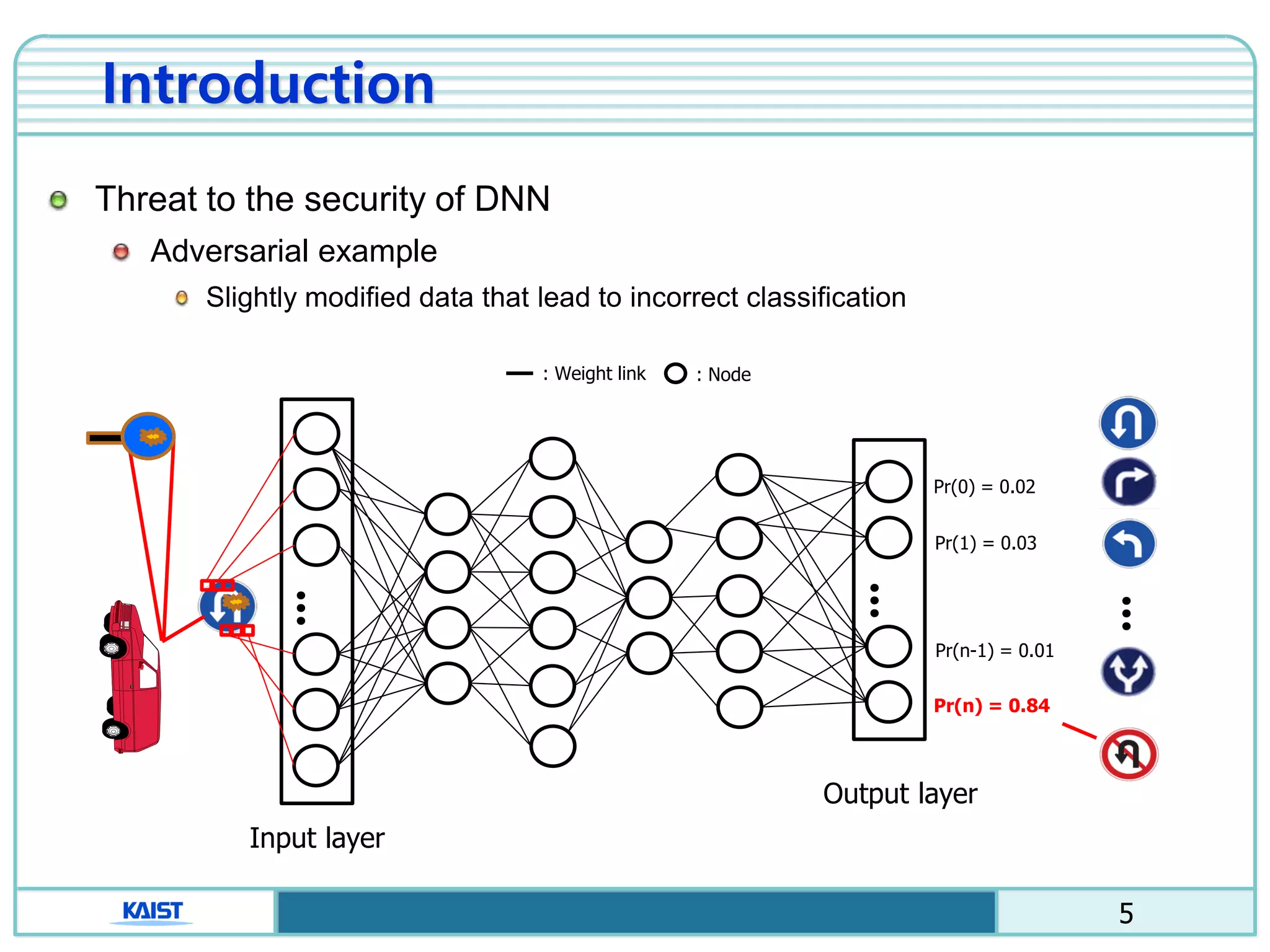
The document discusses the vulnerabilities of deep neural networks (DNNs) to adversarial examples, which are slight modifications to input data that can lead to incorrect classifications. It categorizes adversarial attacks and defenses, highlighting methods for generating adversarial examples and strategies for enhancing DNN robustness. Additionally, a specific scheme to create 'friend-safe' adversarial examples that evade enemy classifiers while being recognized by friendly classifiers is proposed and evaluated.



































![[SOTIF US Conference] Introduction to Safe ML](https://cdn.slidesharecdn.com/ss_thumbnails/20190930crdcccsafemlv1-190930165846-thumbnail.jpg?width=640&height=640&fit=bounds)































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)
















