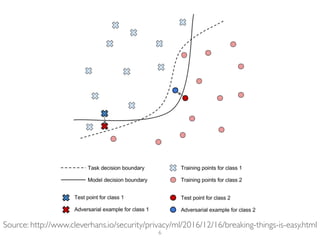
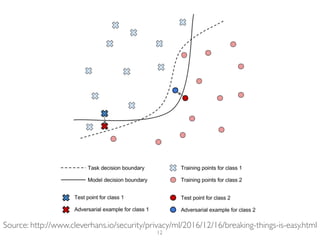
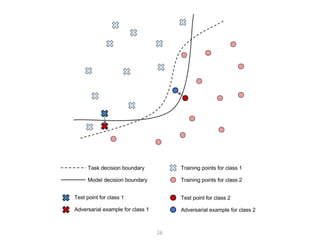
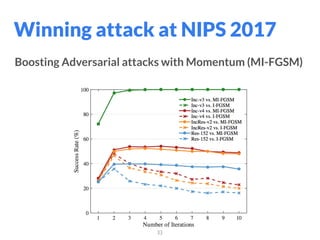
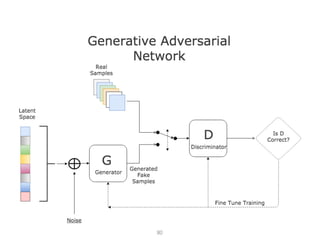
The document addresses adversarial attacks on AI systems, exploring their implications and the fragility they reveal in machine learning models. It discusses threat models, common attack methods, and proposed defenses, such as adversarial training and defensive distillation. The conclusion emphasizes the need for AI models to operate safely and confidently in real-world scenarios, especially in high-stakes applications like self-driving cars.









































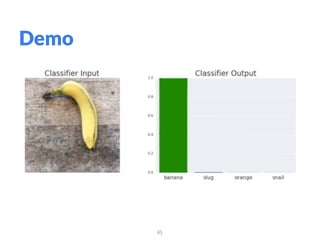
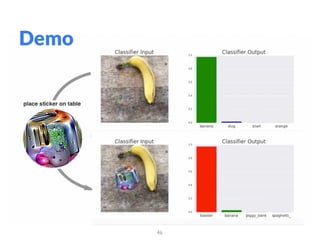






























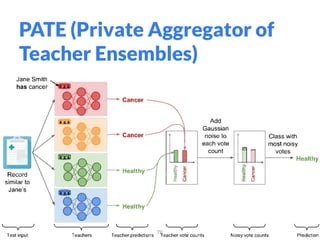



































![[DSC Europe 23] Aleksandar Tomcic - Adversarial Attacks](https://cdn.slidesharecdn.com/ss_thumbnails/aleksandartomcic-adversarialattacks-231128234241-ab5a6f11-thumbnail.jpg?width=640&height=640&fit=bounds)






































