Download to read offline


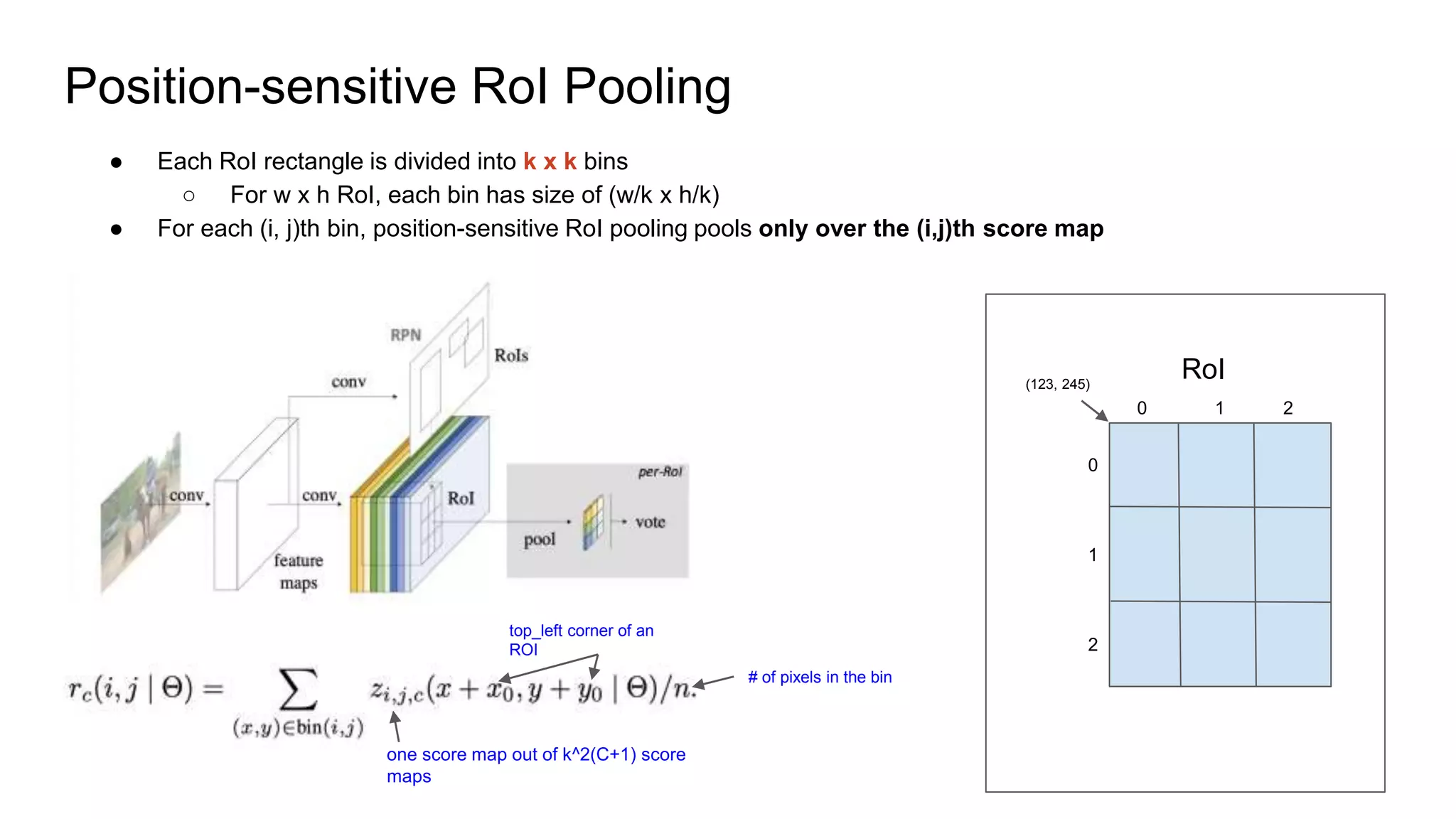
![Position-sensitive RoI Pooling
-> For each class!
For each class: [0.47, 0.77, 0.18, ….], n= C+1 classes](https://image.slidesharecdn.com/r-fcn-220514053921-881fa09f/75/R-FCN-pptx-10-2048.jpg)

![References
[1]https://arxiv.org/abs/1605.06409
[2]https://jonathan-hui.medium.com/understanding-region-based-fully-
convolutional-networks-r-fcn-for-object-detection-828316f07c99](https://image.slidesharecdn.com/r-fcn-220514053921-881fa09f/75/R-FCN-pptx-17-2048.jpg)

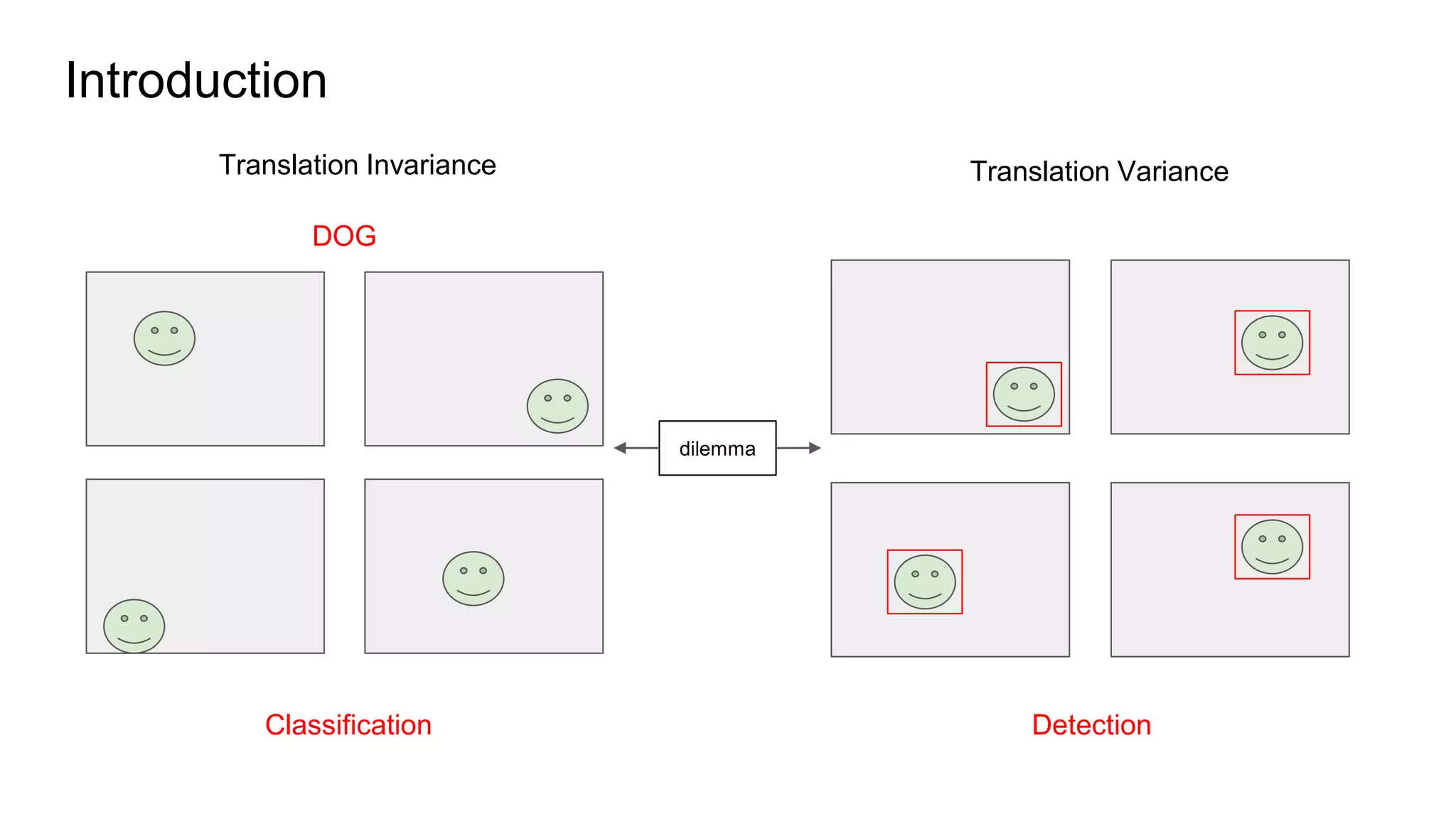
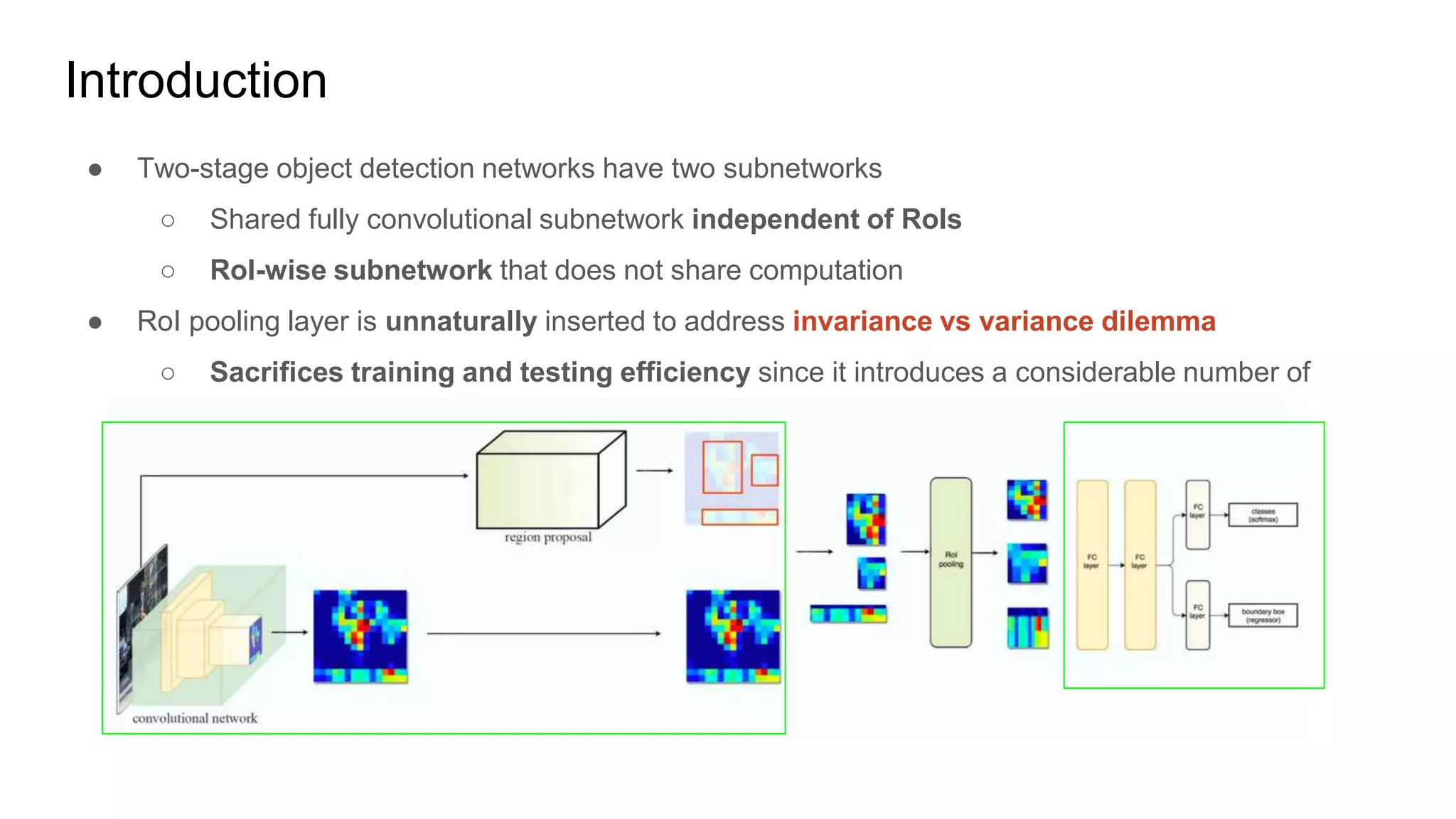
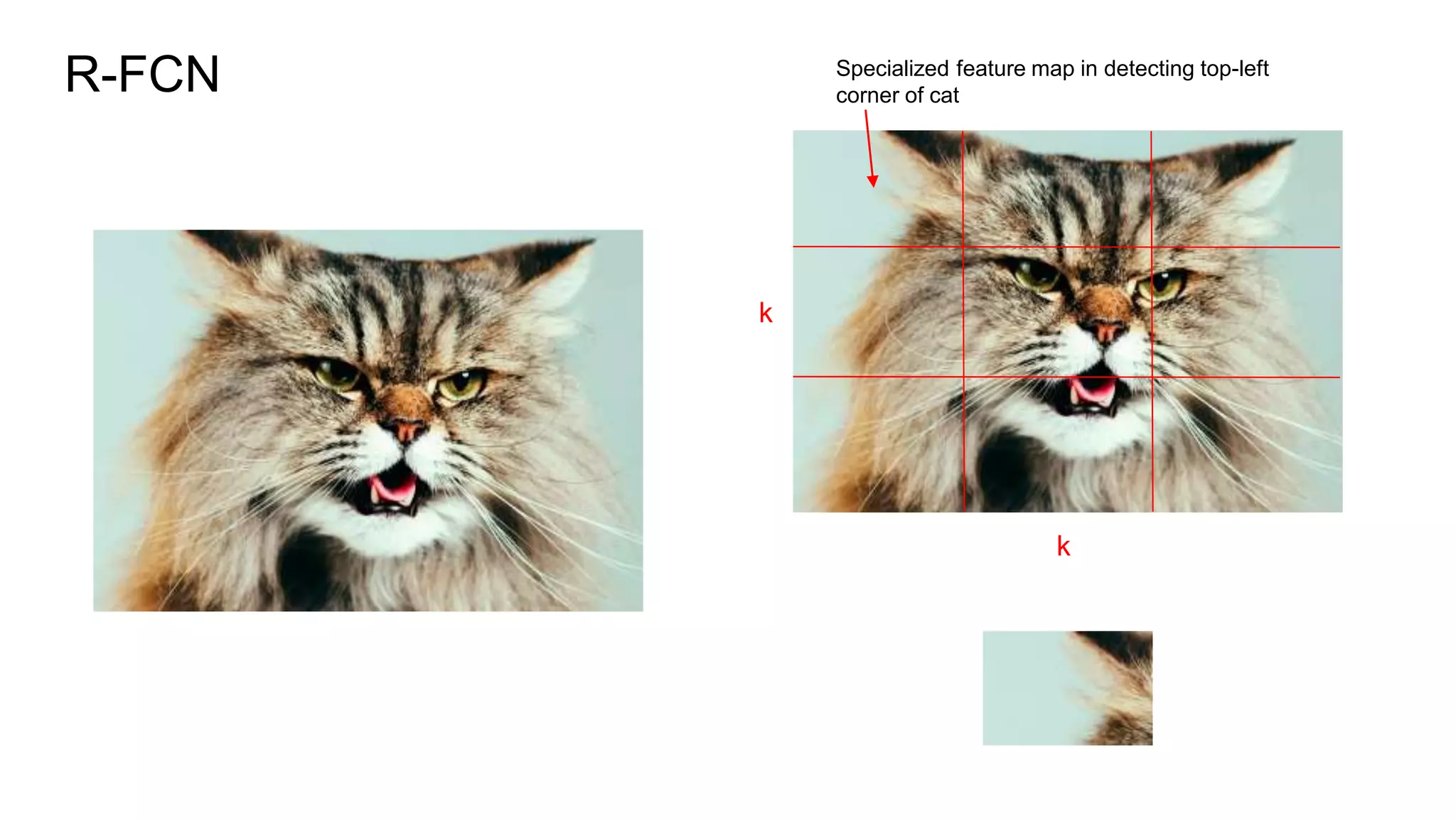
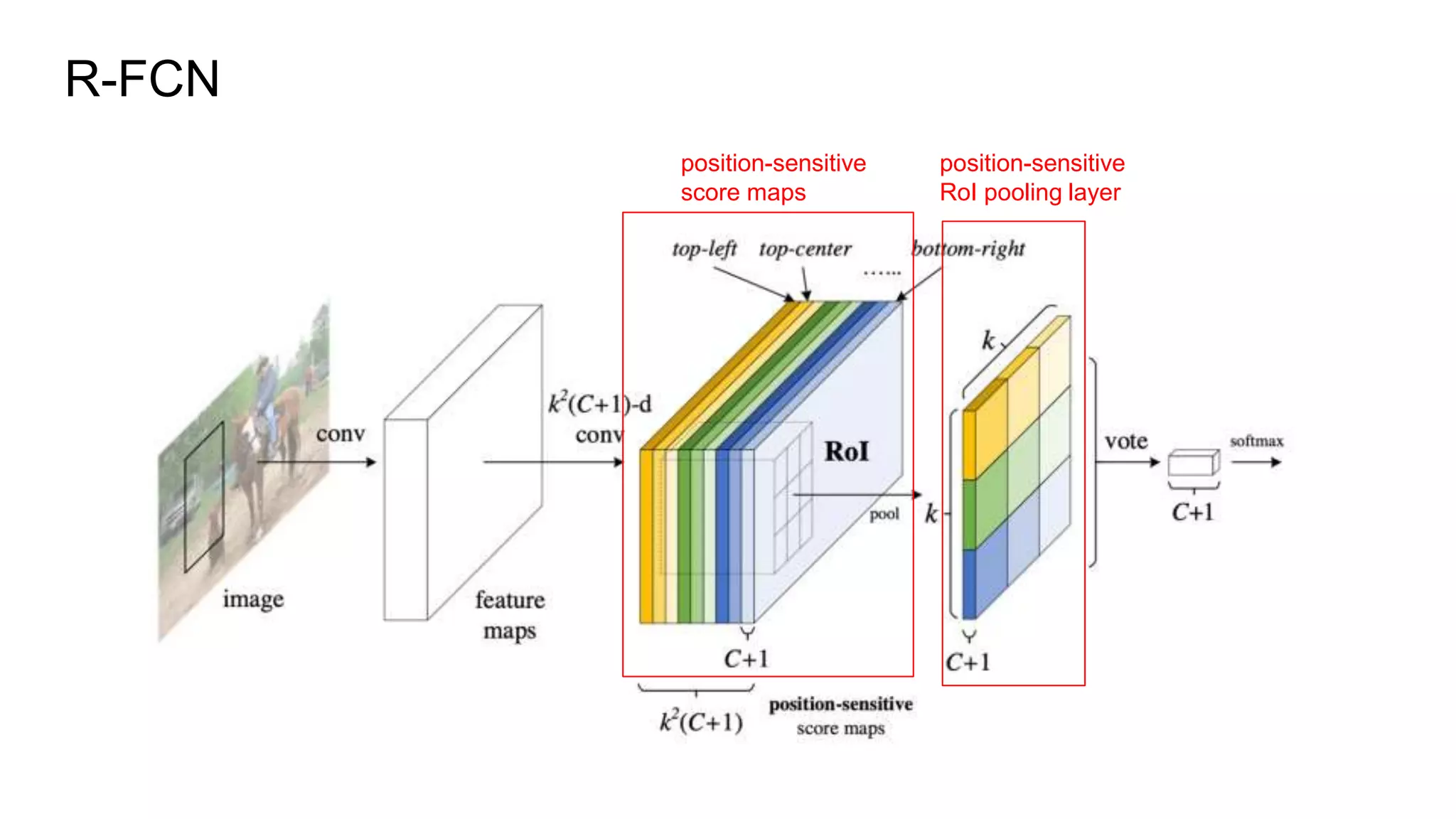
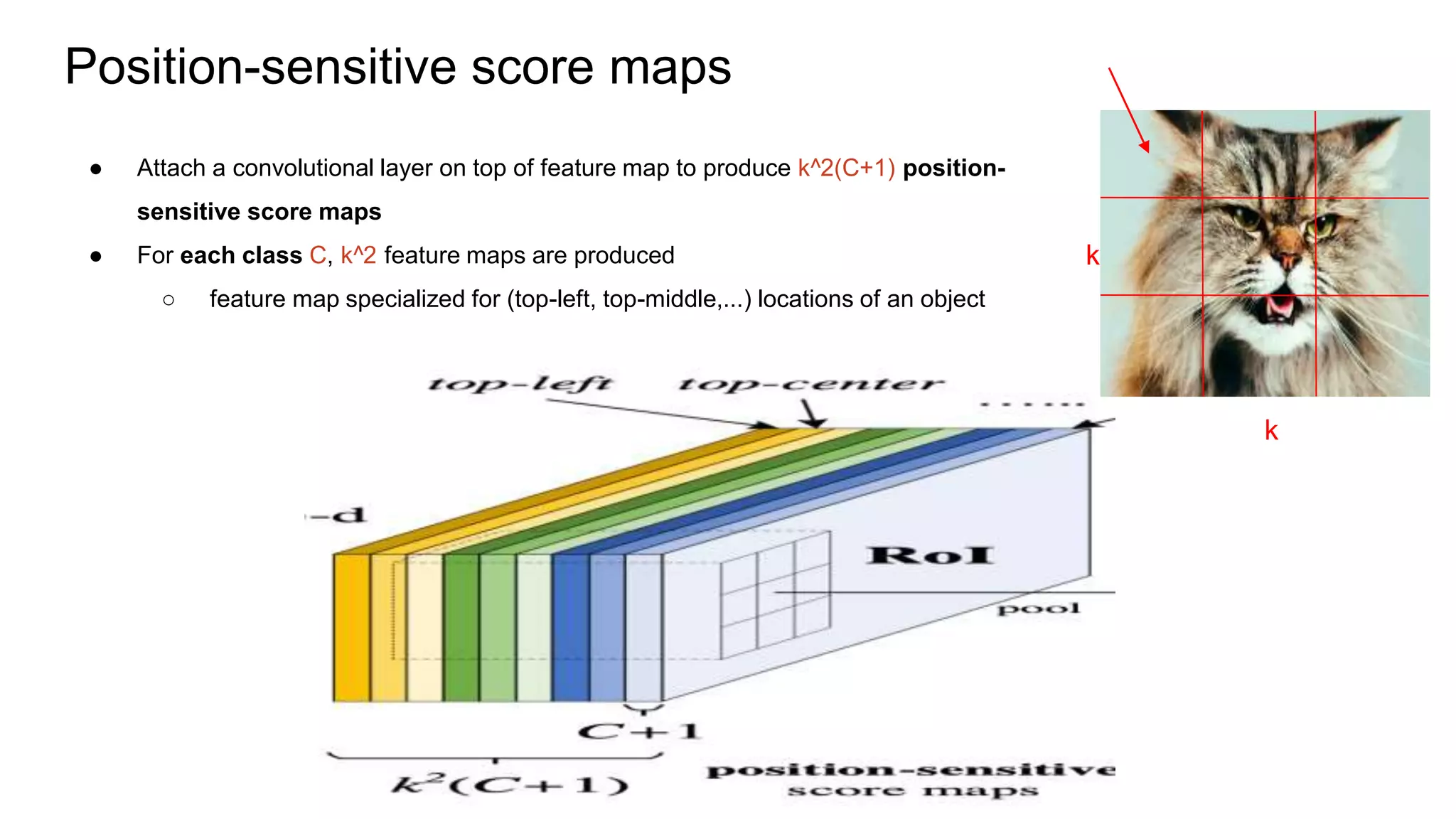
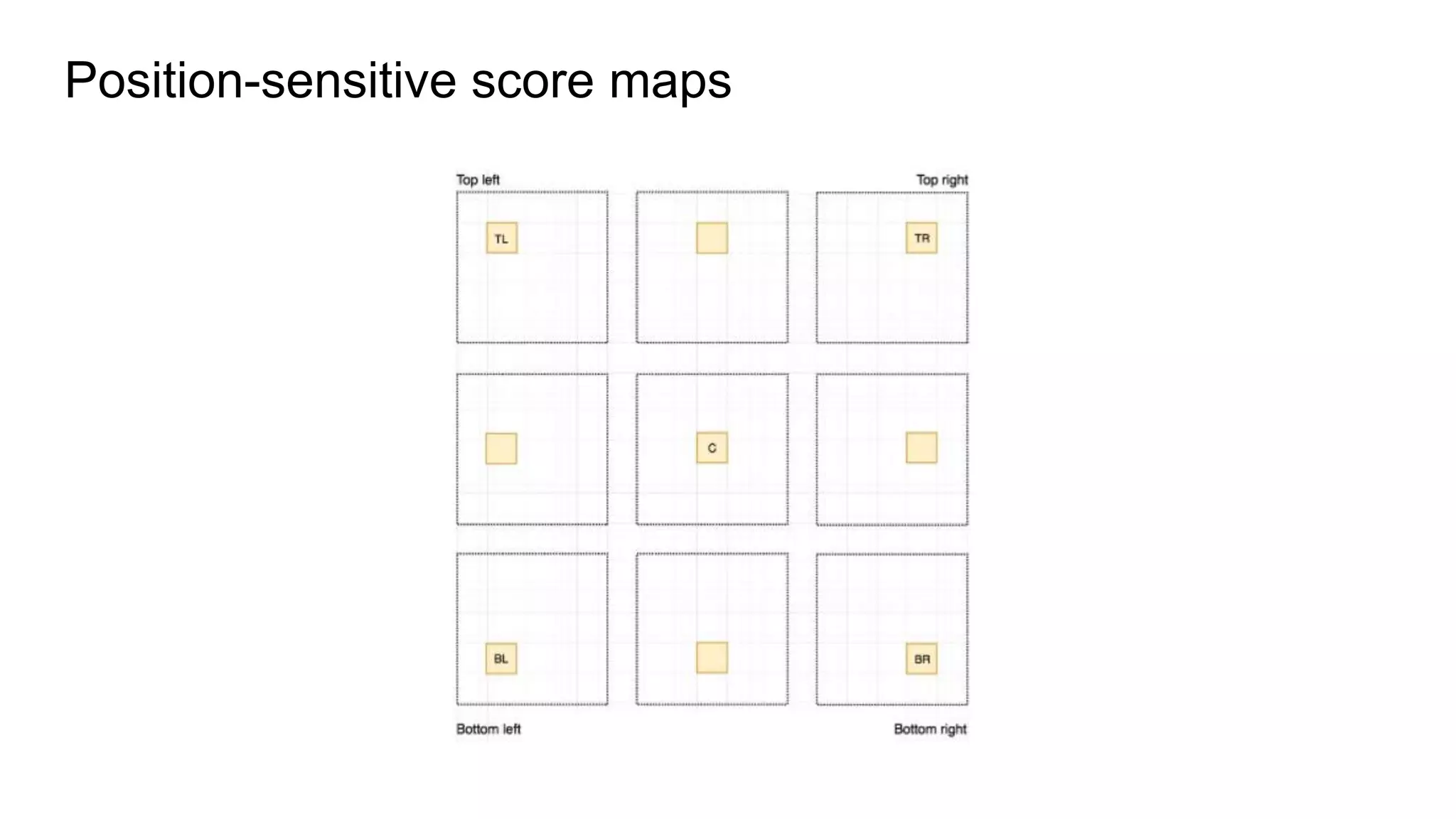
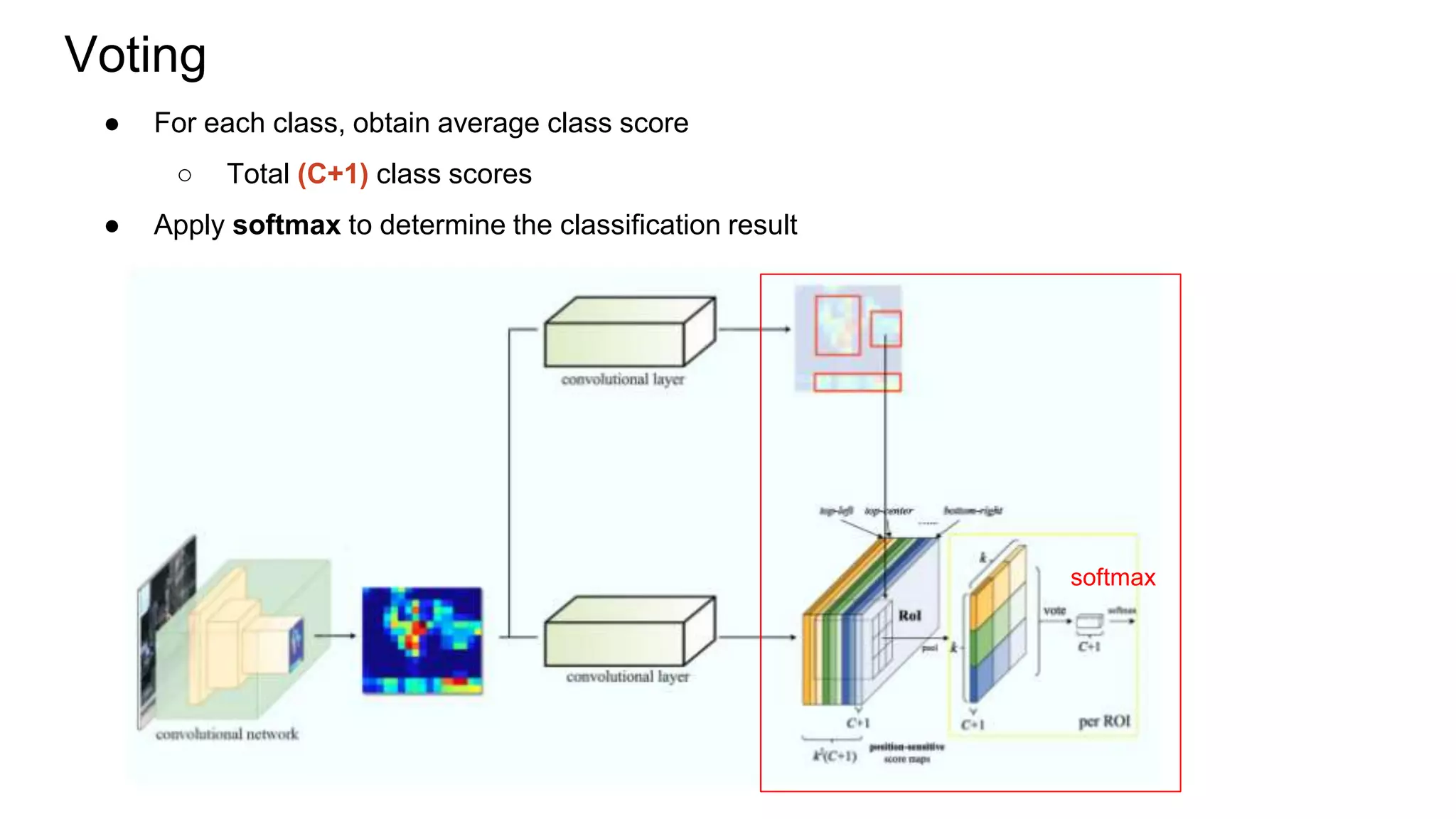
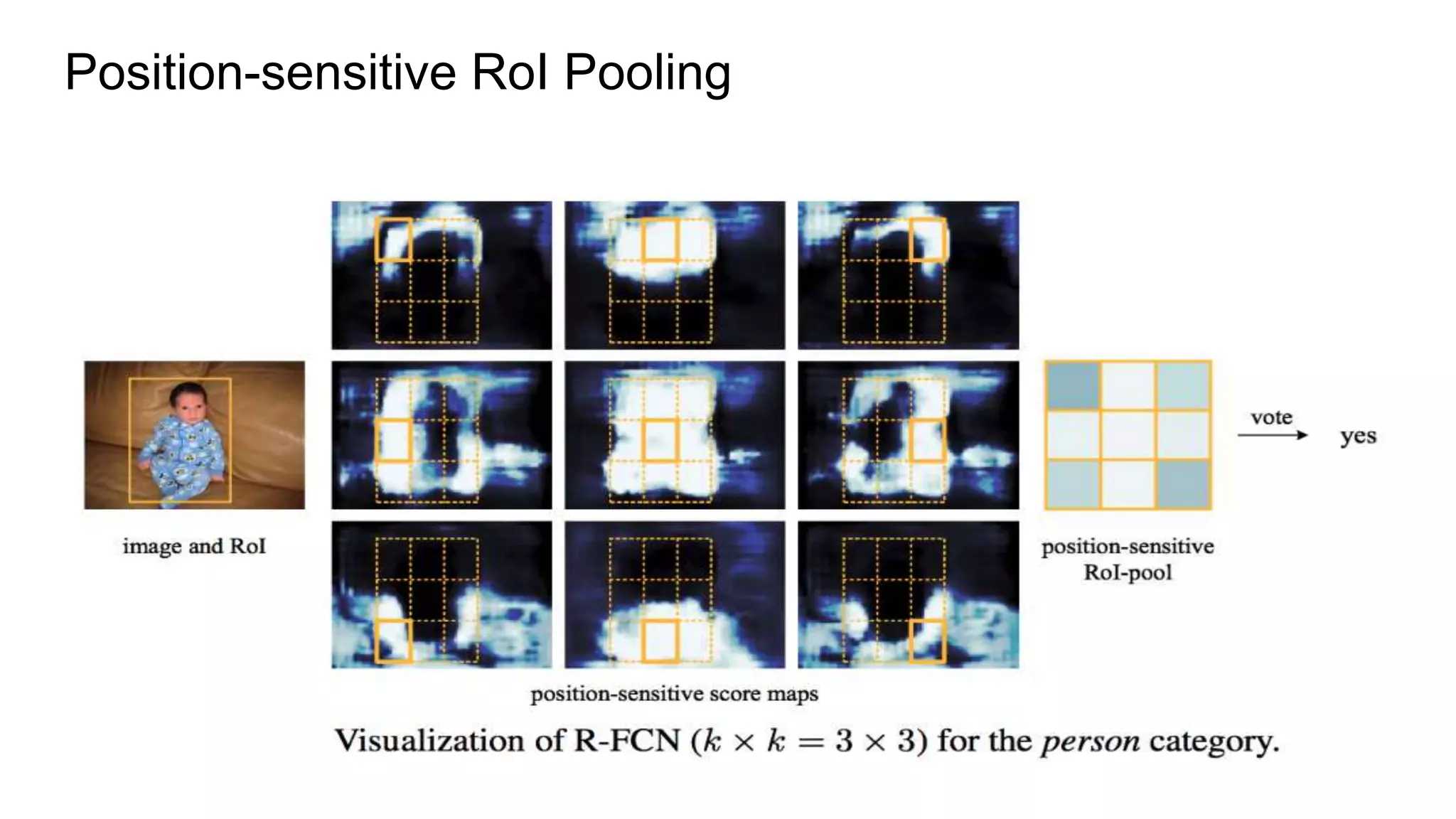
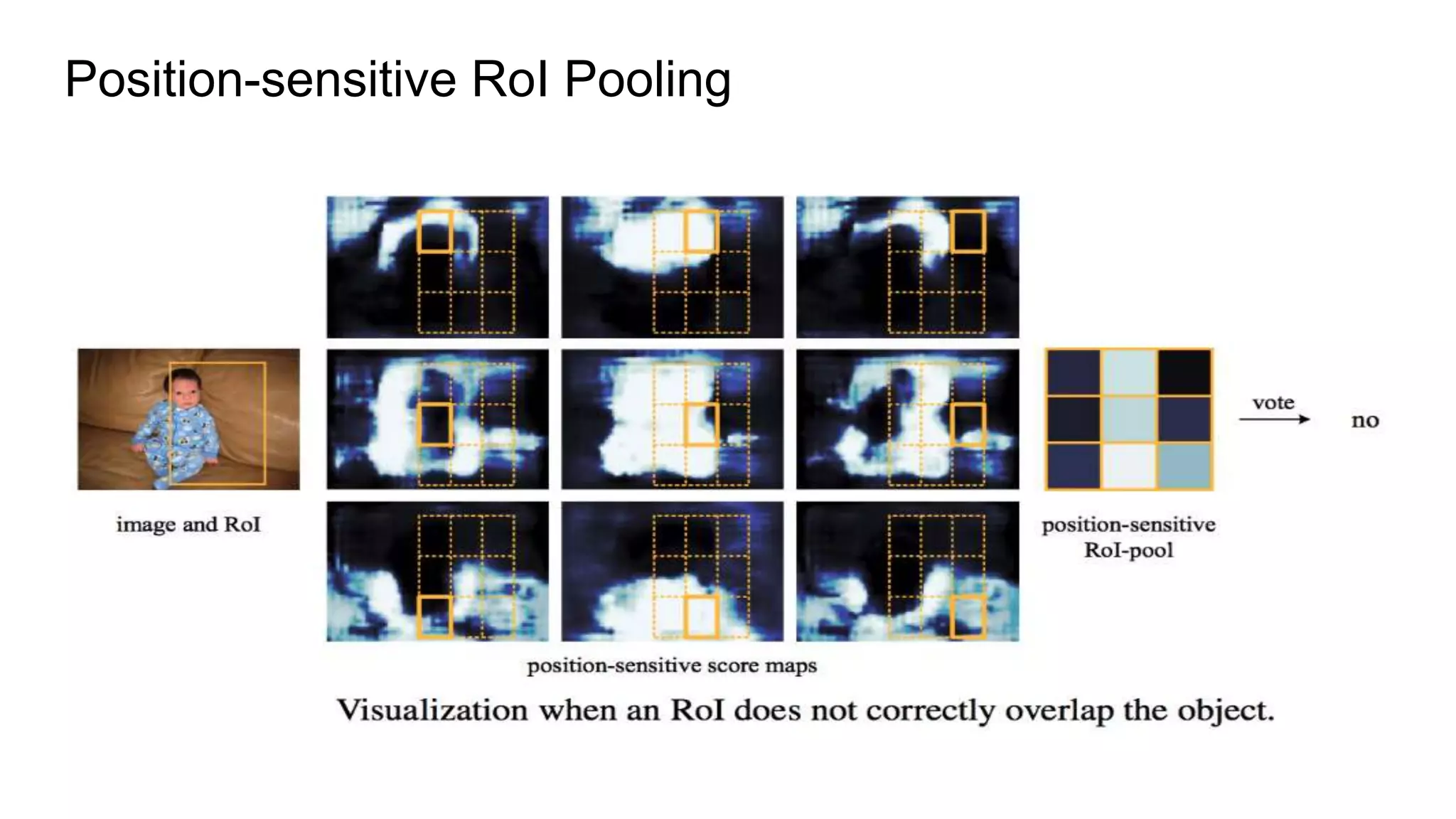
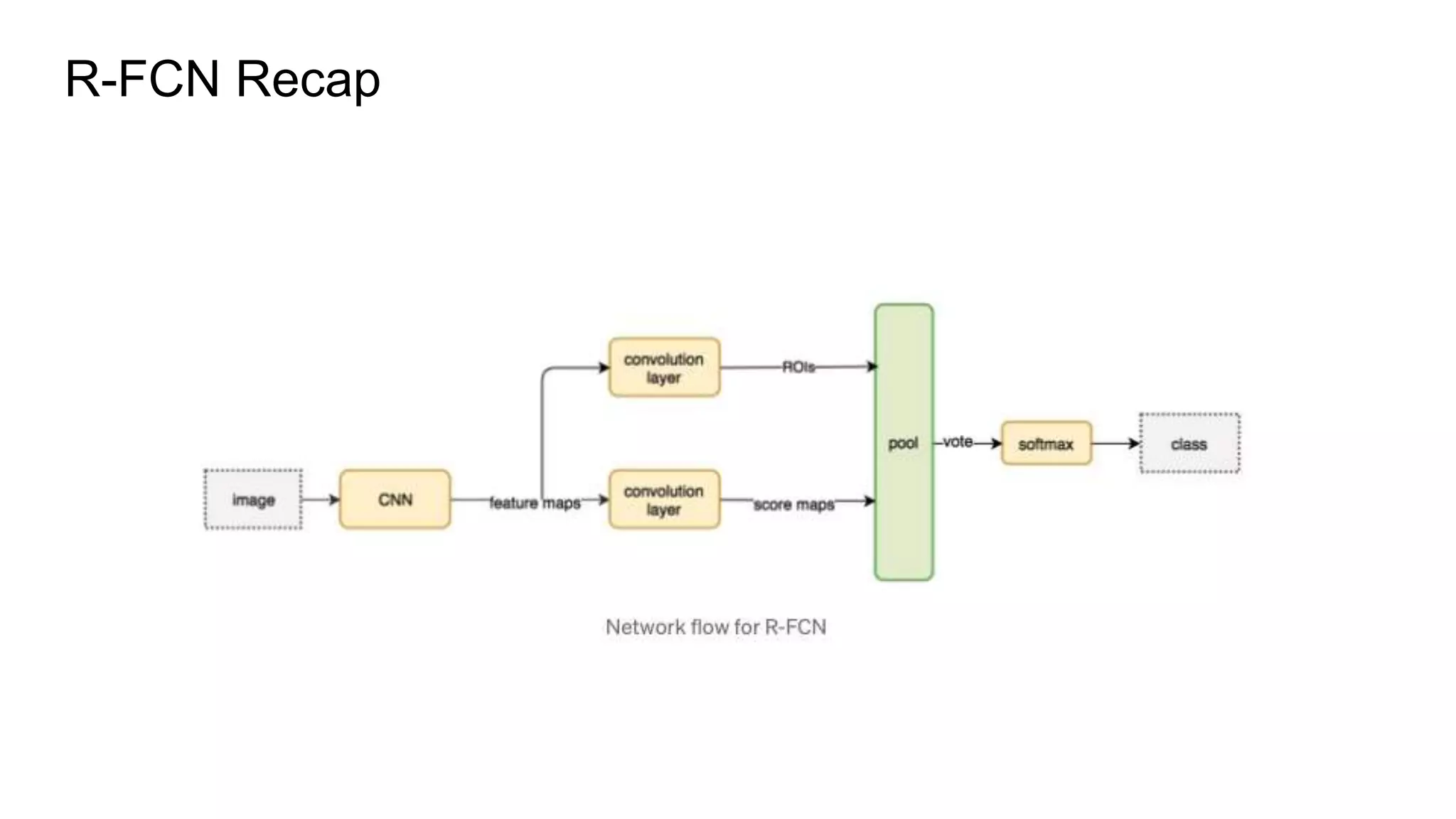
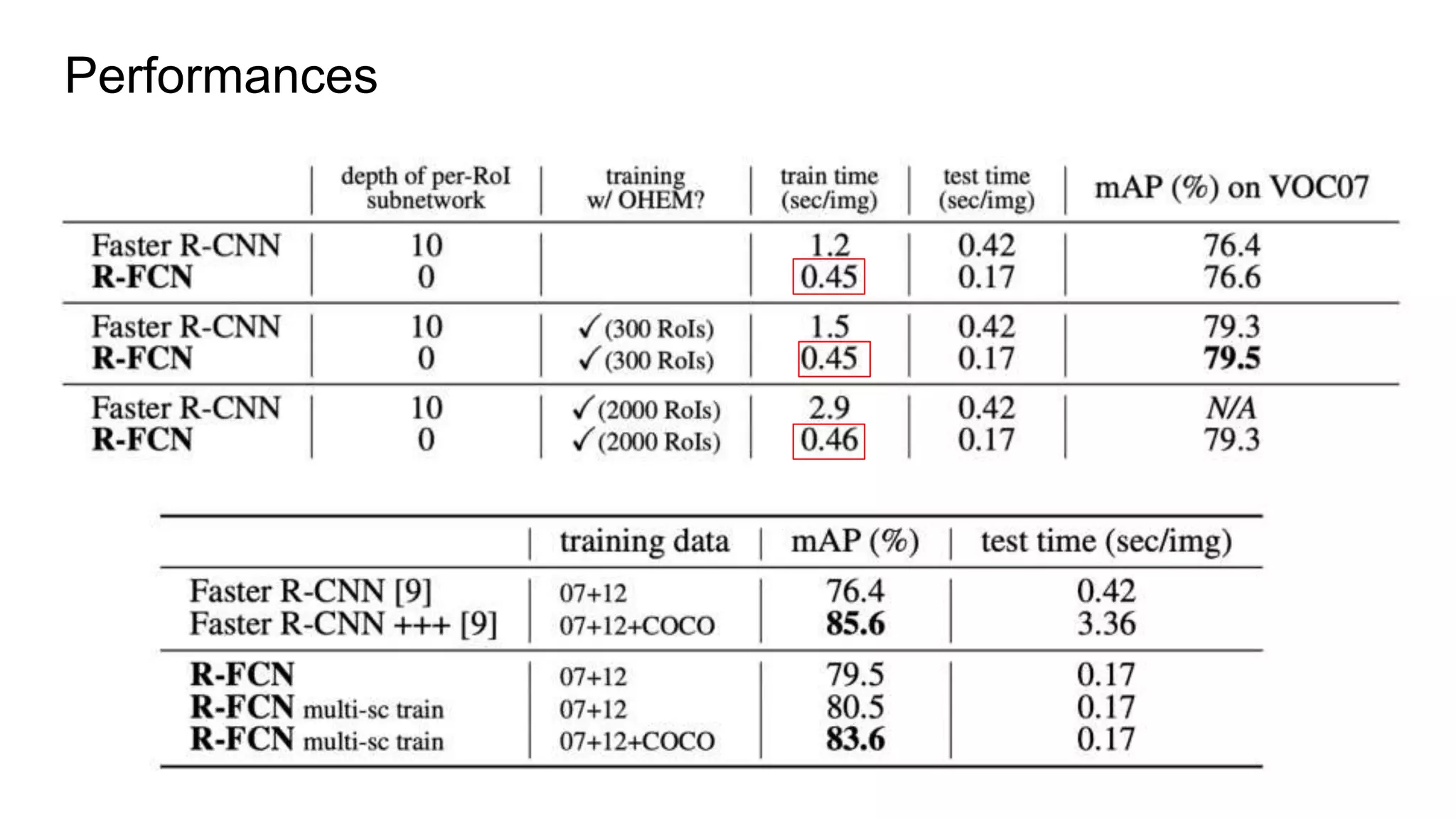
R-FCN is a two-stage object detection network that addresses the translation invariance vs variance dilemma. It uses position-sensitive score maps and RoI pooling to classify objects. Position-sensitive score maps are produced from a convolutional layer and are specialized for different locations within objects. Position-sensitive RoI pooling pools only over the relevant score map for each RoI bin. Bounding box regression is also performed using position-sensitive techniques. R-FCN achieves state-of-the-art object detection performance while being faster than Faster R-CNN since it removes unnecessary RoI pooling layers.





















































