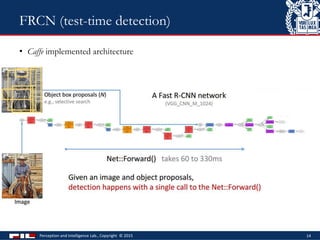
Downloaded 79 times




![• R-CNN
Rich Feature Hierarchies for Accurate Object Detection
and Semantic Segmentation [CVPR 2014]
• SPPnet
Spatial Pyramid Pooling in Deep Convolutional Networks
for Visual Recognition [ECCV 2014]
• DeepMultiBox
Scalable Object Detection using Deep Neural Networks
[CVPR 2014]
5
Previously
Lab meeting](https://image.slidesharecdn.com/150807frcn-170610061041/85/150807-Fast-R-CNN-5-320.jpg)





















![Multi-task loss 𝑳 to train network jointly for CLS and BB regressors
• Two sibling layers
1. Discrete probability distribution per RoI
• 𝑝 = (𝑝0, … , 𝑝 𝐾) over 𝐾 + 1 categories
• 𝑝 computed by a softmaxover 𝐾 + 1 categories
2. BB regressor offsets
• 𝑡 𝑘
= (𝑡 𝑥
𝑘
, 𝑡 𝑦
𝑘
, 𝑡 𝑤
𝑘
, 𝑡ℎ
𝑘
) fore each 𝐾 object classes,
indexed by 𝑘 ∈ [0, … , 𝐾]. 0 as back ground (BG).
28
Fine-tuning (Multi-task loss)](https://image.slidesharecdn.com/150807frcn-170610061041/85/150807-Fast-R-CNN-28-320.jpg)
![• Multi-task loss 𝑳 to train network jointly for CLS and BB regressors
𝑝 = (𝑝0, … , 𝑝 𝐾) over 𝐾 + 1 categories
𝑡 𝑘
= (𝑡 𝑥
𝑘
, 𝑡 𝑦
𝑘
, 𝑡 𝑤
𝑘
, 𝑡ℎ
𝑘
) fore each 𝐾 object classes, indexed by 𝑘 ∈ [0, … , 𝐾]. 0 as BG.
• 𝑘∗
: true class label
• 𝐿 𝑐𝑙𝑠 𝑝, 𝑘∗ = − log 𝑝 𝑘∗ : standard cross-entropy/log loss
• 𝐿𝑙𝑜𝑐 : true bb for class 𝑘∗
: 𝑡∗
= (𝑡 𝑥
∗
, 𝑡 𝑦
∗
, 𝑡 𝑤
∗
, 𝑡ℎ
∗
)
predicted bb: 𝑡 = (𝑡 𝑥, 𝑡 𝑦, 𝑡 𝑤, 𝑡ℎ)
29
Fine-tuning (Multi-task loss)
Iversion bracket
0 if 𝑘∗
= 0 (𝐵𝐺)
1 otherwise](https://image.slidesharecdn.com/150807frcn-170610061041/85/150807-Fast-R-CNN-29-320.jpg)













![• State-of-the-art detection result
• Detailed experiments providing insights.
• Sparse object proposals improve detector quality
• But, a bottleneck
• Decreasing the object proposal time is critical in the future.
Further more
• Faster R-CNN: Towards Real-Time Object Detection with Region Proposal
Networks Object proposal [ArXiv]
• Detection network also proposes objects
• Cost of proposals: 10ms, VGG16 runtime ~200ms including all steps
• Higher mAP, faster
• R-CNN minus R [BMVC2015]
• Fast detector without Selective Search
• No algorithms other than CNN itself
• Attempts to remove Object proposal algorithms and rely exclusively on CNN
• More integrated, simpler and faster detector
• Share full-image convolutional features with detection net
Perception and Intelligence Lab., Copyright © 2015 44
Conclusion](https://image.slidesharecdn.com/150807frcn-170610061041/85/150807-Fast-R-CNN-44-320.jpg)






Fast R-CNN is a method that improves object detection speed and accuracy over previous methods like R-CNN and SPPnet. It uses a region of interest pooling layer and multi-task loss to jointly train a convolutional neural network for classification and bounding box regression in a single stage of training. This allows the entire network to be fine-tuned end-to-end for object detection, resulting in faster training and testing compared to previous methods while achieving state-of-the-art accuracy on standard datasets. Specifically, Fast R-CNN trains 9x faster than R-CNN and runs 200x faster at test time.





















![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)