Download to read offline


![Motivations of Cascade R-CNN
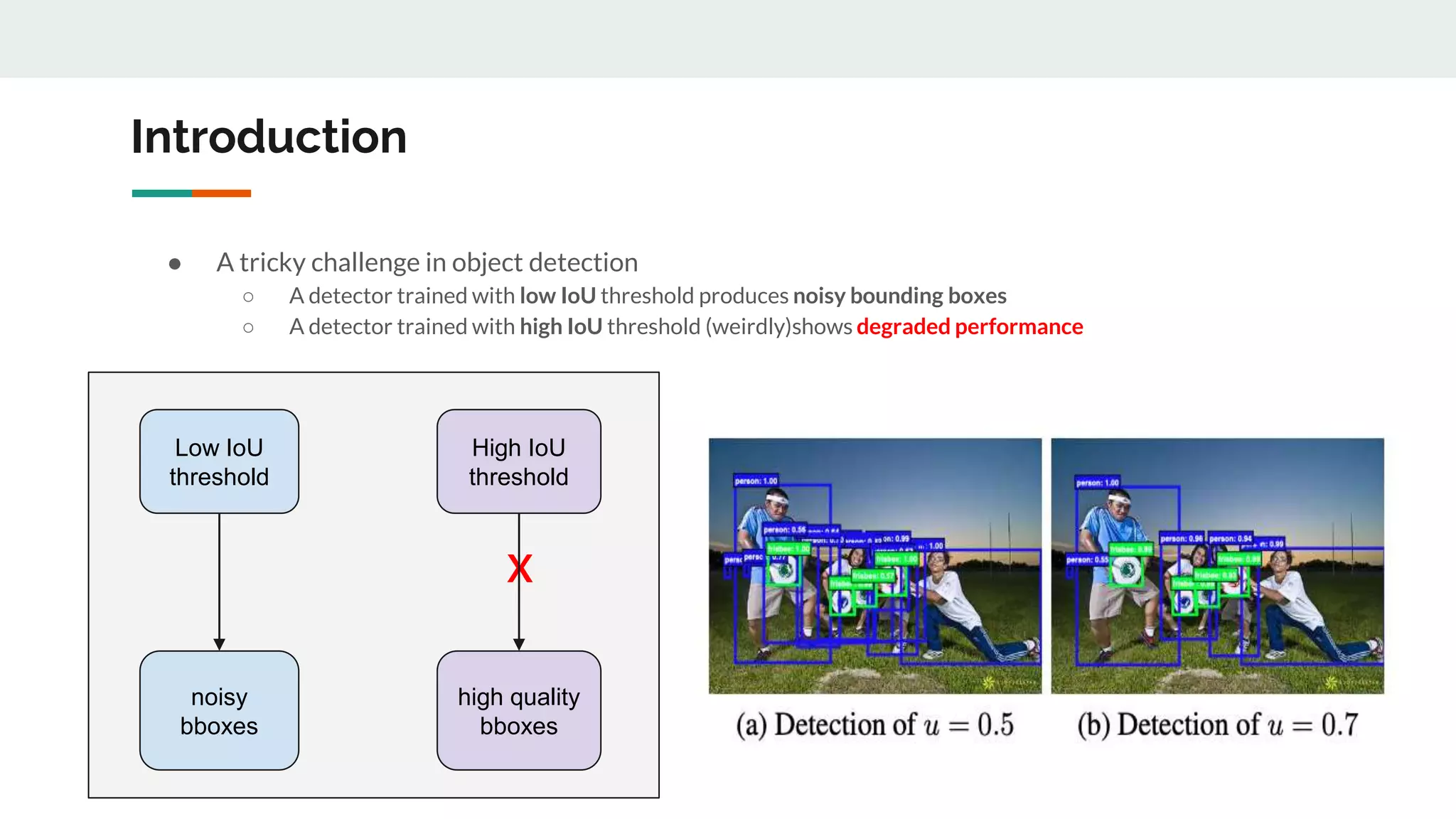
[1] A detector optimized at a single IoU level is not necessarily optimal at other levels
[2] A detector can only have high quality predictions if presented with high quality proposals (e.g. from
RPN)
(Bbox IoU with GT from RPN)
RPN](https://image.slidesharecdn.com/cascader-cnndelvingintohighqualityobjectdetection-220409050233/75/Cascade-R-CNN_-Delving-into-High-Quality-Object-Detection-pptx-4-2048.jpg)
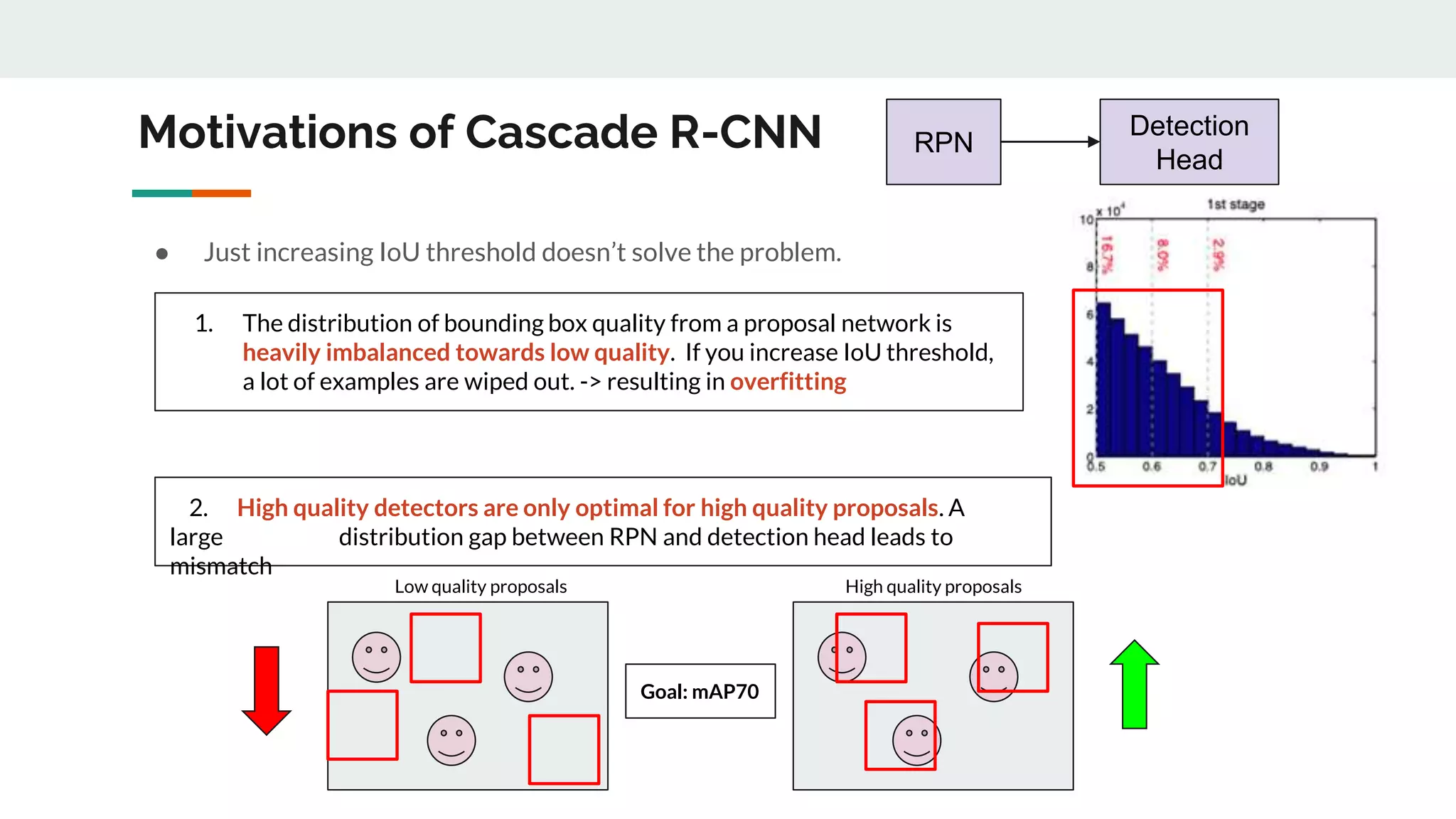

![Summary of Target Problems
[1] A detector optimized at a single IoU level is not necessarily optimal at other levels
[2] A detector can only have high quality predictions if presented with high quality proposals (e.g. from
RPN) -> large distribution gap b/w RPN and Detection Head
[3] Overfitting - Vanishing positive examples
[4] Mismatch between the IoUs for which the detector is optimal and those of the input hypotheses during
inference](https://image.slidesharecdn.com/cascader-cnndelvingintohighqualityobjectdetection-220409050233/75/Cascade-R-CNN_-Delving-into-High-Quality-Object-Detection-pptx-7-2048.jpg)
![Stage 1
(IoU 0.5)
Stage 2
(IoU 0.6)
Stage 3
(IoU 0.7)
[1] A detector optimized at a single IoU level is not necessarily optimal at other levels
[2] A detector can only have high quality predictions if presented with high quality proposals (e.g. from RPN) -> large
distribution gap b/w RPN and Detection Head
[3] Overfitting - Vanishing positive examples
[4] Mismatch between the IoUs for which the detector is optimal and those of the input hypotheses during inference](https://image.slidesharecdn.com/cascader-cnndelvingintohighqualityobjectdetection-220409050233/75/Cascade-R-CNN_-Delving-into-High-Quality-Object-Detection-pptx-8-2048.jpg)
![[1] A detector optimized at a single IoU level is not necessarily optimal at other levels
[2] A detector can only have high quality predictions if presentedwith high quality proposals (e.g. from RPN) -> large
distribution gap b/w RPN and Detection Head
[3] Overfitting- Vanishing positive examples
[4] Mismatch between the IoUs for which the detector is optimal and those of the input hypotheses during inference
Stage 1
(IoU 0.5)
Stage 2
(IoU 0.6)
Stage 3
(IoU 0.7)
resampling distribution to
higher quality](https://image.slidesharecdn.com/cascader-cnndelvingintohighqualityobjectdetection-220409050233/75/Cascade-R-CNN_-Delving-into-High-Quality-Object-Detection-pptx-9-2048.jpg)
![[1] A detector optimized at a single IoU level is not necessarily optimal at other levels
[2] A detector can only have high quality predictions if presented with high quality proposals (e.g. from RPN) -> large
distribution gap b/w RPN and Detection Head
[3] Overfitting - Vanishing positive examples
[4] Mismatch between the IoUs for which the detector is optimal and those of the input hypotheses during inference
Stage 1
(IoU 0.5)
Stage 2
(IoU 0.6)
Stage 3
(IoU 0.7)
Inference](https://image.slidesharecdn.com/cascader-cnndelvingintohighqualityobjectdetection-220409050233/75/Cascade-R-CNN_-Delving-into-High-Quality-Object-Detection-pptx-10-2048.jpg)
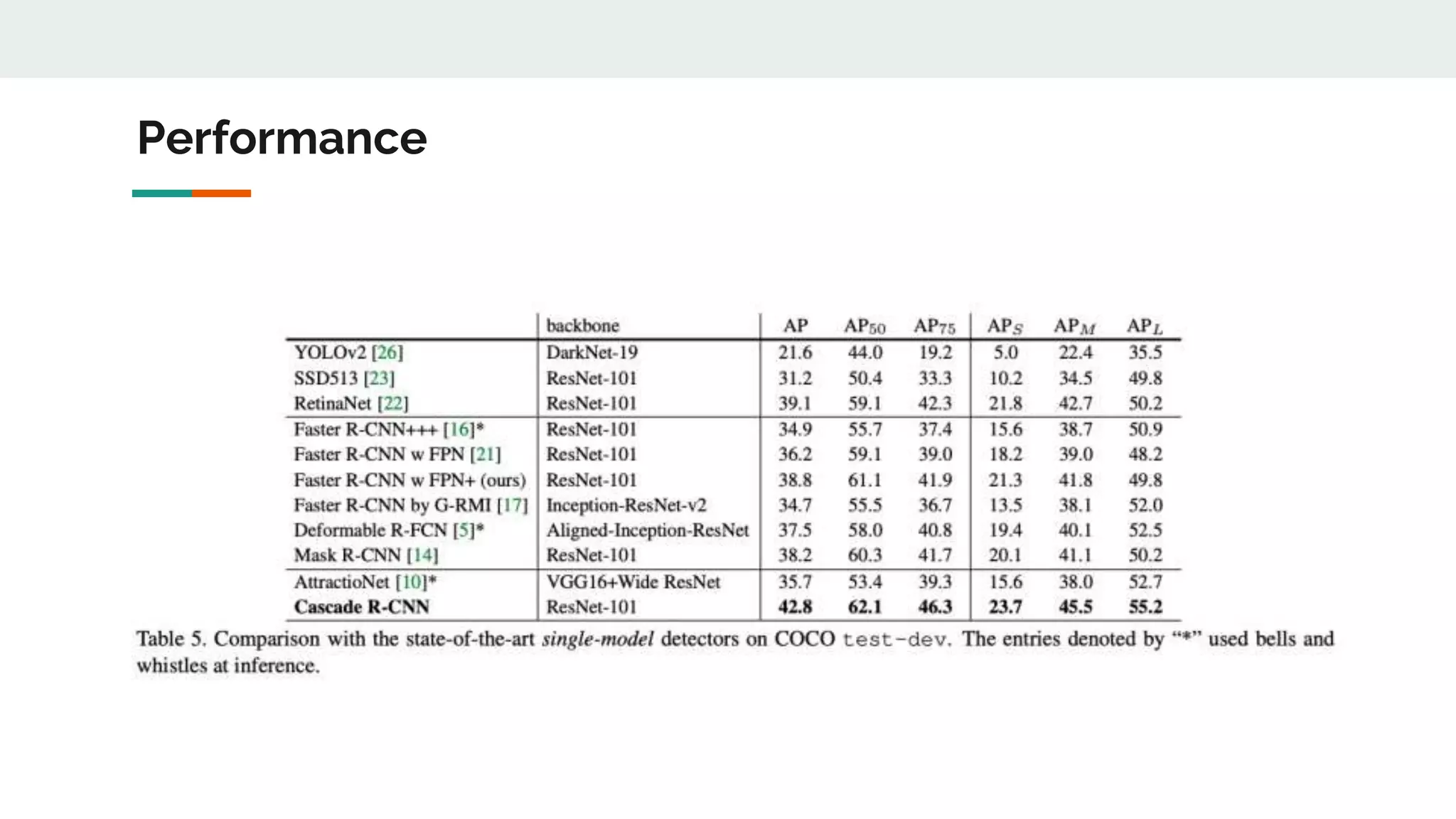


Cascade R-CNN proposes a cascade architecture to address issues with training object detectors at a single IoU threshold. It trains sequential stages with increasing IoU thresholds from 0.5 to 0.7. Each stage takes the outputs from the previous as proposals to train on, closing the quality gap between proposals and detections. This allows the detectors to specialize in a single IoU level and prevents overfitting from low positive examples at higher thresholds.




























![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)




