Downloaded 129 times
![Deep Image Retrieval:
Learning global representations for image
search
Albert Gordo, Jon Almazan, Jerome Revaud, Diane Larlus
Slides by Albert Jiménez [GDoc]
Computer Vision Reading Group (10/05/2016)1
[arXiv]](https://image.slidesharecdn.com/09deepimageretrieval-learningglobalrepresentationsforimagesearch-160510124804/85/Deep-image-retrieval-learning-global-representations-for-image-search-1-320.jpg)





![2nd Contribution
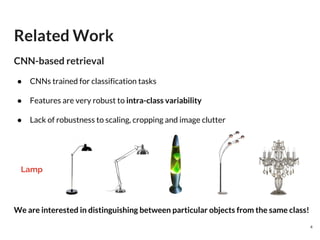
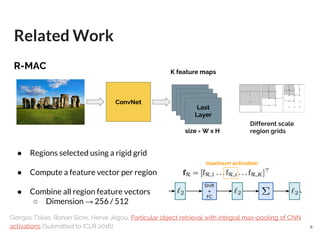
● Localize regions of interest (ROIs)
● Train a Region Proposal Network with bounding boxes (Similar Fast R-CNN,
[arXiv])
In R-MAC → Rigid grid
Replace
Region Proposal Network
10](https://image.slidesharecdn.com/09deepimageretrieval-learningglobalrepresentationsforimagesearch-160510124804/85/Deep-image-retrieval-learning-global-representations-for-image-search-10-320.jpg)

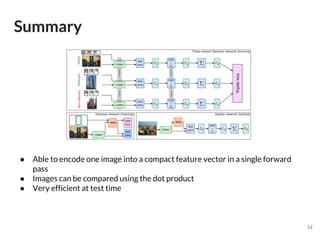




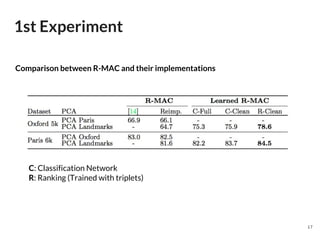
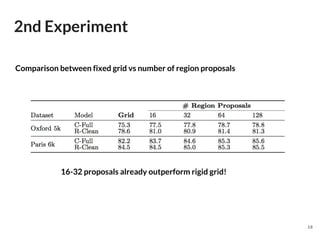

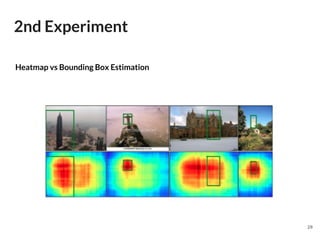

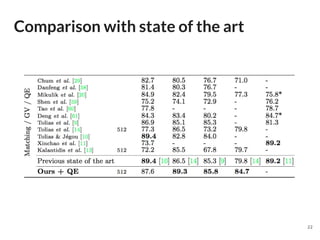





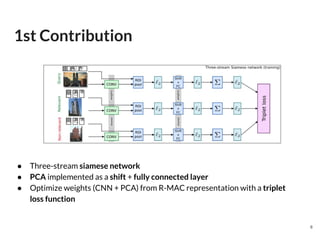
The document discusses a novel approach to deep image retrieval using a three-stream siamese network and regional maximum activation of convolutions (r-mac) to effectively encode images into compact feature vectors. It highlights the methodology employed, including the use of triplet loss for optimization, and demonstrates the system's efficiency through experiments using various datasets. The study concludes that this technique offers scalability and improved performance in image retrieval tasks compared to prior methods.




































![[NS][Lab_Seminar_241118]Relation Matters: Foreground-aware Graph-based Relati...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241118fgrr-241118111529-1ff1aba4-thumbnail.jpg?width=640&height=640&fit=bounds)

















































