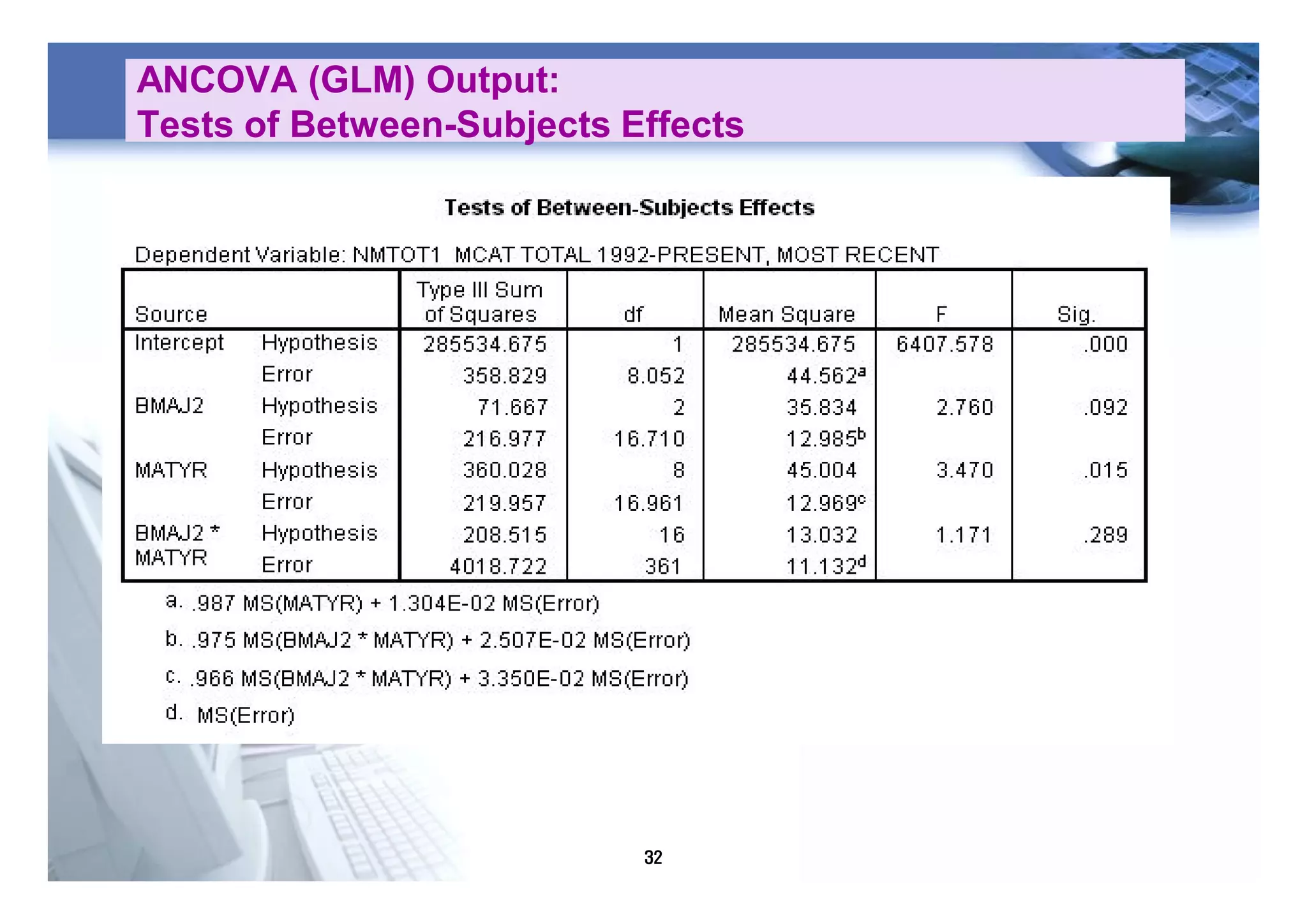
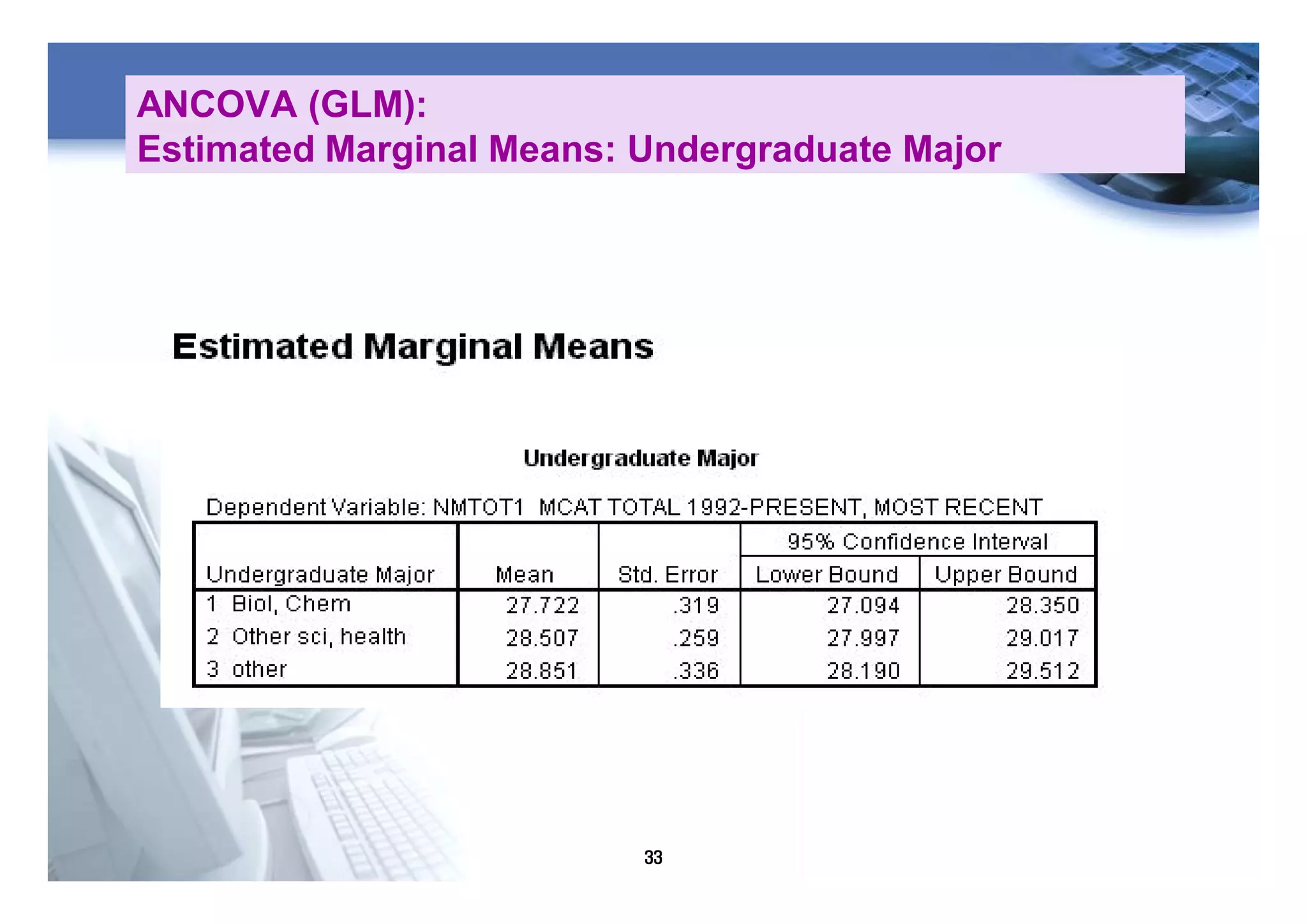
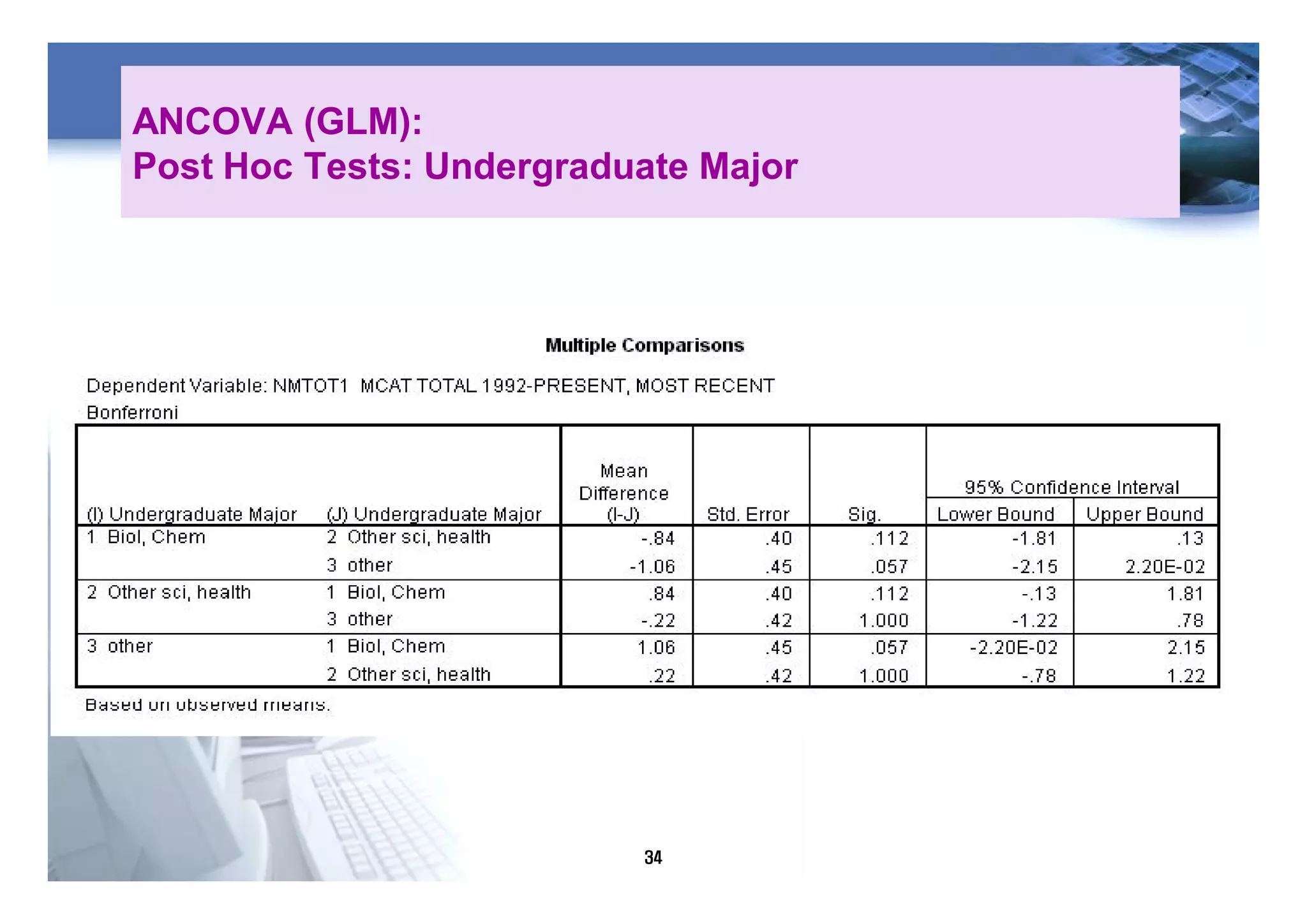
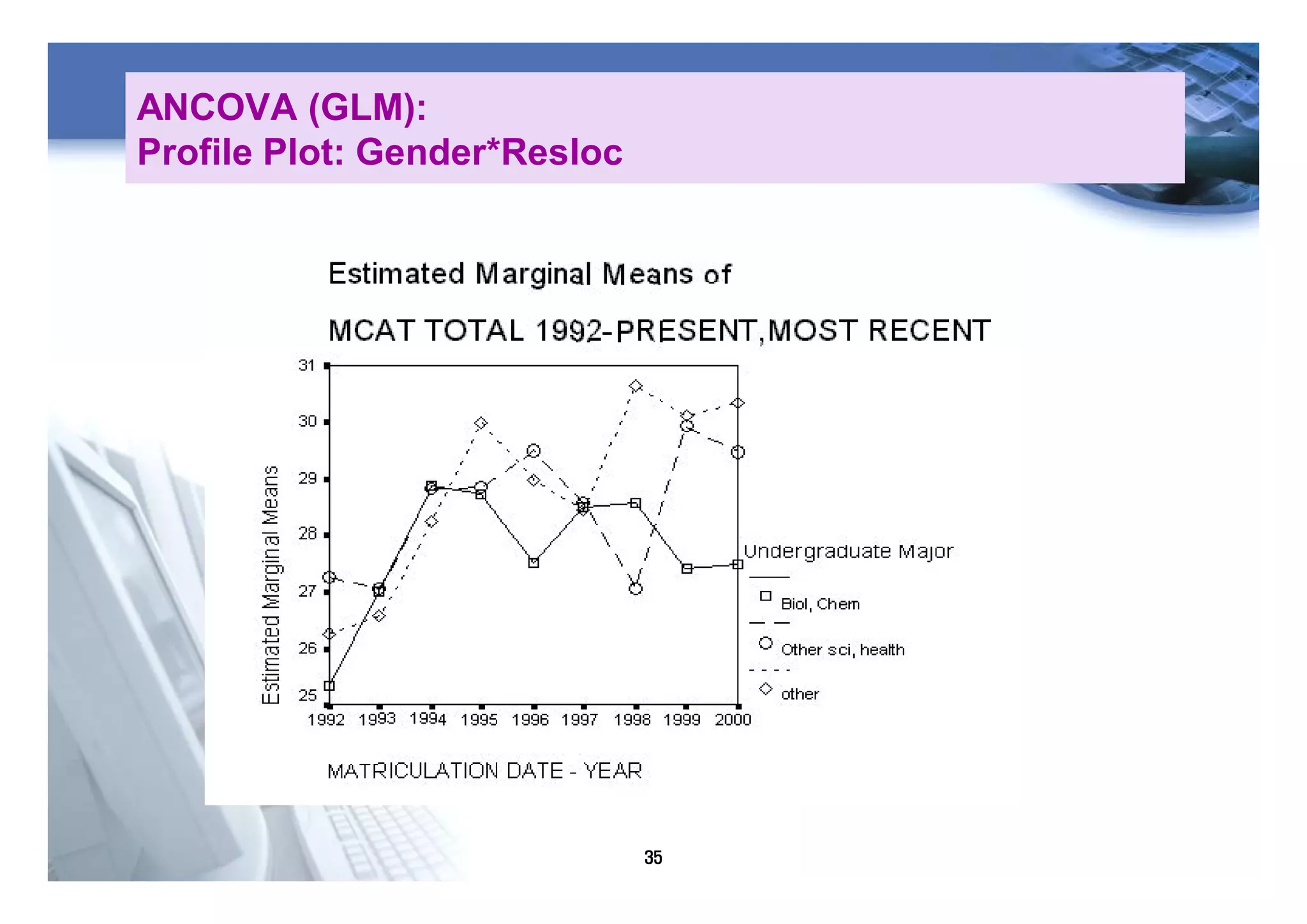
1) The document discusses various statistical methods including one-way ANOVA, repeated measures ANOVA, and ANCOVA.
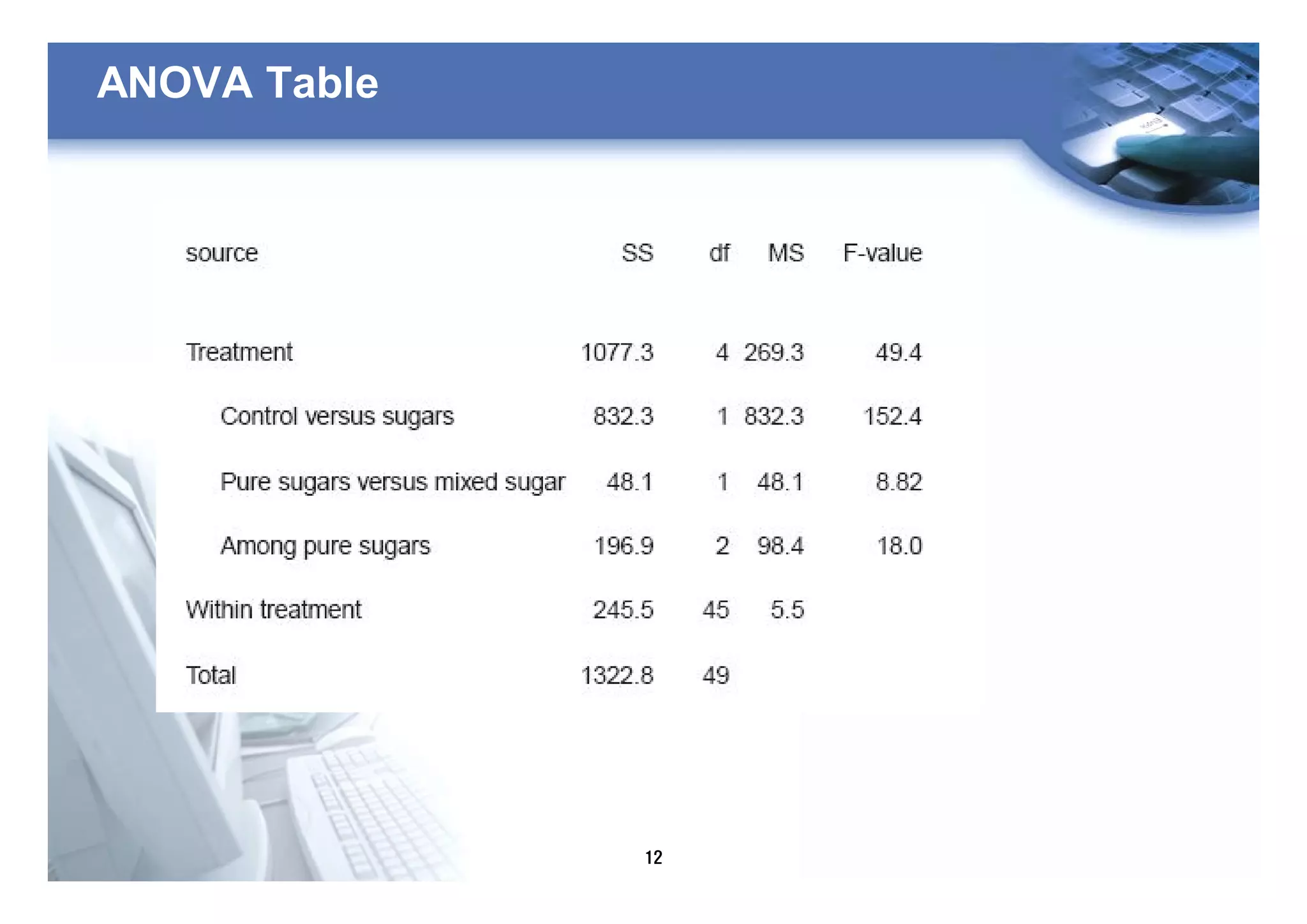
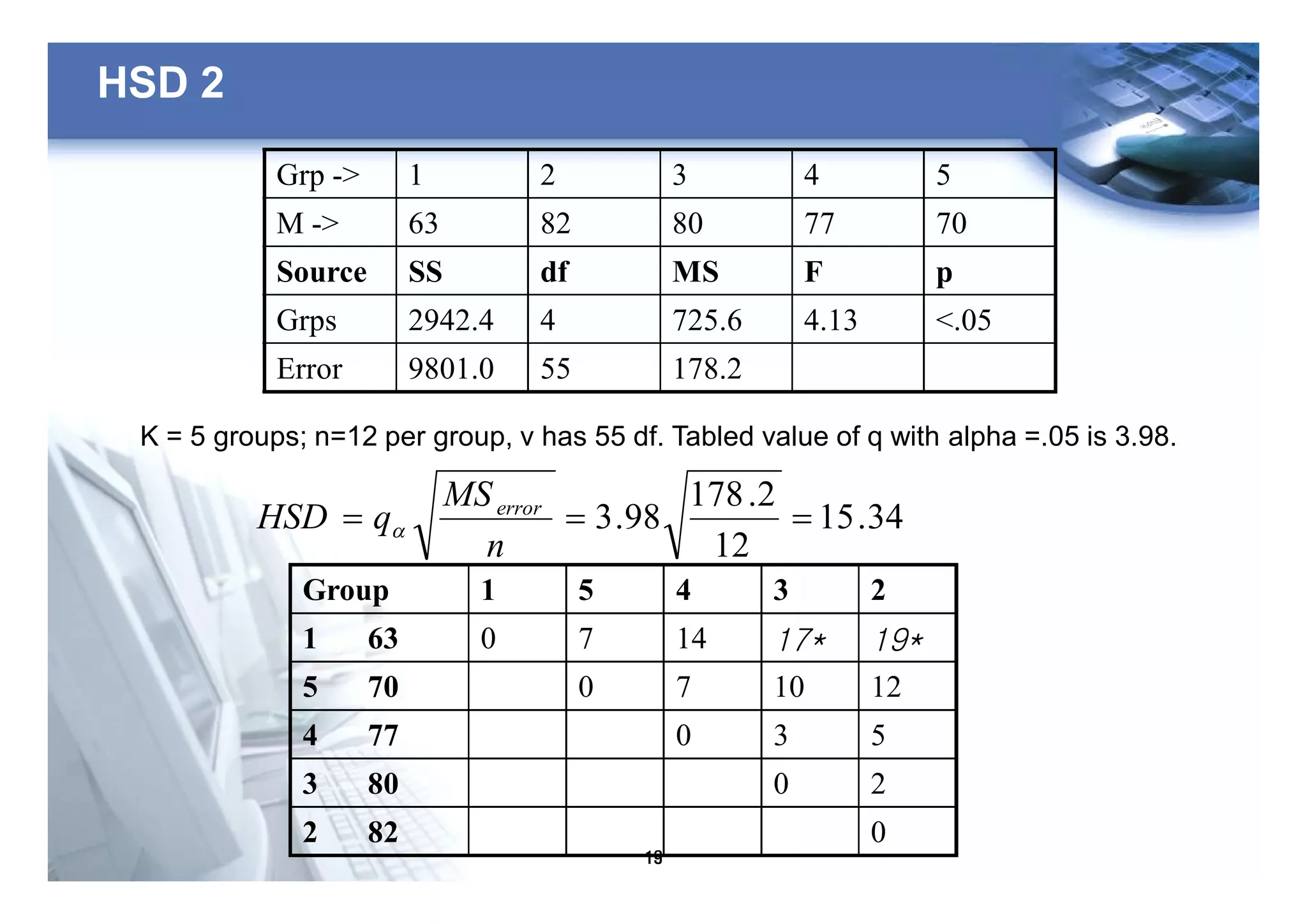
2) One-way ANOVA is used to compare the means of three or more independent groups when you have one independent variable with three or more categories and one continuous dependent variable.
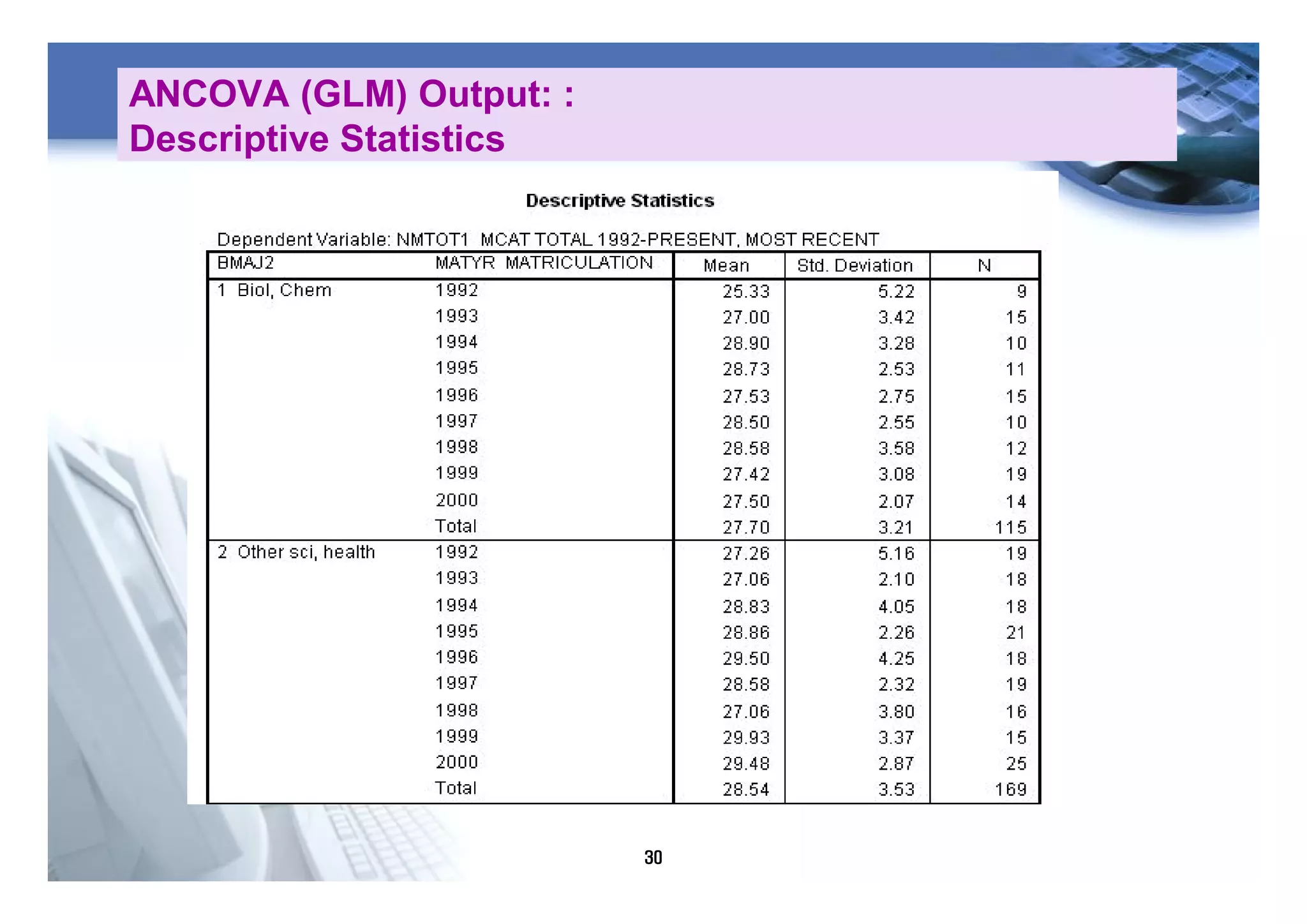
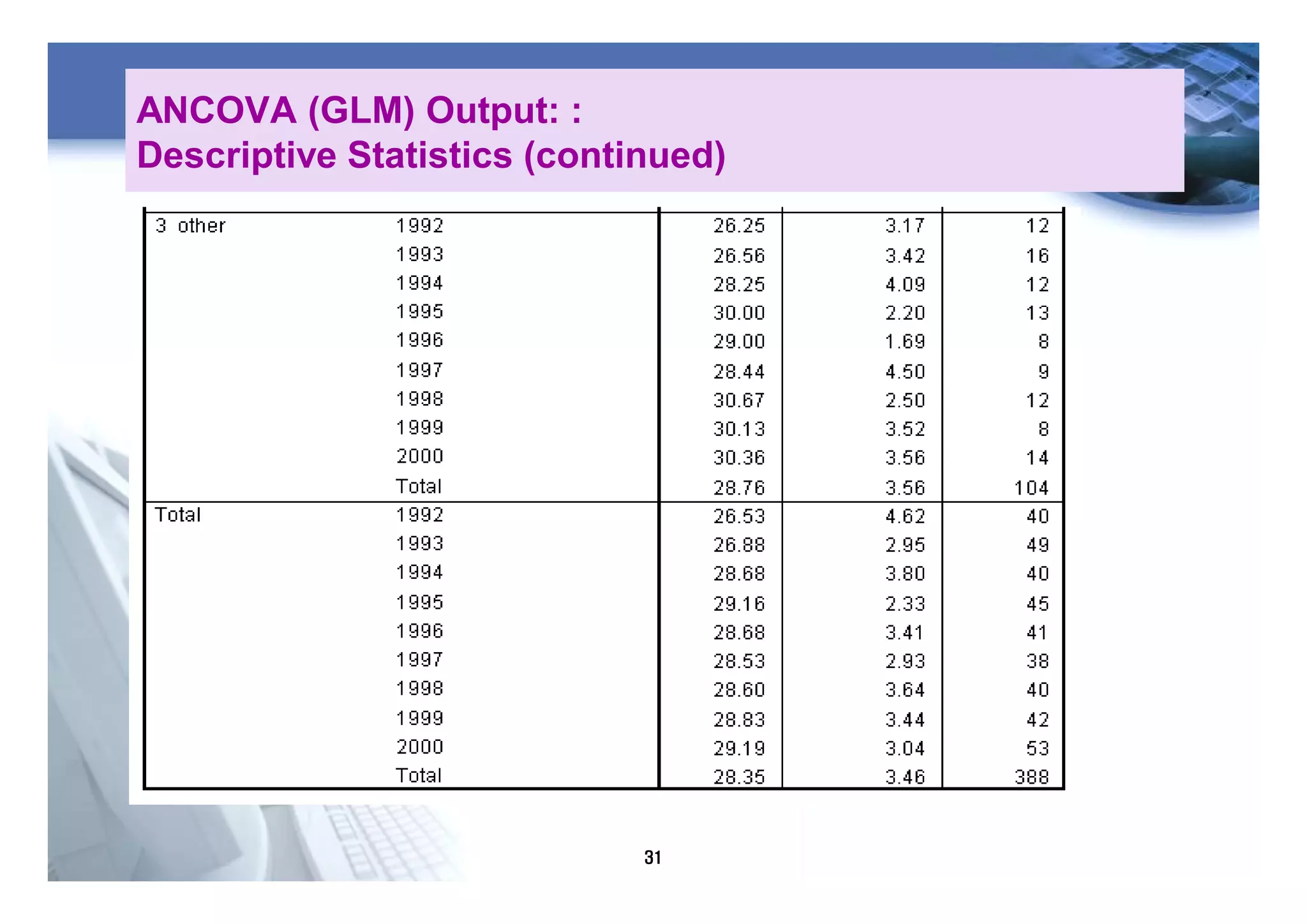
3) Repeated measures ANOVA is used when the same subjects are measured under different conditions to assess for main effects and interactions while accounting for the dependency of measurements within subjects.