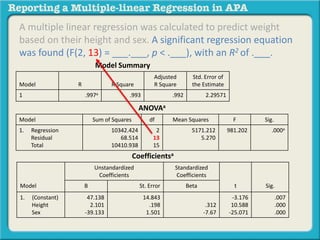
A multiple linear regression was calculated to predict weight based on height and sex. The regression equation was significant and height and sex were significant predictors of weight, explaining 99.3% of the variance. Participants' predicted weight is equal to 47.138 - 39.133 (sex) + 2.101 (height), where height is measured in inches and sex is coded as 0 for female and 1 for male.





![DV = Dependent Variable
IV = Independent Variable
A multiple linear regression was calculated to predict
[DV] based on [IV1] and [IV2]. A significant regression
equation was found (F(_,__) = ___.___, p < .___), with
an R2 of .___. Participants’ predicted [DV] is equal to
__.___ – __.___ (IV1) + _.___ (IV2), where [IV1] is coded
or measured as _____________, and [IV2] is coded or
measured as __________. Object of measurement
increased _.__ [DV unit of measure] for each [IV1 unit
of measure] and _.__ for each [IV2 unit of measure].
Both [IV1] and [IV2] were significant predictors of [DV].](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-5-320.jpg)





![A multiple linear regression was calculated to predict
[DV] based on their [IV1] and [IV2].](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-12-320.jpg)
![A multiple linear regression was calculated to predict
[DV] based on their [IV1] and [IV2].
You have been asked to investigate the degree to which
height and sex predicts weight.](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-13-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their [IV1] and [IV2].
You have been asked to investigate the degree to which
height and sex predicts weight.](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-14-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and [IV2].
You have been asked to investigate the degree to which
height and sex predicts weight.](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-15-320.jpg)




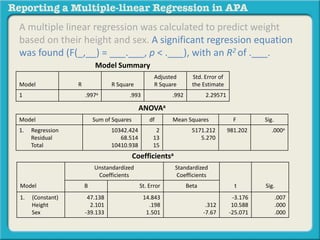
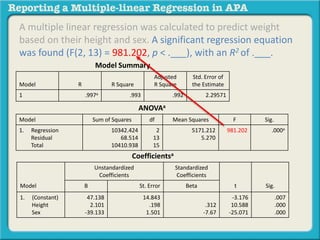



![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted [DV] is equal to __.___ + __.___ (IV2) +
_.___ (IV1), where [IV2] is coded or measured as _____________,
and [IV1] is coded or measured __________.](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-28-320.jpg)
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted [DV] is equal to __.___ + __.___ (IV1) +
_.___ (IV2), where [IV1] is coded or measured as _____________,
and [IV2] is coded or measured __________.
ANOVAa
Model Sum of Squares df Mean Squares F Sig.
1. Regression
Residual
Total
10342.424
68.514
10410.938
2
13
15
5171.212
5.270
981.202 .000a
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-29-320.jpg)
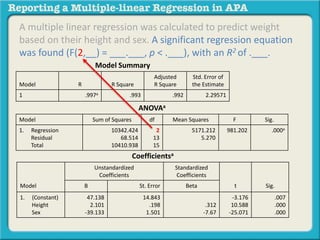
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted [DV] is equal to __.___ + __.___ (IV1) +
_.___ (IV2), where [IV1] is coded or measured as _____________,
and [IV2] is coded or measured __________.
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000
Independent Variable1: Height
Independent Variable2: Sex
Dependent Variable: Weight](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-30-320.jpg)
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted weight is equal to __.___ + __.___ (IV1) +
_.___ (IV2), where [IV1] is coded or measured as _____________,
and [IV2] is coded or measured __________.
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000
Independent Variable1: Height
Independent Variable2: Sex
Dependent Variable: Weight](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-31-320.jpg)
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted weight is equal to 47.138 + __.___ (IV1) +
_.___ (IV2), where [IV1] is coded or measured as _____________,
and [IV2] is coded or measured __________.
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000
Independent Variable1: Height
Independent Variable2: Sex
Dependent Variable: Weight](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-32-320.jpg)
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted weight is equal to 47.138 – 39.133 (IV1) +
_.___ (IV1), where [IV1] is coded or measured as _____________,
and [IV2] is coded or measured __________.
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000
Independent Variable1: Height
Independent Variable2: Sex
Dependent Variable: Weight](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-33-320.jpg)
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted weight is equal to 47.138 – 39.133 (SEX) +
_.___ (IV1), where [IV1] is coded or measured as _____________,
and [IV2] is coded or measured __________.
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000
Independent Variable1: Height
Independent Variable2: Sex
Dependent Variable: Weight](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-34-320.jpg)
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted weight is equal to 47.138 – 39.133 (SEX) +
2.101 (IV1), where [IV1] is coded or measured as _____________,
and [IV2] is coded or measured __________.
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000
Independent Variable1: Height
Independent Variable2: Sex
Dependent Variable: Weight](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-35-320.jpg)
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted weight is equal to 47.138 – 39.133 (SEX) +
2.101 (HEIGHT), where [IV1] is coded or measured as
_____________, and [IV2] is coded or measured __________.
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000
Independent Variable1: Height
Independent Variable2: Sex
Dependent Variable: Weight](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-36-320.jpg)
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted weight is equal to 47.138 – 39.133 (SEX) +
2.101 (HEIGHT), where sex is coded or measured as
_____________, and [IV2] is coded or measured __________.
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000
Independent Variable1: Height
Independent Variable2: Sex
Dependent Variable: Weight](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-37-320.jpg)
![A multiple linear regression was calculated to predict weight
based on their height and sex. A significant regression equation
was found (F(2, 13) = 981.202, p < .000), with an R2 of .993.
Participants’ predicted weight is equal to 47.138 – 39.133 (SEX) +
2.101 (HEIGHT), where sex is coded as 1 = Male, 2 = Female, and
[IV2] is coded or measured __________.
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000
Independent Variable1: Height
Independent Variable2: Sex
Dependent Variable: Weight](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-38-320.jpg)





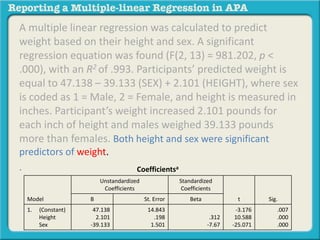
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Object of measurement increased _.__ [DV unit of
measure] for each [IV1 unit of measure] and _.__ for each
[IV2 unit of measure].](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-44-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Object of measurement increased _.__ [DV unit of
measure] for each [IV1 unit of measure] and _.__ for each
[IV2 unit of measure].
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-45-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Participant’s weight increased _.__ [DV unit of
measure] for each [IV1 unit of measure] and _.__ for each
[IV2 unit of measure].
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-46-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Participant’s weight increased 2.101 [DV unit of
measure] for each [IV1 unit of measure] and _.__ for each
[IV2 unit of measure].
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-47-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Participant’s weight increased 2.101 pounds for
each [IV1 unit of measure] and _.__ for each [IV2 unit of
measure].
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-48-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Participant’s weight increased 2.101 pounds for
each inch of height and _.__ for each [IV2 unit of measure].
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-49-320.jpg)



![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Participant’s weight increased 2.101 pounds for
each inch of height and males weighed 39.133 pounds
more than females. Both [IV1] and [IV2] were significant
predictors of [DV].](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-53-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Participant’s weight increased 2.101 pounds for
each inch of height and males weighed 39.133 pounds
more than females. Both [IV1] and [IV2] were significant
predictors of [DV].
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-54-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Participant’s weight increased 2.101 pounds for
each inch of height and males weighed 39.133 pounds
more than females. Both height and [IV2] were significant
predictors of [DV].
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-55-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Participant’s weight increased 2.101 pounds for
each inch of height and males weighed 39.133 pounds
more than females. Both height and sex were significant
predictors of [DV].
Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-56-320.jpg)
![A multiple linear regression was calculated to predict
weight based on their height and sex. A significant
regression equation was found (F(2, 13) = 981.202, p <
.000), with an R2 of .993. Participants’ predicted weight is
equal to 47.138 – 39.133 (SEX) + 2.101 (HEIGHT), where sex
is coded as 1 = Male, 2 = Female, and height is measured in
inches. Participant’s weight increased 2.101 pounds for
each inch of height and males weighed 39.133 pounds
more than females. Both height and sex were significant
predictors of [DV].
. Coefficientsa
Model
Unstandardized
Coefficients
Standardized
Coefficients
t Sig.B St. Error Beta
1. (Constant)
Height
Sex
47.138
2.101
-39.133
14.843
.198
1.501
.312
-7.67
-3.176
10.588
-25.071
.007
.000
.000](https://image.slidesharecdn.com/reportingamultiplelinearregressioninapa-141002163648-phpapp02-170529110723/85/Reporting-a-multiple-linear-regression-in-APA-57-320.jpg)
















































































![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)





