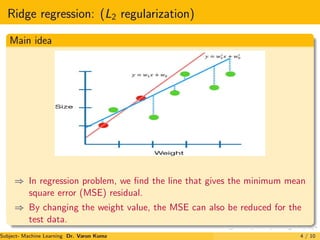
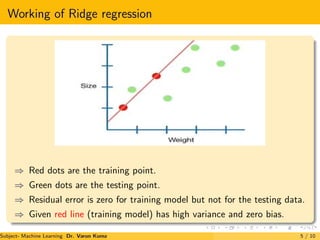
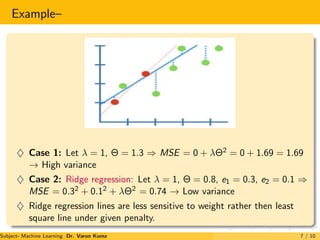
The document discusses regularization techniques for machine learning models called Ridge and Lasso regression. Ridge regression, also known as L2 regularization, introduces a small bias to models to minimize testing error by reducing variance. It works by adding penalties for large weights proportional to the square of the weight. Lasso regression, or L1 regularization, is similar but can exclude useless variables from models by setting some weights to zero. Both techniques aim to reduce overfitting and improve generalization to unlabeled data.