Downloaded 607 times







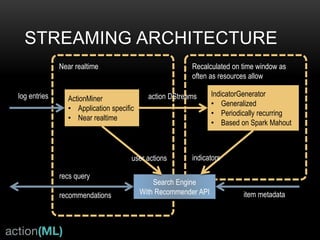
![FROM COOCCURRENCE TO
RECOMMENDATION
• This actually means to take the user’s
history hp and compare it to rows of the
cooccurrence matrix (PtP)
• TF-IDF weighting of cooccurrence would
be nice to mitigate the undue influence
of popular items
• Find items nearest to the user’s history
• Sort these by similarity strength and
keep only the highest
—you have recommendations
• Sound familiar? Find the k-nearest
neighbors using cosine and TF-IDF?
r = (PtP)hp
hp
user1: [item2, item3]
(PtP)
item1: [item2, item3]
item2: [item1, item3, item95]
item3: […]
find item that most closely
matches the user’s history
item1 !](https://image.slidesharecdn.com/unified-recommender-141007141435-conversion-gate02/85/The-Universal-Recommender-7-320.jpg)
![FROM COOCCURRENCE TO
RECOMMENDATION
• This actually means to take the user’s
history hp and compare it to rows of the
cooccurrence matrix (PtP)
• TF-IDF weighting of cooccurrence would
be nice to mitigate the undue influence
of popular items
• Find items nearest to the user’s history
• Sort these by similarity strength and
keep only the highest
—you have recommendations
• Sound familiar? Find the k-nearest
neighbors using cosine and TF-IDF?
• That’s exactly what a search engine
does!
r = (PtP)hp
hp
user1: [item2, item3]
(PtP)
item1: [item2, item3]
item2: [item1, item3, item95]
item3: […]
find item that most closely
matches the user’s history
item1 !](https://image.slidesharecdn.com/unified-recommender-141007141435-conversion-gate02/85/The-Universal-Recommender-8-320.jpg)















![* The ES json query looks like this:
* {
* "size": 20
* "query": {
* "bool": {
* "should": [
* {
* "terms": {
* "rate": ["0", "67", "4"]
* }
* },
* {
* "terms": {
* "buy": ["0", "32"],
* "boost": 2
* }
* },
* { // categorical boosts
* "terms": {
* "category": ["cat1"],
* "boost": 1.05
* }
* }
* ],
* "must": [ // categorical filters
* {
* "terms": {
* "category": ["cat1"],
* "boost": 0
* }
* },
* {
* "must_not": [//blacklisted items
* {
* "ids": {
* "values": ["items-id1", "item-id2", ...]
* }
* },
* {
* "constant_score": {// date in query must fall between the expire and avqilable dates of an item
* "filter": {
* "range": {
* "availabledate": {
* "lte": "2015-08-30T12:24:41-07:00"
* }
* }
* },
* "boost": 0
* }
* },
* {
* "constant_score": {// date range filter in query must be between these item property values
* "filter": {
* "range" : {
* "expiredate" : {
* "gte": "2015-08-15T11:28:45.114-07:00"
* "lt": "2015-08-20T11:28:45.114-07:00"
* }
* }
* }, "boost": 0
* }
* },
* {
* "constant_score": { // this orders popular items for backfill
* "filter": {
* "match_all": {}
* },
* "boost": 0.000001 // must have as least a small number to be boostable
* }
* }
* }
* }
* }
*
An example Elasticsearch query on a multi-
field index created from the output of the CCO
engine. The index includes about 90% of the
data in the “whole enchilada” equation.
This executes in 50ms on a non-cached
cluster and ~26ms on an unoptimized cluster.](https://image.slidesharecdn.com/unified-recommender-141007141435-conversion-gate02/85/The-Universal-Recommender-26-320.jpg)

The document outlines the development of a universal recommender system that improves recommendation quality by utilizing user history and co-occurrence metrics. It emphasizes the use of various user actions and metadata to enhance recommendation accuracy, overcoming limitations of traditional collaborative filtering methods. The system incorporates real-time data processing and advanced algorithms like log-likelihood ratios to deliver personalized recommendations efficiently.








































![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)


























