Downloaded 17 times






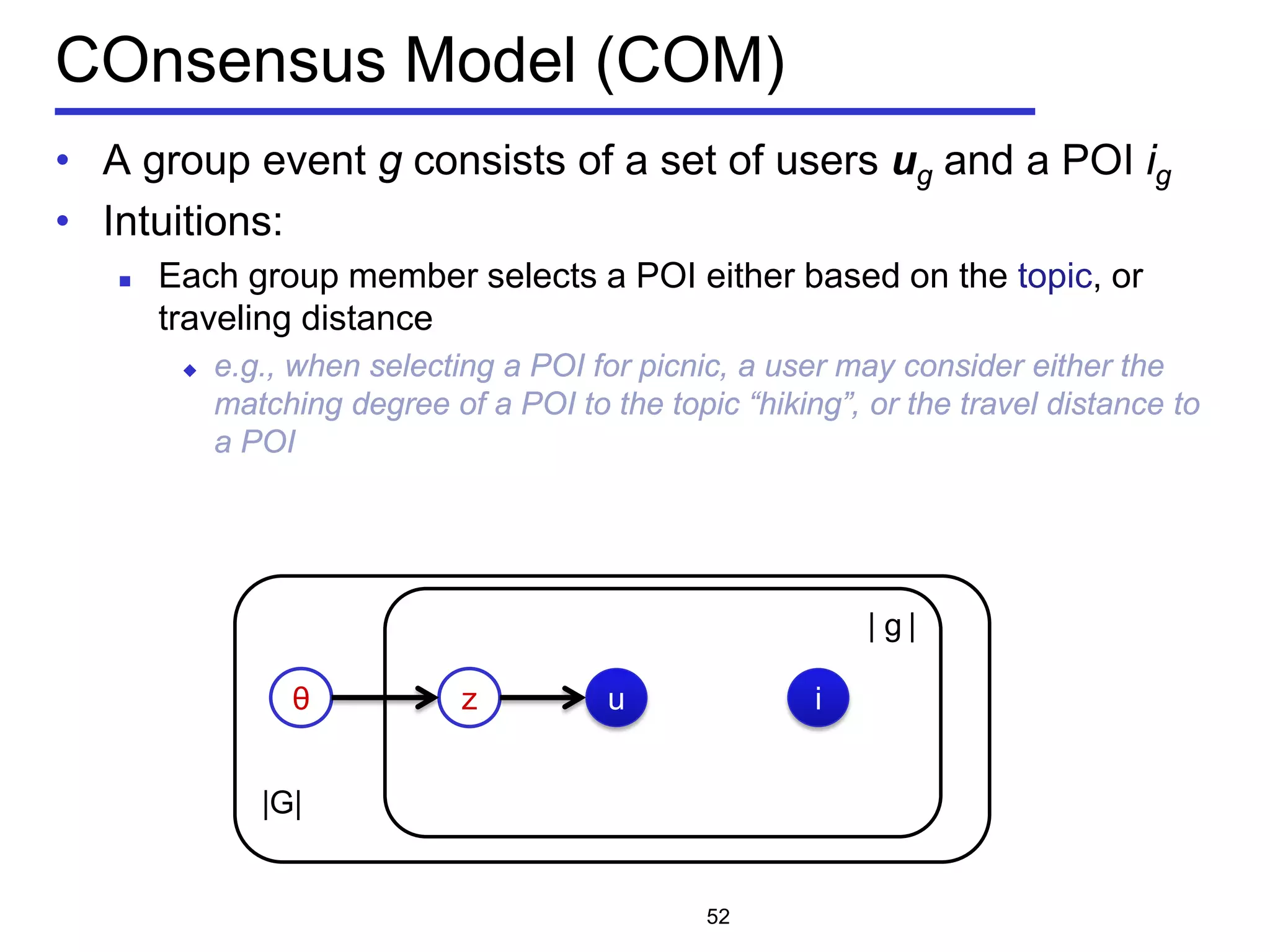
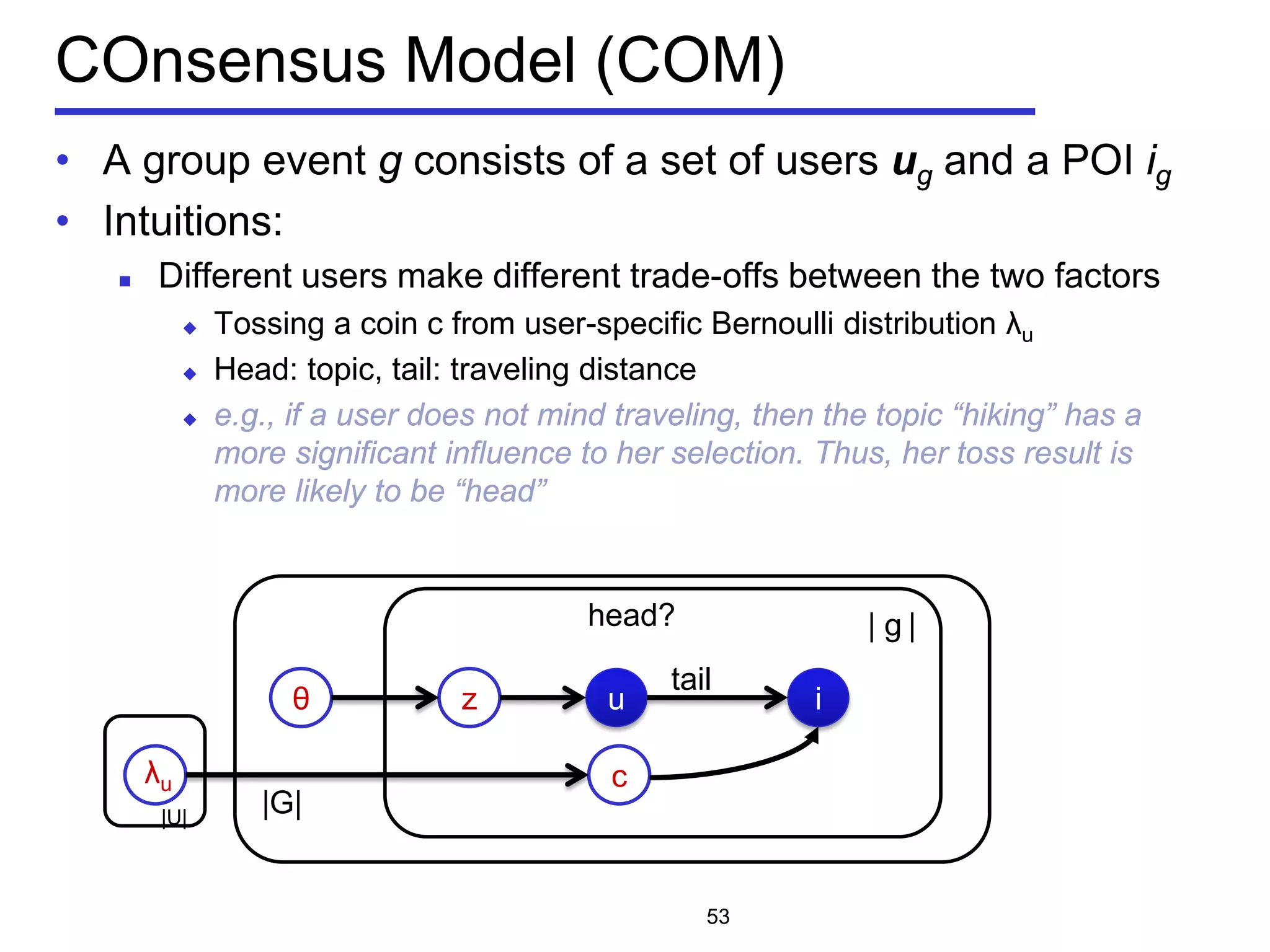
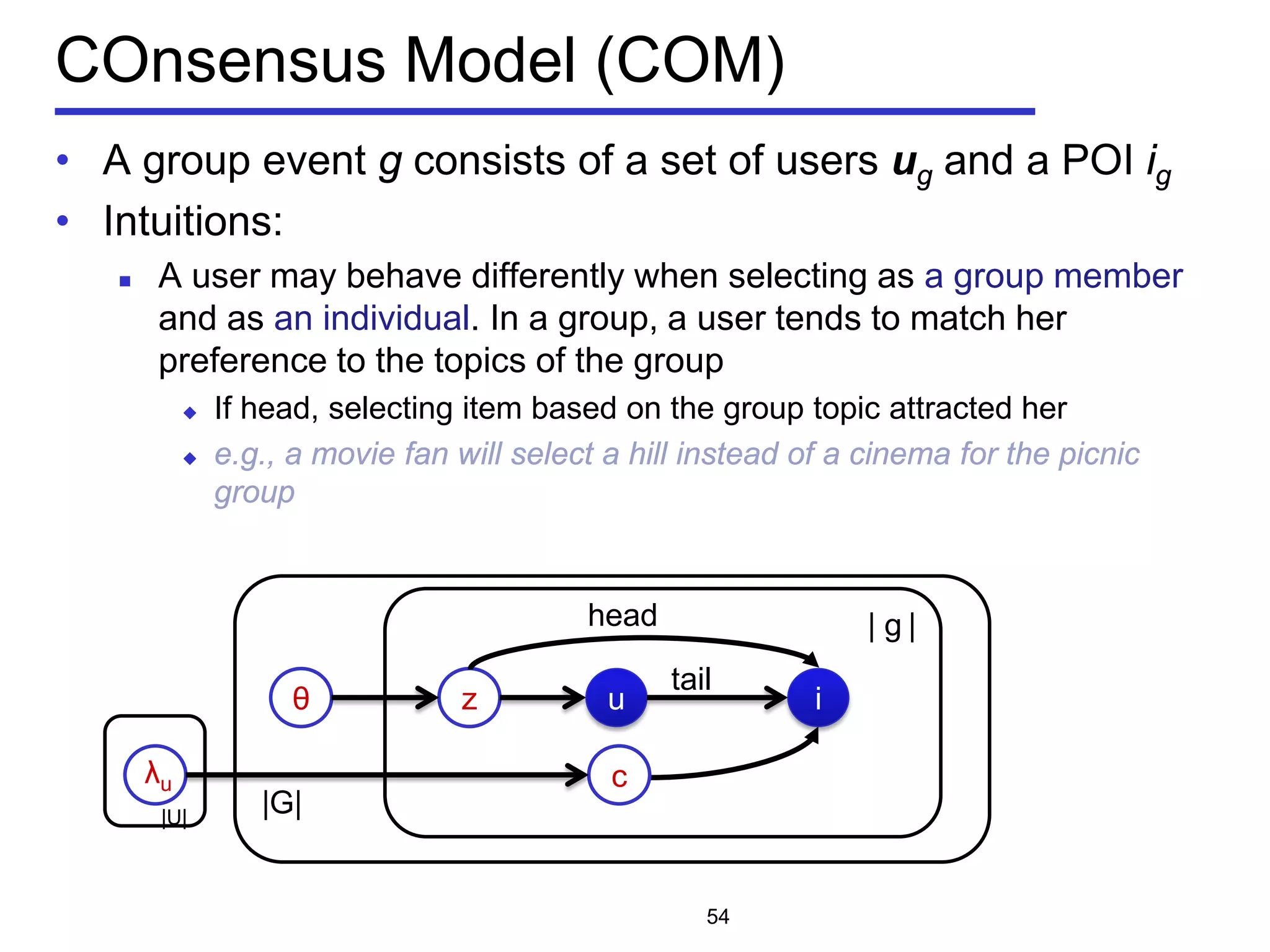
![Problem Statement of m-CK problem
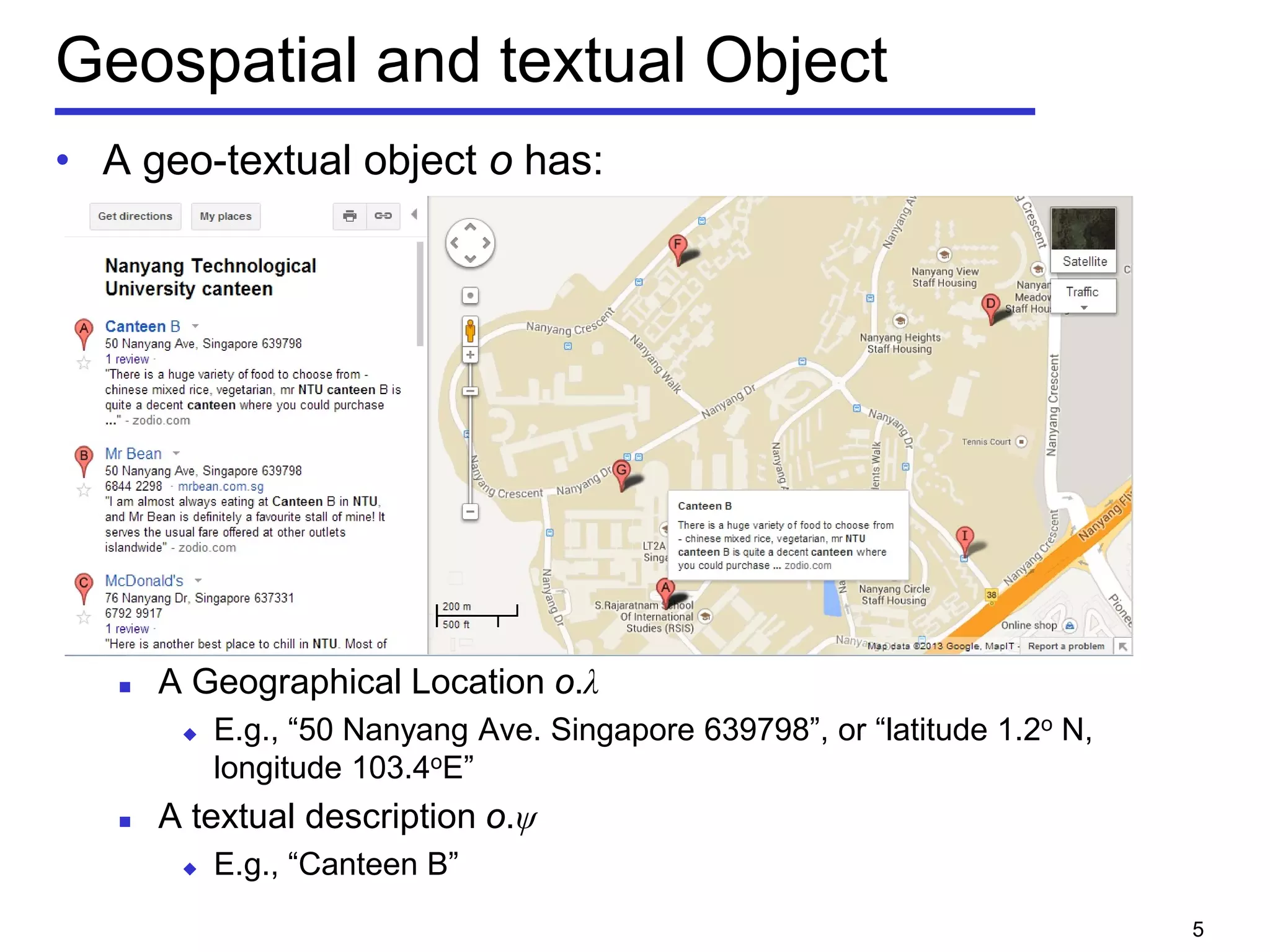
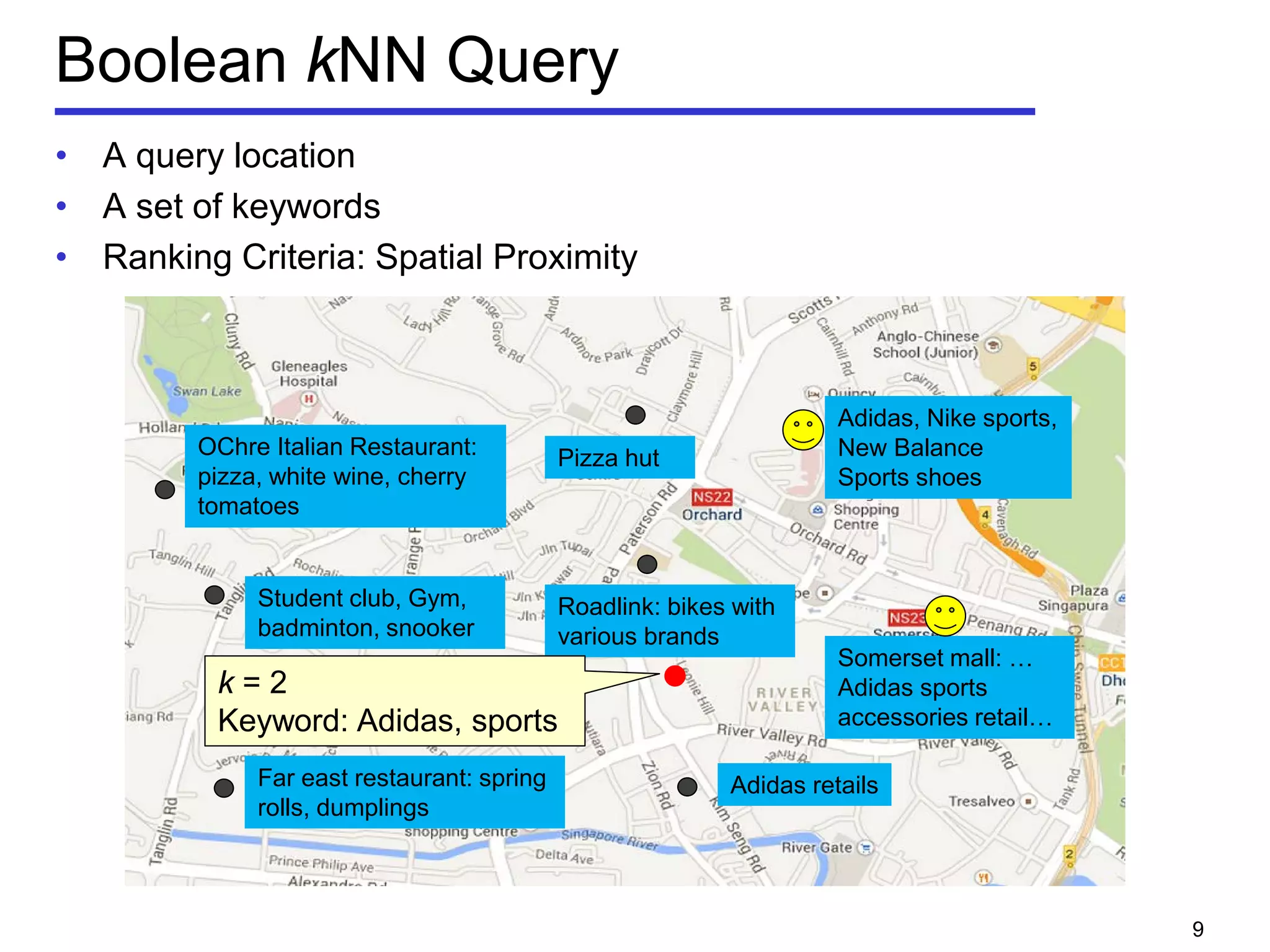
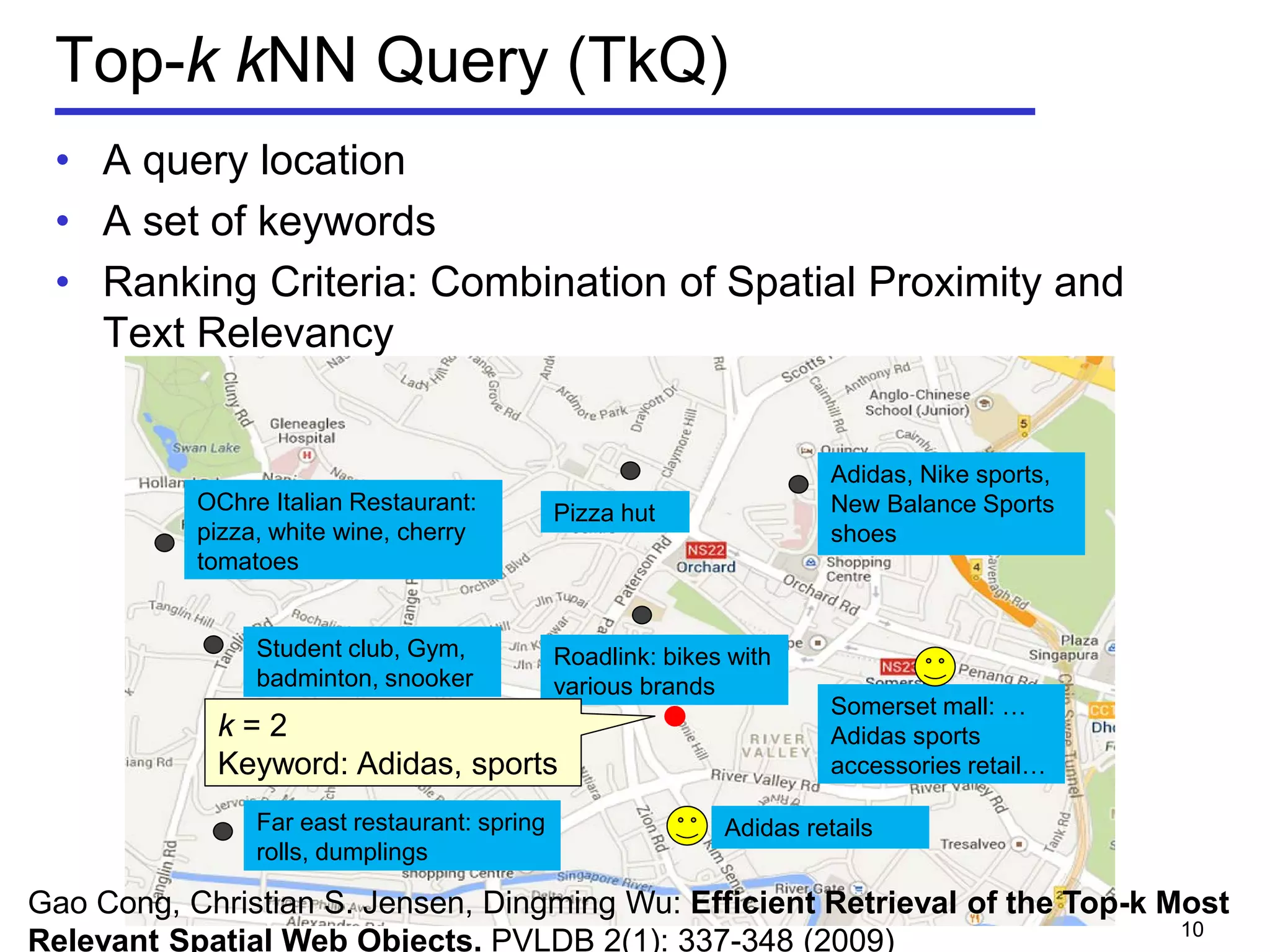
• Geo-textual object o
Location 𝑜. 𝜆
Textual description 𝑜. 𝜓
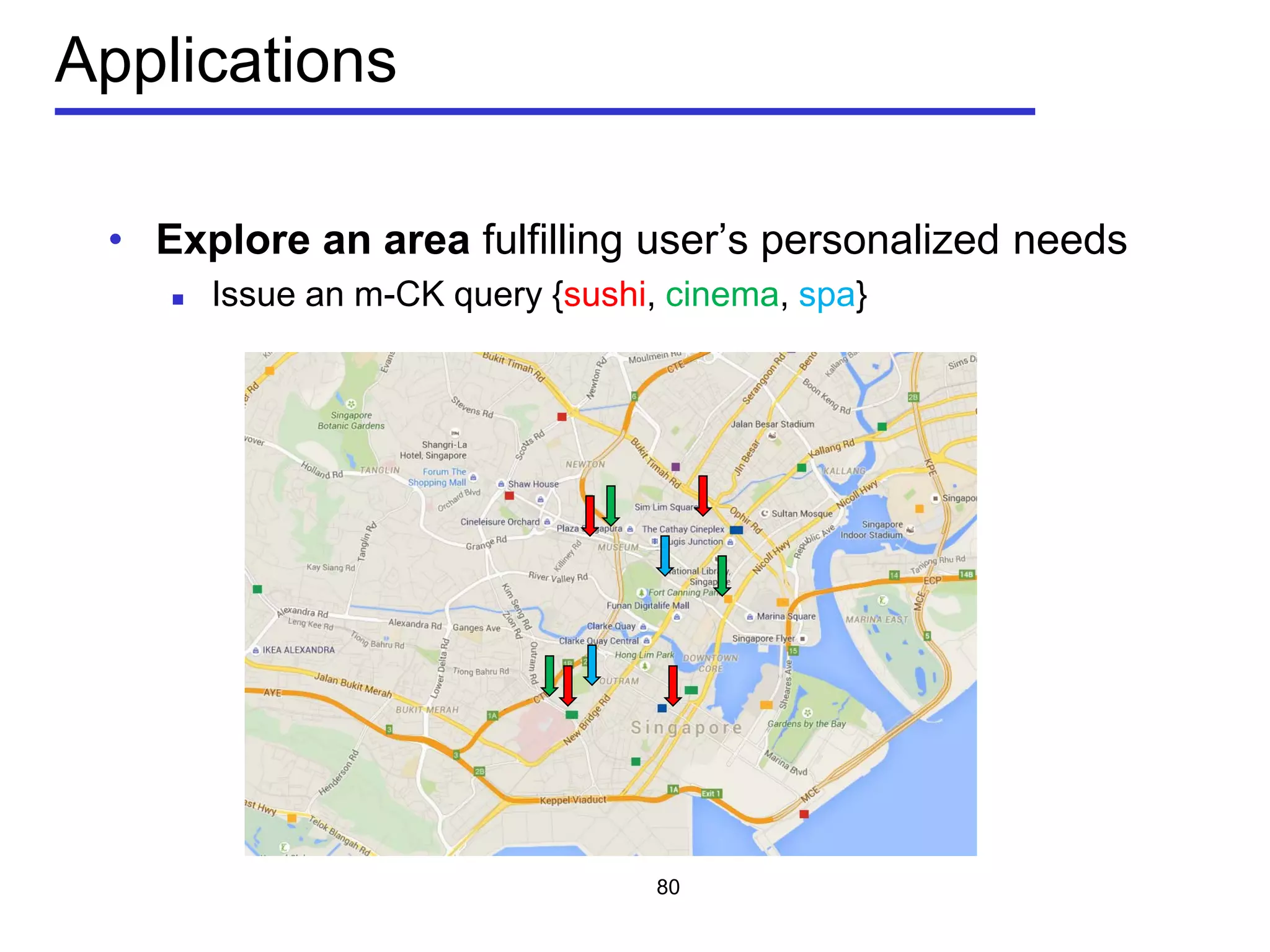
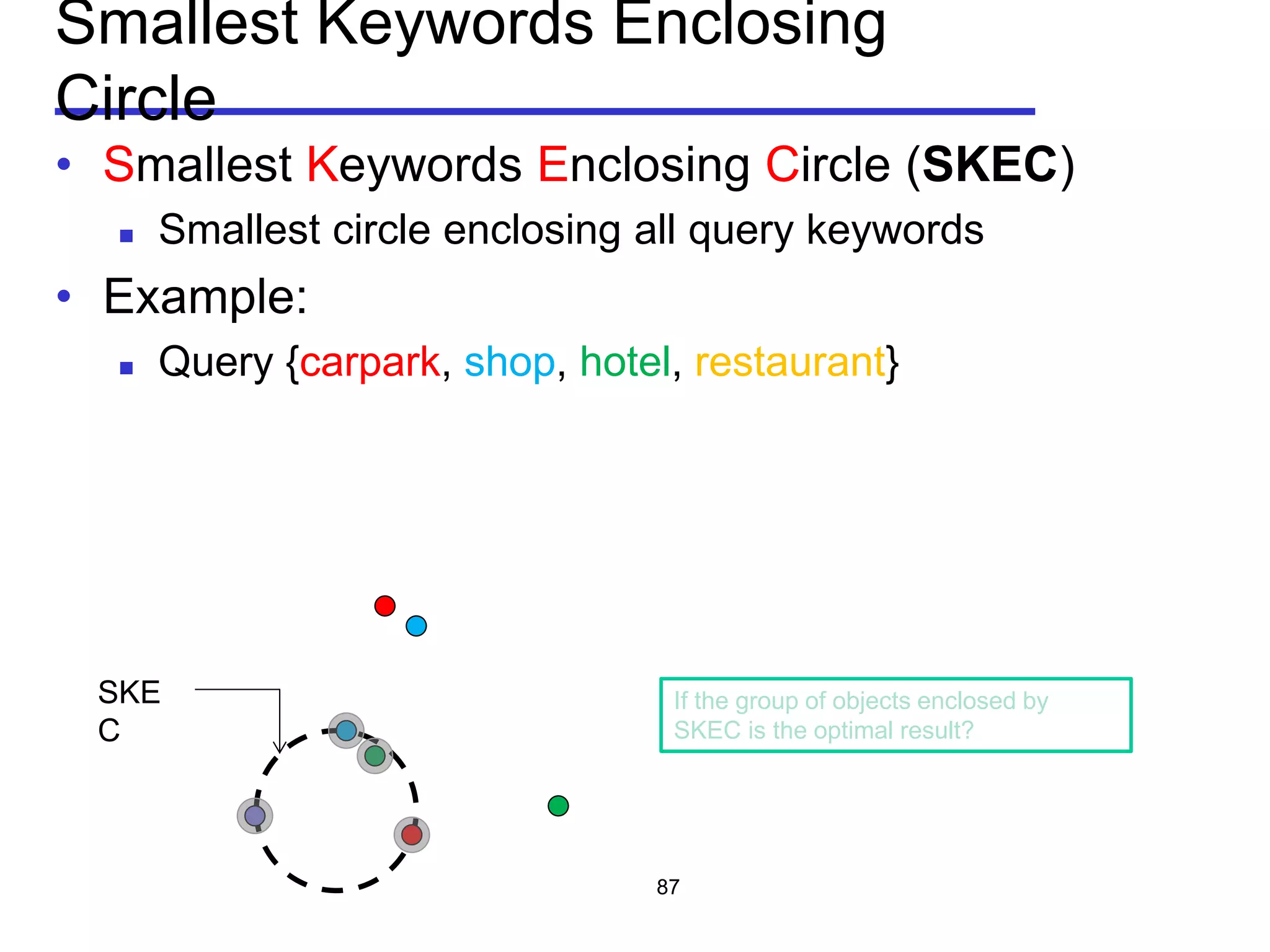
• m-closest keywords (m-CK) problem [Zhang et al, ICDE 2009,
ICDE 2010]
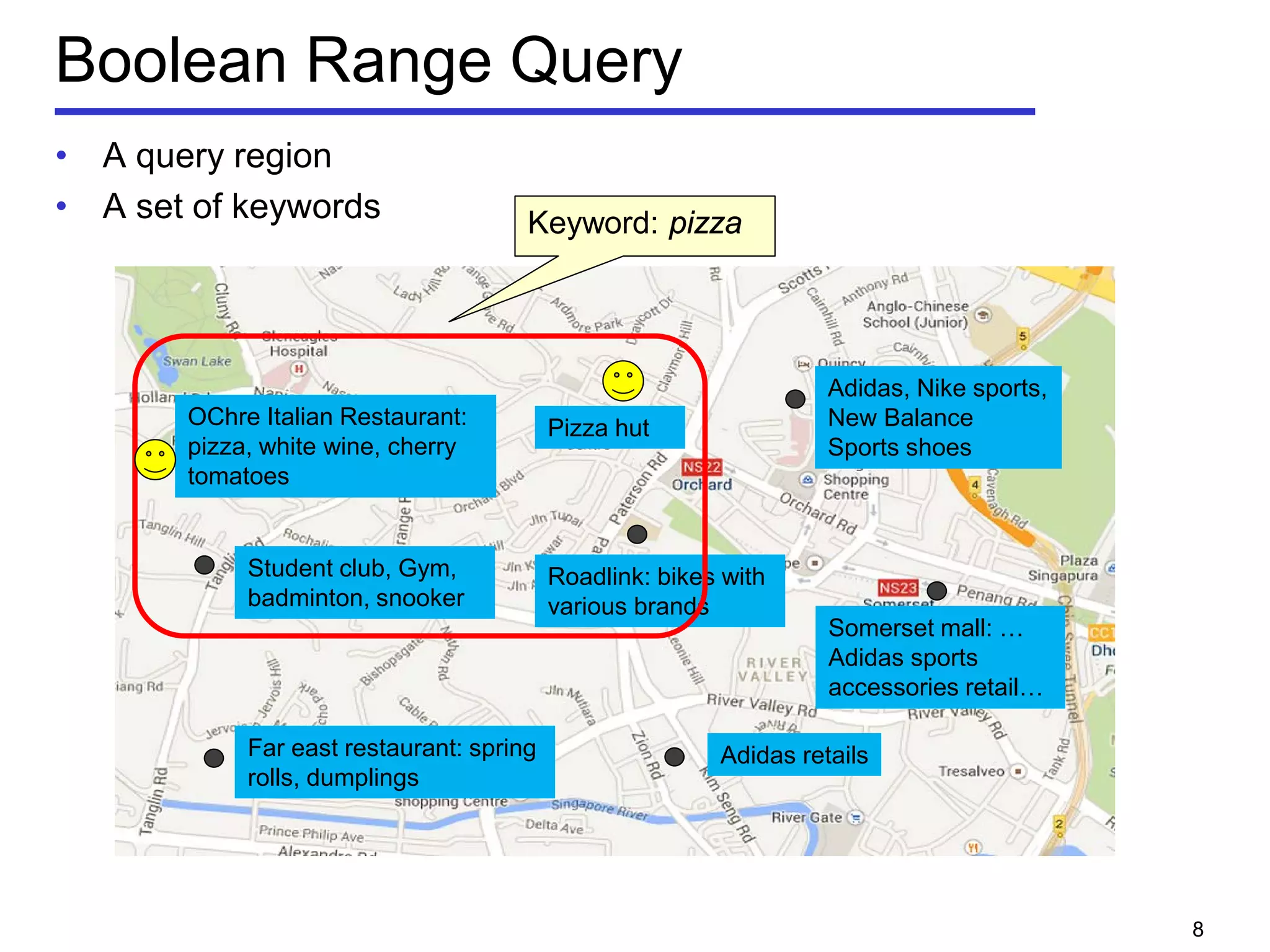
A query q consists of m query keywords
Find a group of objects T covering all the m query keywords
𝑞 ⊆∪ 𝑜∈𝑇 𝑜. 𝜓
Objects should be close to each other
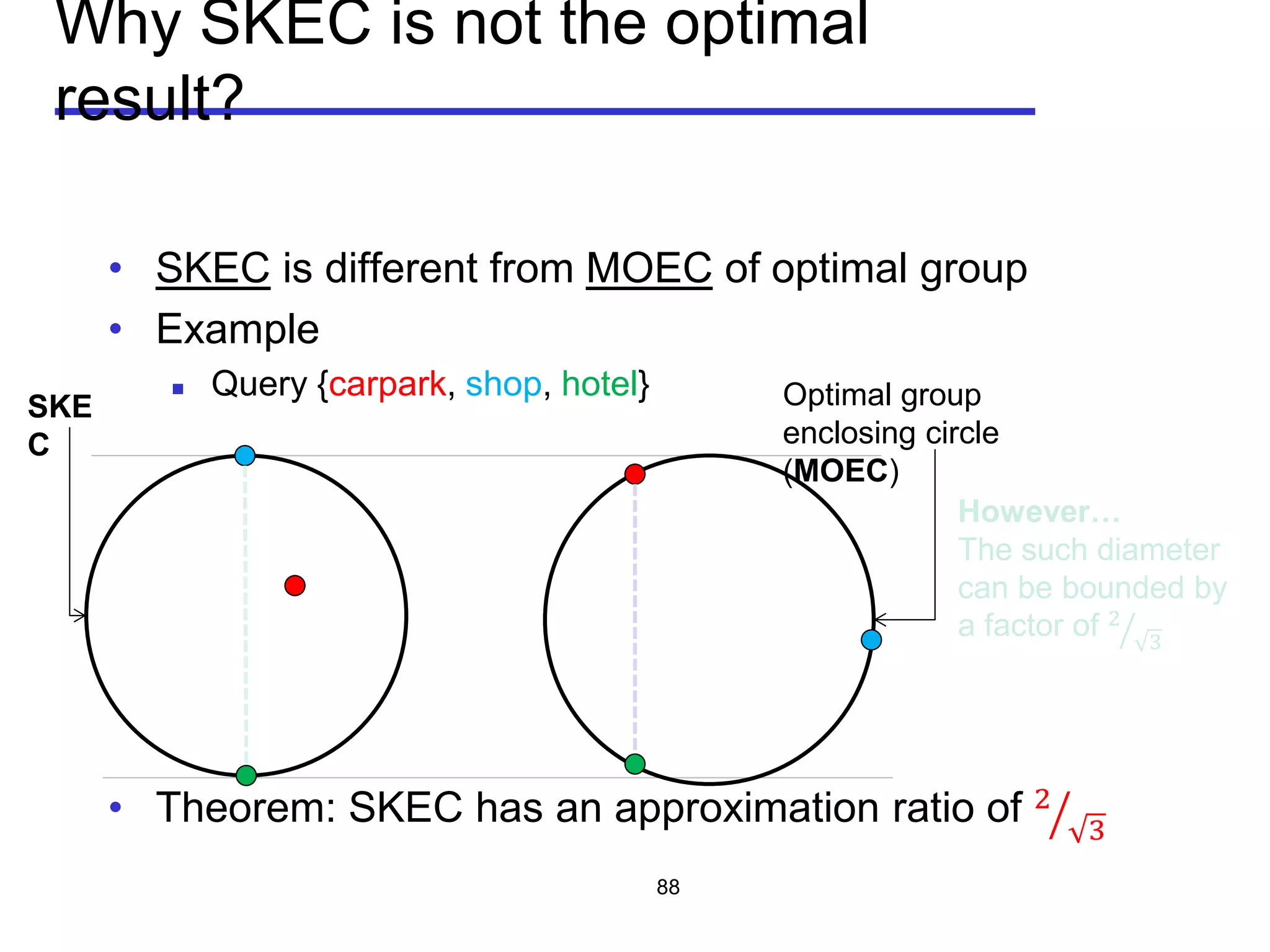
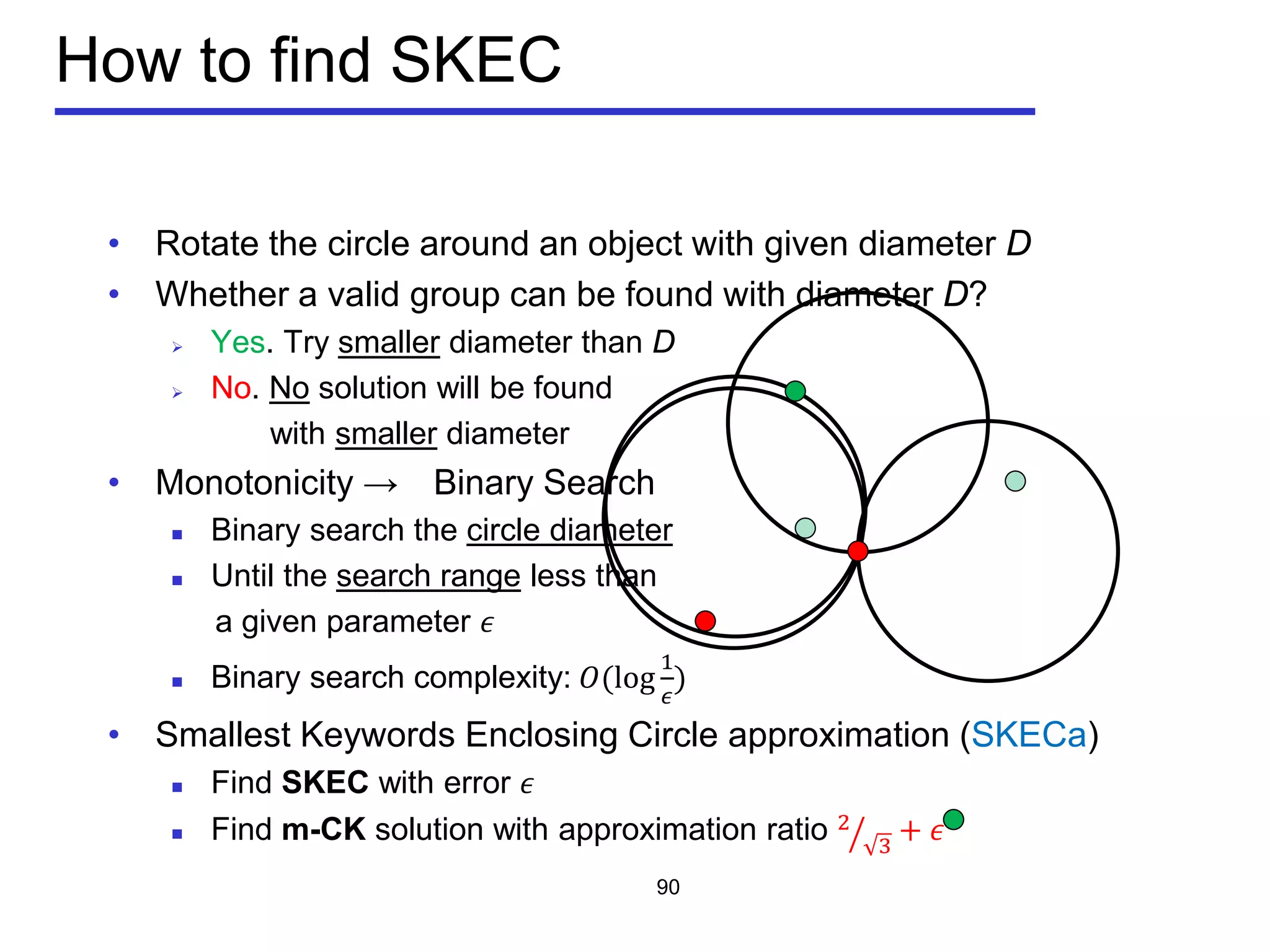
Minimize the diameter of a group
Diameter of a group:
the maximum Euclidean distance between any pair of
objects
𝐷𝐷𝐷𝐷 𝑇 = max
𝑜 𝑖,𝑜 𝑗∈𝑇
𝐷𝐷𝐷𝐷(𝑜𝑖, 𝑜𝑗)
20](https://image.slidesharecdn.com/gaocong-geospatialsocialmediadatamanagementandcontext-awarerecommendation-160616081437/75/Gao-cong-geospatial-social-media-data-management-and-context-aware-recommendation-13-2048.jpg)











![Point-of-interest Recommendation
• A great quantity of geo-annotated UGC has been
accumulated
Twitter: 1-2 million tweets per hour, 2.7% of which are geo-
annotated [1]
Foursquare: 6 billion check-ins [2]
• The spatial, temporal and semantic information enables a
number of applications
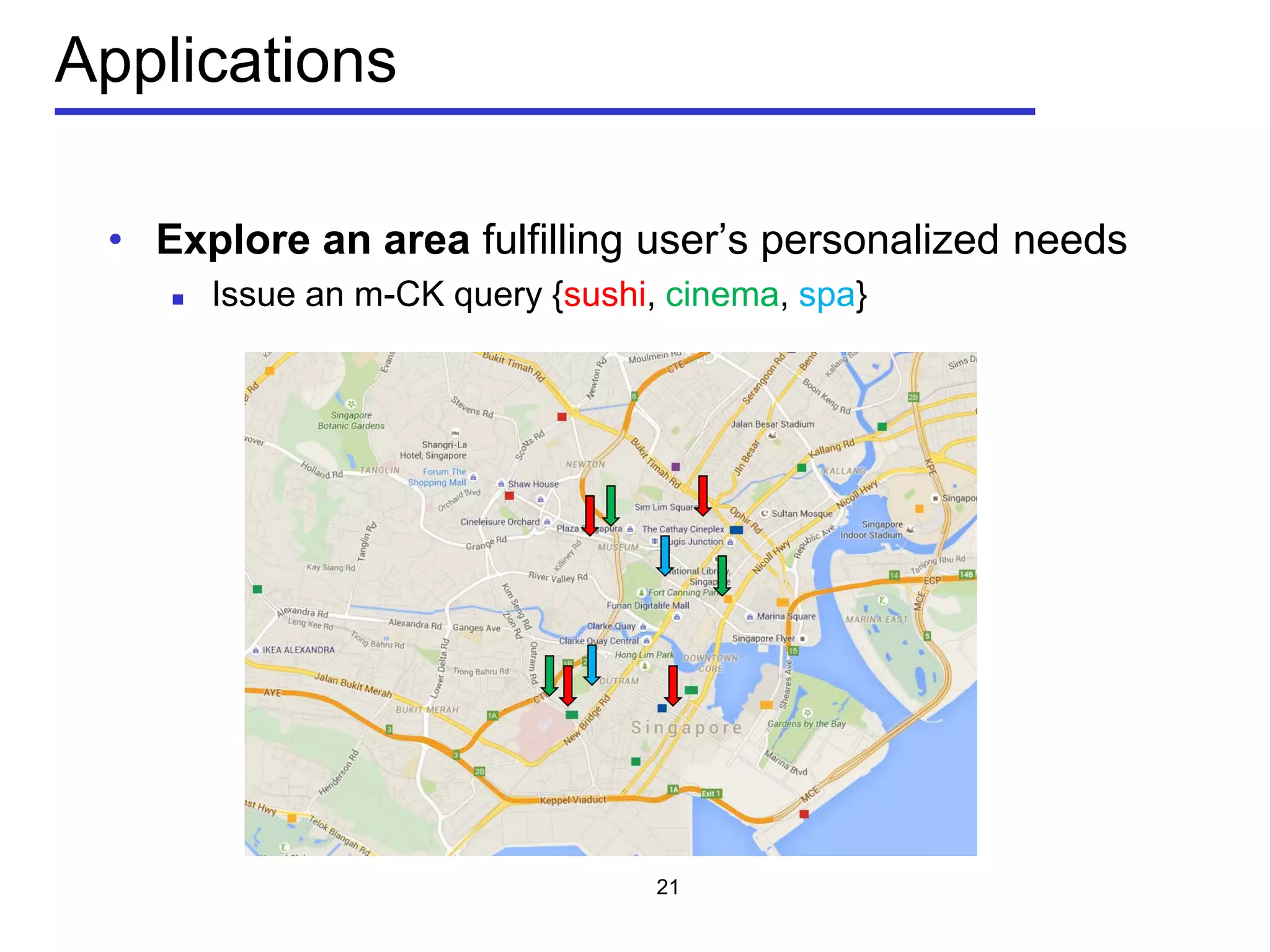
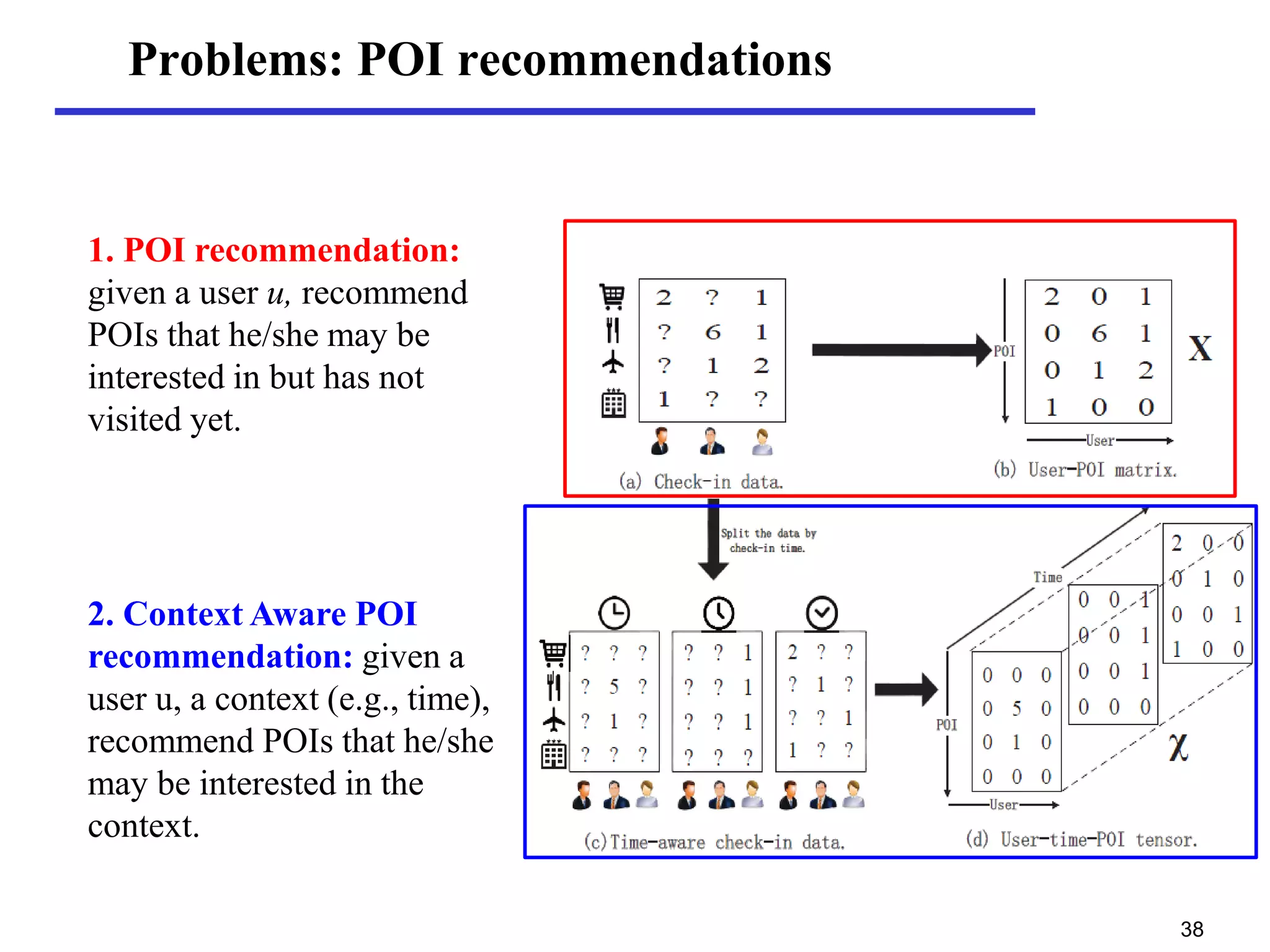
• Point-of-interest Recommendation: to recommend points-
of-interest (POIs) that a user is interested in but has not
visited
To users: discovering new places, knowing their cities better
To merchants: launching advertisements, attracting more
customers
[1] http://irevolution.net/2013/06/09/mapping-global-twitter-heartbeat/
[2] https://foursquare.com/about
37](https://image.slidesharecdn.com/gaocong-geospatialsocialmediadatamanagementandcontext-awarerecommendation-160616081437/75/Gao-cong-geospatial-social-media-data-management-and-context-aware-recommendation-30-2048.jpg)





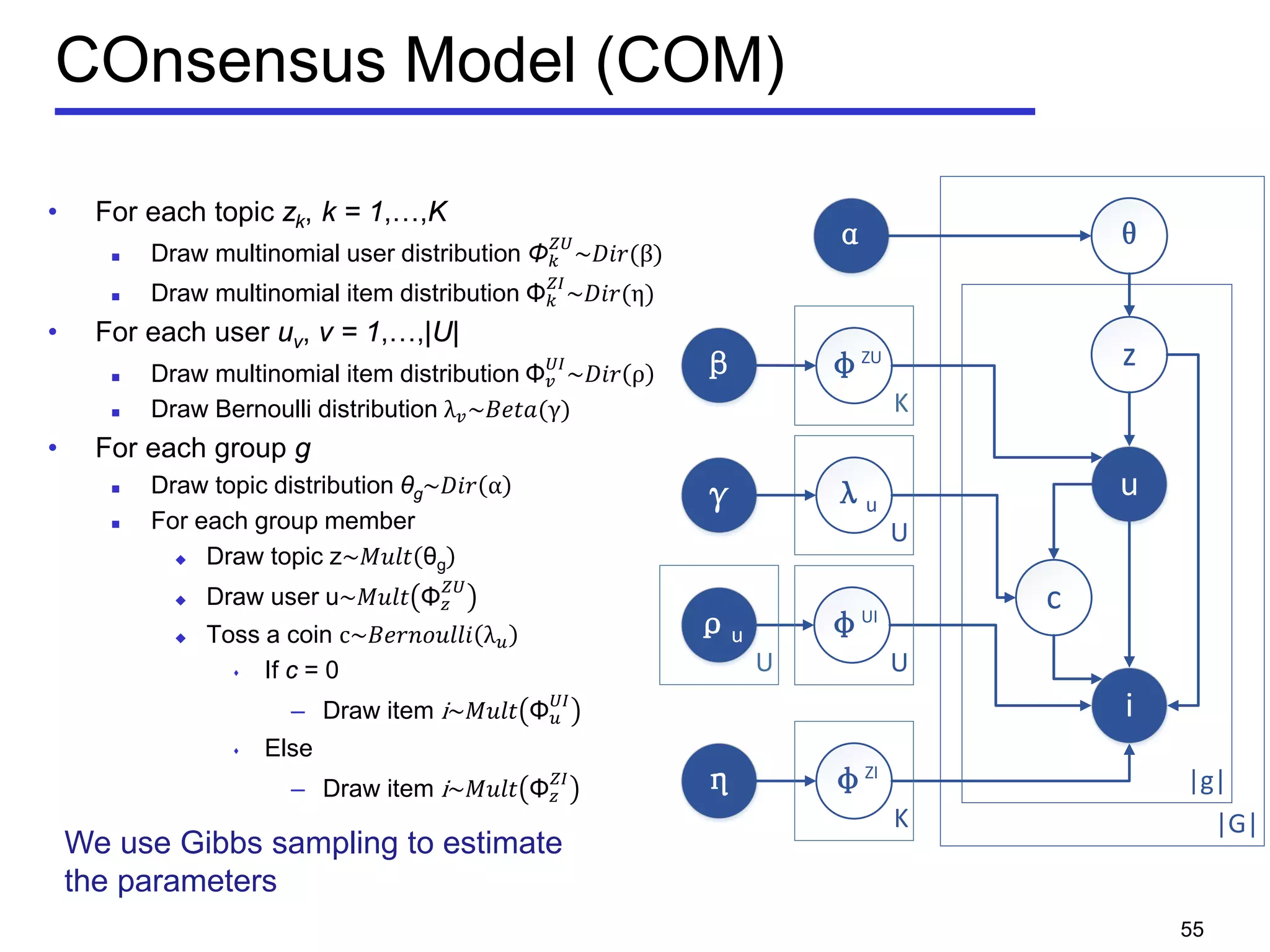









![Problem Statement
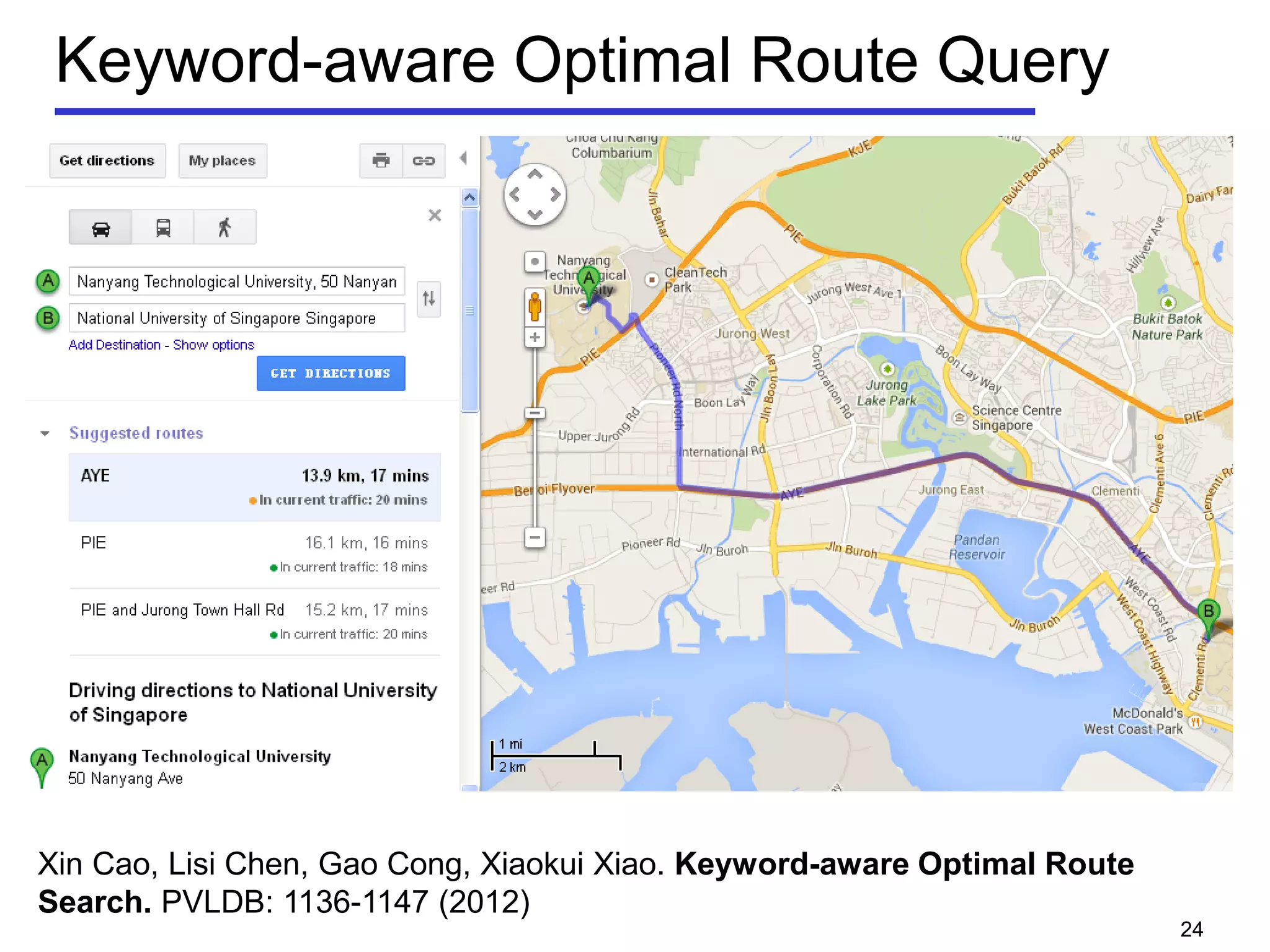
• Geo-textual object o
Location 𝑜. 𝜆
Textual description 𝑜. 𝜓
• m-closest keywords (m-CK) problem [Zhang et al, ICDE 2009,
ICDE 2010]
A query q consists of m query keywords
Find a group of objects T covering all the m query keywords
𝑞 ⊆∪ 𝑜∈𝑇 𝑜. 𝜓
Objects should be close to each other
Minimize the diameter of a group
Diameter of a group:
the maximum Euclidean distance between any pair of
objects
𝐷𝐷𝐷𝐷 𝑇 = max
𝑜 𝑖,𝑜 𝑗∈𝑇
𝐷𝐷𝐷𝐷(𝑜𝑖, 𝑜𝑗)78](https://image.slidesharecdn.com/gaocong-geospatialsocialmediadatamanagementandcontext-awarerecommendation-160616081437/75/Gao-cong-geospatial-social-media-data-management-and-context-aware-recommendation-62-2048.jpg)












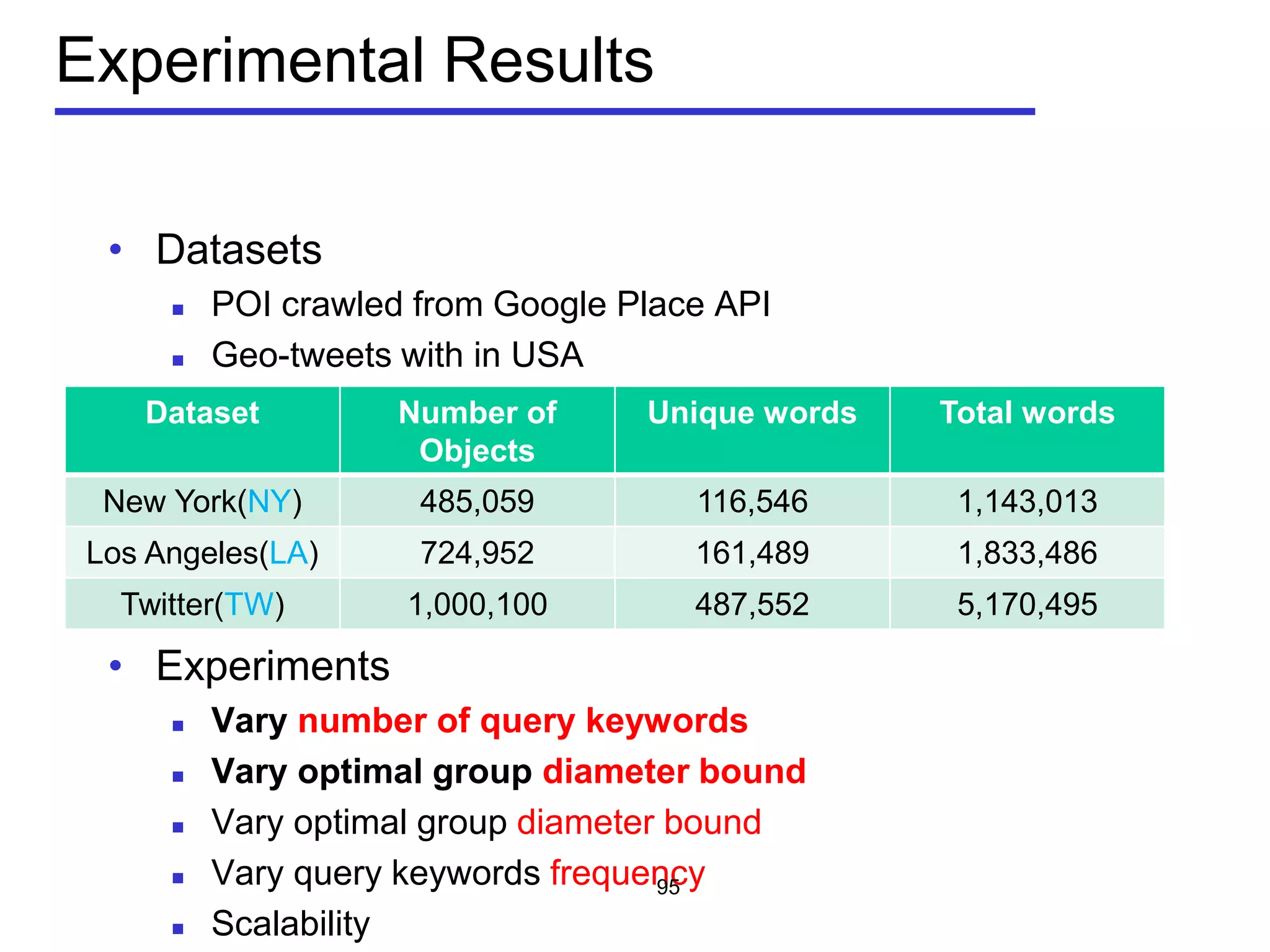
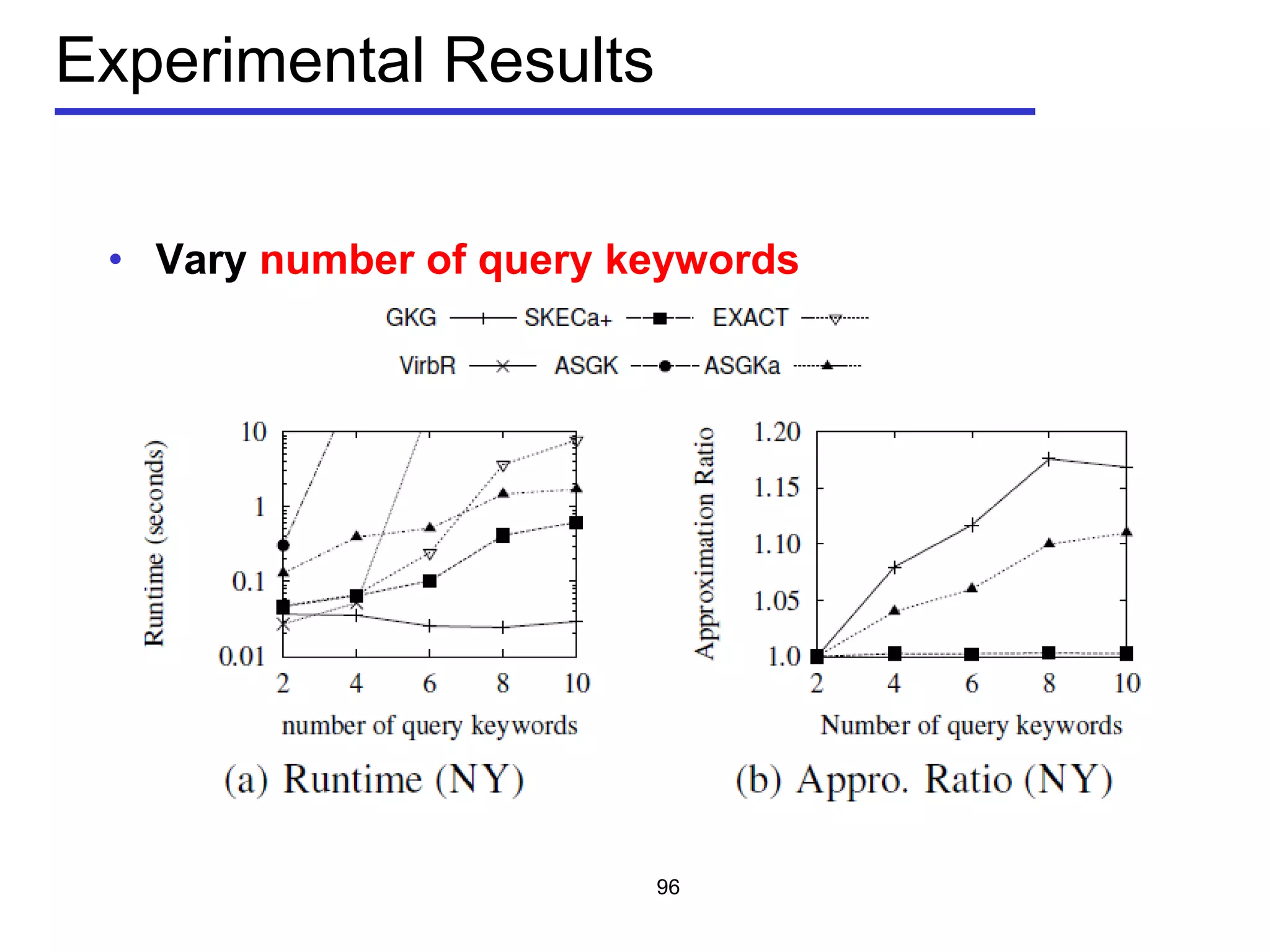
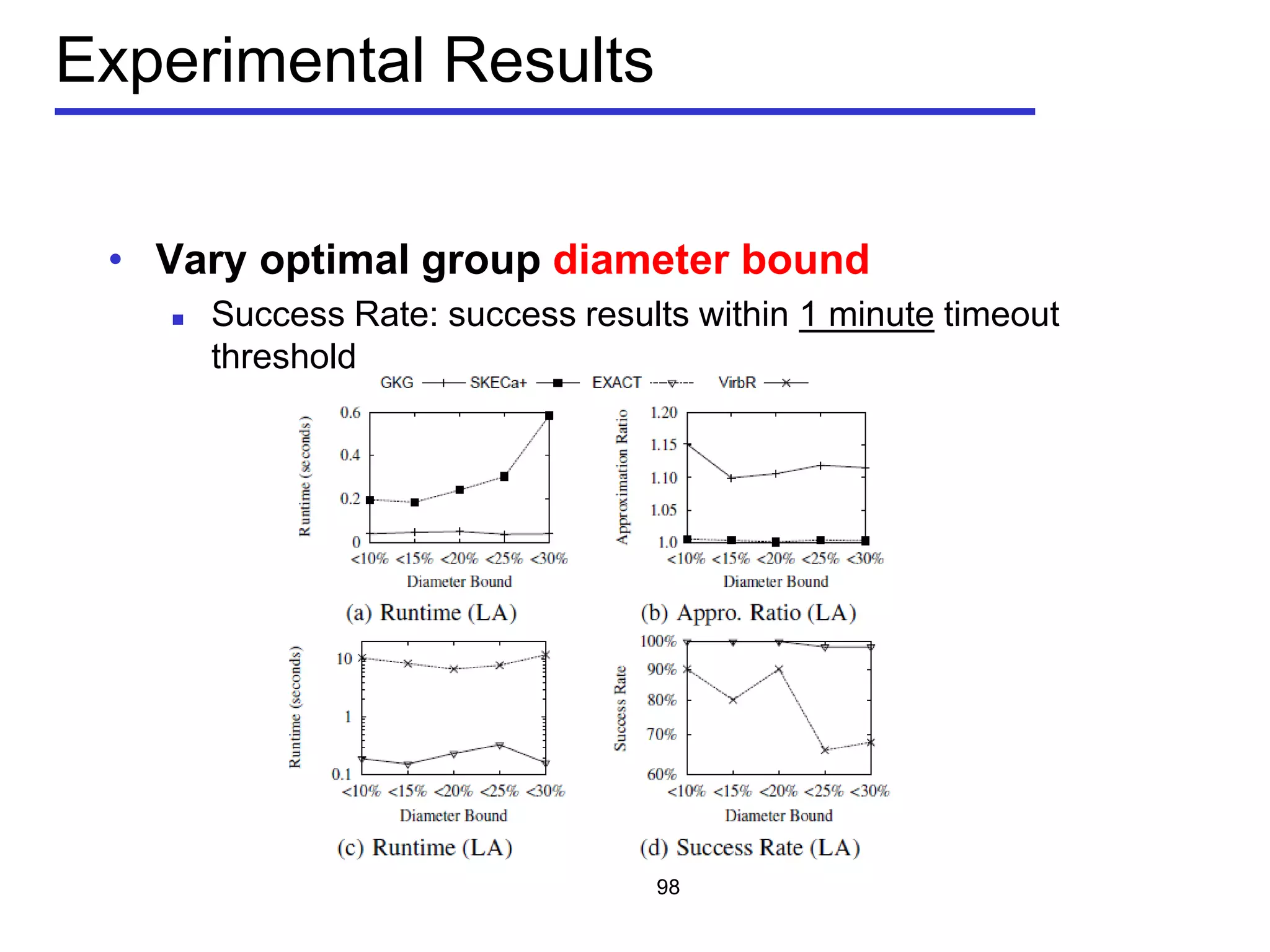


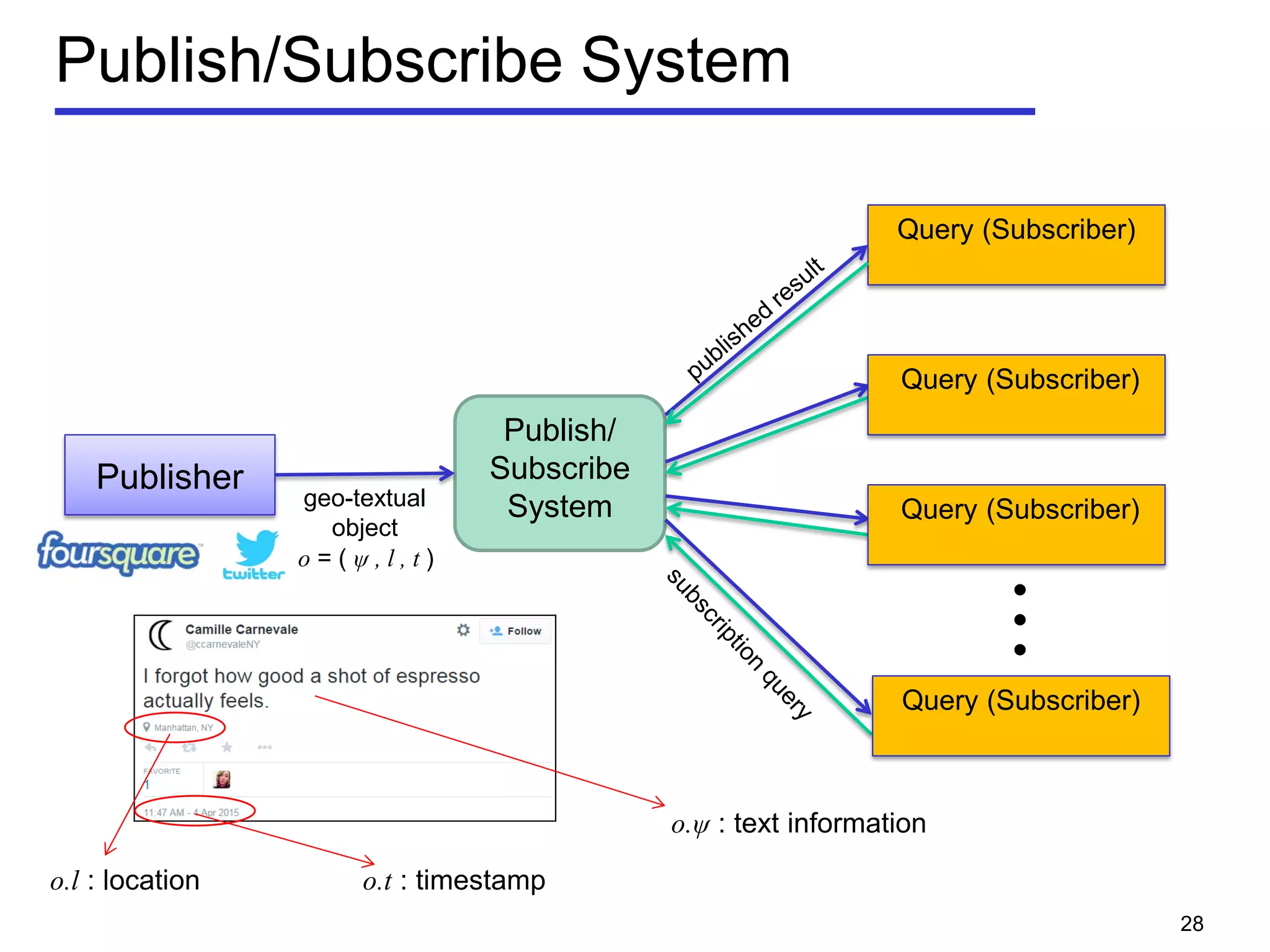
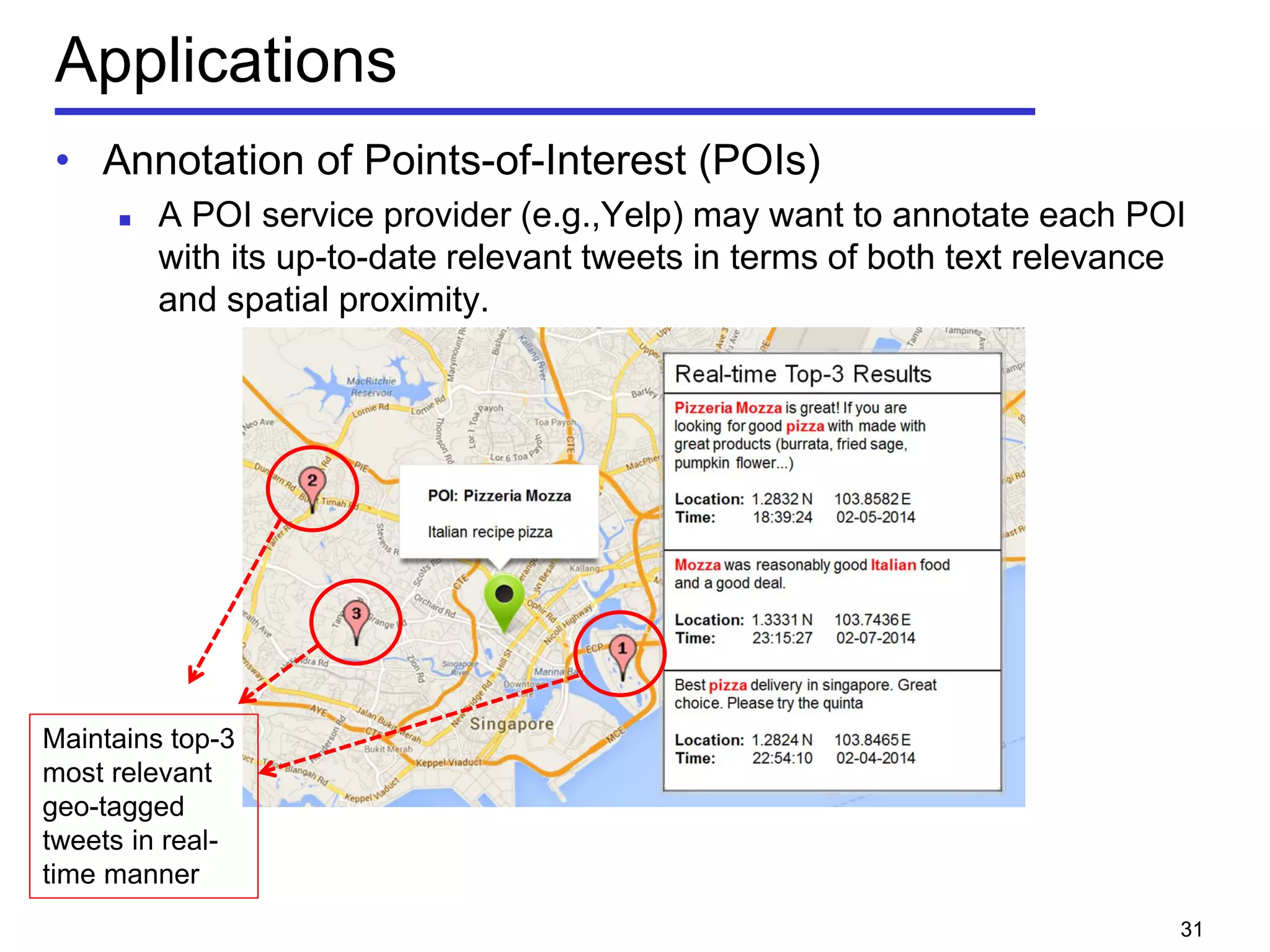
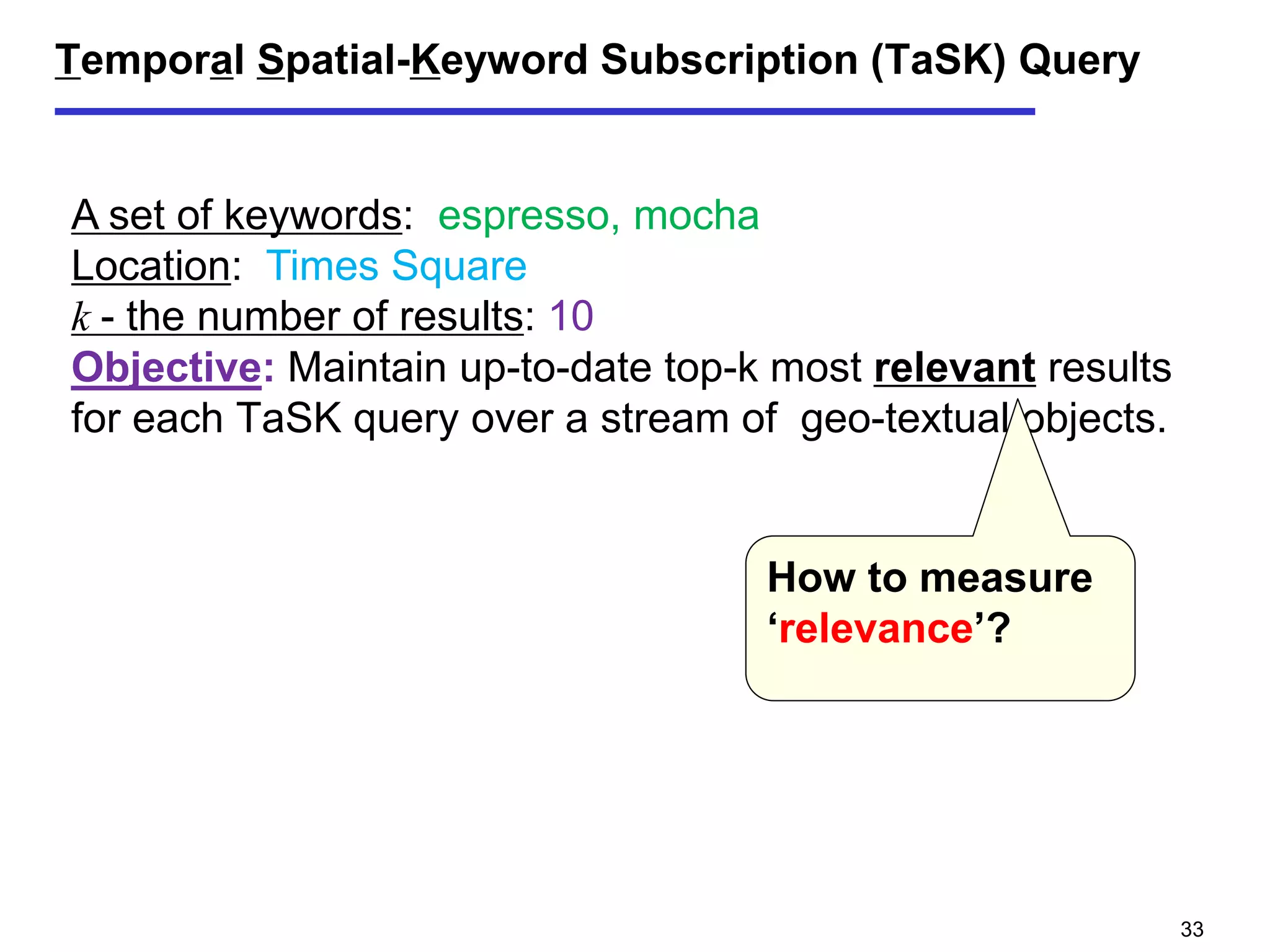
The document discusses geospatial social media data management and context-aware recommendation. It introduces technologies for geo-positioning users and content, and how user generated content from social media is increasingly associated with geo-locations. The document then outlines queries for static geo-textual data, publish/subscribe queries on geo-textual data streams, and personalized, context-aware point-of-interest recommendation based on modeling user behavior from geo-textual data.






































































![[DSC Europe 25] Dobrica Cosic - From Electrons to Innovation: How Granular Da...](https://cdn.slidesharecdn.com/ss_thumbnails/h4qk69zereaumbceubgr-dobrica-cosic-from-electrons-to-innovation-how-granular-data-and-analytics-are--251218085301-b982fb14-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Mathias Halkjær Petersen - The AI workforce revolution.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/3xviexv7q5gojhdsyvat-the-ai-workforce-revolution-251218084820-f3c286ed-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)