Downloaded 54 times

























![User-Item Relevance Models
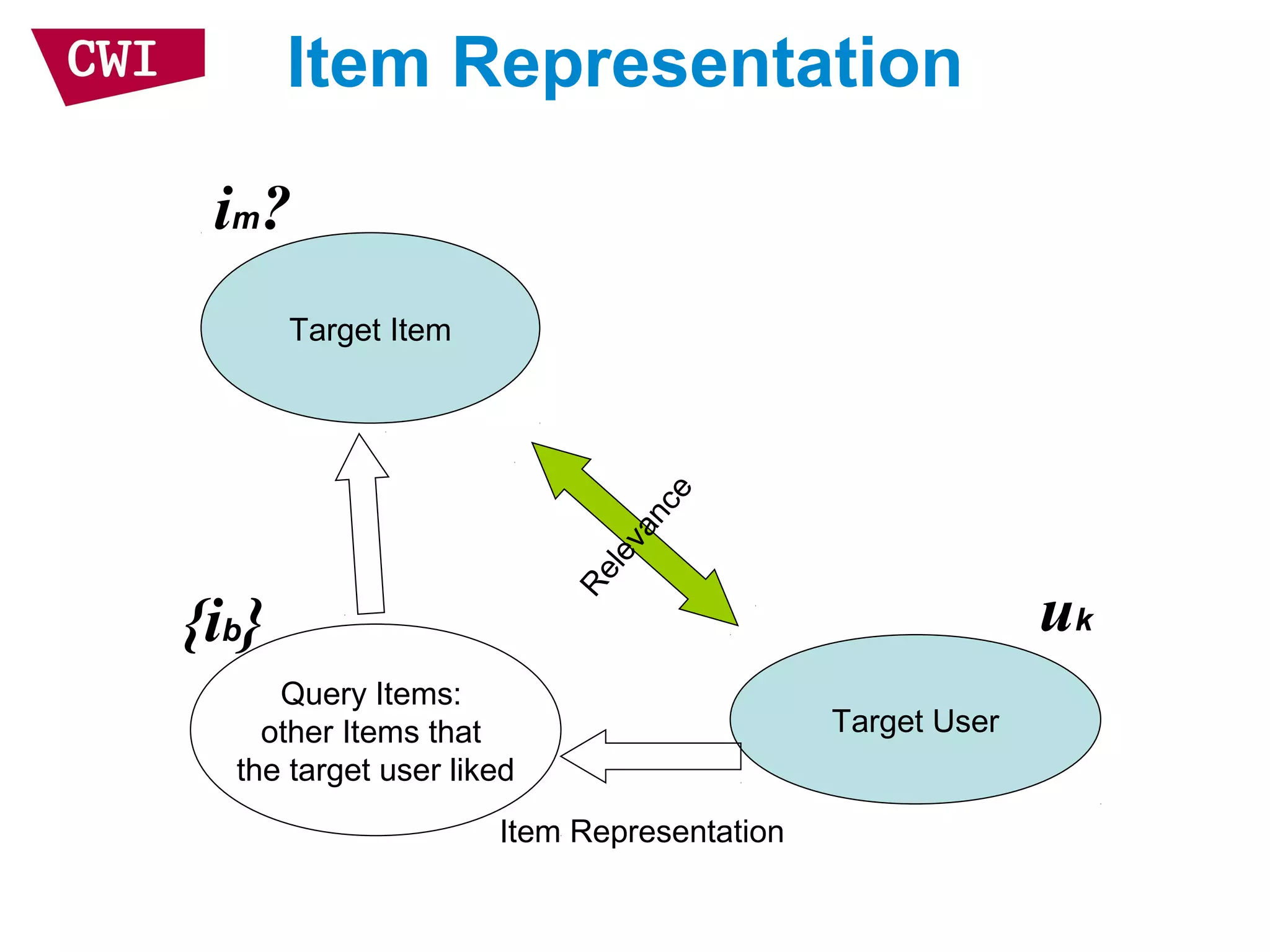
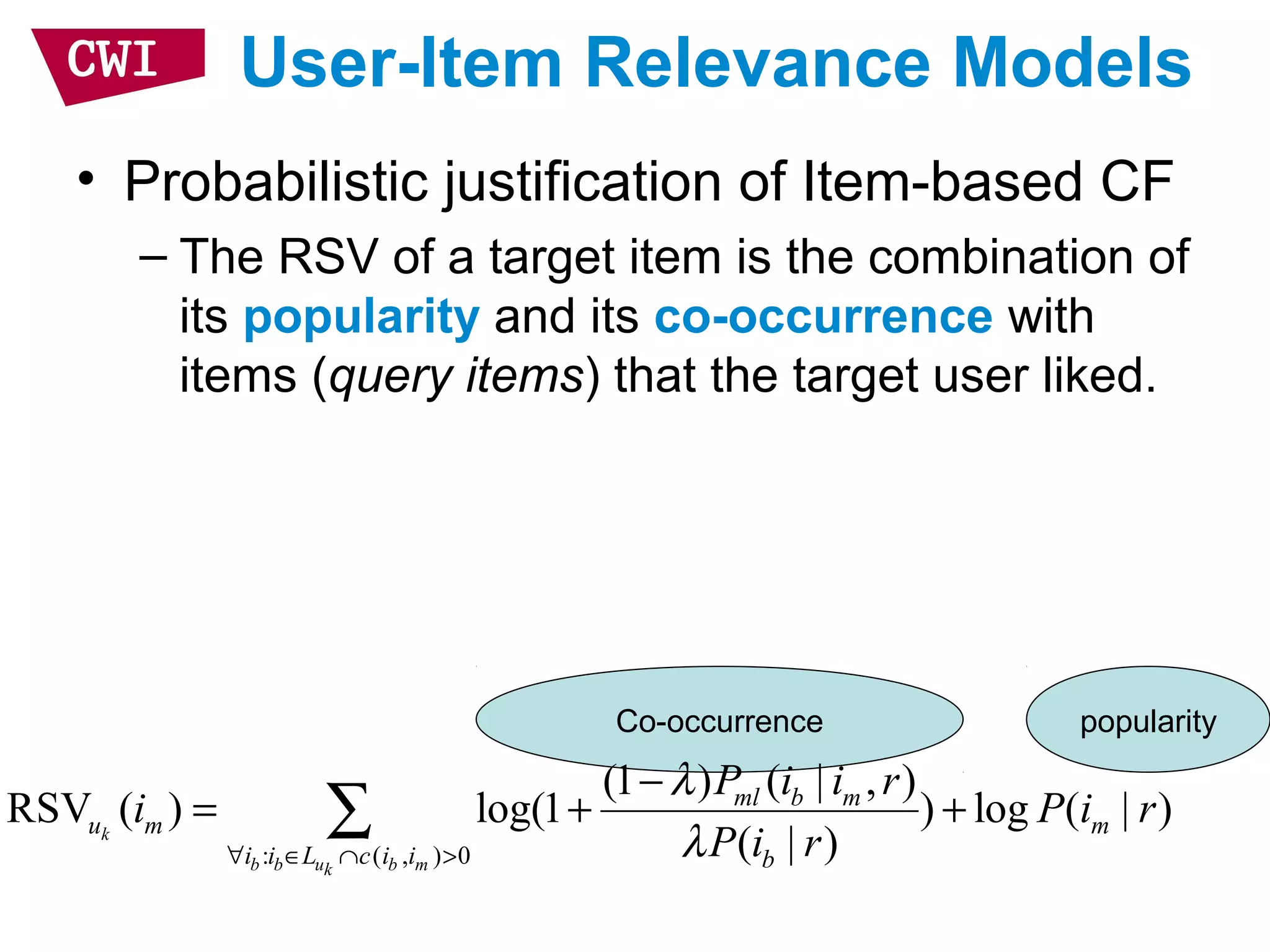
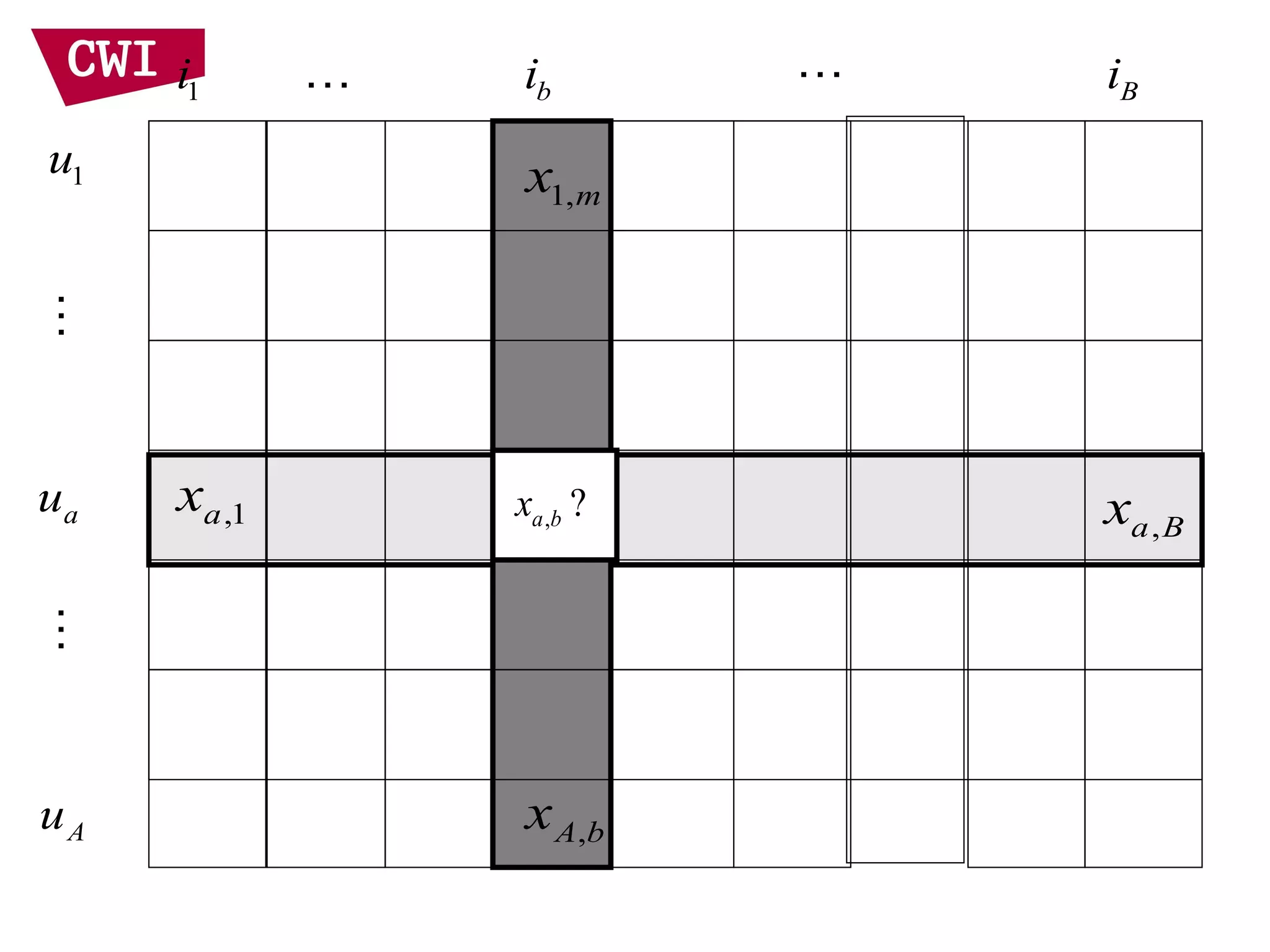
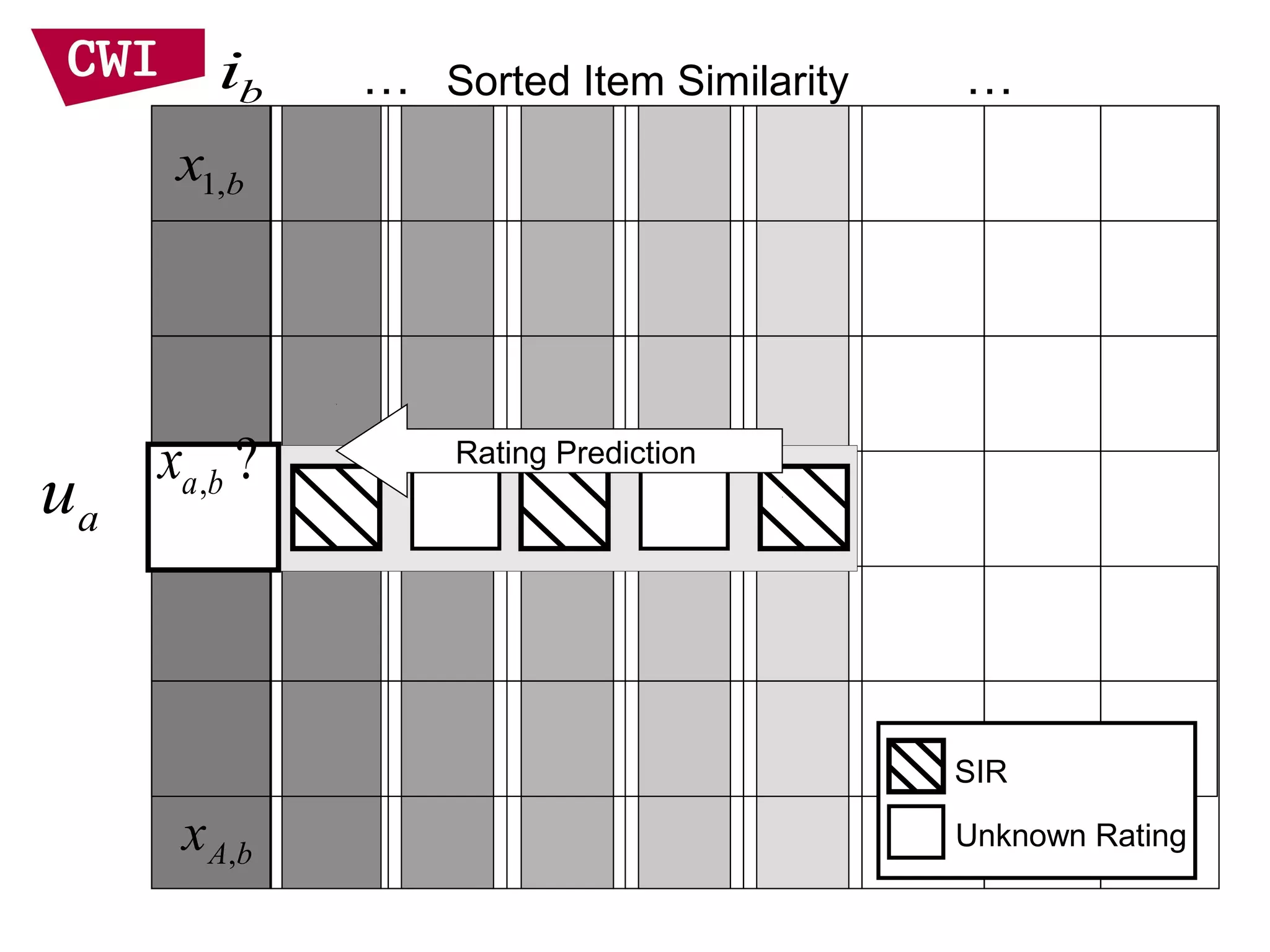
• Item representation
– Use items that I liked to represent target user
– Assume the item “ratings” are independent
– Linear interpolation smoothing to address
sparsity
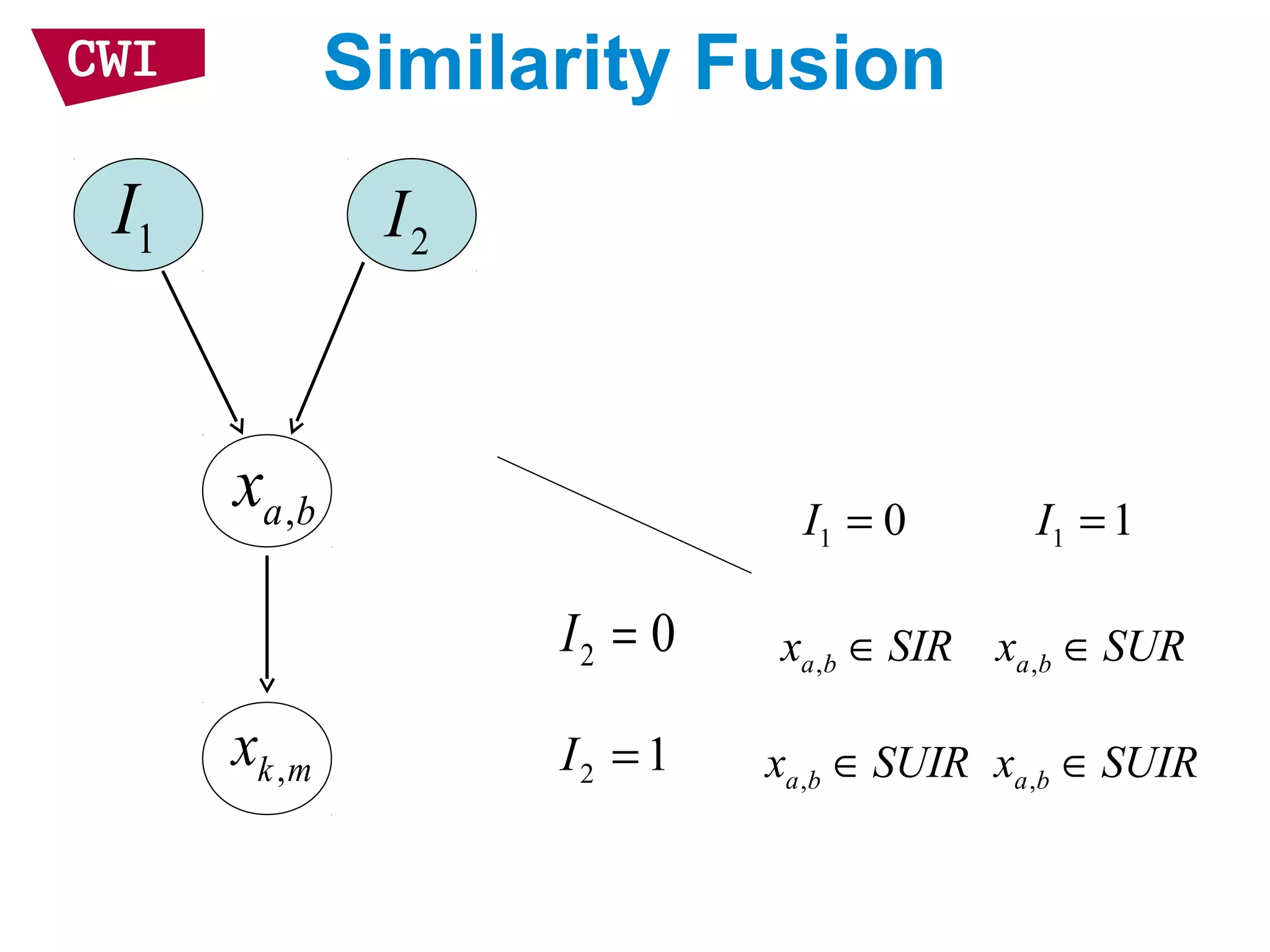
: ( , ) 0
( | , ) ( | , ) ( | )
RSV ( ) log log
( | , ) ( | , ) ( | )
...
(1 ) ( | , )
log(1 ) log ( | )
( | )
k
b b u b mk
m k k m m
u m
m k k m m
ml b m
m
i i L c i i b
P r i u P u r i P r i
i
P r i u P u r i P r i
P i i r
P i r
P i r
λ
λ∀ ∈ ∩ >
= =
−
= + +∑
( | , ) (1 ) ( | , ) ( | )b m ml b m ml bP i i r P i i r P i rλ λ= − +
[0,1] is a parameter to adjust the strength of smoothingλ ∈](https://image.slidesharecdn.com/ir-cf-essir-2015-150922120551-lva1-app6892/75/Models-for-Information-Retrieval-and-Recommendation-38-2048.jpg)

![User-Item Relevance Models
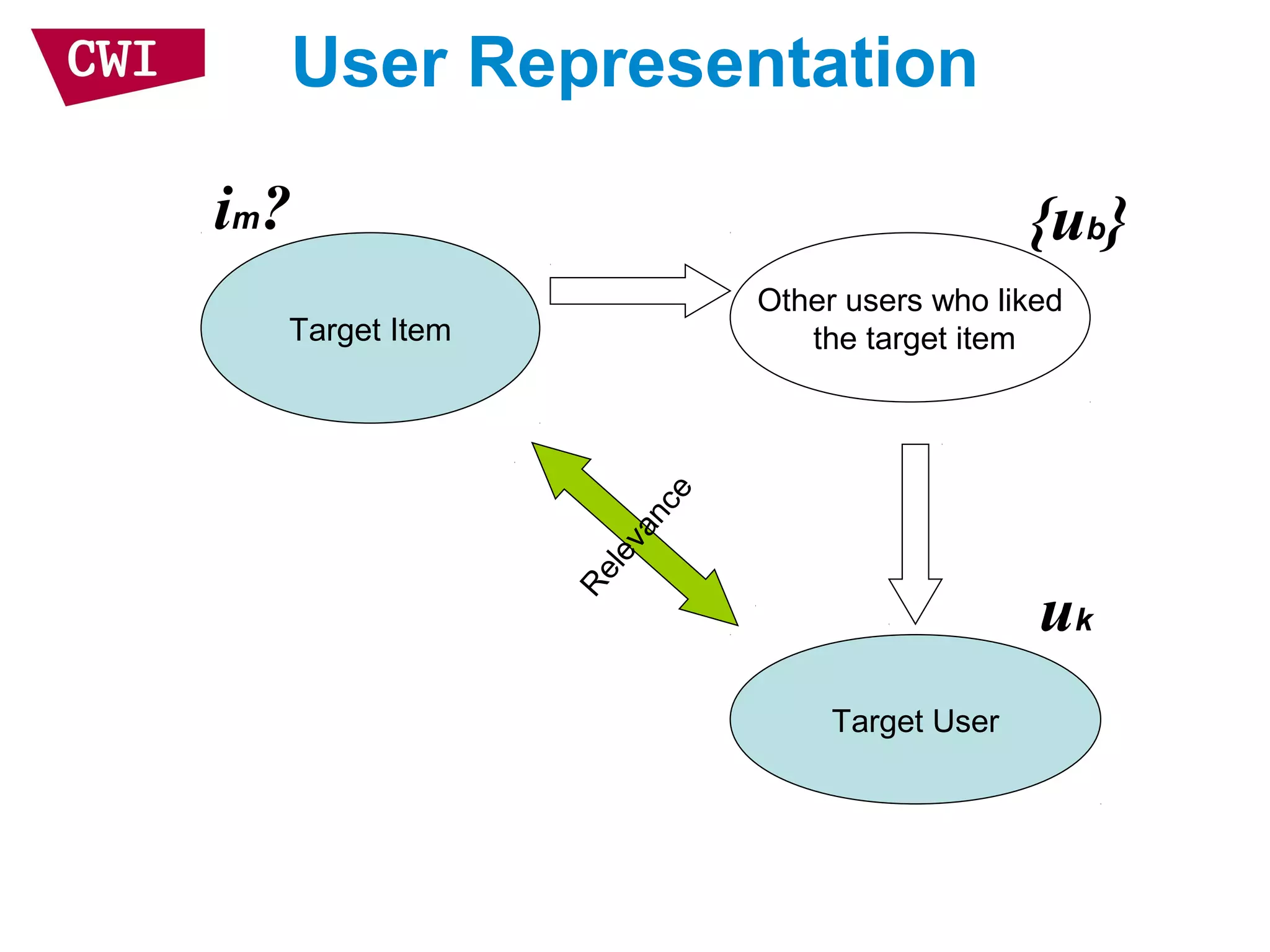
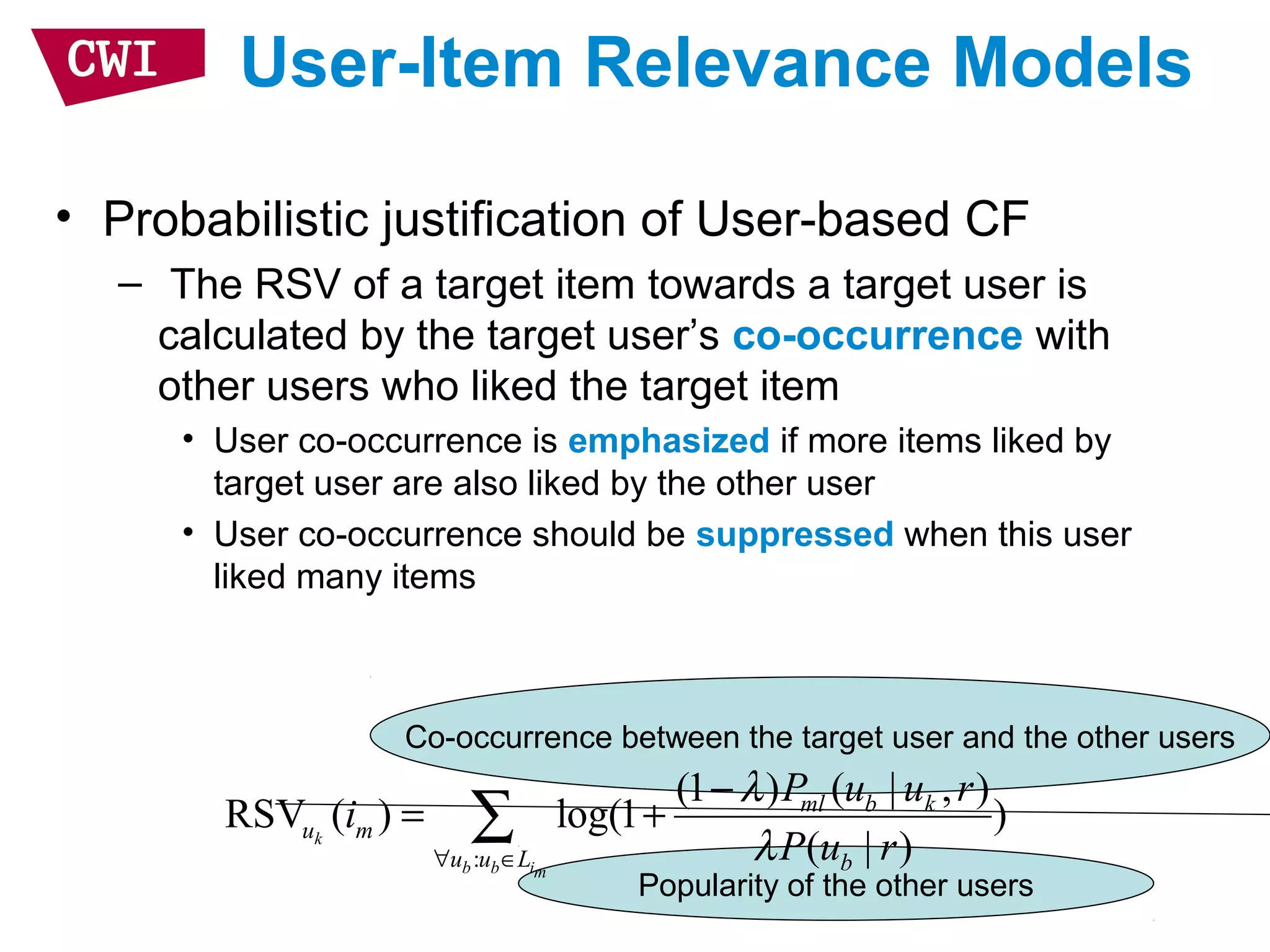
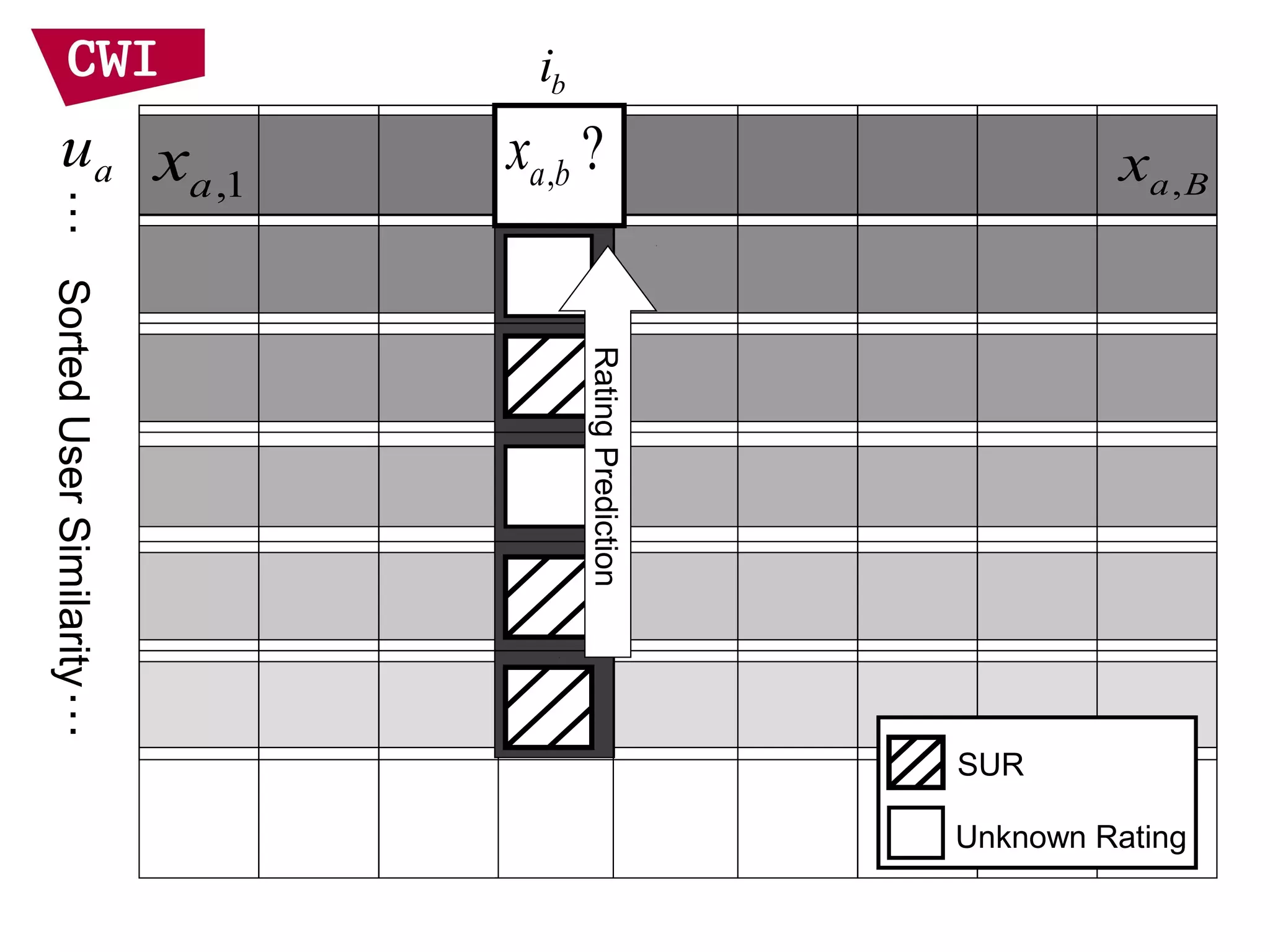
• User representation
– Represent target item by users who like it
– Assume the user profiles are independent
– Linear interpolation smoothing to address sparsity
:
( | , ) ( | , ) ( | )
RSV ( ) log log
( | , ) ( | , ) ( | )
...
(1 ) ( | , )
log(1 )
( | )
k
b b im
m k m k k
u m
m k m k k
ml b k
u u L b
P r i u P i r u P r u
i
P r i u P i r u P r u
P u u r
P u r
λ
λ∀ ∈
= =
−
= +∑
( | , ) (1 ) ( | , ) ( | )ml b k ml b k ml bP u u r P u u r P u rλ λ= − +
[0,1] is a parameter to adjust the strength of smoothingλ ∈](https://image.slidesharecdn.com/ir-cf-essir-2015-150922120551-lva1-app6892/75/Models-for-Information-Retrieval-and-Recommendation-42-2048.jpg)






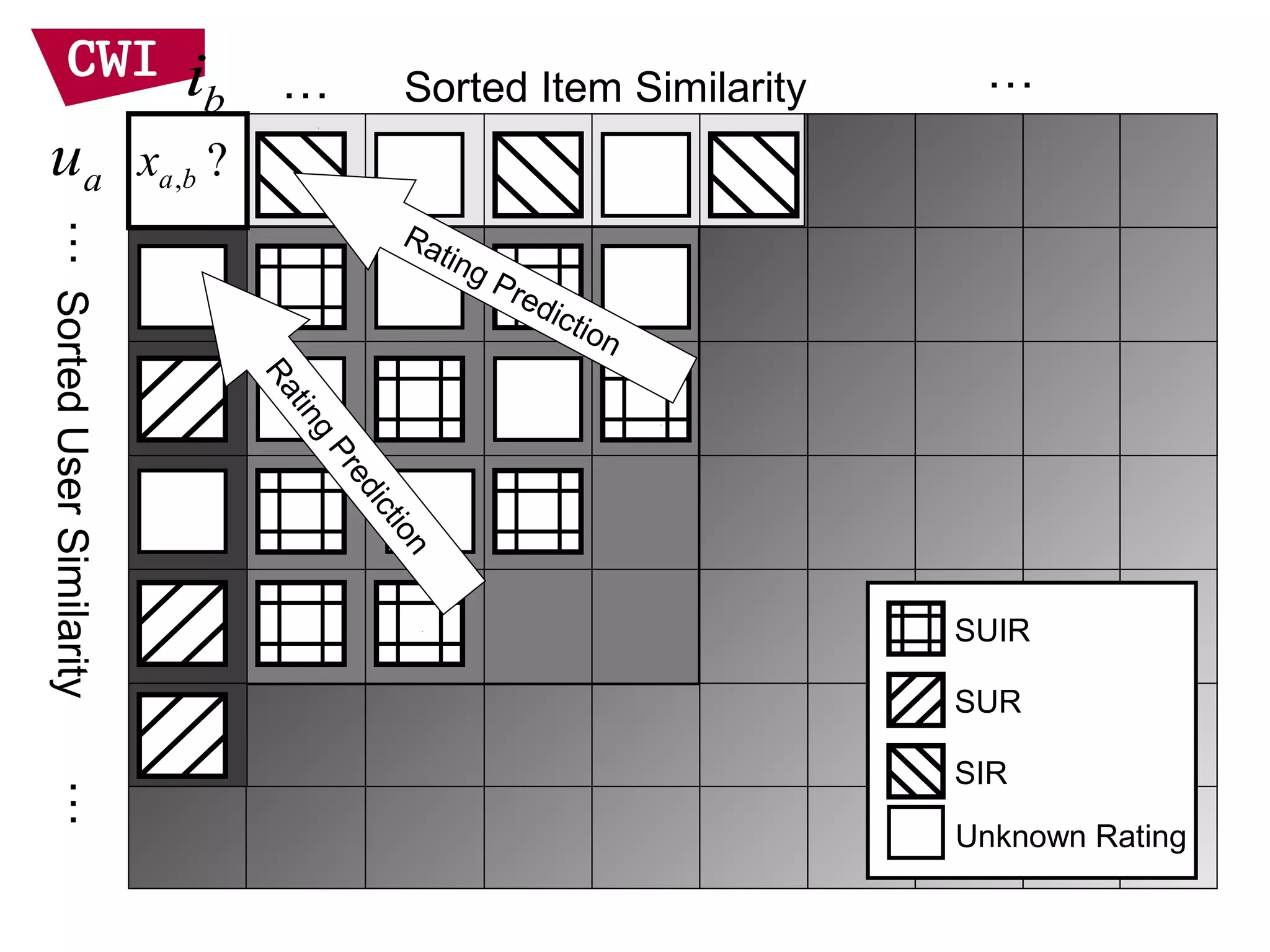


















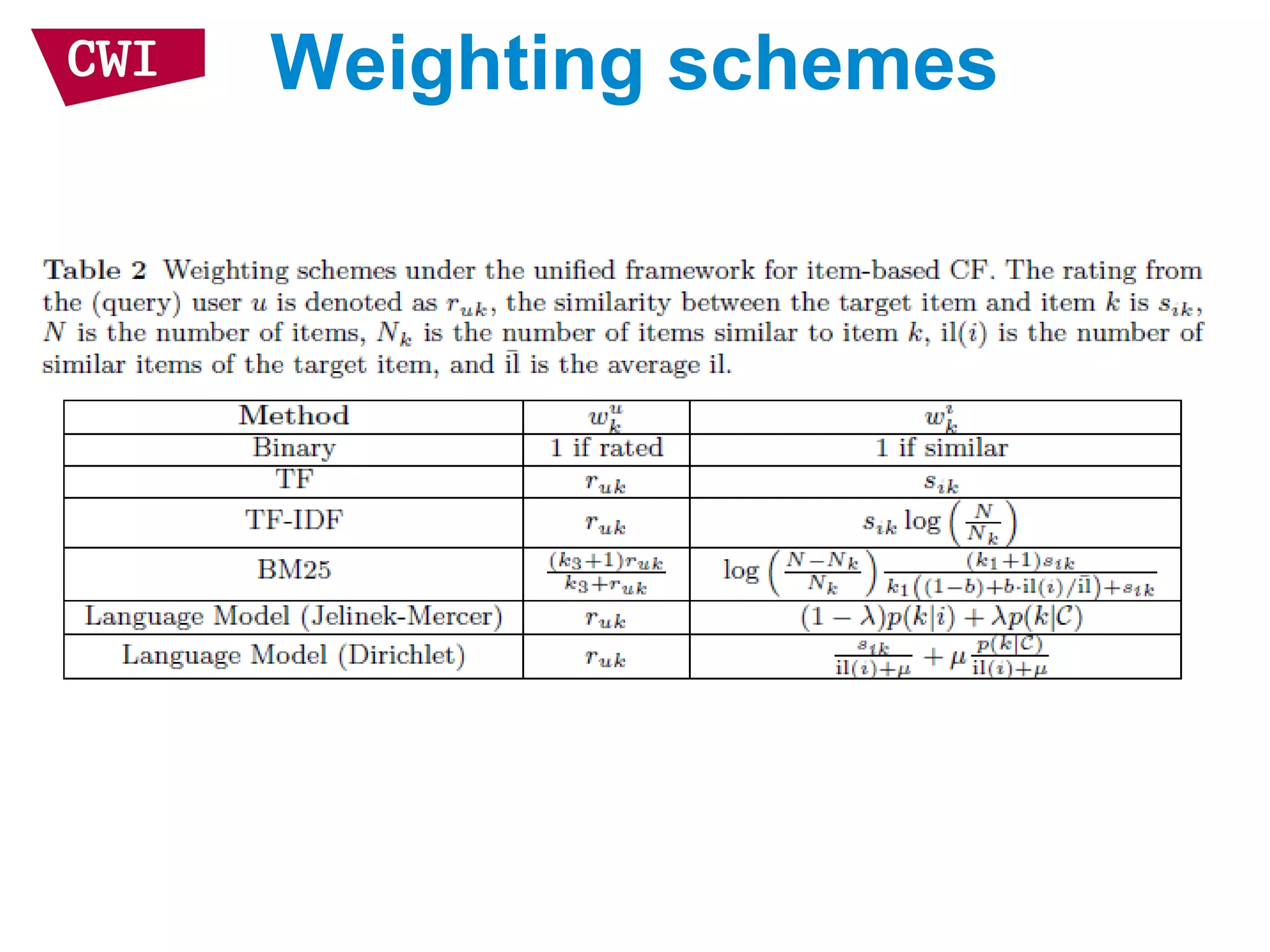
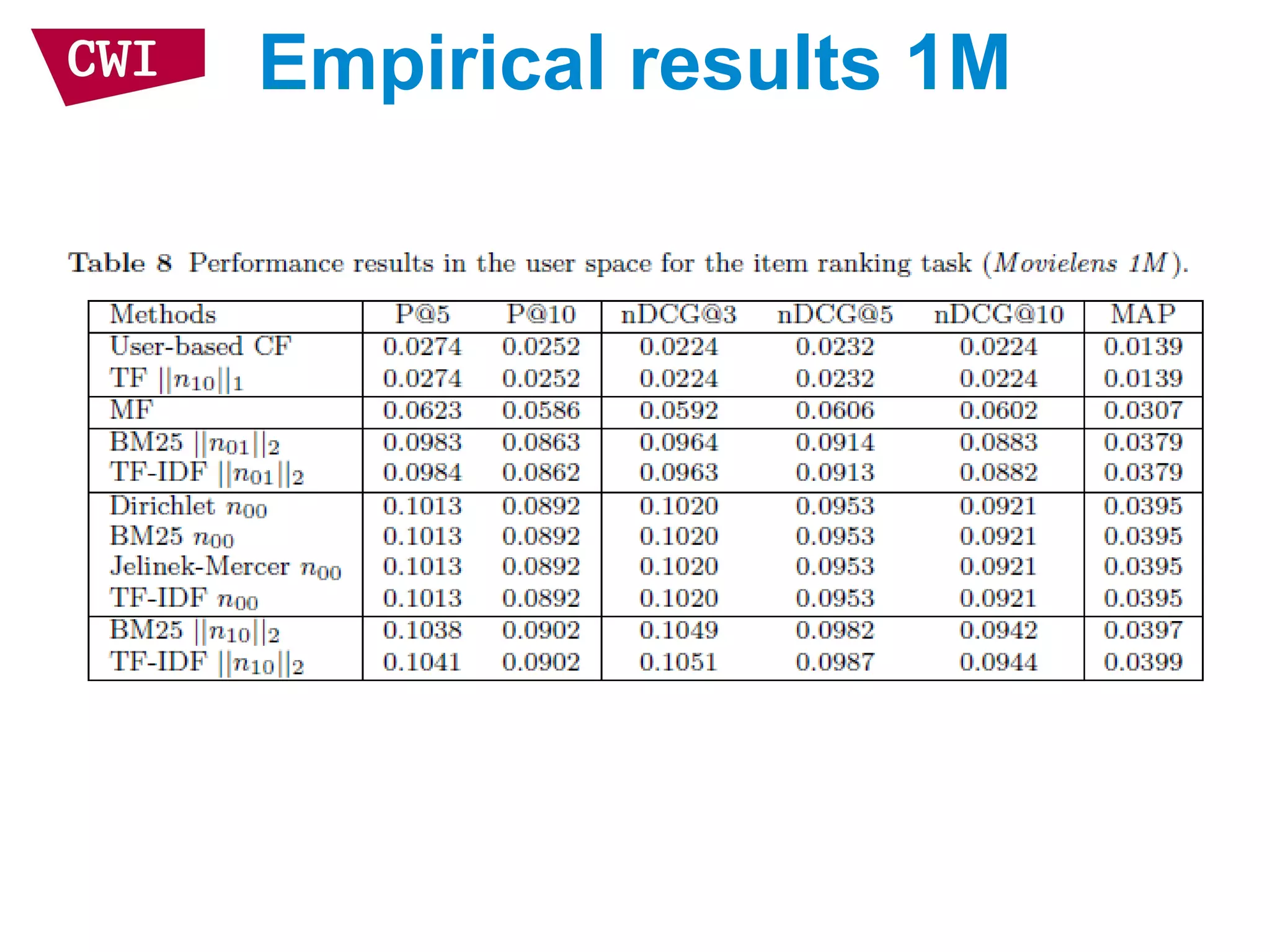
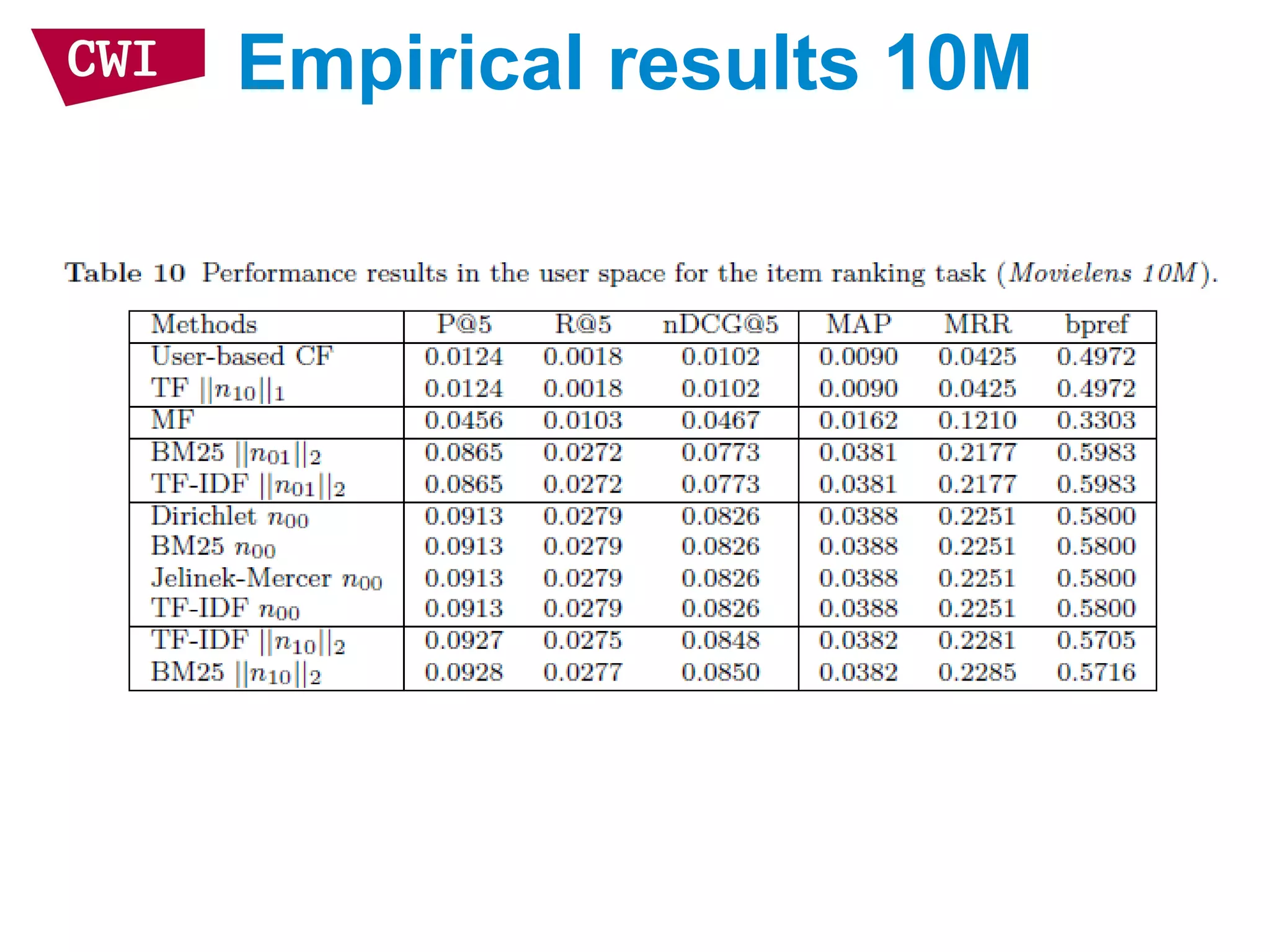
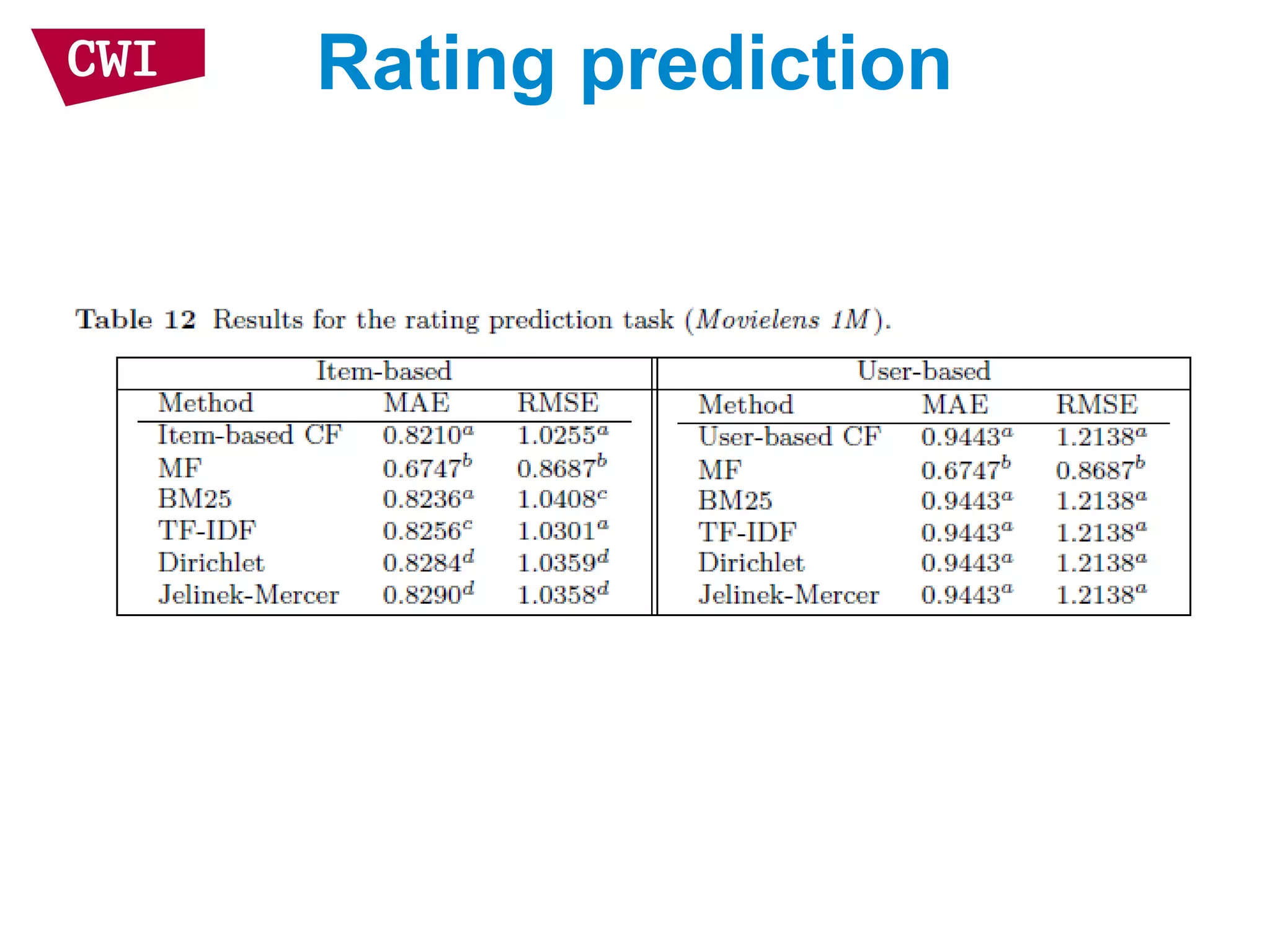












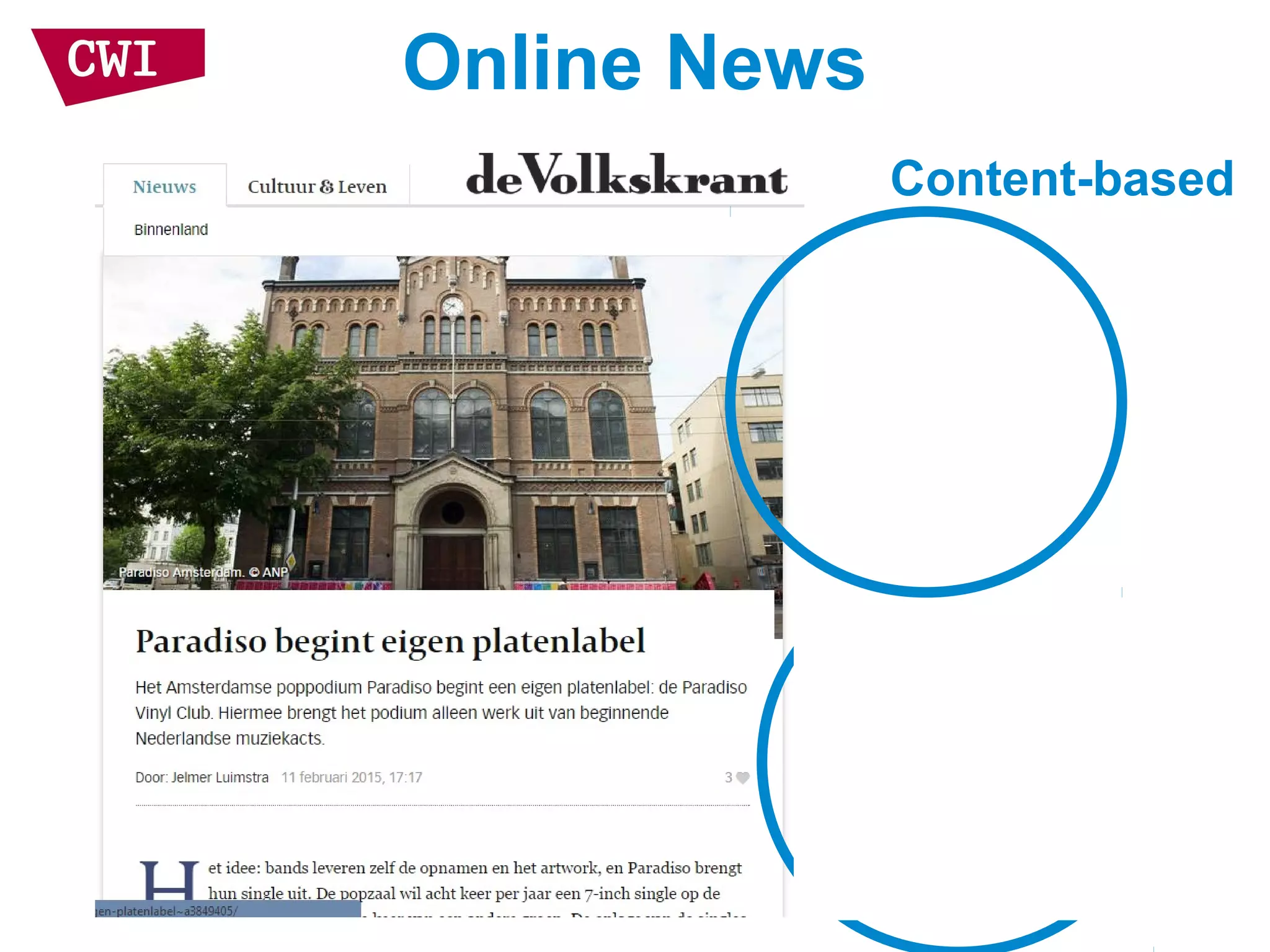
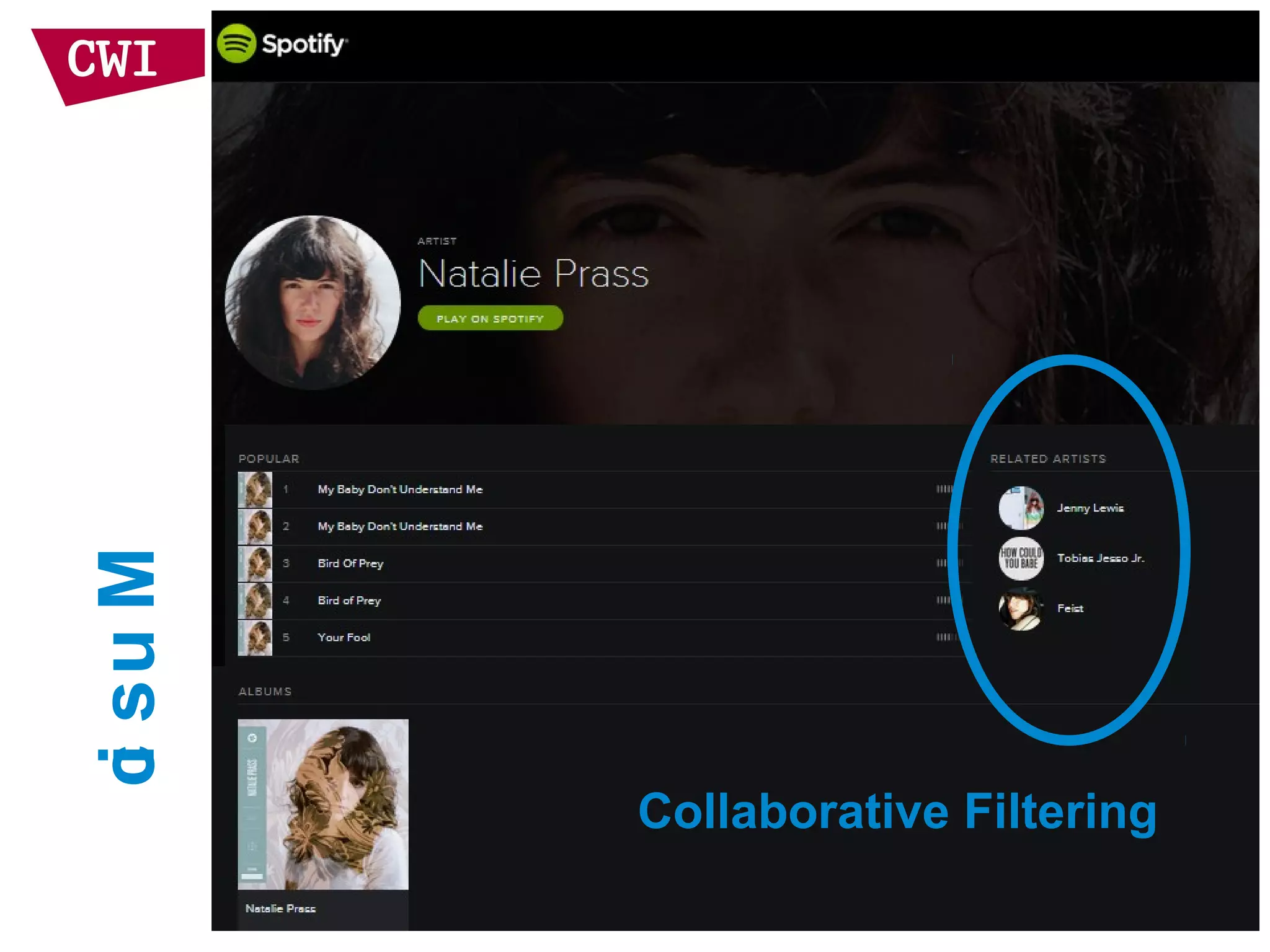
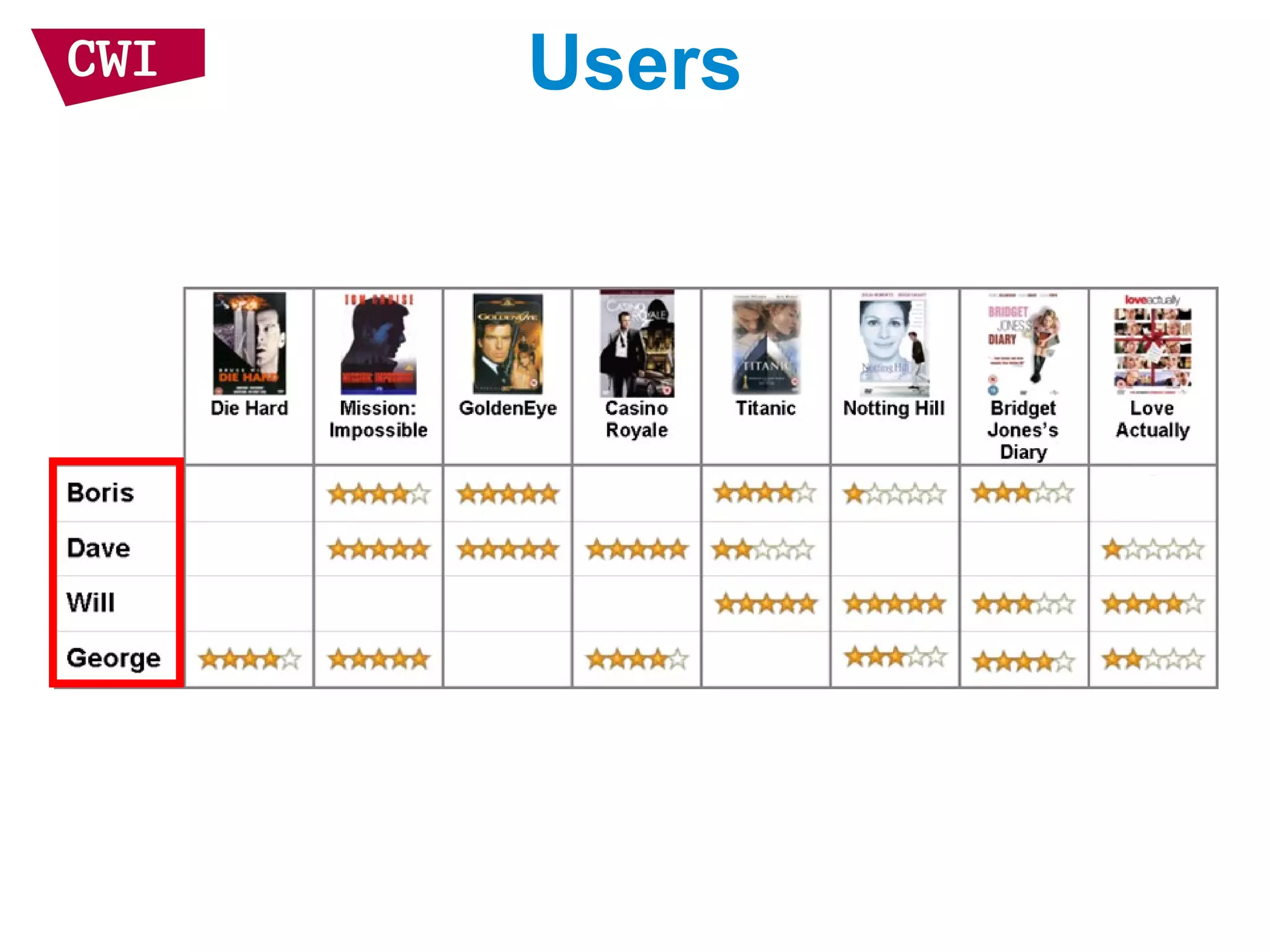
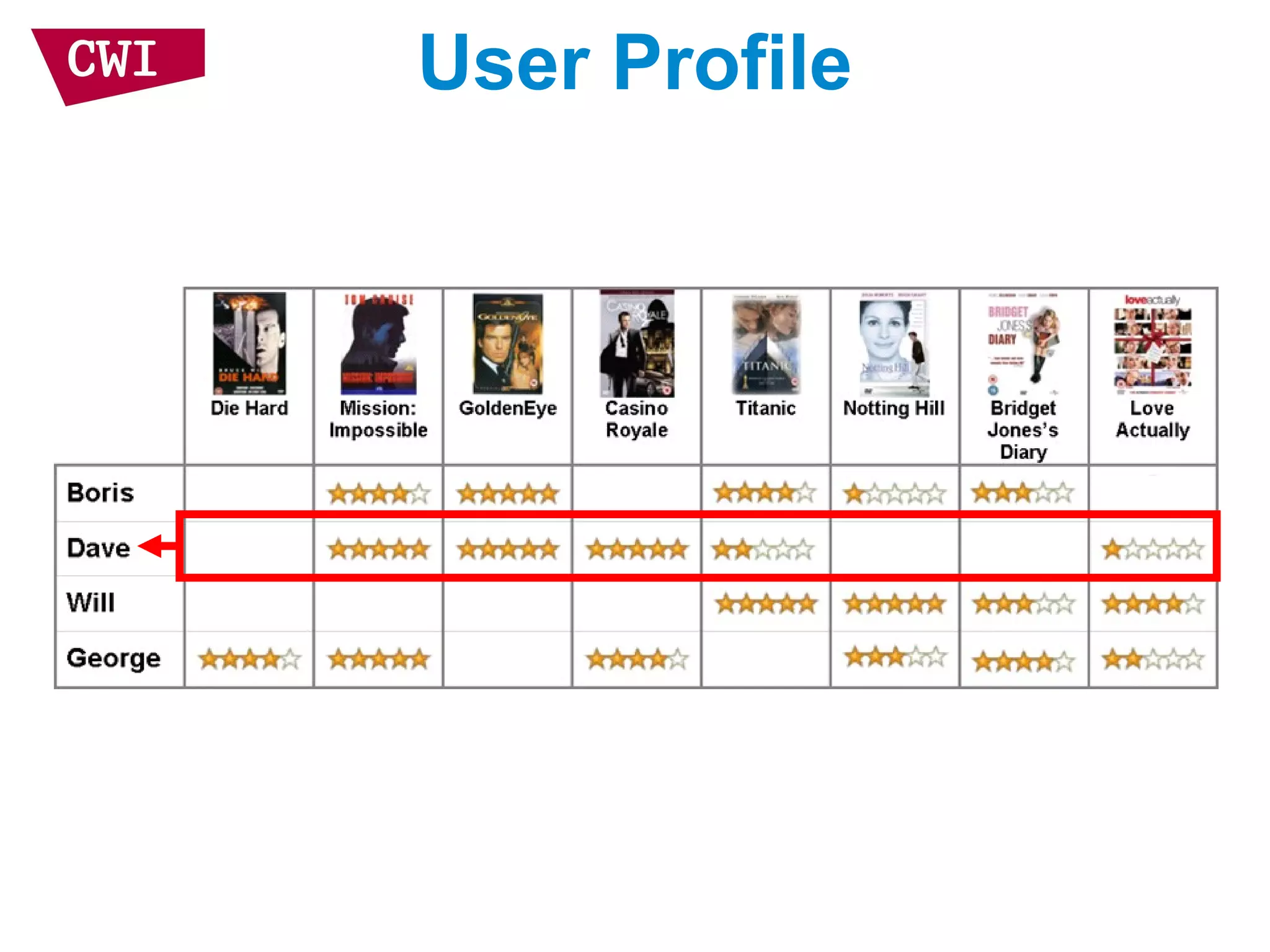
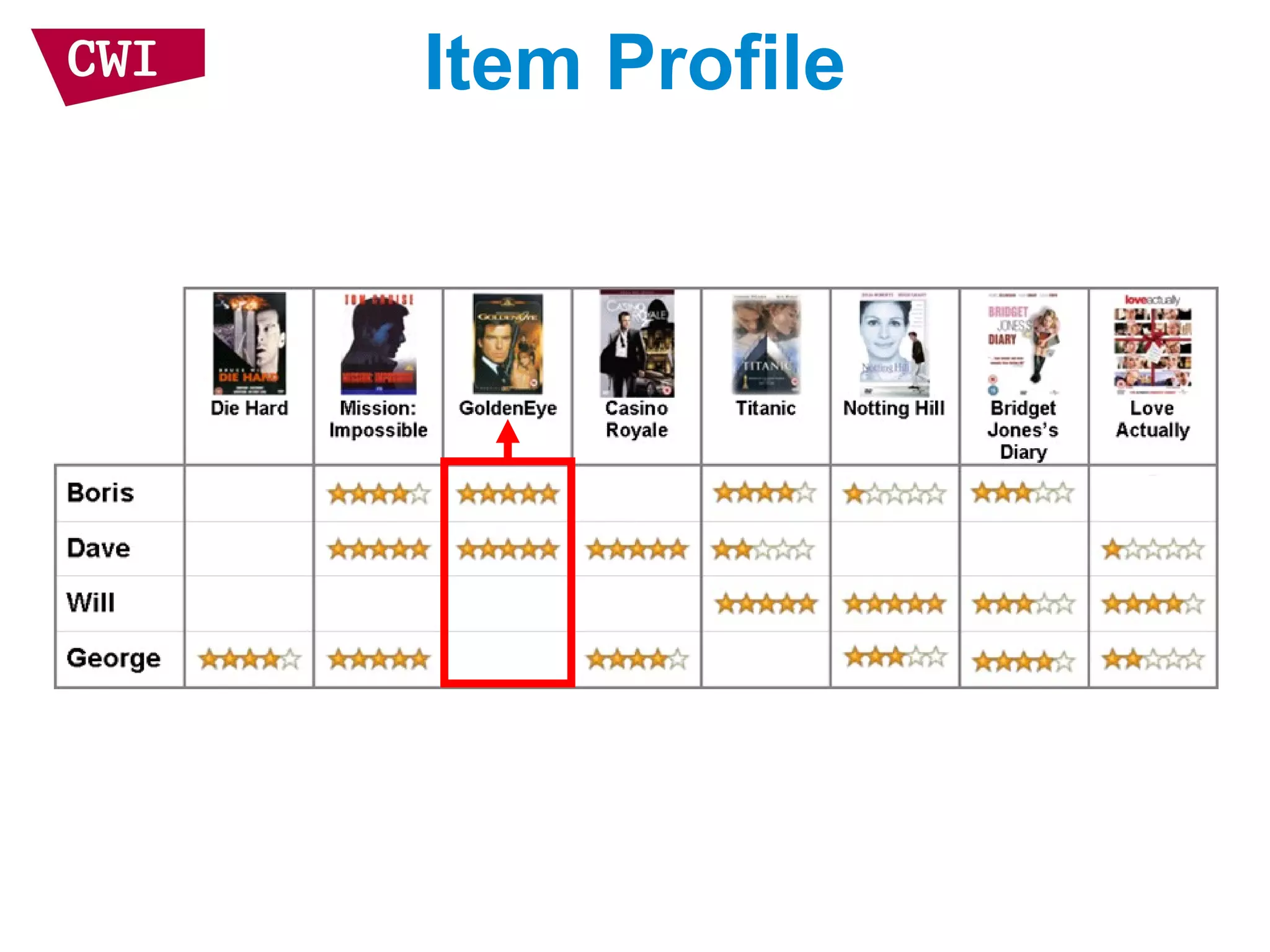
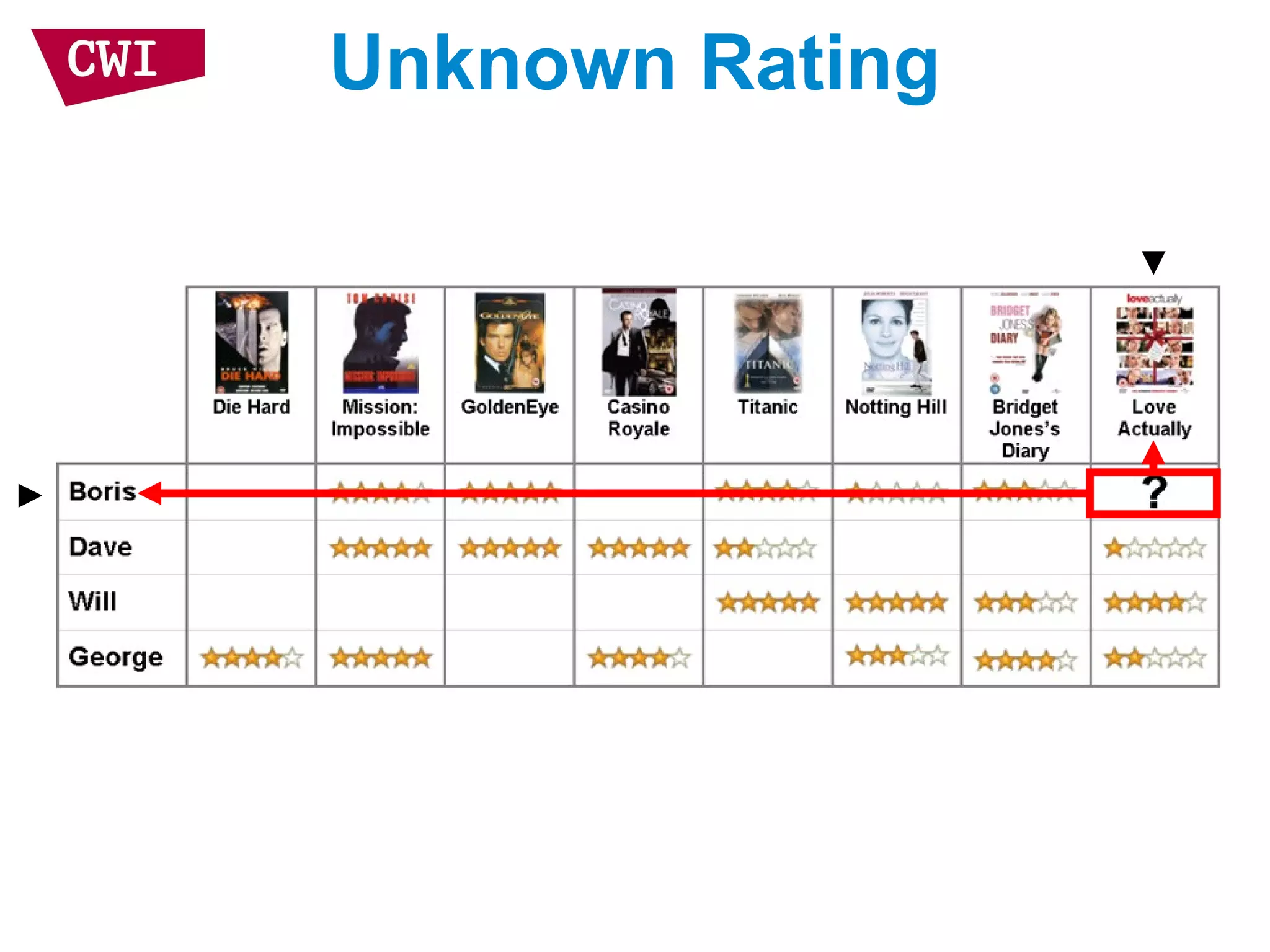
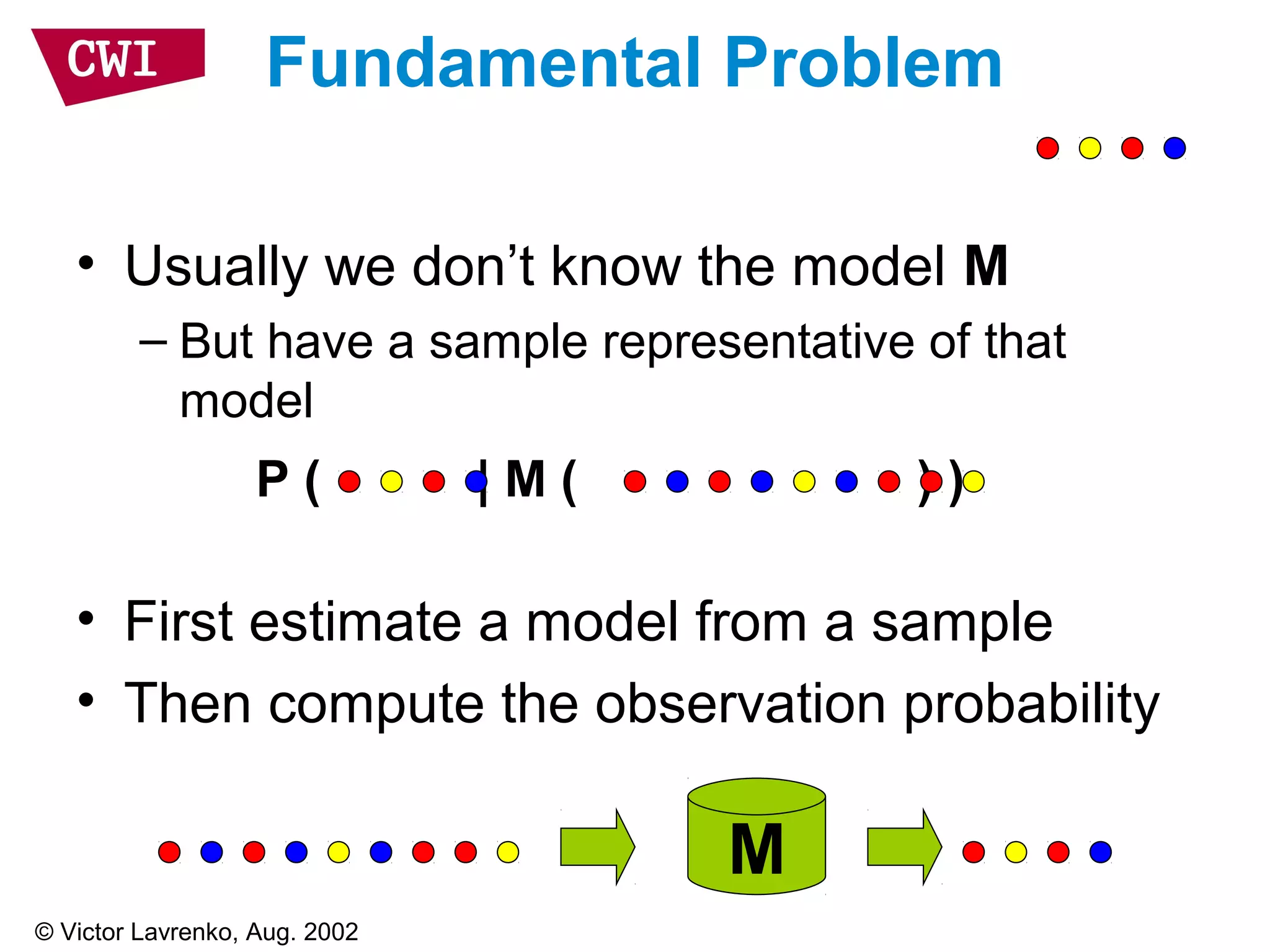
The document discusses the interrelationship between recommendation systems and information retrieval, focusing on collaborative filtering (CF) and language modeling techniques. It highlights the benefits of CF such as overcoming feature representation issues and provides a probabilistic framework for user-item relevance modeling, addressing sparsity problems in the data. Additionally, it explores the use of user and item representations, emphasizing the integration of popularity and co-occurrence in CF systems for better recommendation performance.
































![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)










![Language Models for Collaborative Filtering Neighbourhoods [ECIR '16 Slides]](https://cdn.slidesharecdn.com/ss_thumbnails/slides-2016-lmforneigh-160411083912-thumbnail.jpg?width=640&height=640&fit=bounds)











































