Download as PDF, PPTX









![{
"table": "trips",
"joins": [
{
"alias": "g",
"table": "geofences",
"conditions": [
"geography_intersects(request_at, g.shape)"
]
}
], "dimensions": [
{
"sqlExpression": "request_at",
"timeBucketizer": "day",
"timeUnit": "millisecond"
}
], "measures": [
{
"sqlExpression": "count(*)",
"rowFilters": [
"status='completed'"
]
}
], "rowFilters": [
"city_id=1",
"g.uuid=0x0A"
], "timeFilter": {
"column": "request_at",
"from": "yesterday",
"to": "yesterday"
},
"timezone": "America/Los_Angeles"
}
Example](https://image.slidesharecdn.com/apollostratapublic-170406202756/85/Real-Time-Analytics-at-Uber-Scale-18-320.jpg)




![Why SQL is hard for time series OLAP
● #completed_trips / #requested_trips
○ SUM(CASE WHEN trips.status=’completed’ THEN 1 ELSE 0 END) / SUM(CASE WHEN trips.status!=’ignored’ THEN 1 ELSE 0 END)
○ SELECT …, _1.completed / _2.requested FROM (SELECT …, COUNT(*) as completed FROM trips WHERE status=’completed’ GROUP BY
...) AS _1 JOIN (SELECT …, COUNT(*) as requested FROM trips WHERE status!=’ignored’ GROUP BY ...) AS _2 ON ...
○ Filters make measures complex
Field Value
Measure[0].SQLExpression count(*)
Measure[0].Filters status=’completed’
Measure[0].Alias completed
Measure[1].SQLExpression count(*)
Measure[1].Filters status!=’ignored’
Measure[1].Alias requested
Measure[2].SQLExpression completed / requested](https://image.slidesharecdn.com/apollostratapublic-170406202756/85/Real-Time-Analytics-at-Uber-Scale-23-320.jpg)













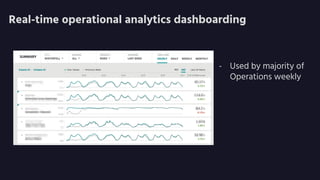
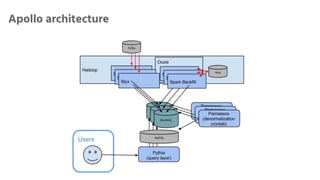
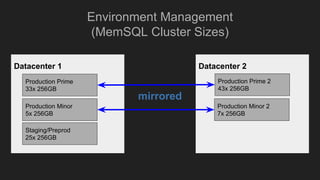
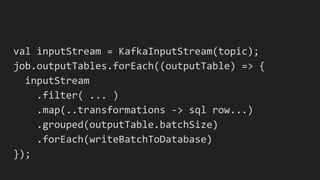
Apollo is a real-time analytics platform at Uber designed for immediate visibility and efficient data querying, with low ingest latency and strong data correctness. It features a custom analytical query language optimized for time series data, providing flexibility and ease of use. Future development plans include enhancements in onboarding and schema management, along with improvements in technology and automation.























































































