















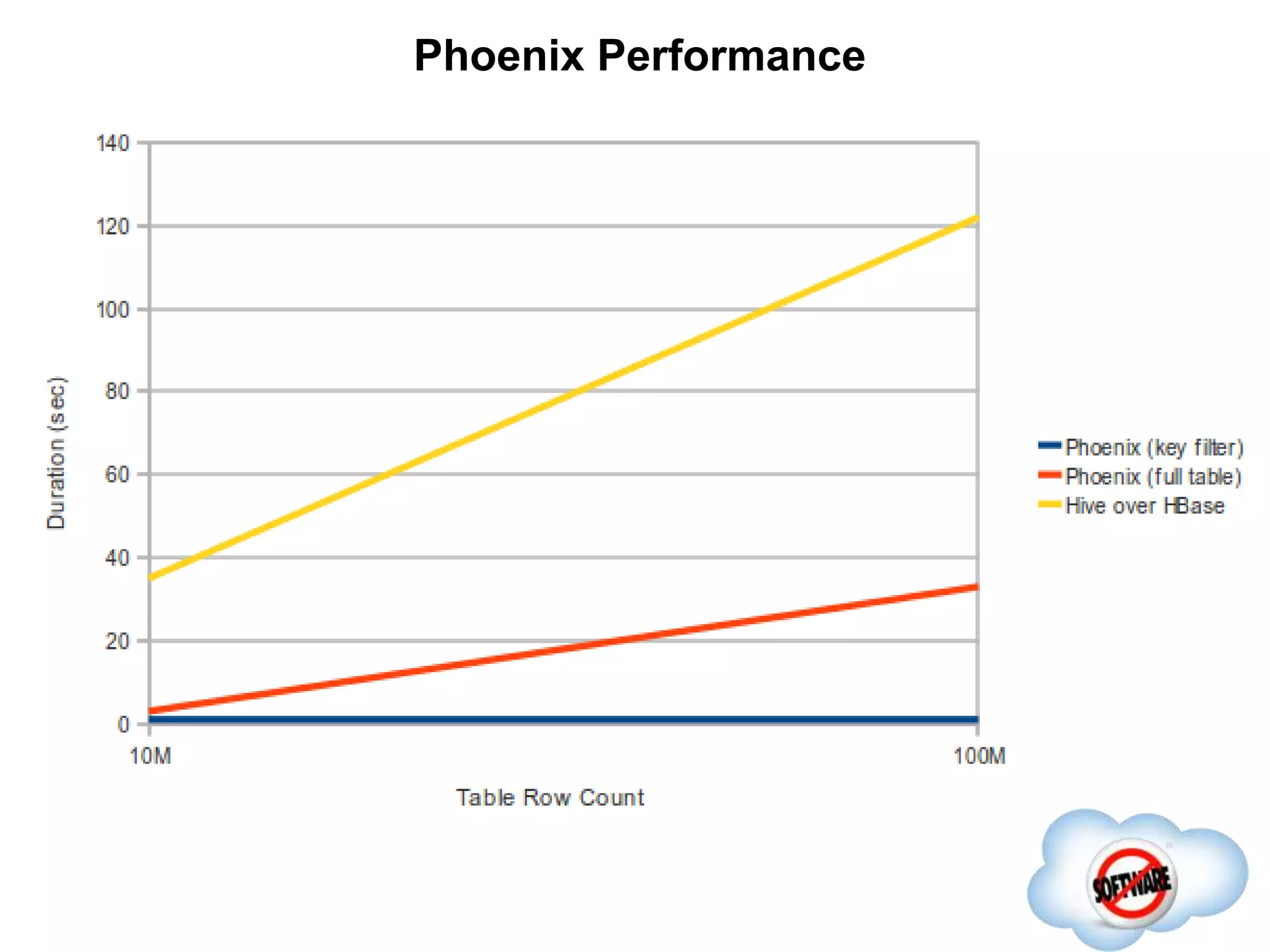




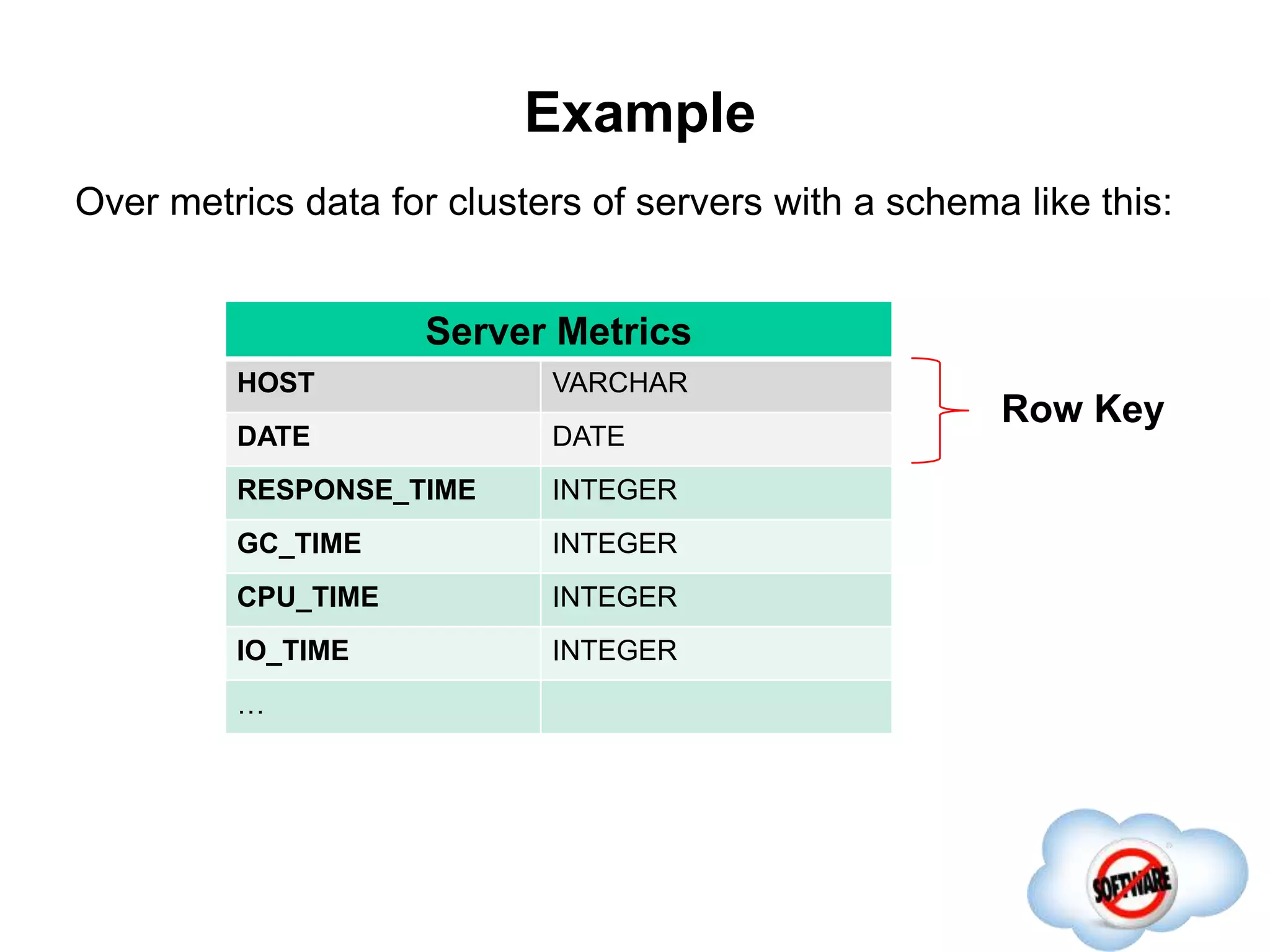
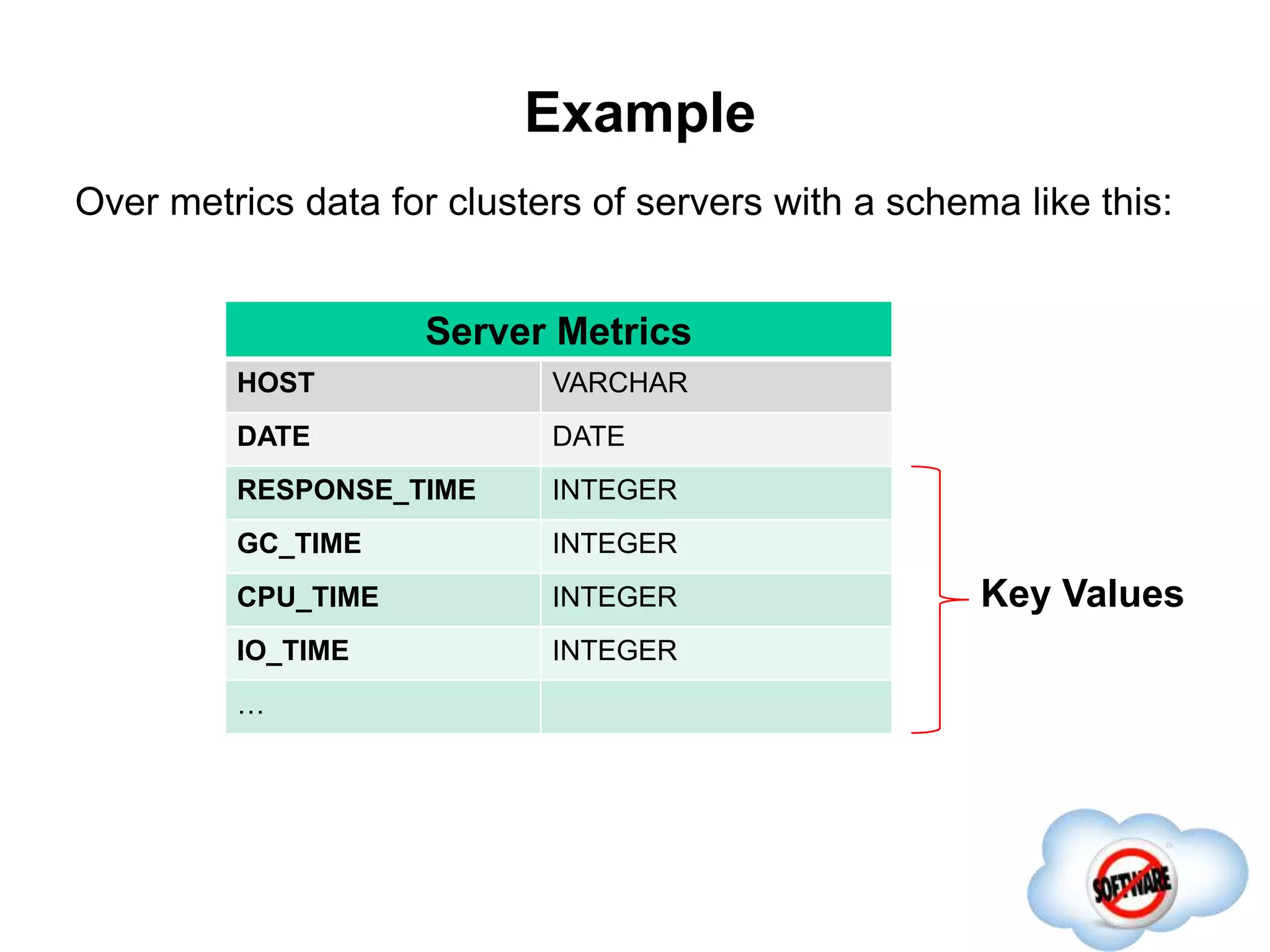


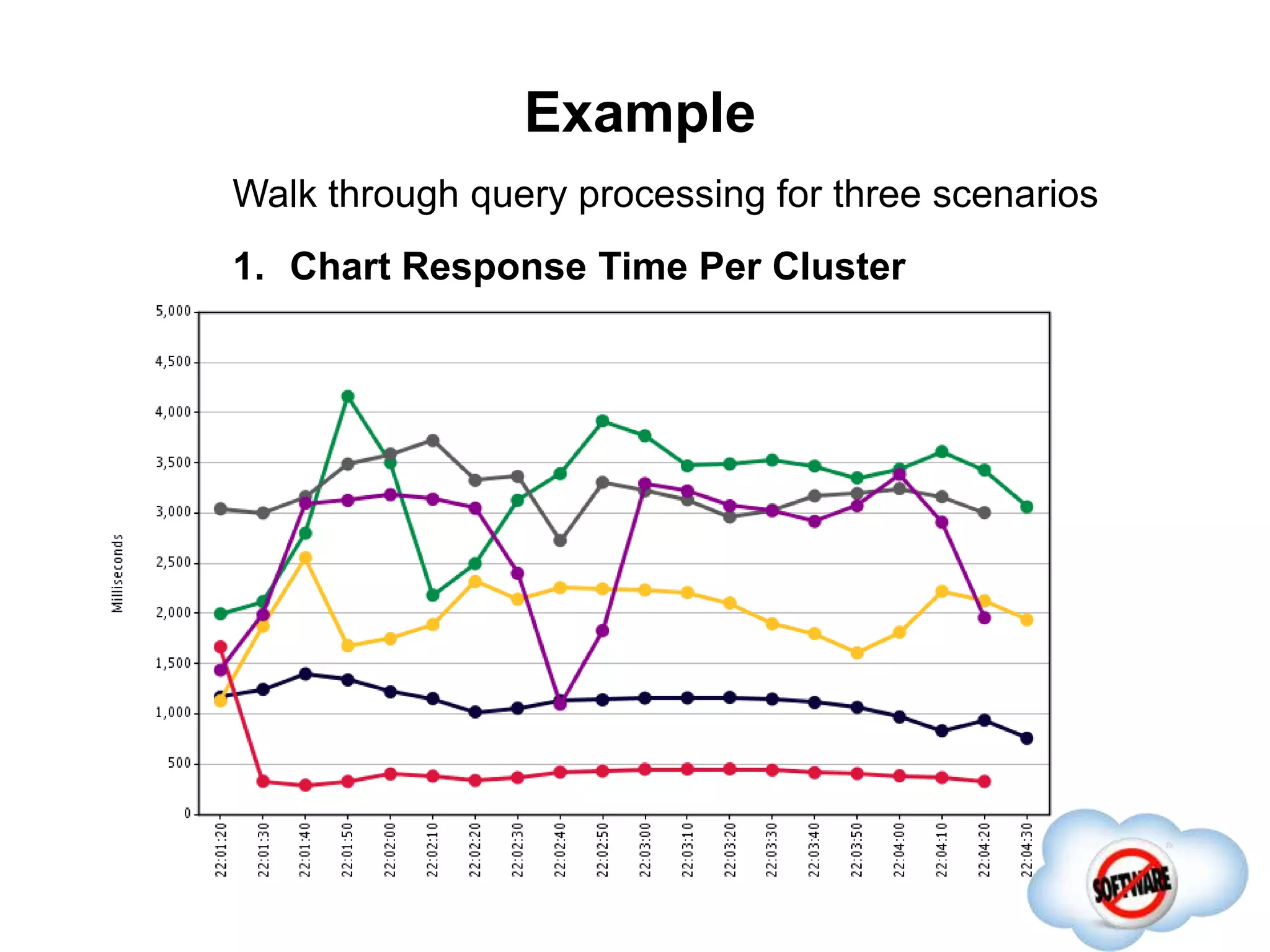

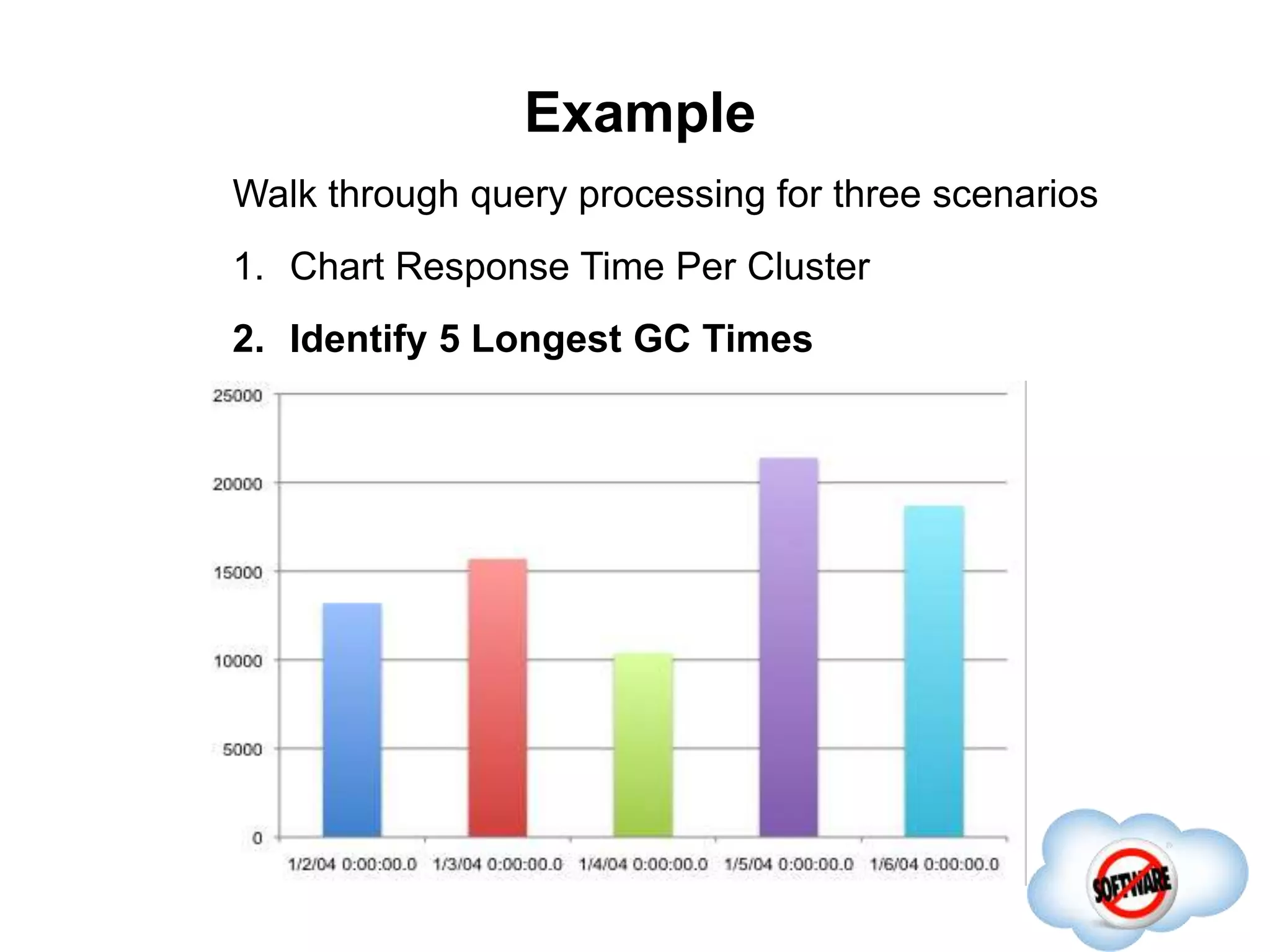







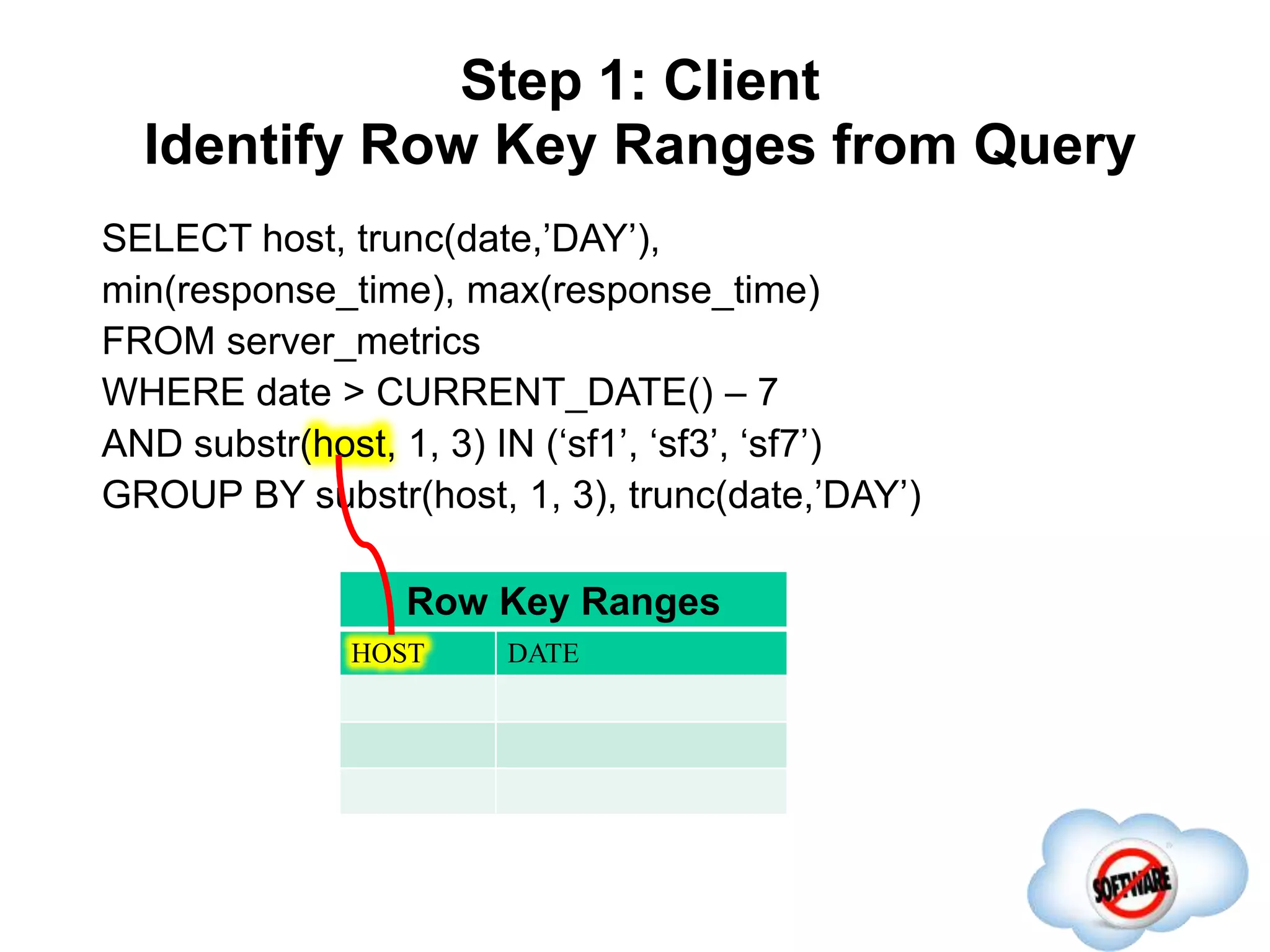
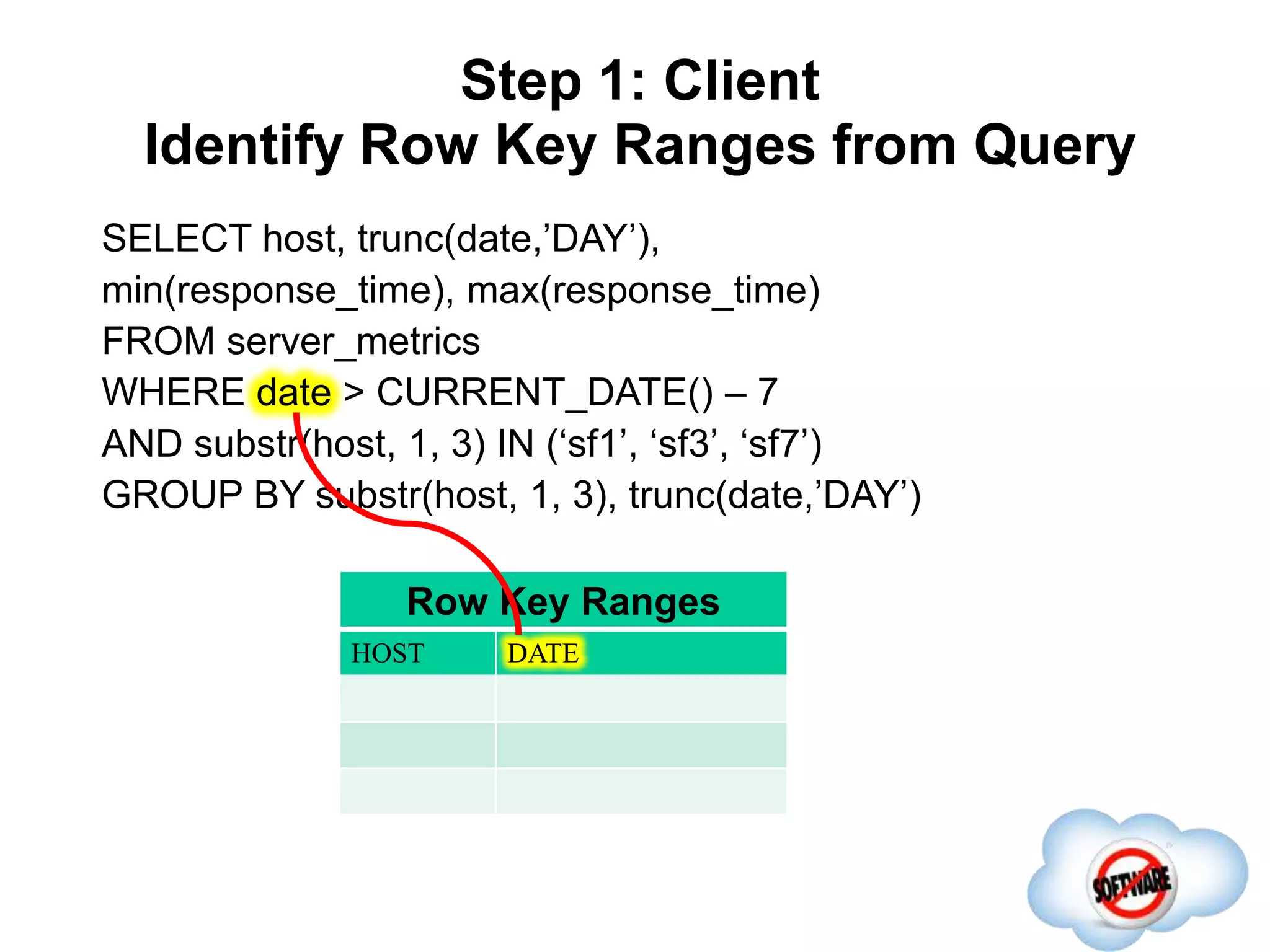
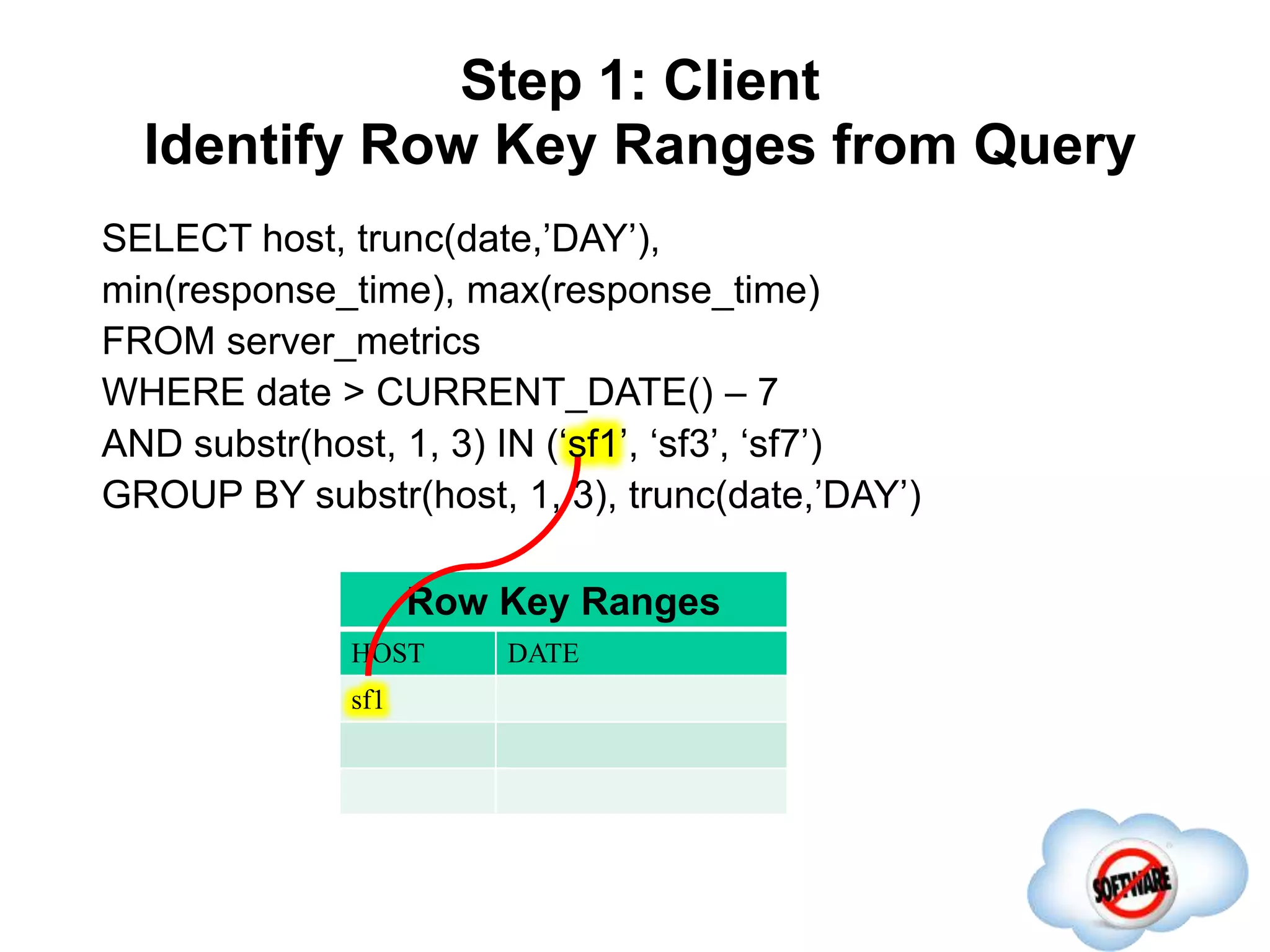
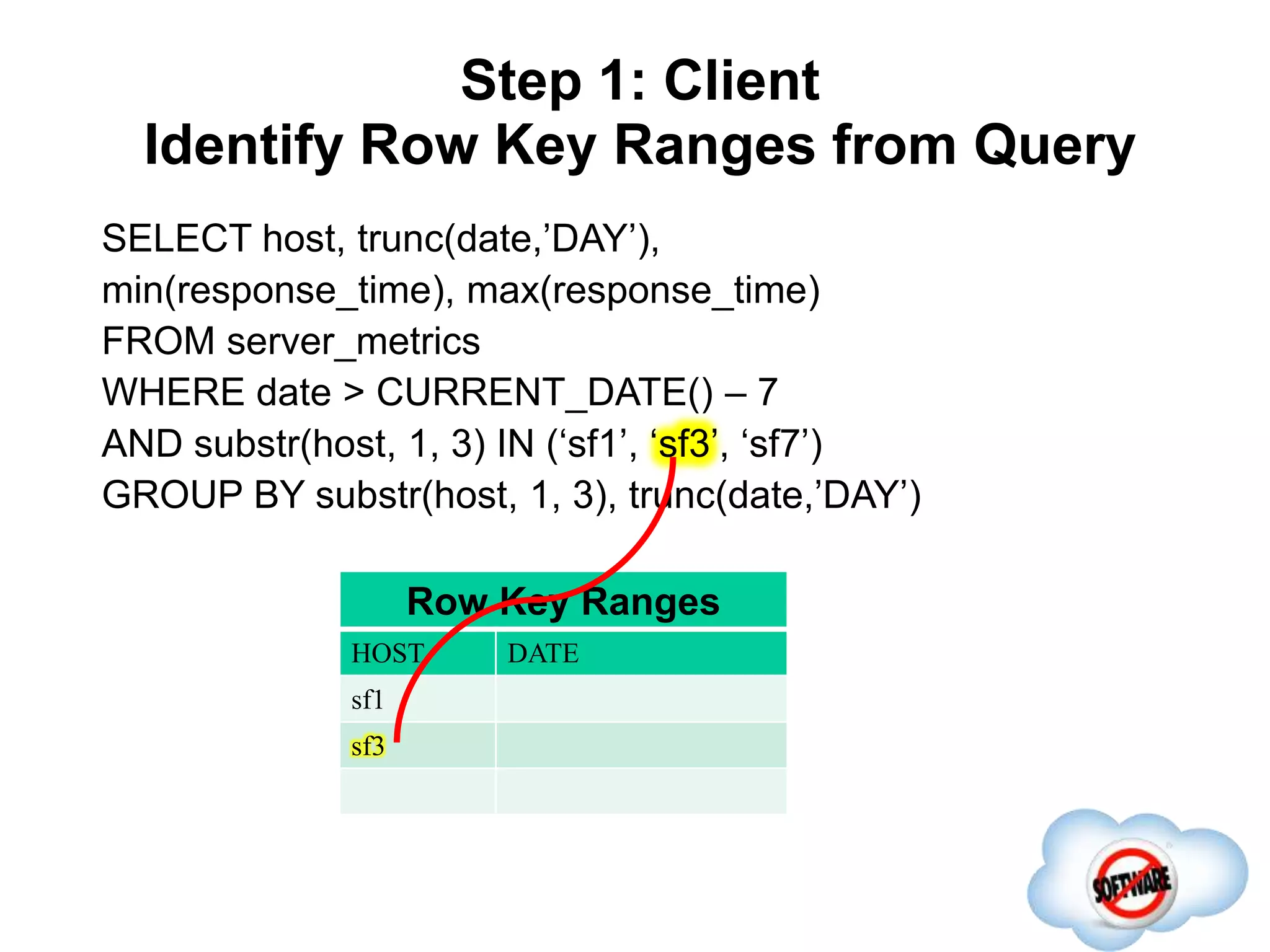

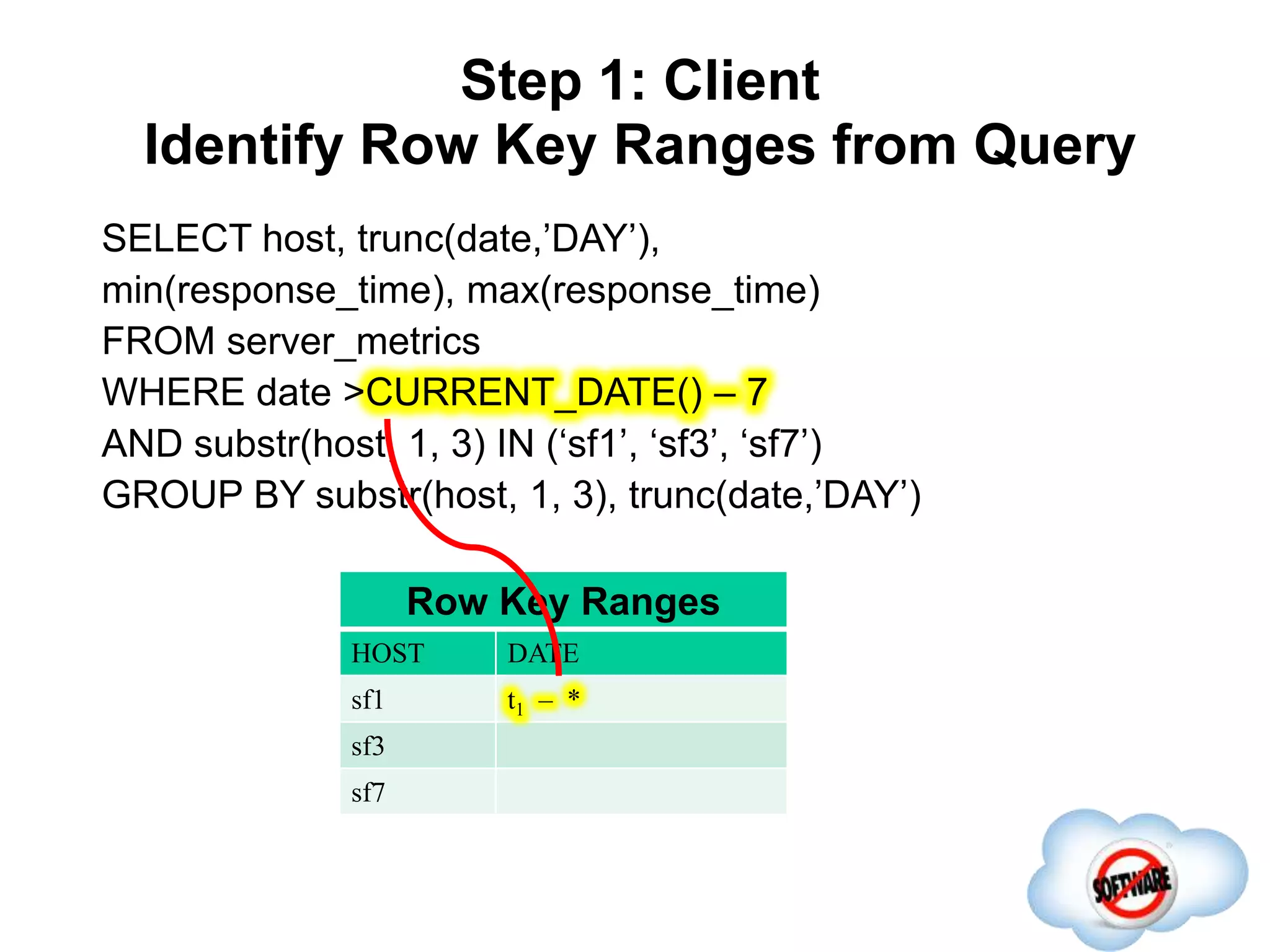
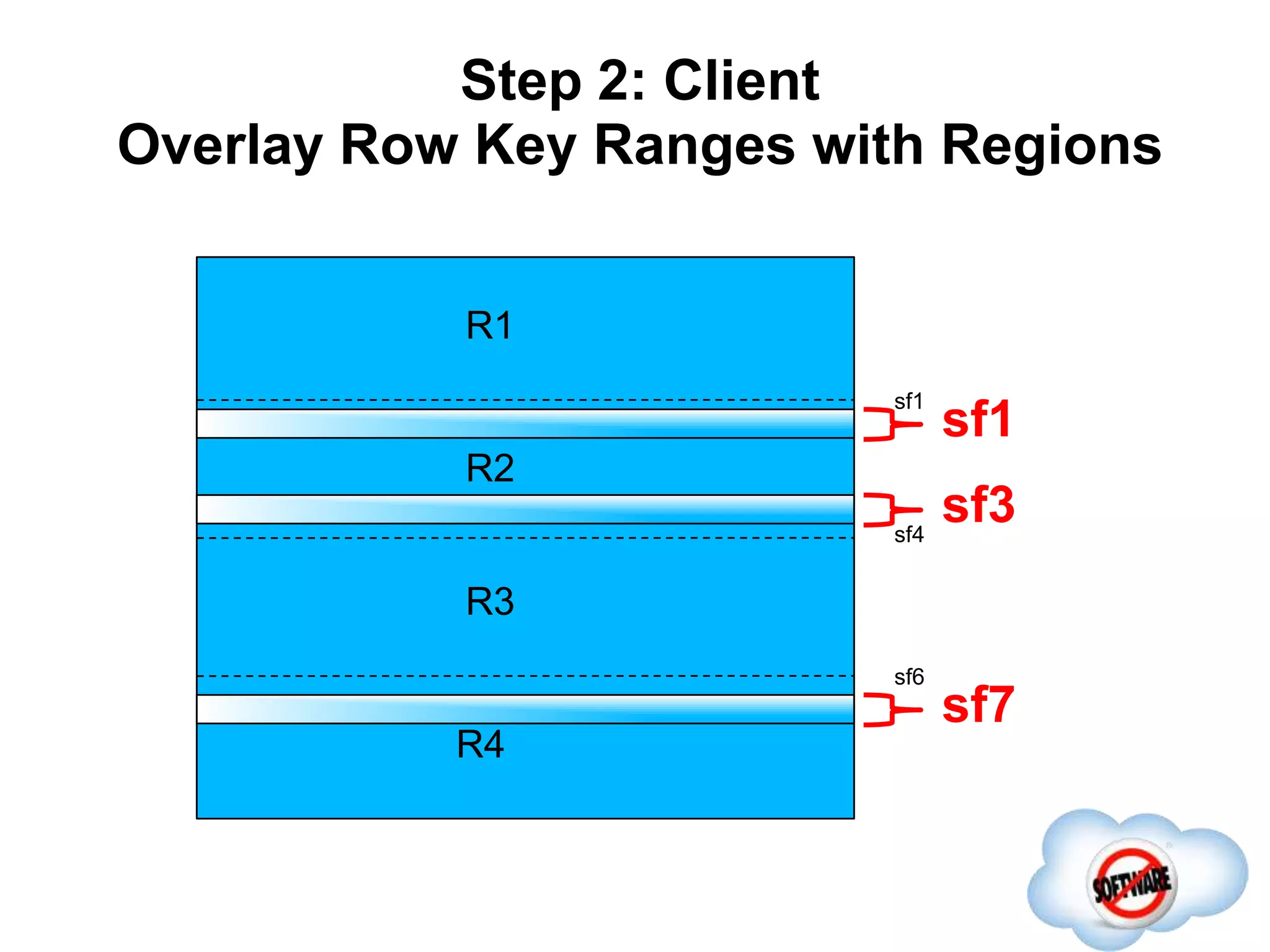
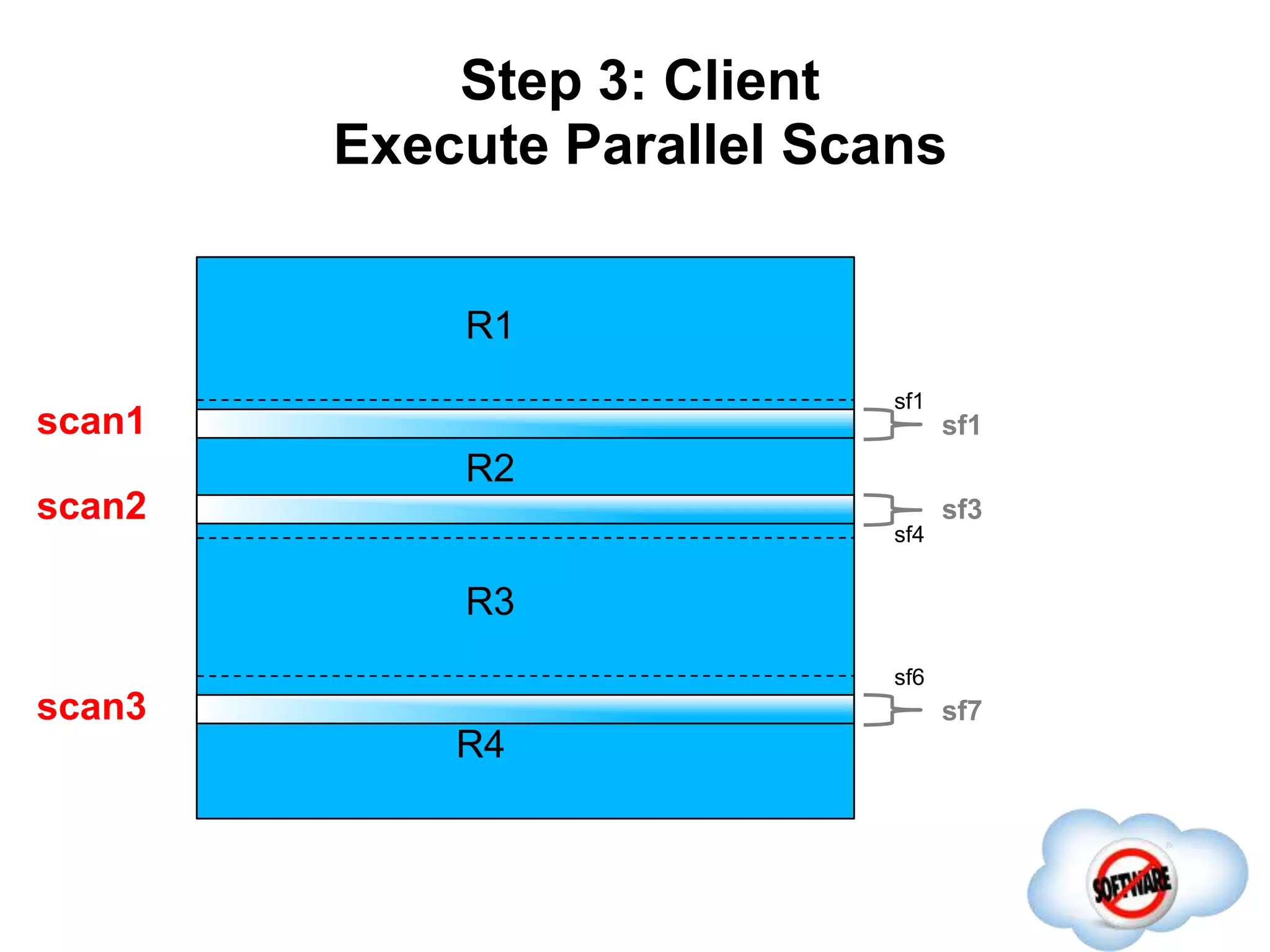
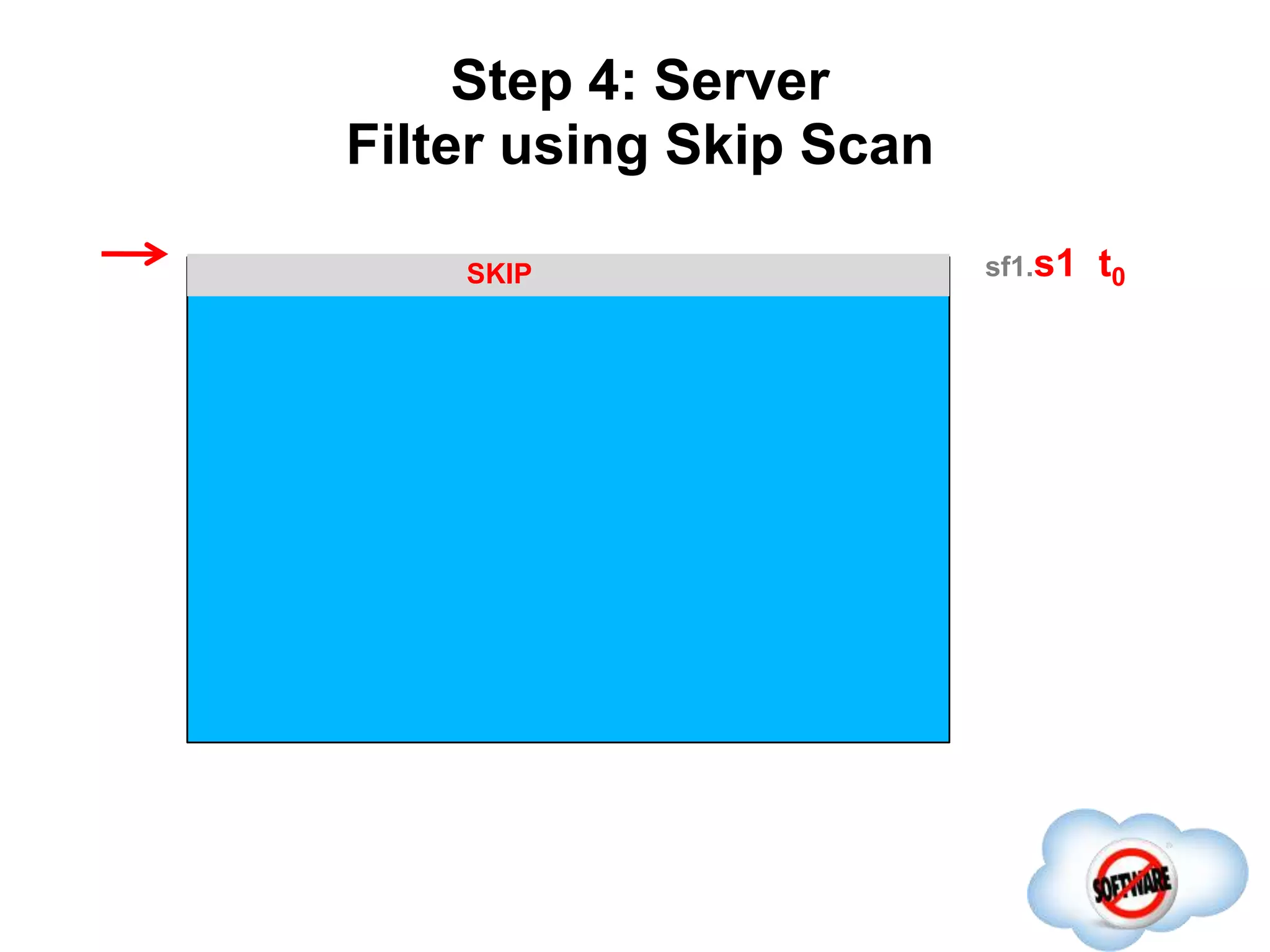
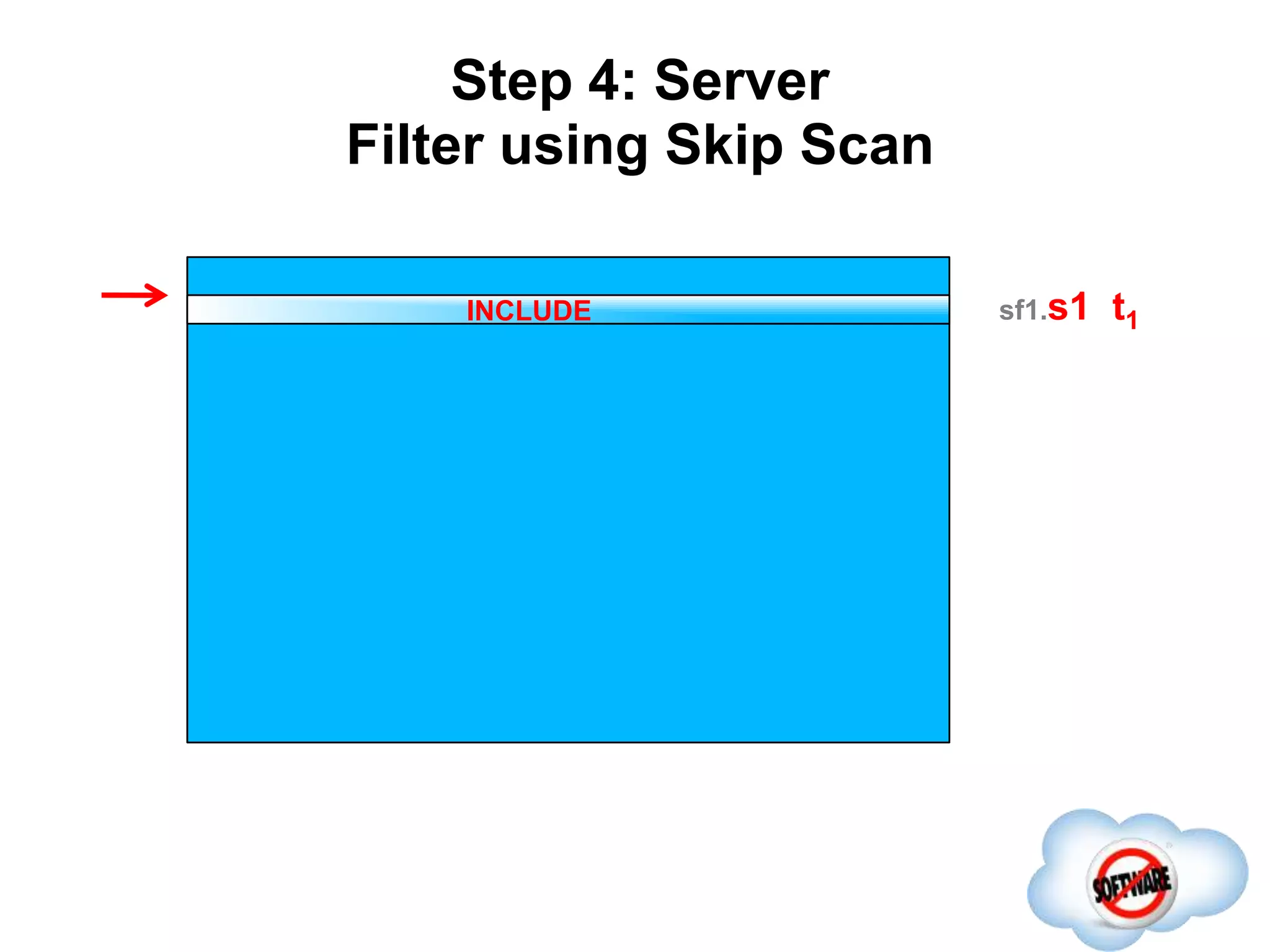
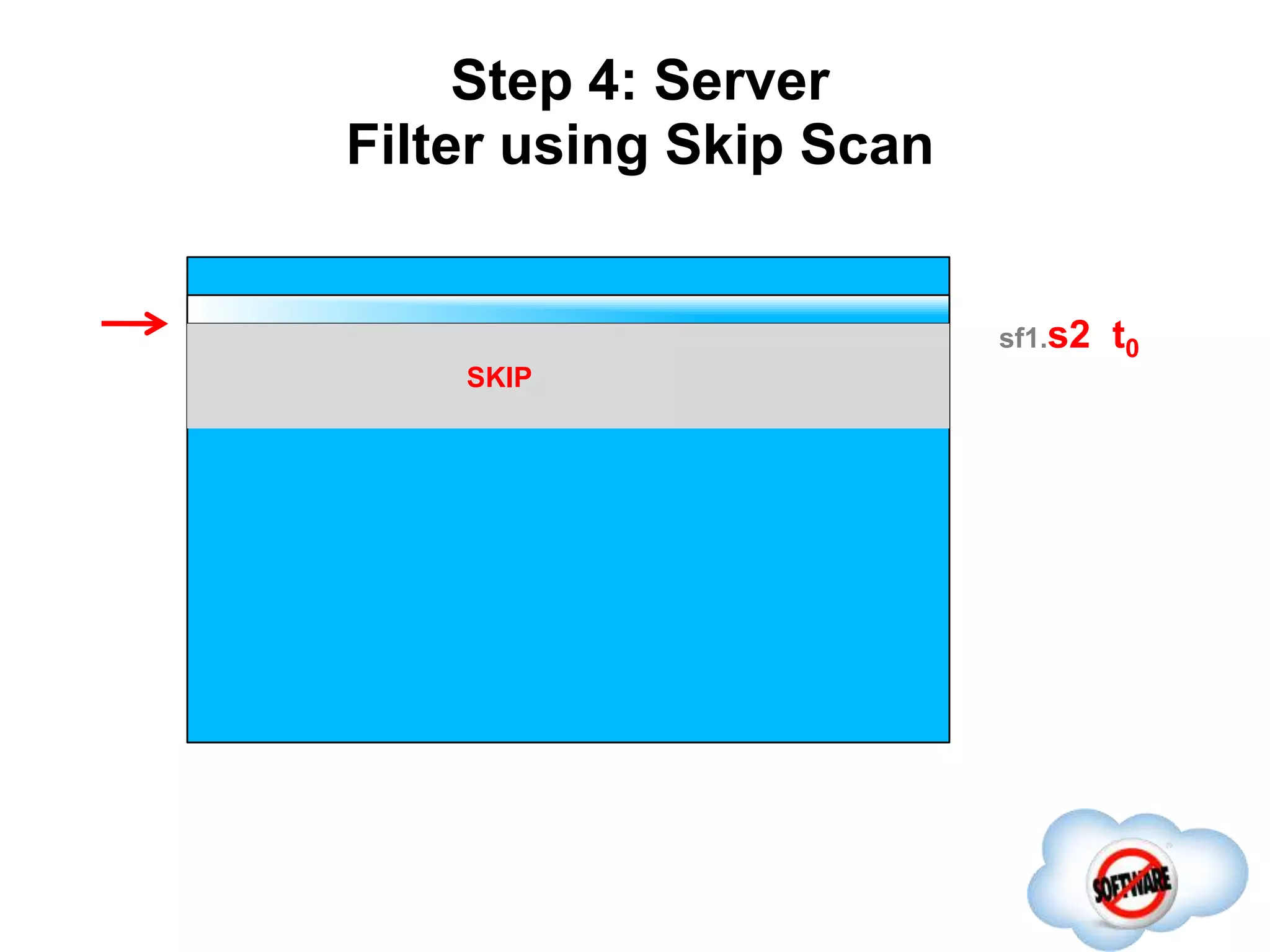
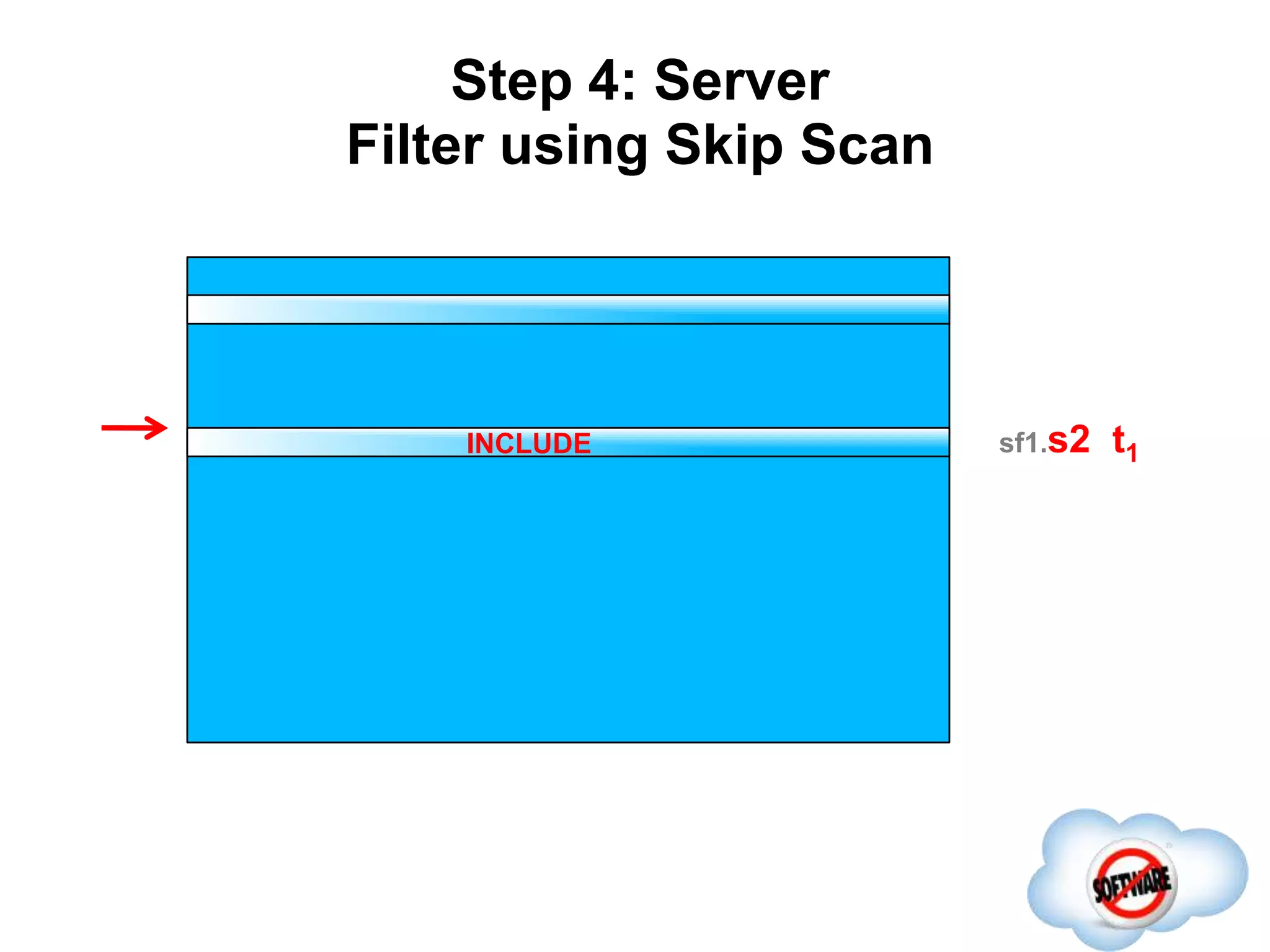
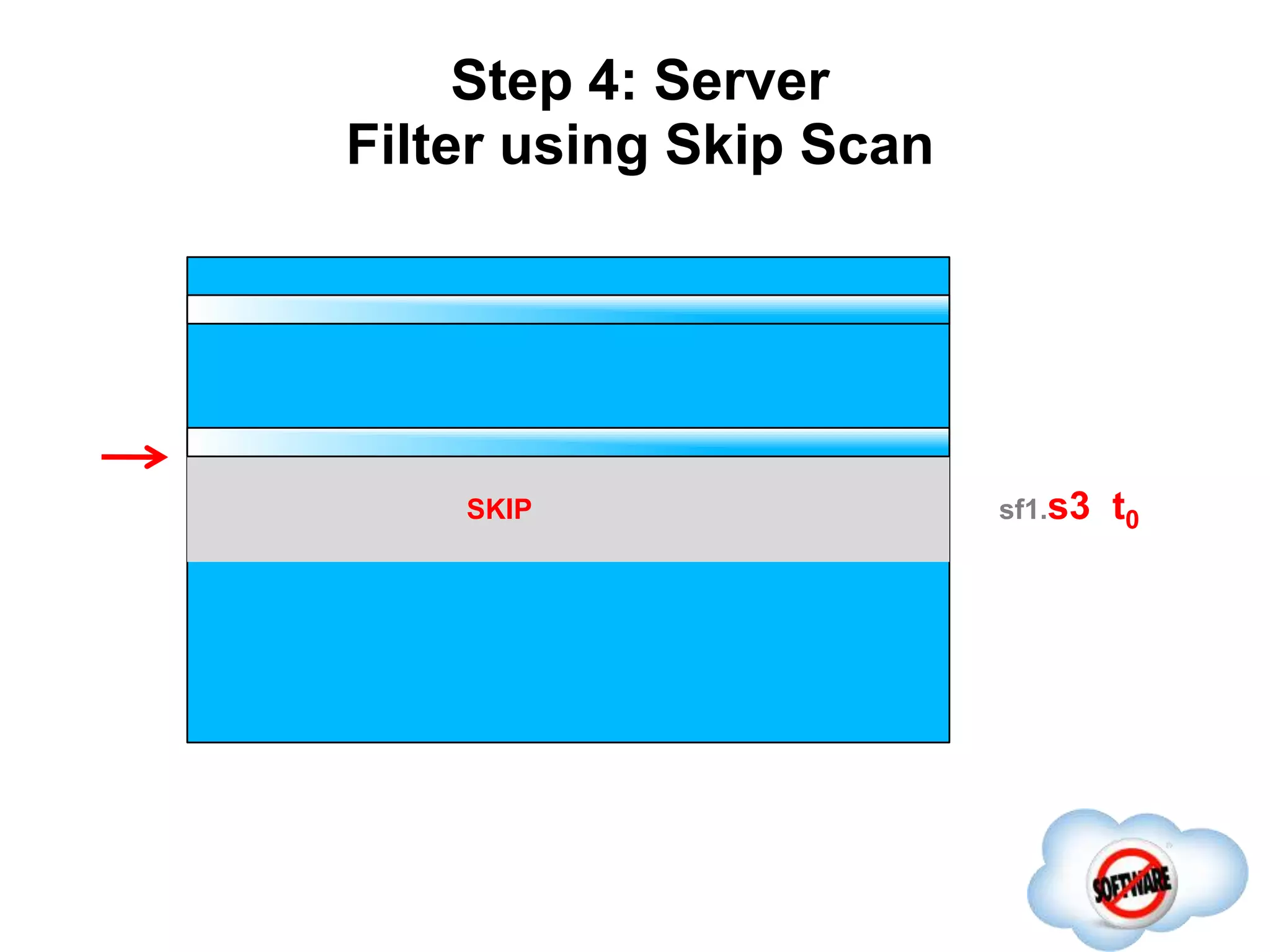
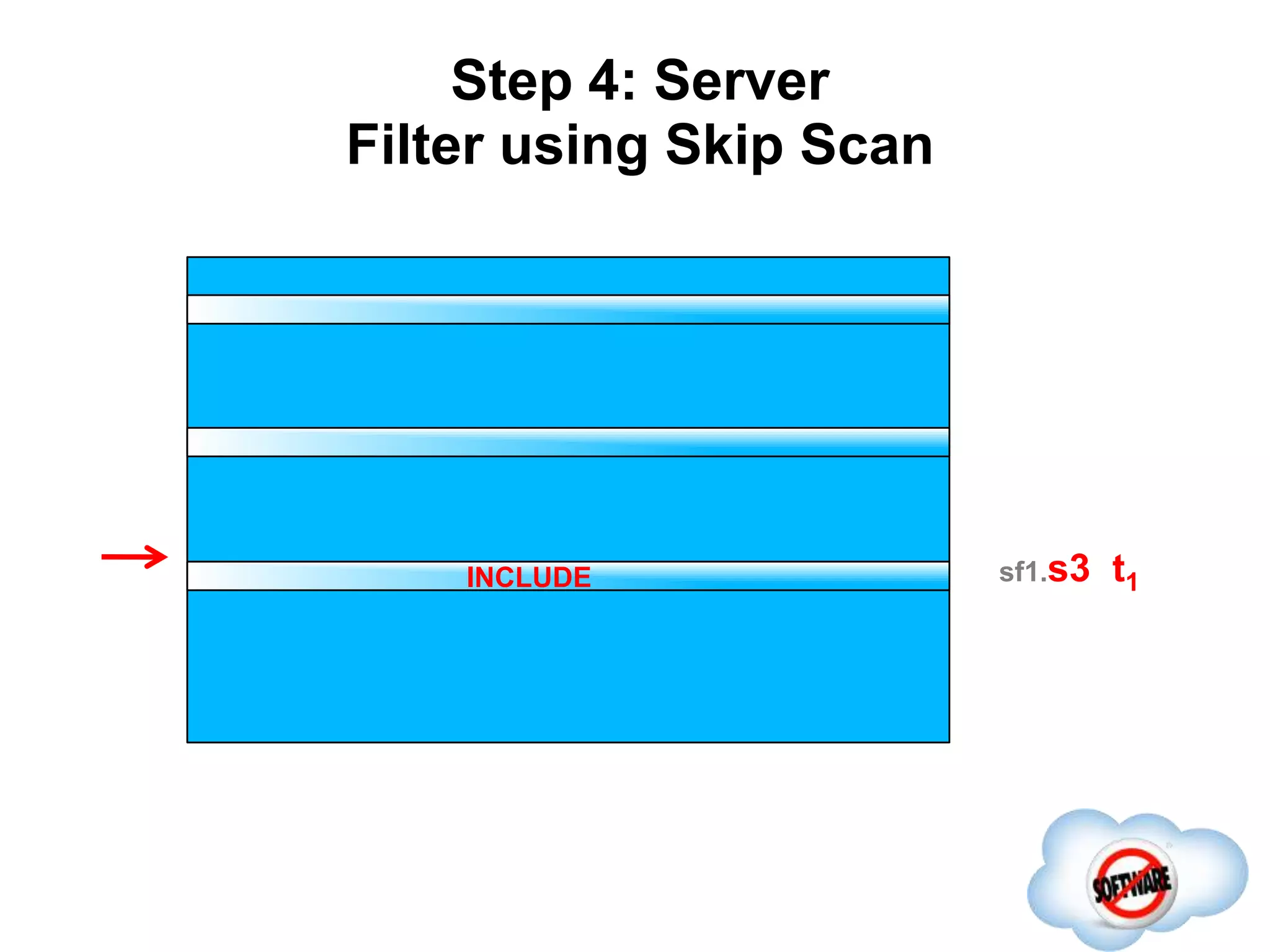

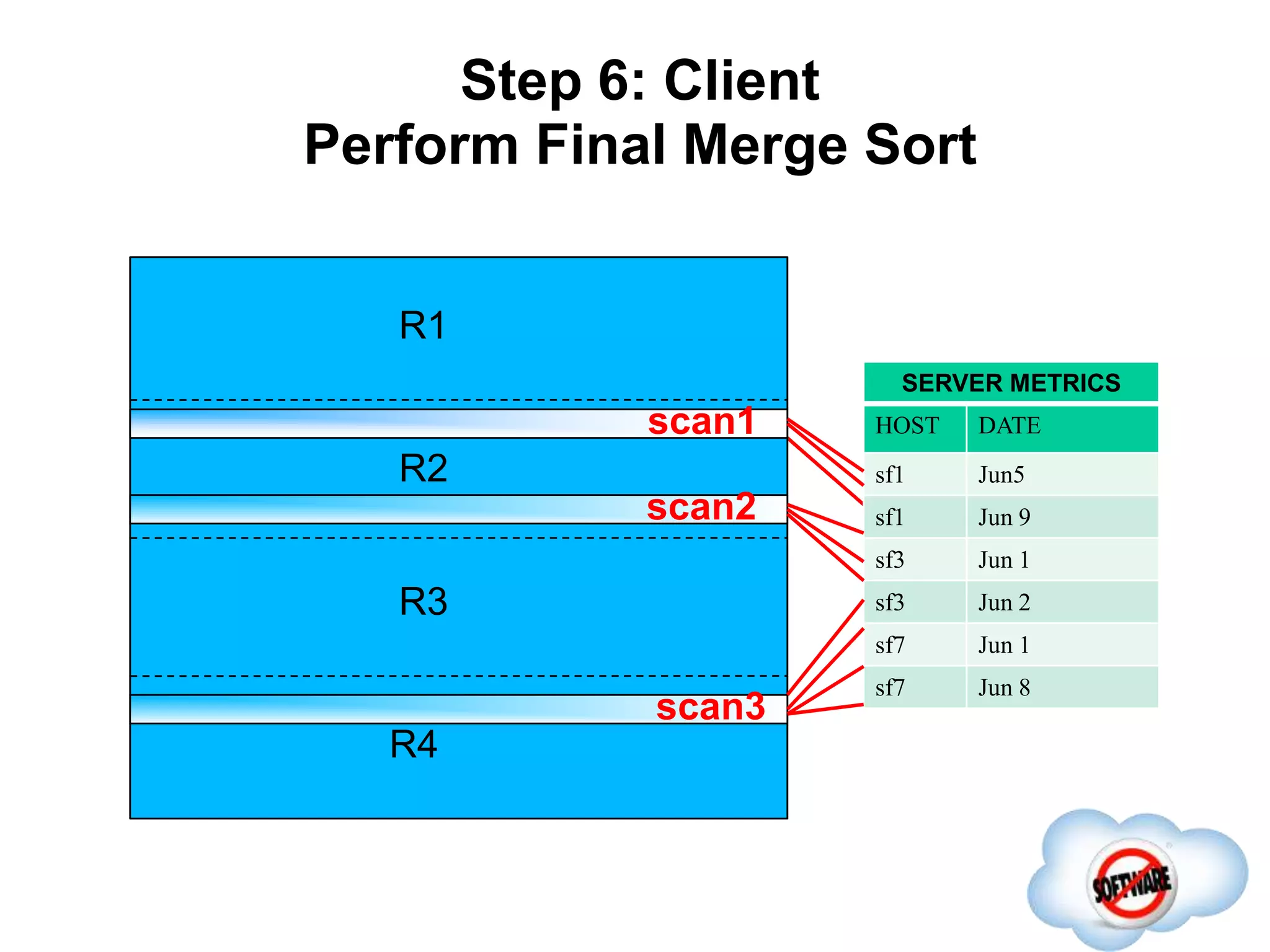


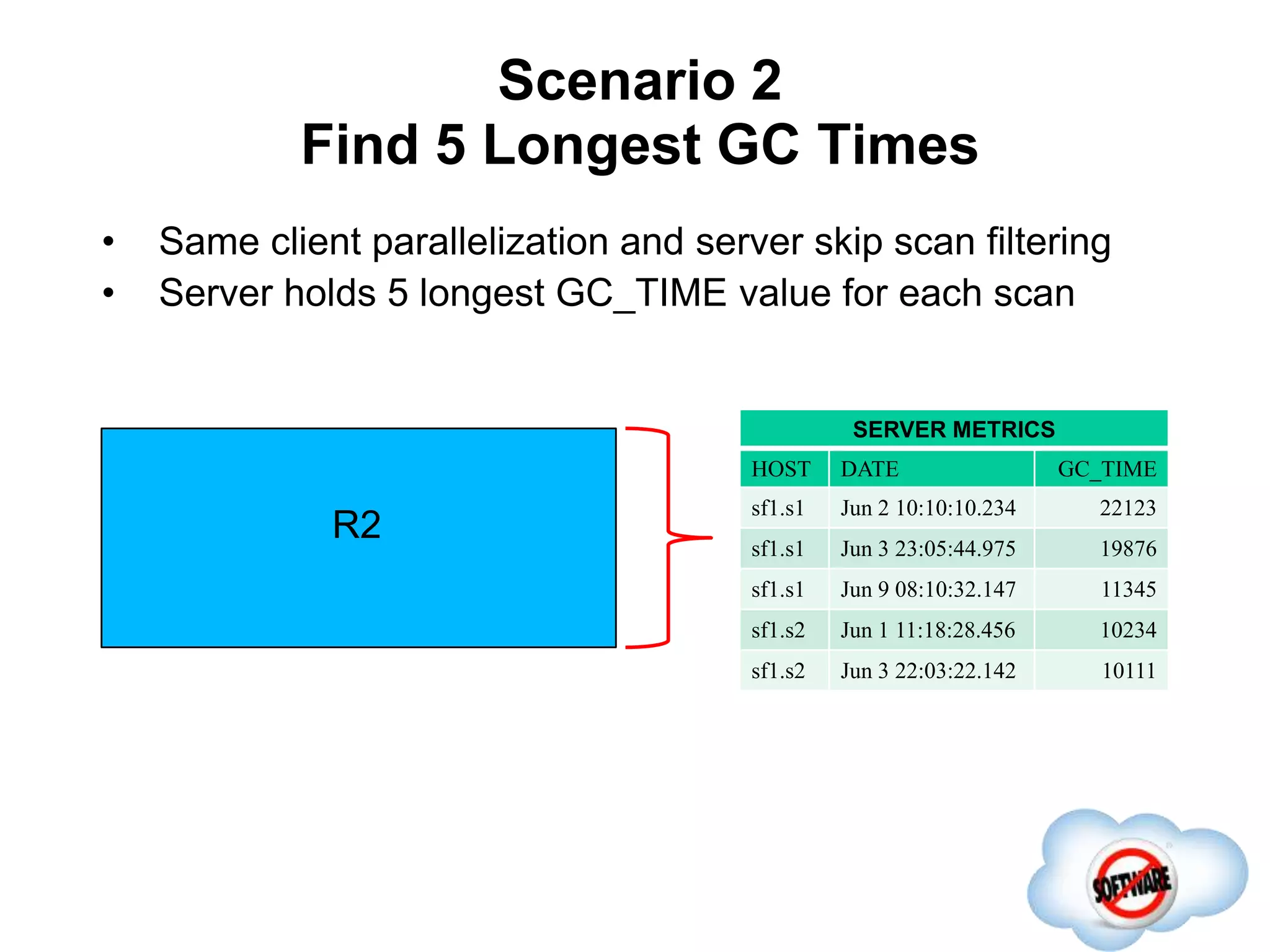




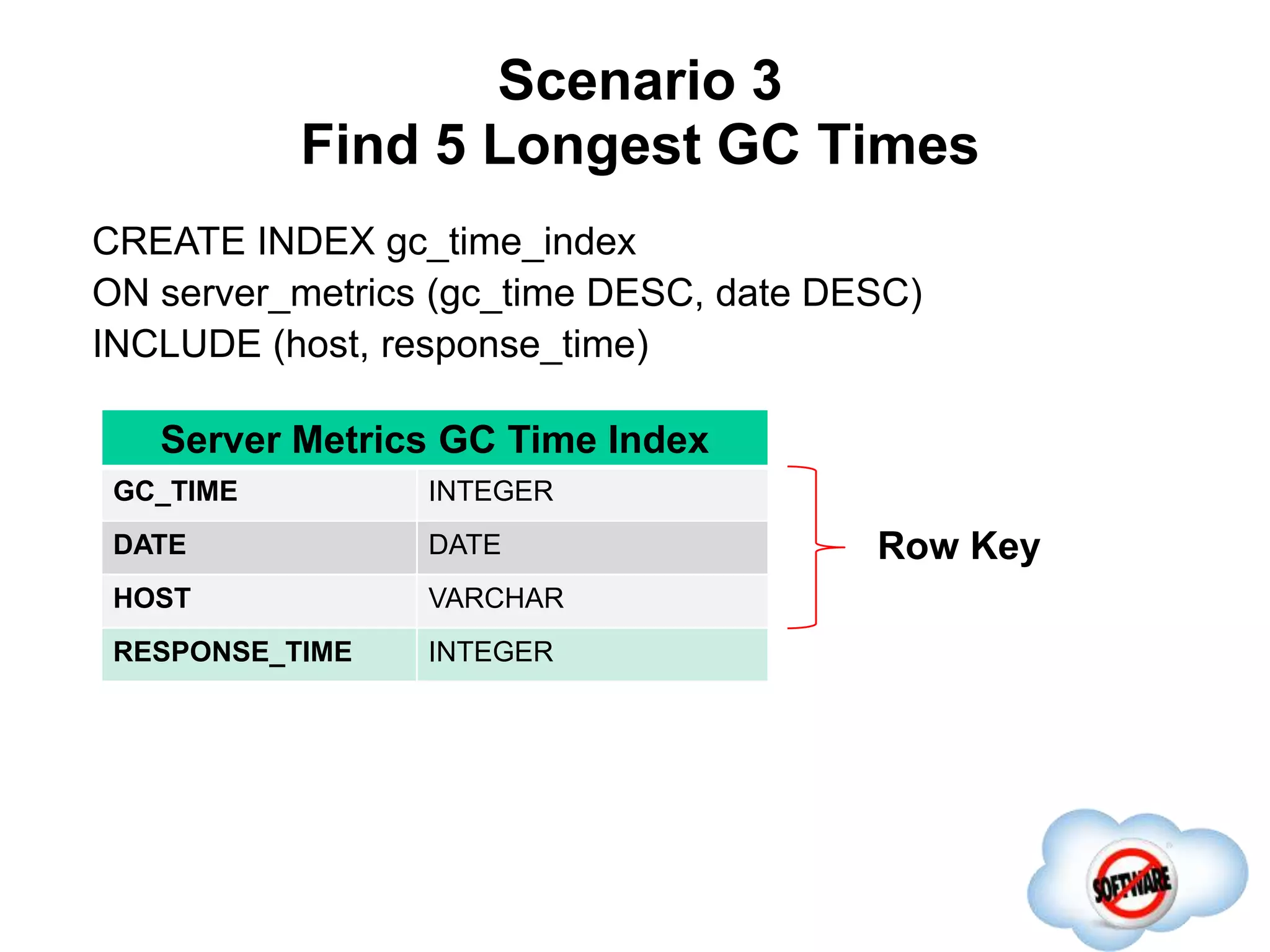




This document discusses Phoenix, an open source SQL skin for HBase. Phoenix provides a SQL interface and JDBC driver for HBase, allowing users to query HBase data using SQL and leveraging existing SQL tools and frameworks. It compiles SQL queries into efficient native HBase operations, improving performance. Examples demonstrate how Phoenix handles different types of queries, such as aggregating metrics data and finding the longest GC times, through optimizations like skip scans and server-side processing.










































































































