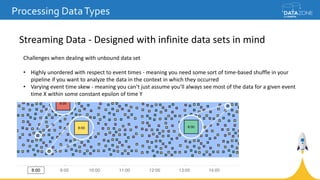
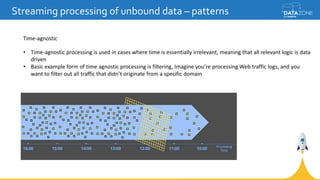
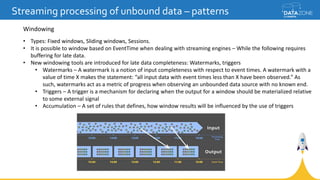
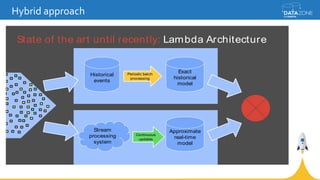
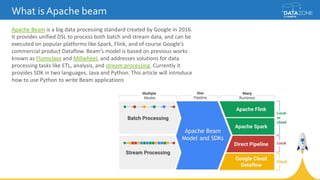
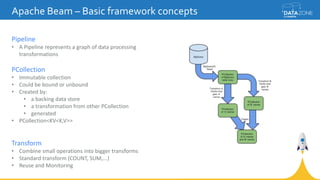
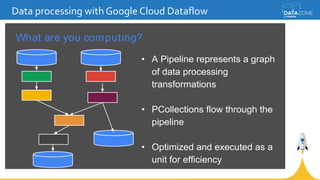
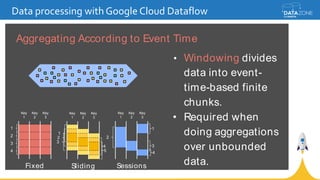
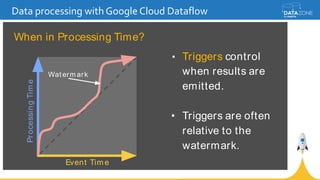
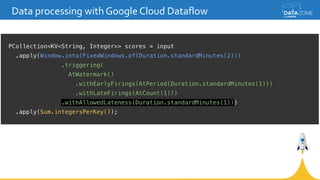
Google Cloud Dataflow is a fully managed cloud service for batch and streaming data processing. It provides a unified programming model and DSL that can process both batch and streaming data on platforms like Spark, Flink, and Google's managed Dataflow service. Dataflow uses concepts like pipelines, PCollections, transforms, and windowing to process data according to event time while controlling latency through triggers. The Dataflow service on Google Cloud provides integration with Google Cloud services and monitoring at a cost based on the number and type of workers used.













































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






