Downloaded 38 times



![Phoenix SQL Support
SELECT <expression>…
FROM <table>
WHERE <expression>
GROUP BY <expression>…
HAVING <aggregate expression>
ORDER BY <aggregate expression>…
LIMIT <value>
Aggregation Functions
MIN, MAX, AVG, SUM, COUNT
Built-in Functions
SUBSTR, ROUND, TRUNC, TO_CHAR, TO_DATE
Operators
=,!=,<>,<,<=,>,>=, LIKE
AND, OR, NOT
Bind Parameters
?, :#
CASE WHEN
IN (<value>…)
DDL/DML (in progress)
CREATE/DROP <table>
DELETE FROM <table> WHERE <expression>
UPSERT INTO <table> [(<column>…)]
VALUES (<value>…)](https://image.slidesharecdn.com/phoenixhbasemeetup-121107113031-phpapp02/75/Phoenix-h-basemeetup-4-2048.jpg)

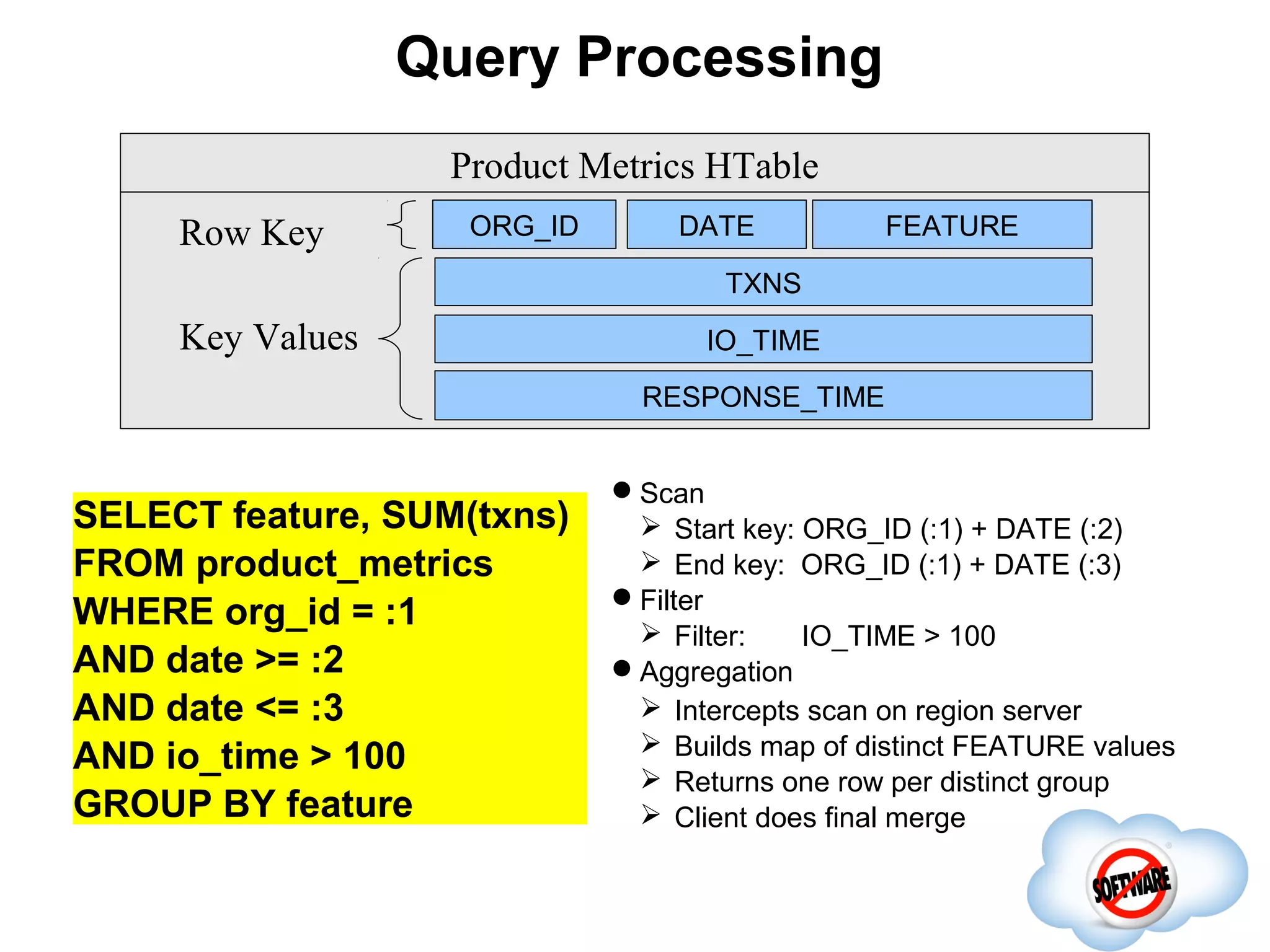

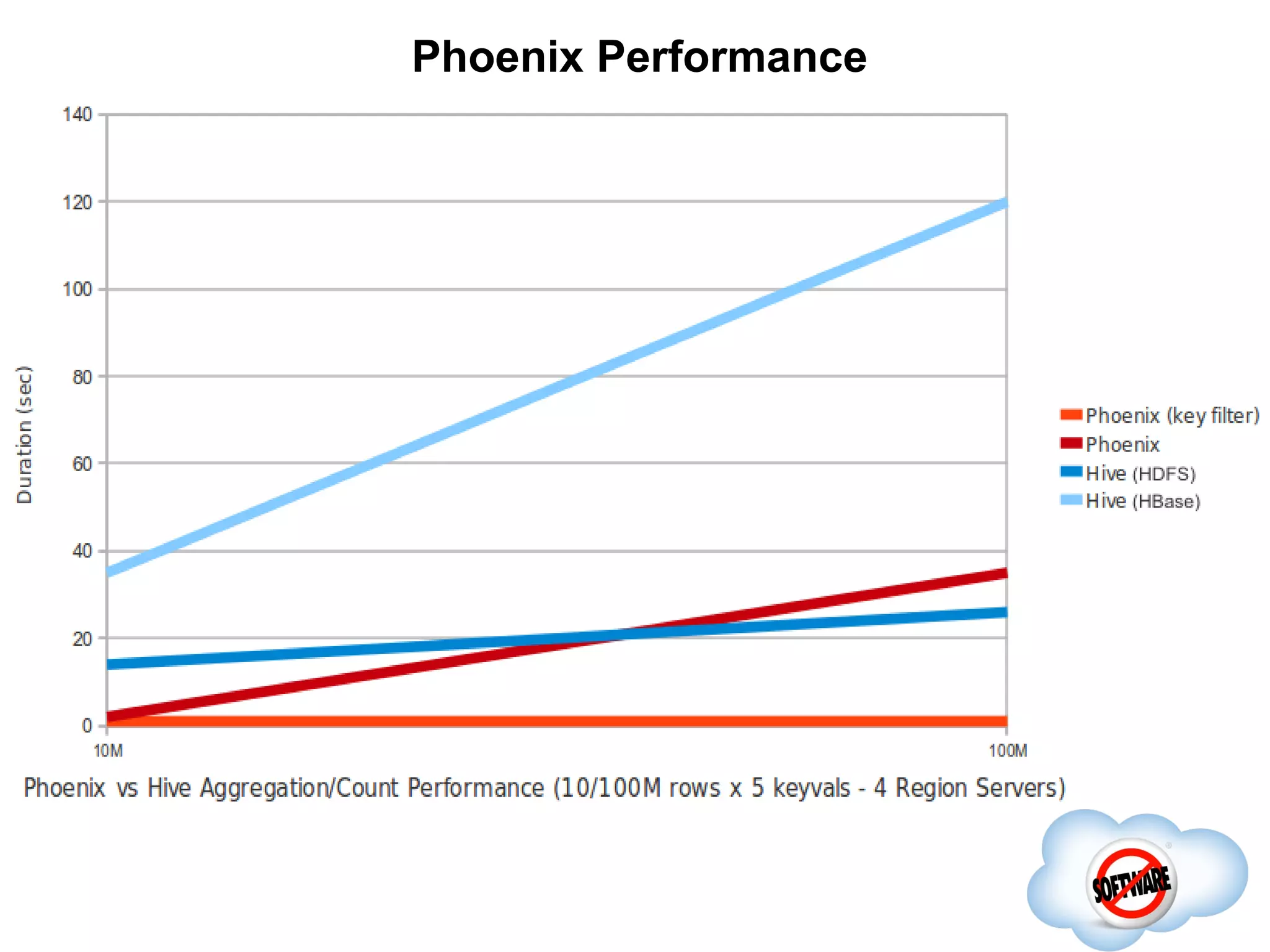
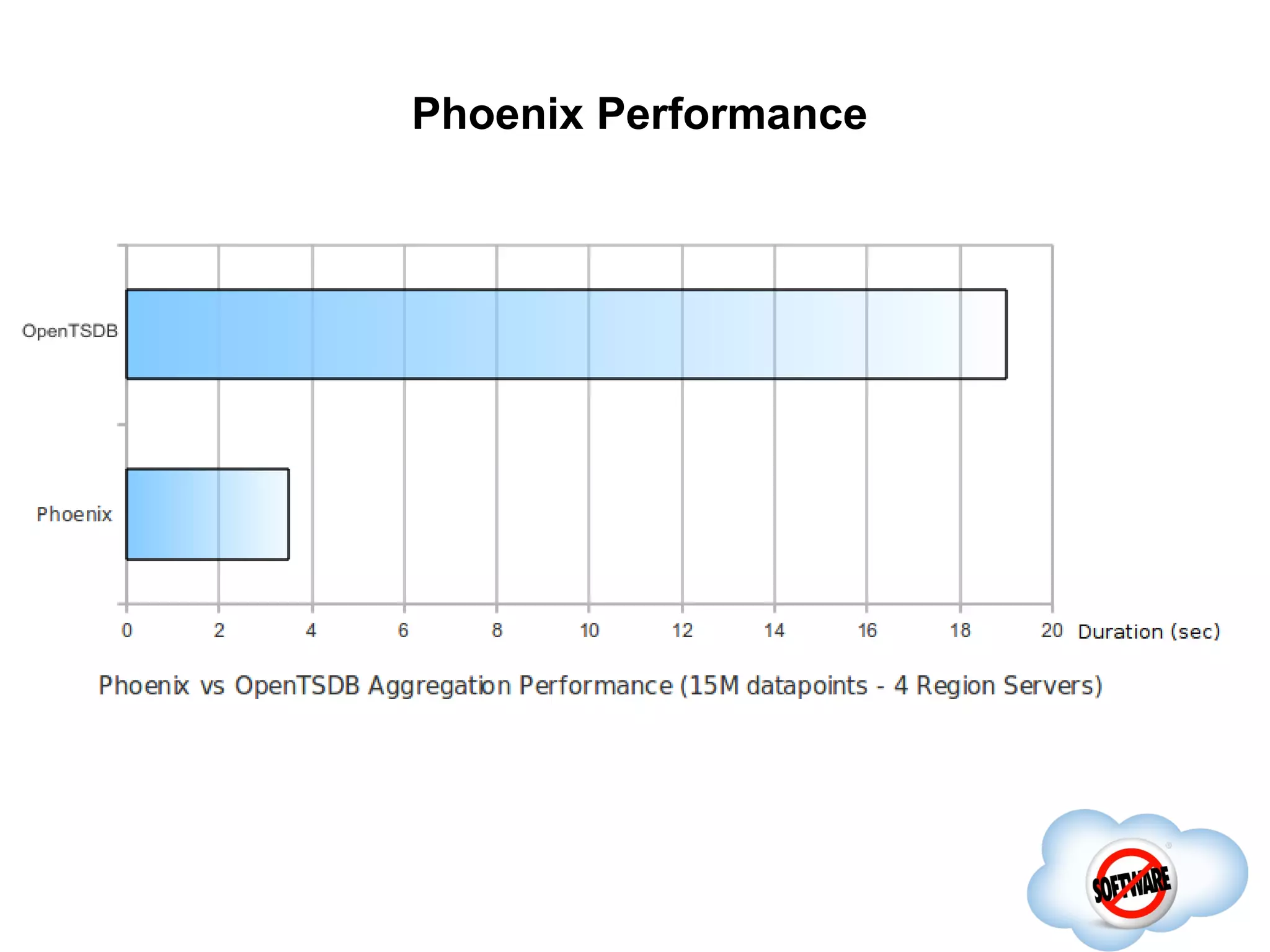



Phoenix is an open source SQL layer for HBase that provides low latency queries over HBase data. It transforms SQL queries into a series of HBase scans and uses HBase APIs and coprocessors for aggregation and filtering. Phoenix supports common SQL constructs like SELECT, WHERE, GROUP BY, and JOINs. It optimizes queries by leveraging features like start/stop keys, parallelization, and aggregation on region servers. Upcoming features include secondary indexes, sampling, and improved SQL support.







![[Altibase] 9 replication part2 (methods and controls)](https://cdn.slidesharecdn.com/ss_thumbnails/altibase9replicationpart2methodsandcontrols-160126071813-thumbnail.jpg?width=640&height=640&fit=bounds)


















































