Downloaded 27 times


































![openCV.py – Generate HOG Descriptor
import cv2
#Calculate Hog Descriptor
hog = cv2.HOGDescriptor()
im = cv2.imread('gary.jpg')
h = hog.compute(im)
#turn list of lists into a single vector
finalList = list()
for i in h:
finalList.append(i[0])
print finalList
gary.jpg
42](https://image.slidesharecdn.com/sparksummtdublin2017-memsql-real-timeimagerecognition-171027074702/85/Spark-Summit-Dublin-2017-MemSQL-Real-Time-Image-Recognition-42-320.jpg)


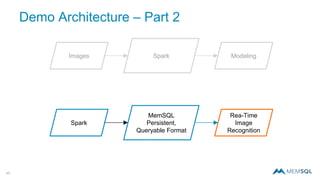

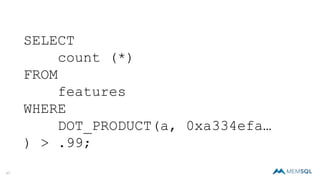


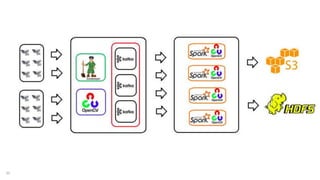











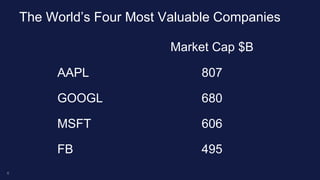
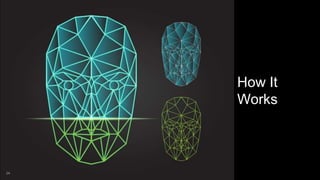
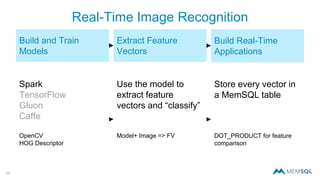
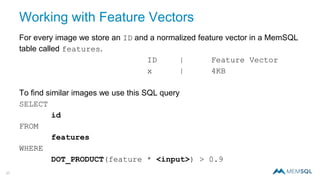
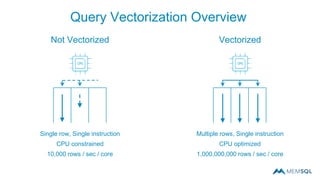
The document discusses real-time image recognition using Apache Spark. It describes how images are analyzed to extract histogram of oriented gradients (HOG) descriptors, which are stored as feature vectors in a MemSQL table. Similar images can then be identified by comparing feature vectors using dot products, enabling searches of millions of images per second. A demo is shown generating HOG descriptors from an image and storing them as a vector for fast similarity matching.






















































































