Downloaded 76 times



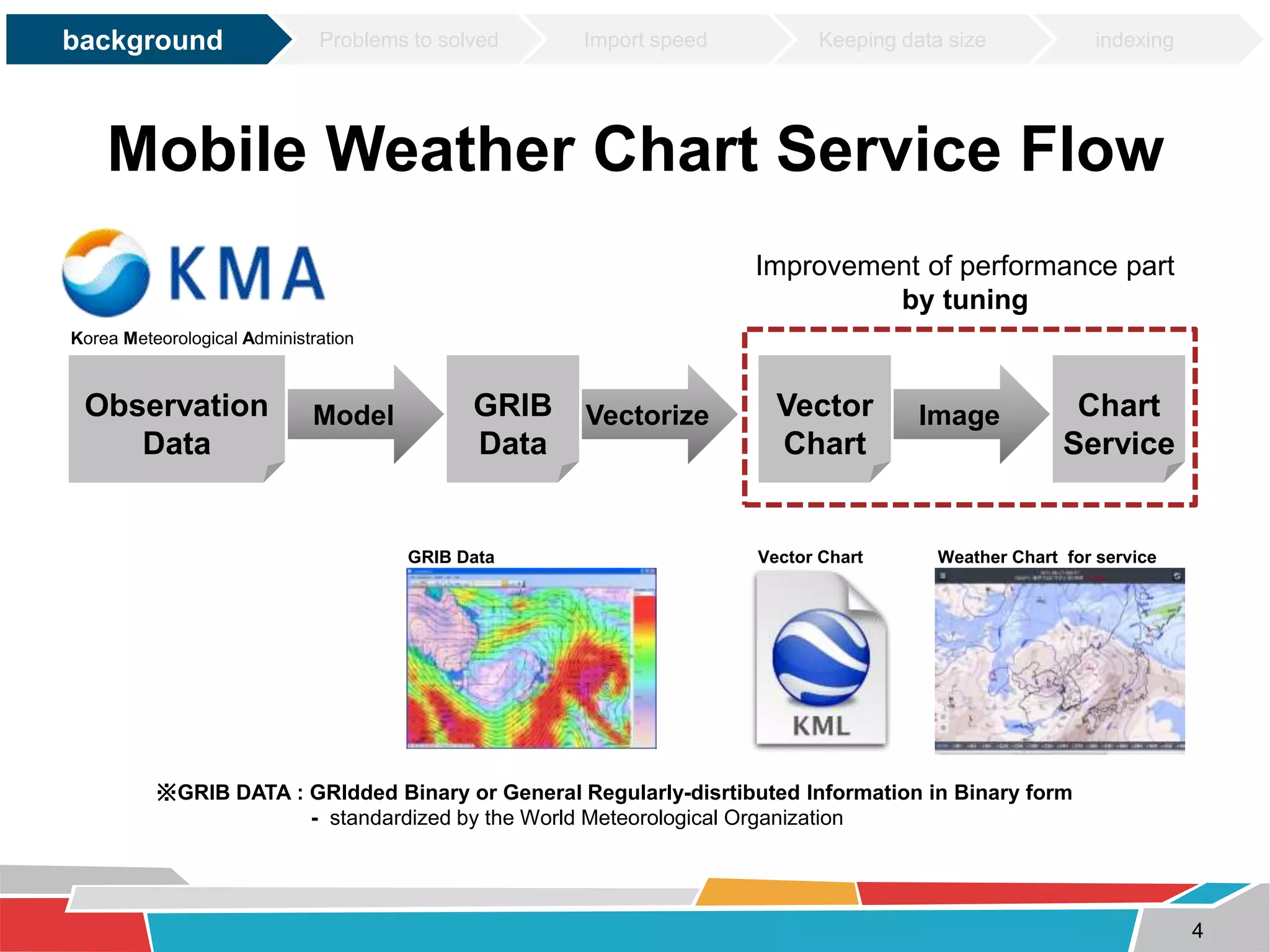
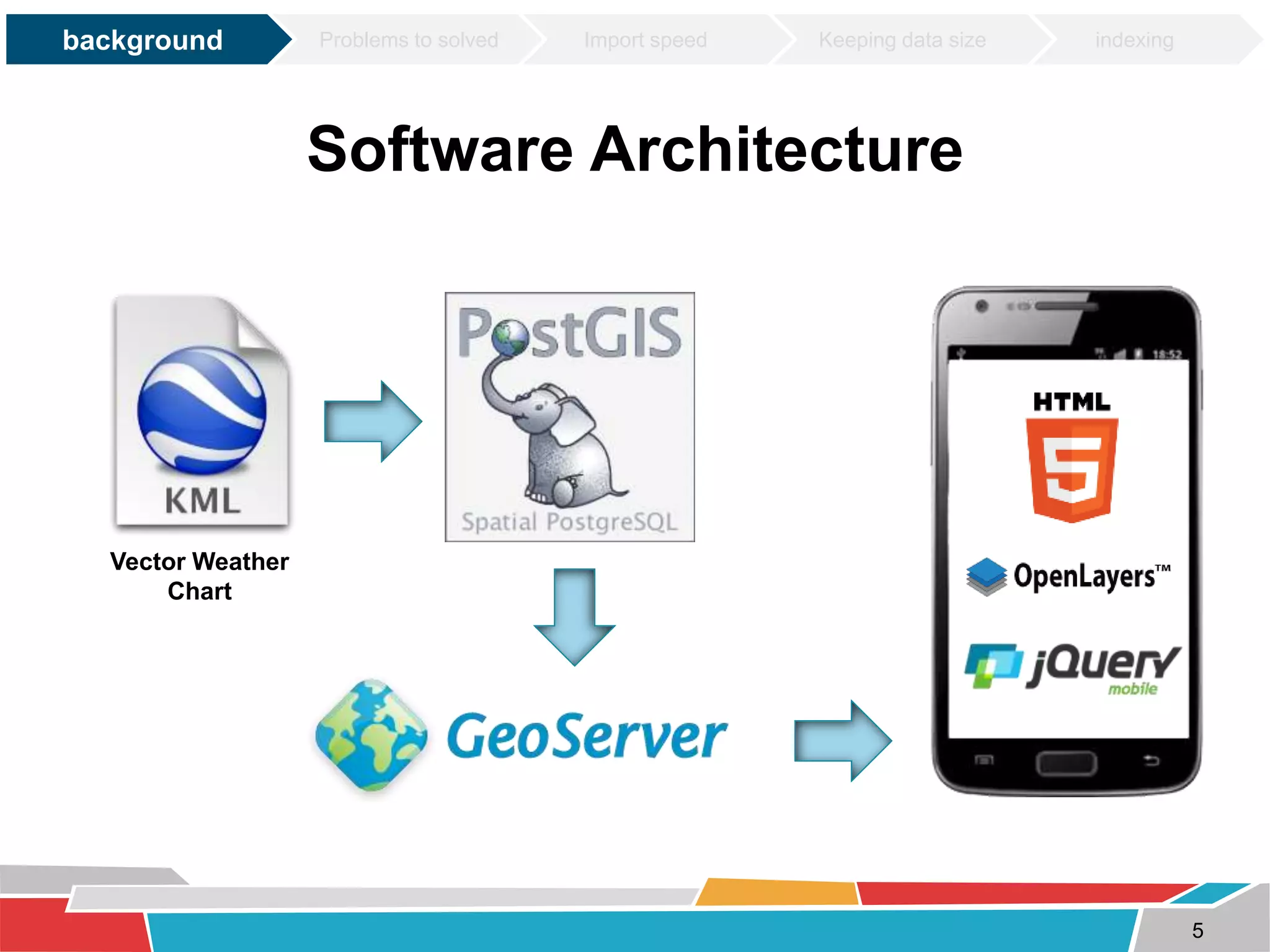

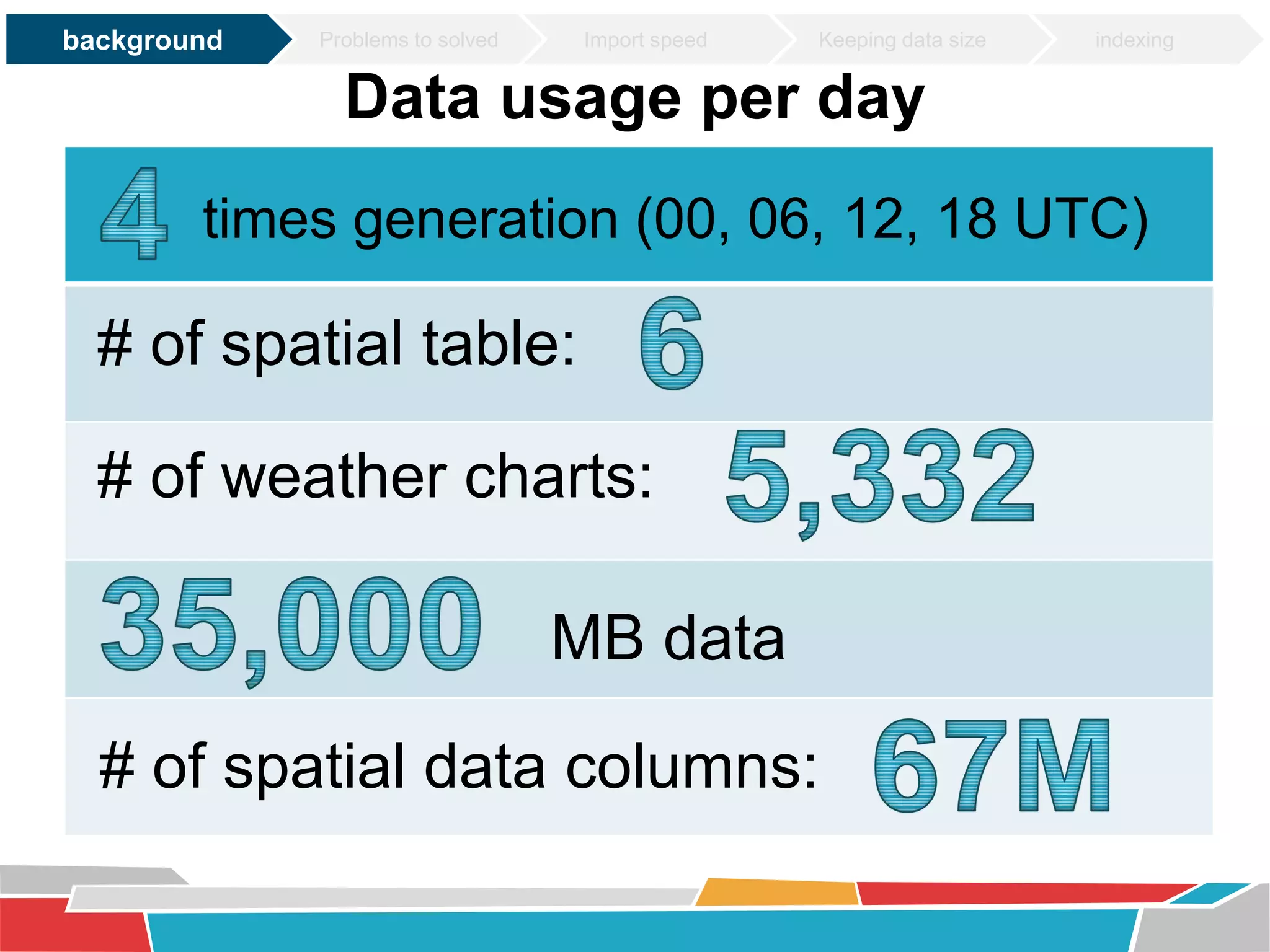

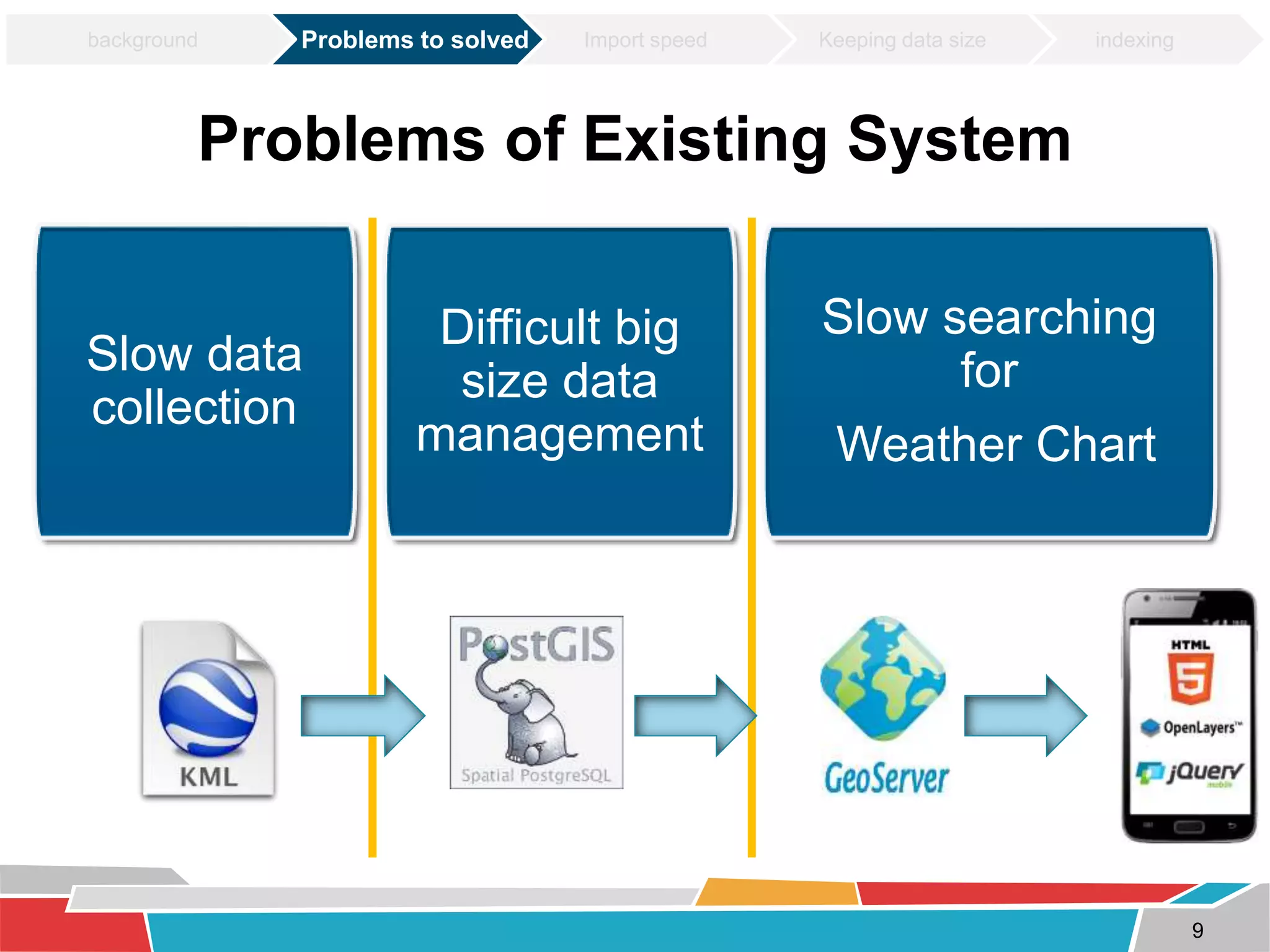

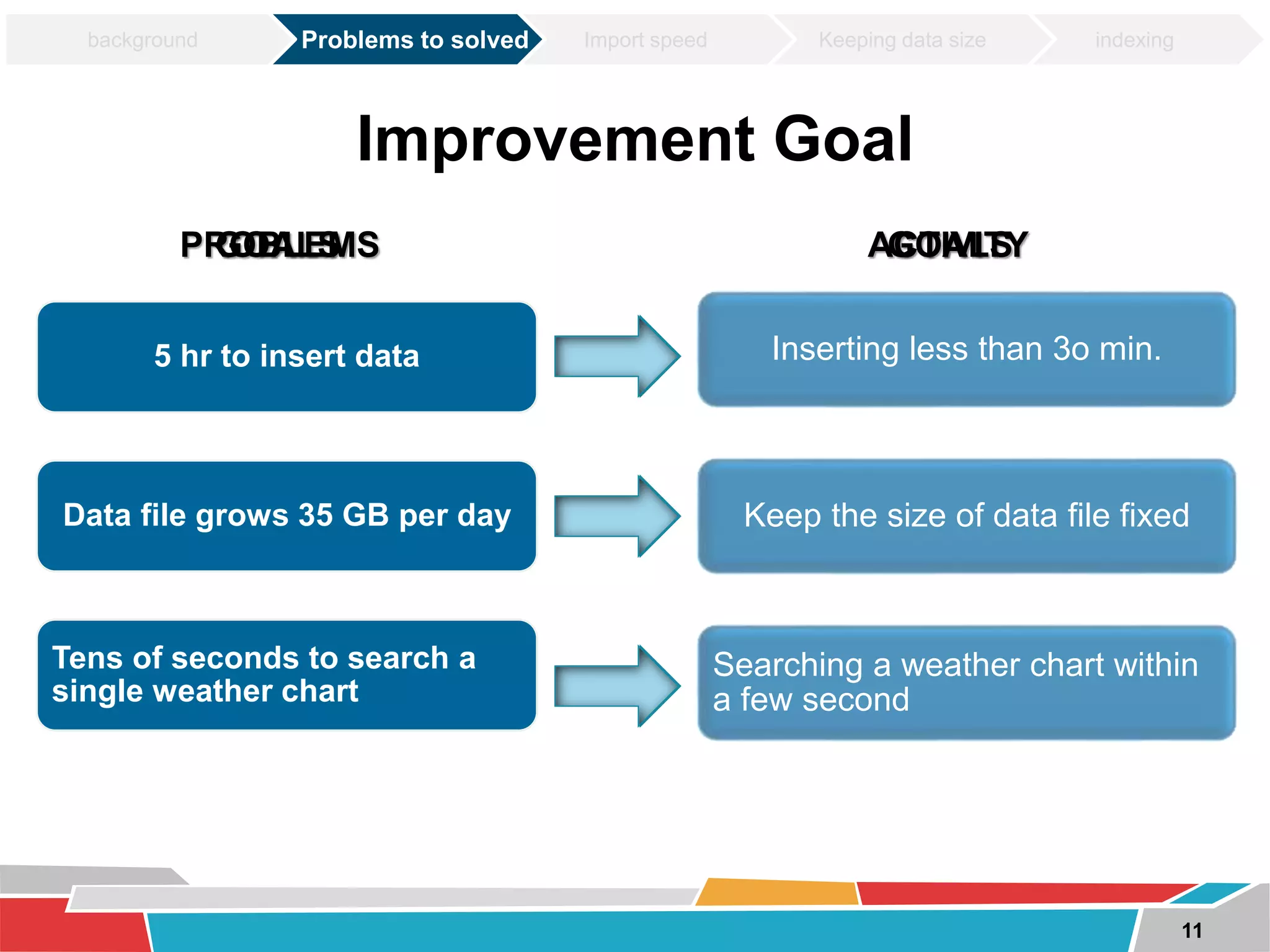

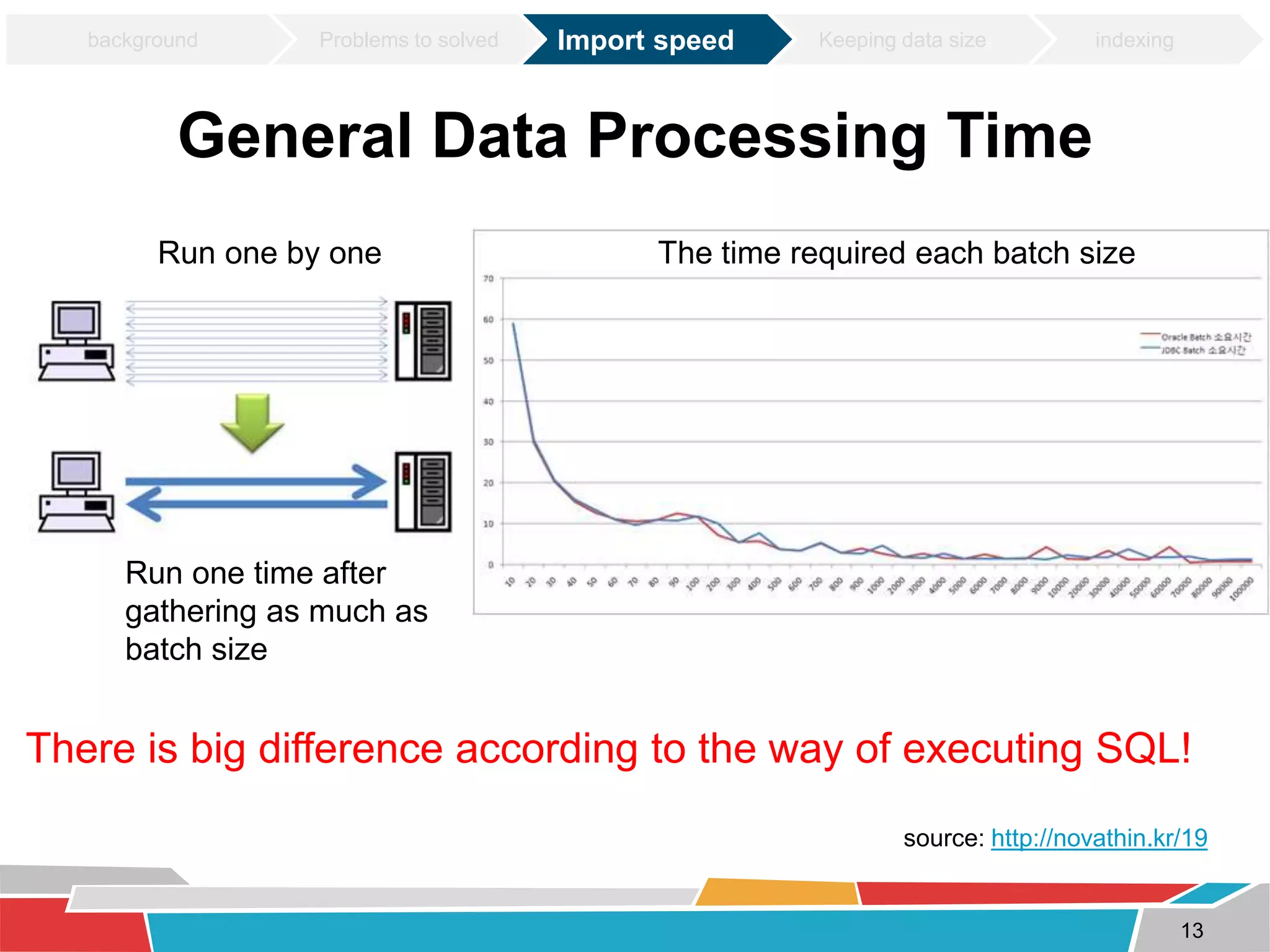
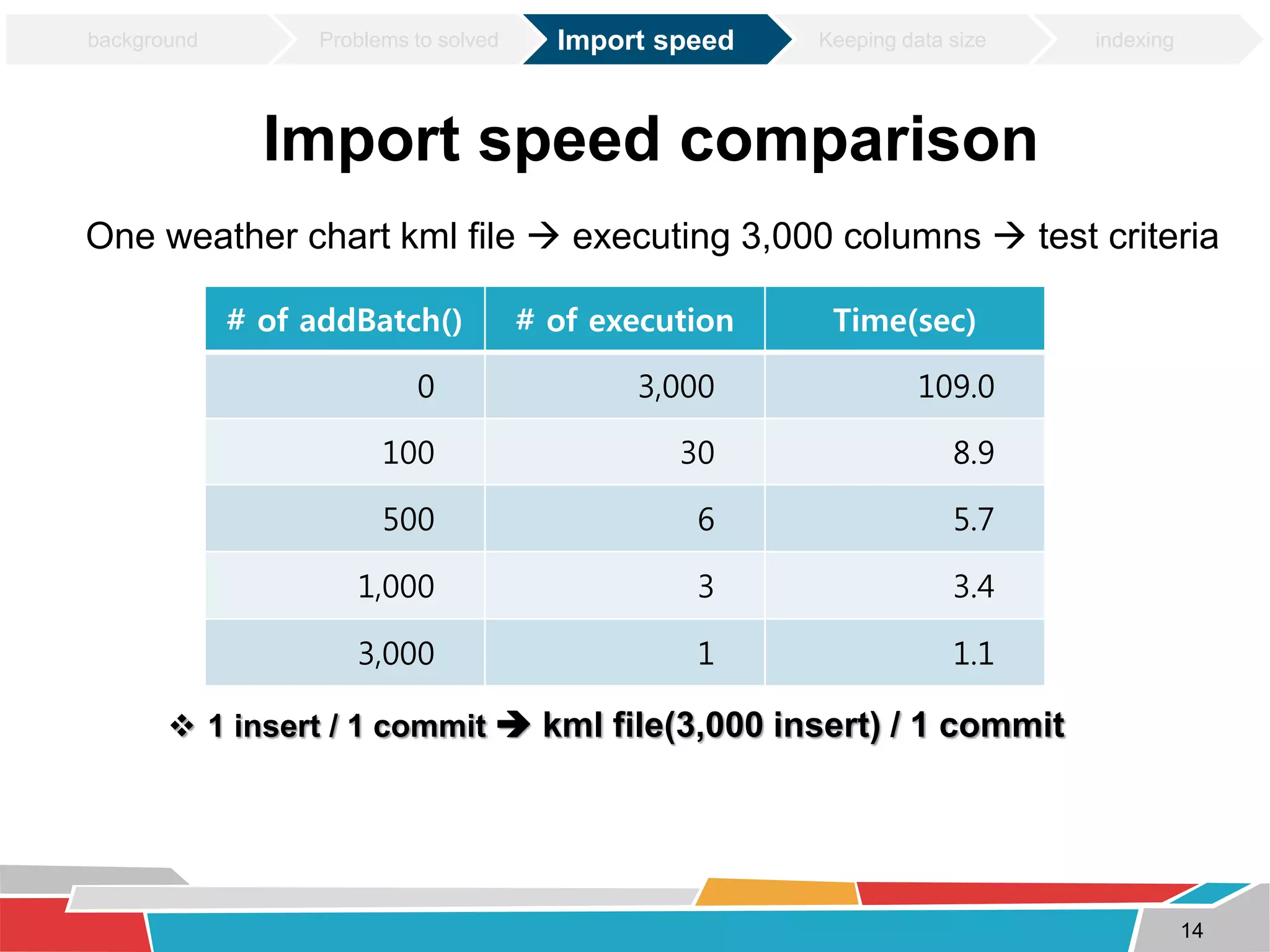


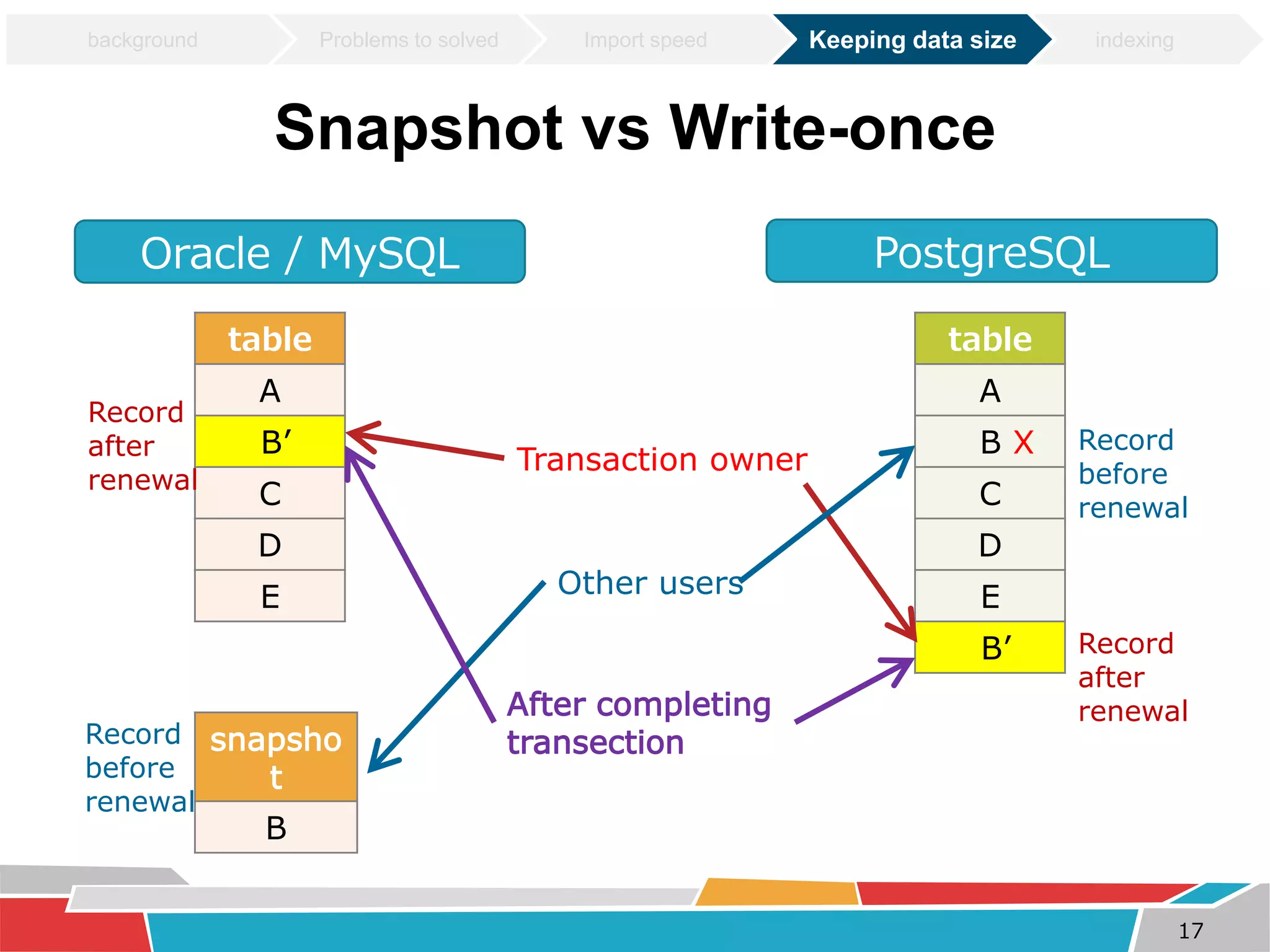
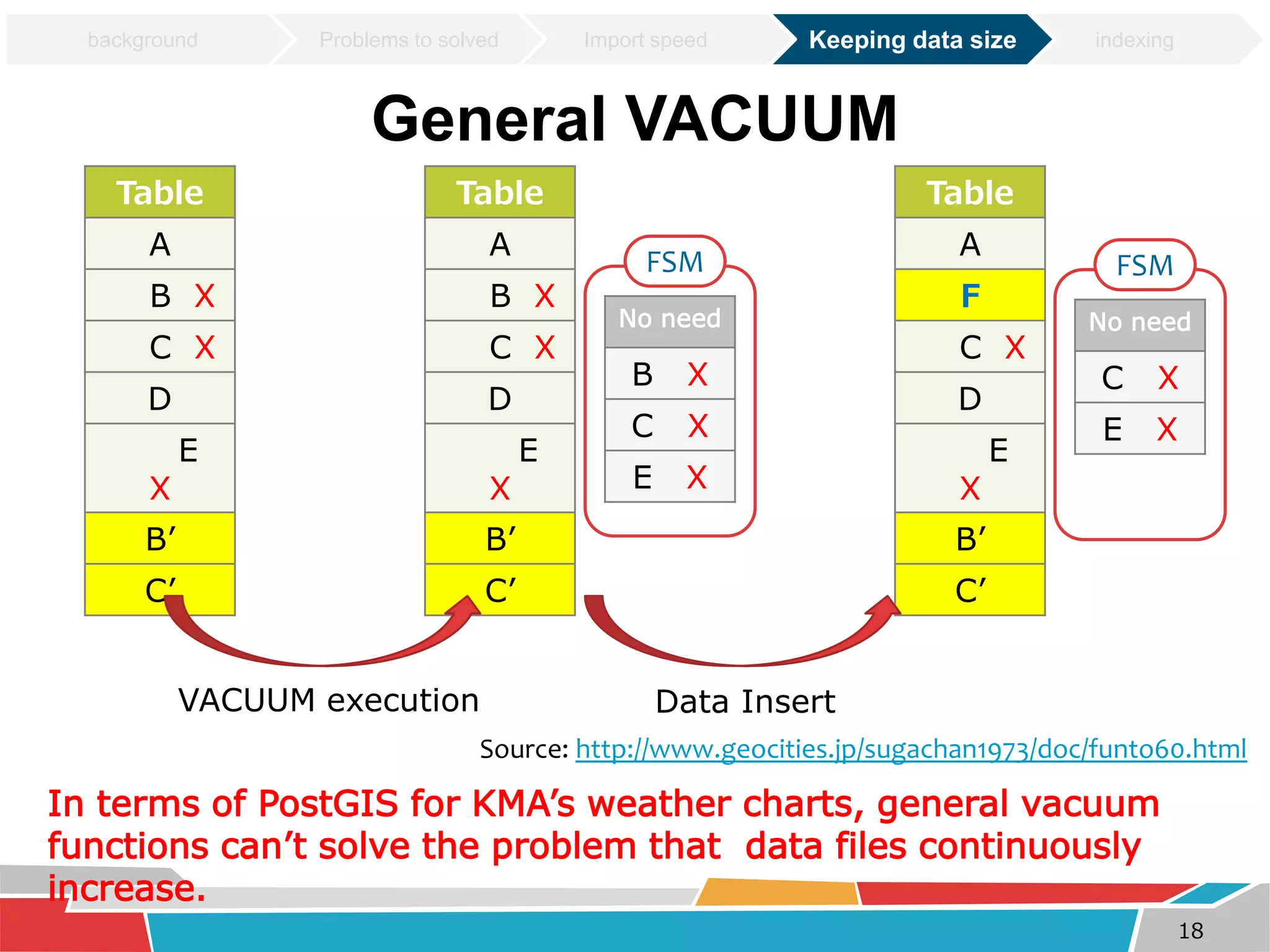

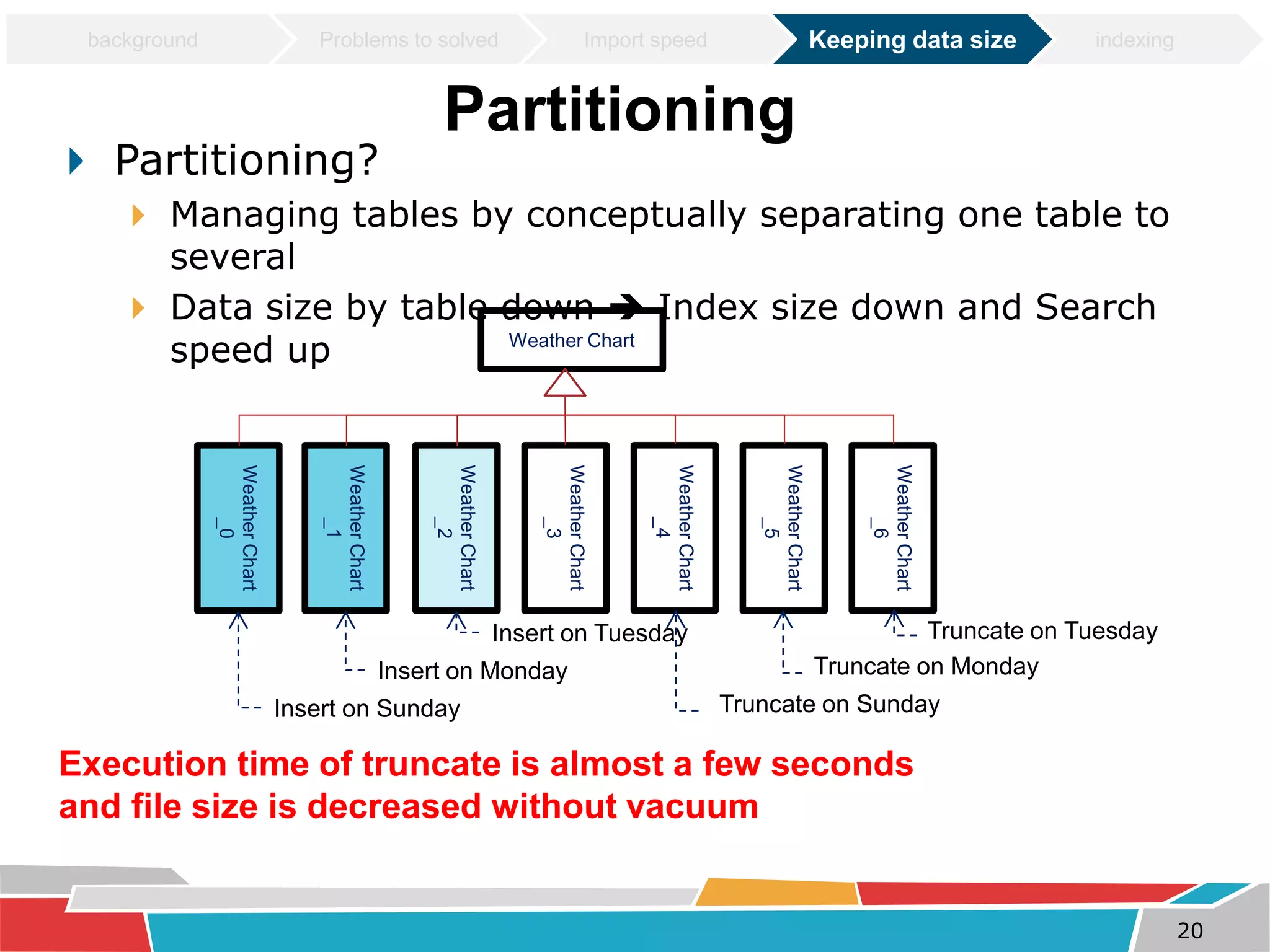

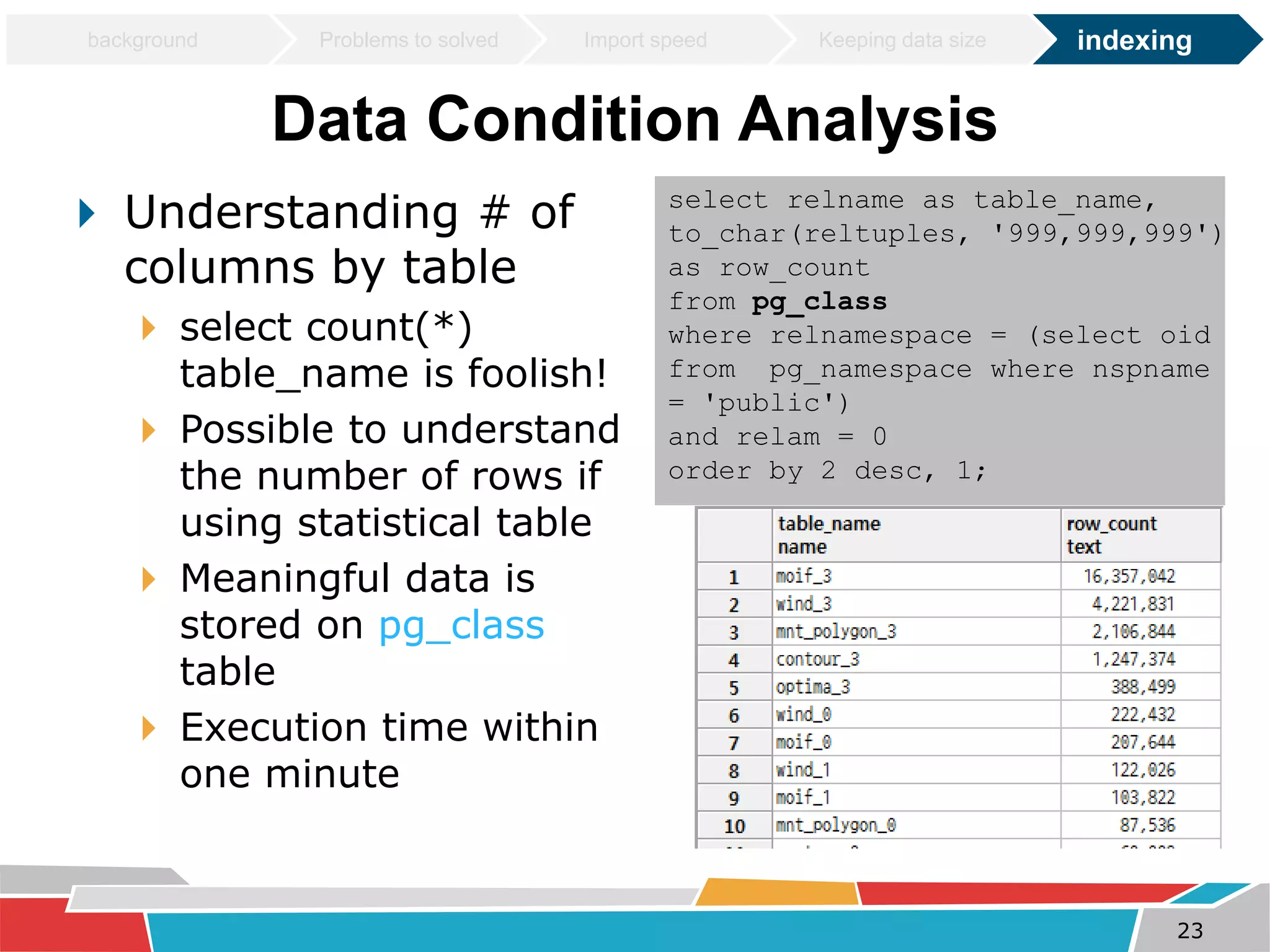

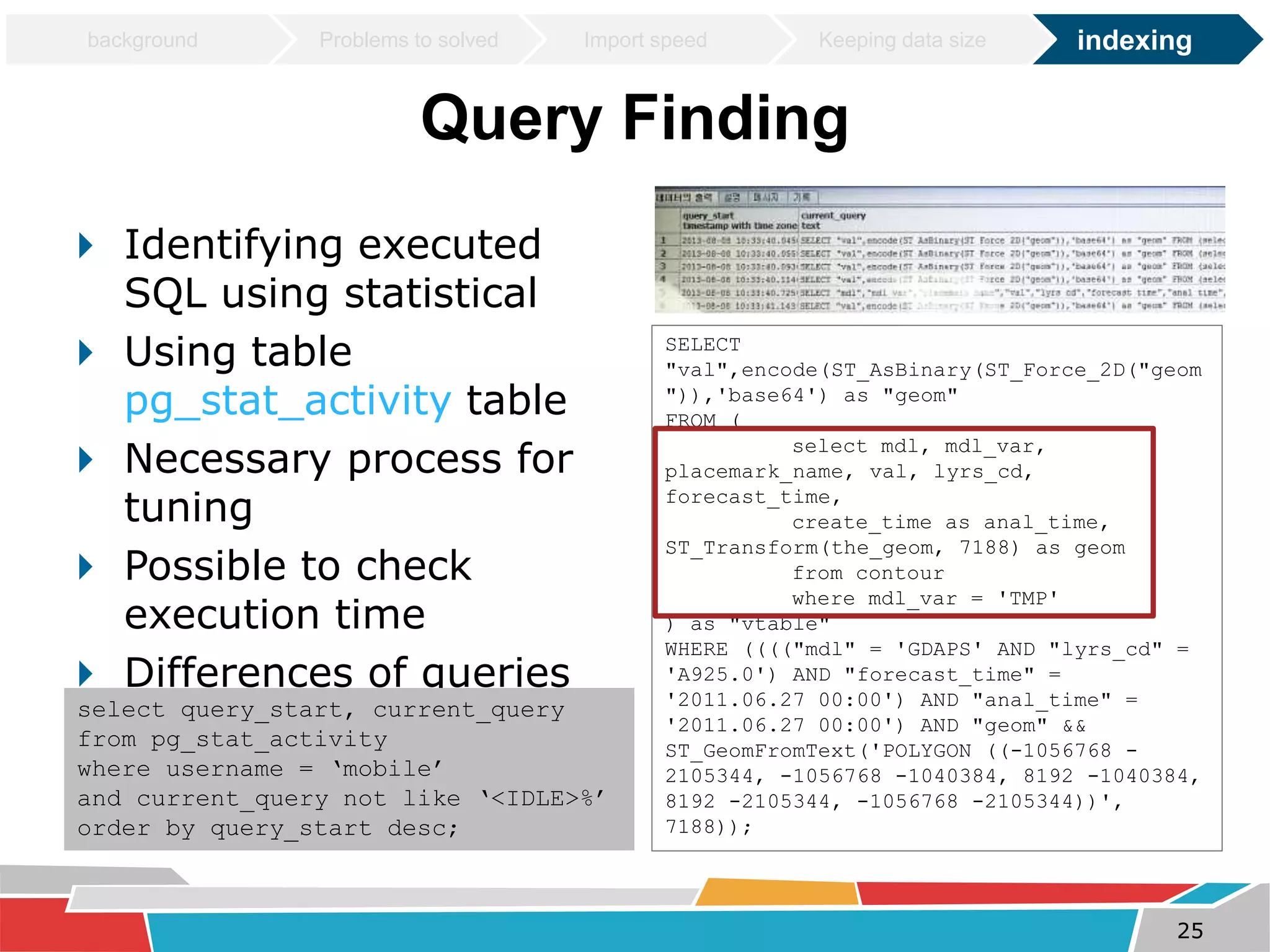
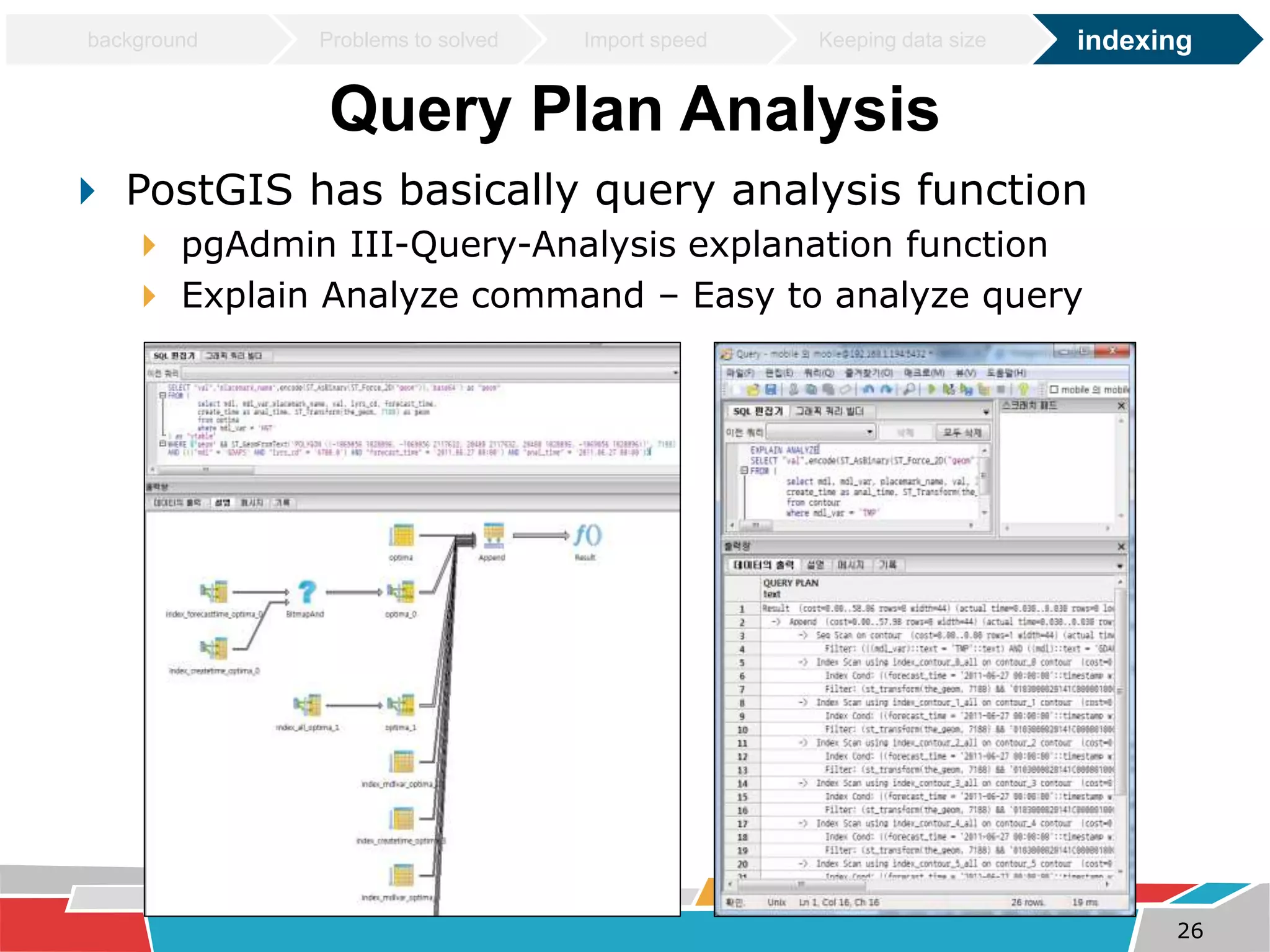


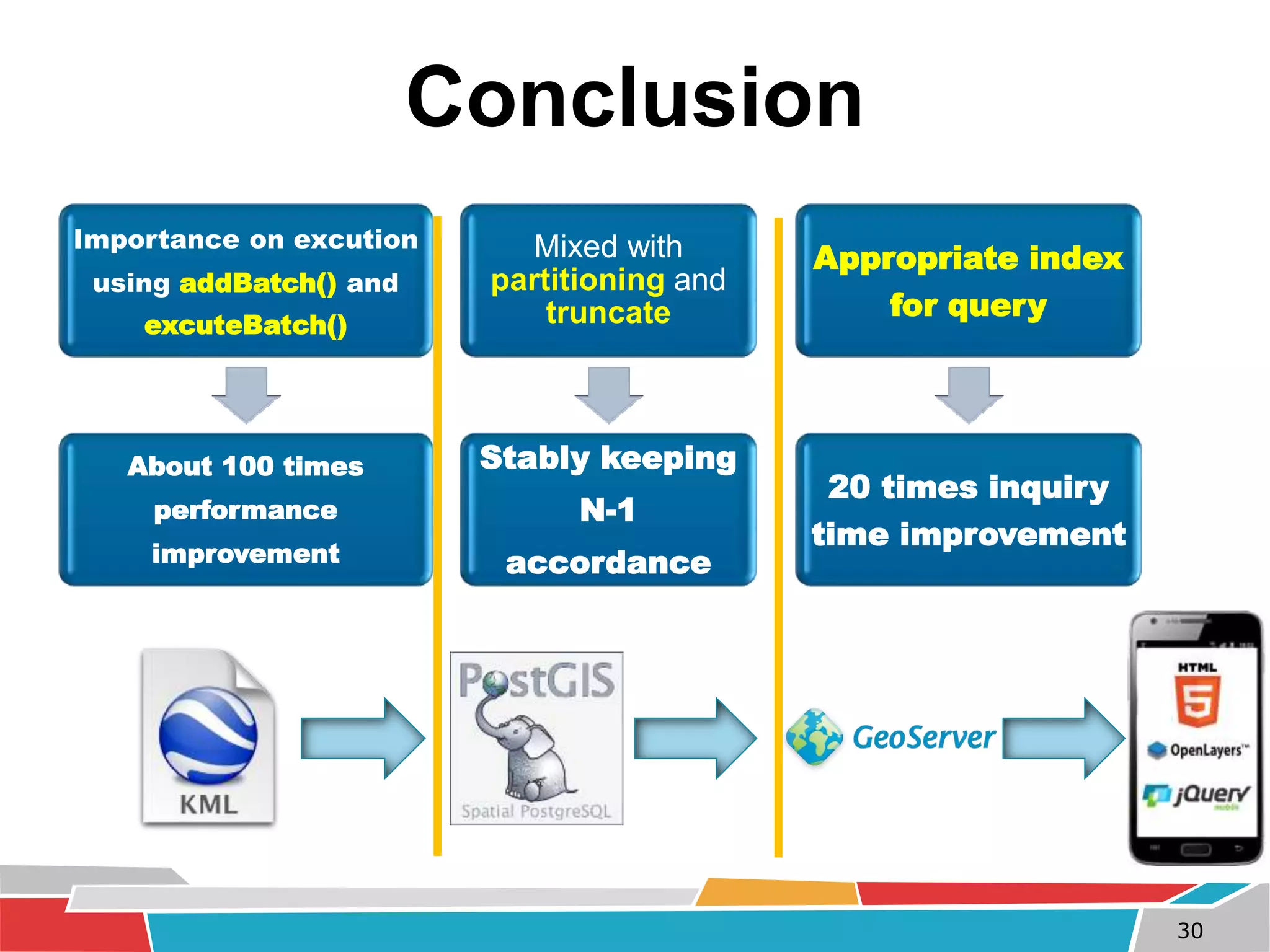



This document discusses tuning techniques used to improve the performance of a mobile weather chart service using PostGIS and GeoServer. The initial system was slow due to a lack of tuning. Tuning techniques included: 1) Improving import speed by batching inserts instead of single inserts, reducing import time from over 5 hours to under 30 minutes. 2) Managing data size by partitioning tables and truncating partitions daily to keep file sizes fixed. 3) Improving query speeds by analyzing queries, redesigning indexes on frequently searched columns, and reducing index sizes. These tuning efforts improved query speeds by up to 25 times.
![[Foss4 g2013]the architecture of mobile traffic map service final](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2013thearchitectureofmobiletrafficmapservicefinal-140325221039-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![[FOSS4G Korea 2016] GeoHash를 이용한 지형도 변화탐지와 시계열 관리](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2016koreageohash-160905074529-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Foss4 g2014 korea] qgis를 플랫폼으로 한 파이썬기반 공간통계 구현 사례](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2014koreaqgis-140828044955-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Foss4 g2013 korea]postgis와 geoserver를 이용한 대용량 공간데이터 기반 일기도 서비스 구축 사례](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2013koreapostgisgeoserver-140325221011-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















