Downloaded 17 times













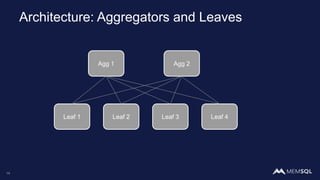
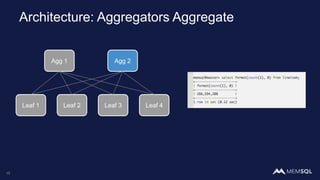
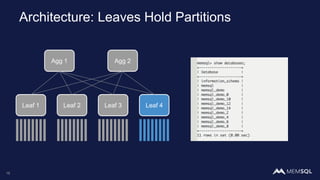
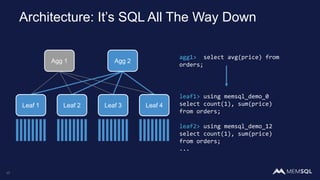














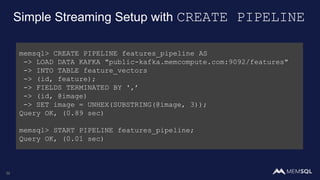
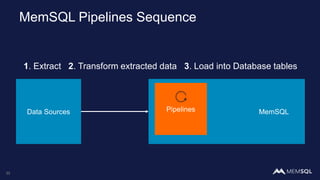
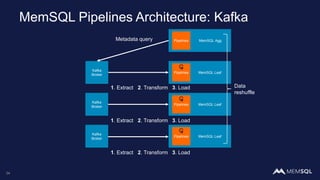
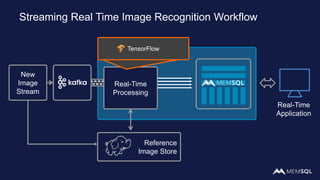




This document discusses using MemSQL to perform real-time image recognition on streaming data. Key points include: - Feature vectors extracted from images using models like TensorFlow can be stored in MemSQL tables for analysis. - MemSQL allows querying these feature vectors to find similar images based on cosine similarity calculations. - This enables applications like detecting duplicate or illegal images in real-time streams.























































































