Downloaded 20 times














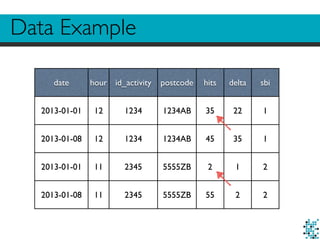
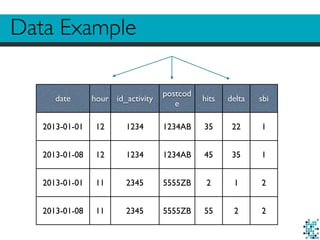
![helper.py example
def get_statistics(data, sbi):
sbi_df = data[data.sbi == sbi]
# select * from data where sbi = sbi
hits = sbi_df.hits.sum() # select sum(hits) from …
delta_hits = sbi_df.delta.sum() # select sum(delta) from …
if delta_hits:
percentage = (hits - delta_hits) / delta_hits
else:
percentage = 0
return {"sbi": sbi, "total": hits, "percentage": percentage}](https://image.slidesharecdn.com/nosql-barcelona-141125012208-conversion-gate01/85/Giovanni-Lanzani-SQL-NoSQL-databases-for-data-driven-applications-NoSQL-matters-Barcelona-2014-20-320.jpg)
![helper.py example
def get_timeline(data, sbi):
df_sbi = data.groupby([“date”, “hour", “sbi"]).aggregate(sum)
# select sum(hits), sum(delta) from data group by date, hour, sbi
return df_sbi](https://image.slidesharecdn.com/nosql-barcelona-141125012208-conversion-gate01/85/Giovanni-Lanzani-SQL-NoSQL-databases-for-data-driven-applications-NoSQL-matters-Barcelona-2014-21-320.jpg)














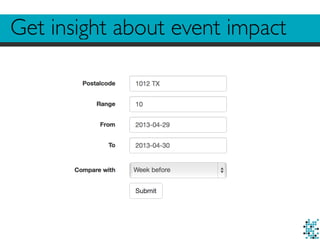
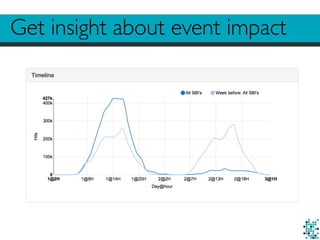
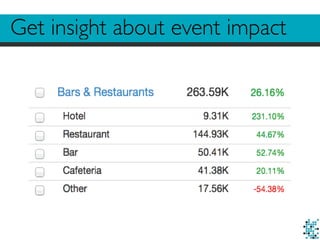
1. The document discusses challenges in building real-time, data-driven applications including dealing with big data, privacy concerns, performing some real-time analysis, and enabling real-time retrieval of large datasets. 2. It describes using Hadoop to store, enrich, and preprocess raw logs totaling around 40TB of data, while addressing privacy needs. 3. The author details techniques used to enable fast real-time retrieval of data points within a given date range and radius from a center location, such as indexing data and using temporary tables.







![[WebMuses] Big data dla zdezorientowanych](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatadlazdezorientowanych-141023123710-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)














































































