Download as PDF, PPTX










![Ranking using latent
representation
• If user = [-100, -100]
• 2d latent factor
• We get the corresponding ranking](https://image.slidesharecdn.com/soundcloud-meetup-140302034159-phpapp02/85/Ranking-and-Diversity-in-Recommendations-RecSys-Stammtisch-at-SoundCloud-Berlin-15-320.jpg)
![Matrix Factorization
(for ranking)
• Randomly initialize item vectors
• Randomly initialize user vectors
• While not converged
• Compute rating prediction error
• Update user factors
• Update item factors
• Lets say user is [-100, -100]
• Compute the square error
• (5-<[-100, -100], [0.180, 0.19]>)2=1764
• Update the user and item to the direction
where the error is reduced
(according to the gradient of the loss)
8 items with ratings
and random factors](https://image.slidesharecdn.com/soundcloud-meetup-140302034159-phpapp02/85/Ranking-and-Diversity-in-Recommendations-RecSys-Stammtisch-at-SoundCloud-Berlin-16-320.jpg)
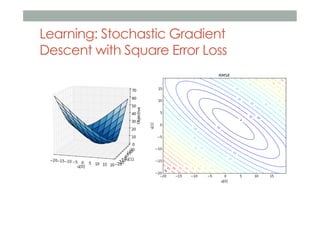
![SquareUser: [3, 1], RMSE=6.7
Loss](https://image.slidesharecdn.com/soundcloud-meetup-140302034159-phpapp02/85/Ranking-and-Diversity-in-Recommendations-RecSys-Stammtisch-at-SoundCloud-Berlin-18-320.jpg)

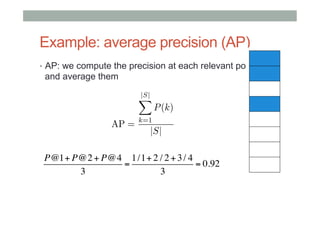
![Why is hard? Non Smoothness
Example: AP
u:[-20,-20]
u:[20,20]](https://image.slidesharecdn.com/soundcloud-meetup-140302034159-phpapp02/85/Ranking-and-Diversity-in-Recommendations-RecSys-Stammtisch-at-SoundCloud-Berlin-21-320.jpg)
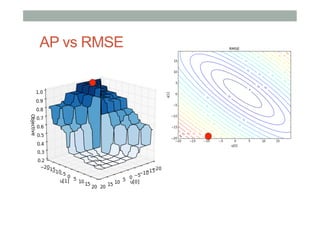

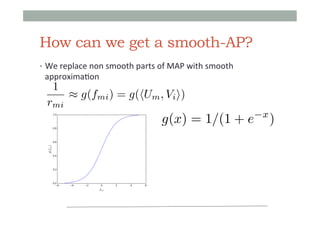
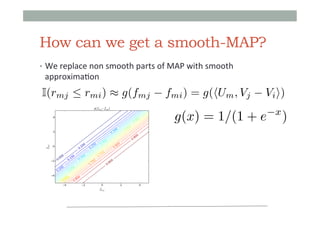
![Smooth version of MAP
u:[-20,-20]
u:[20,20]](https://image.slidesharecdn.com/soundcloud-meetup-140302034159-phpapp02/85/Ranking-and-Diversity-in-Recommendations-RecSys-Stammtisch-at-SoundCloud-Berlin-26-320.jpg)
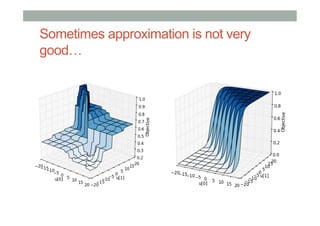


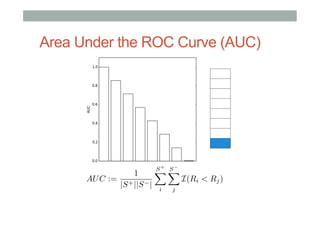
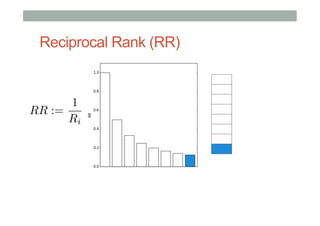
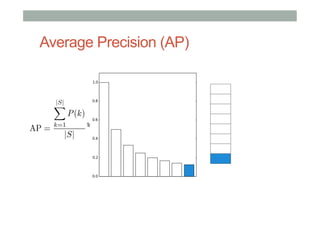
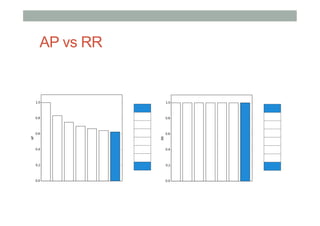
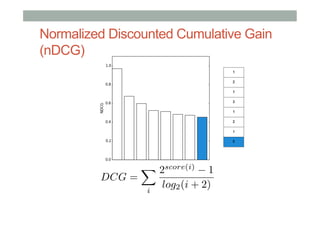





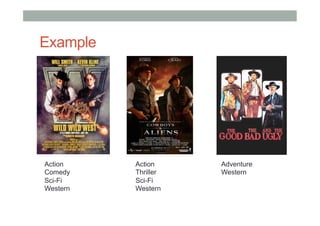
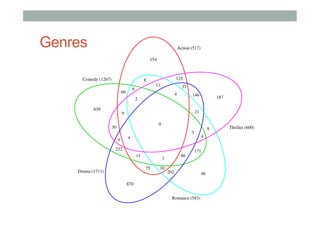
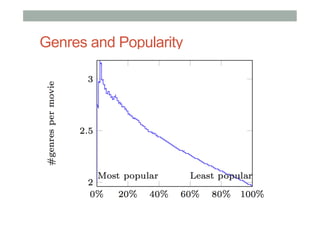




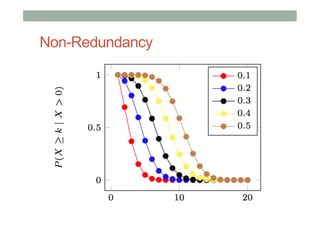





The document discusses ranking and diversity in recommender systems, emphasizing the importance of accurate ranking and the challenges involved, such as learning to rank directly rather than predicting ratings. It outlines various ranking methods, potential inconsistencies, and the need for diversity in recommendations through techniques like intent-aware metrics and genre-based diversity. Additionally, it introduces new diversity metrics based on the binomial distribution and highlights coverage and redundancy considerations in recommendation algorithms.


![[SIGIR17] Learning to Rank Using Localized Geometric Mean Metrics](https://cdn.slidesharecdn.com/ss_thumbnails/slides-170808085021-thumbnail.jpg?width=640&height=640&fit=bounds)



















































































