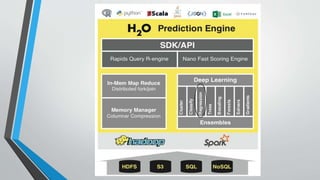
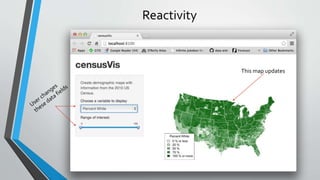
The document evaluates various machine learning algorithms using h2o.ai to analyze census data for income predictions. It highlights the effectiveness of algorithms like linear regression and discusses the benefits of using R packages, specifically Shiny, for data visualization. The project emphasizes the accessibility of machine learning tools and their importance in data analysis.