Downloaded 94 times






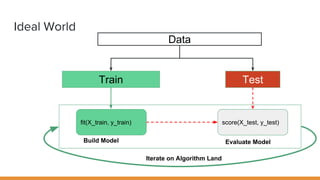

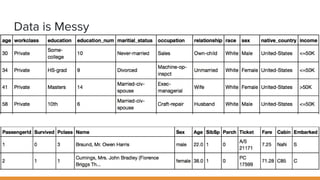
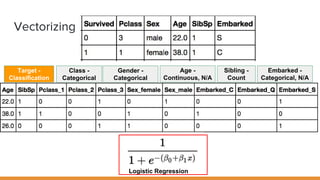
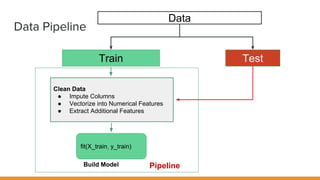
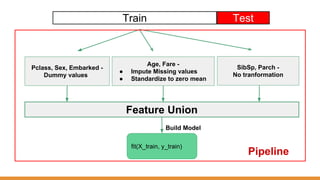


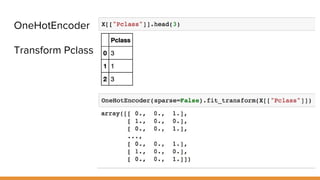


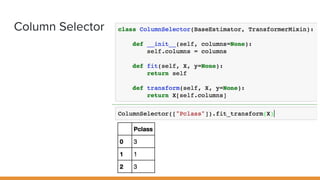
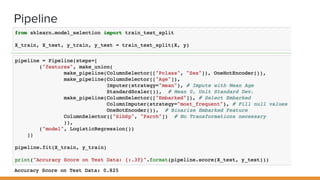
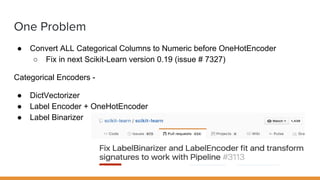

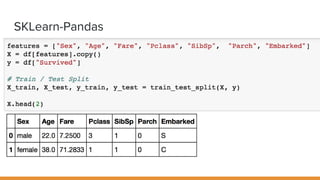
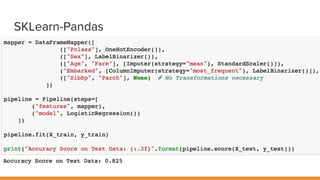
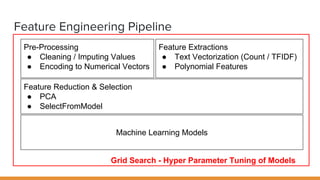
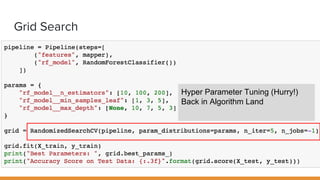




The document discusses feature engineering pipelines in scikit-learn and Python, emphasizing the necessity of preprocessing messy real-world data to build and evaluate machine learning models. It outlines various techniques for data cleaning, transformation, and encoding, as well as tools like sklearn-pandas for enhancing feature engineering processes. The author also shares resources and practical implementations for effective machine learning model training and evaluation.



































































