The document presents insights on using CXL (Compute Express Link) in AI applications, highlighting memory expansion form factors, latency and bandwidth management strategies. It discusses configurations for optimizing memory performance across different tiers of storage, including hot and cold data placement. Benchmark results from various tests indicate performance variances based on configurations used, emphasizing the importance of understanding application behaviors for optimal system performance.







![• Intel VTune Profiler and toplev are great tools to use
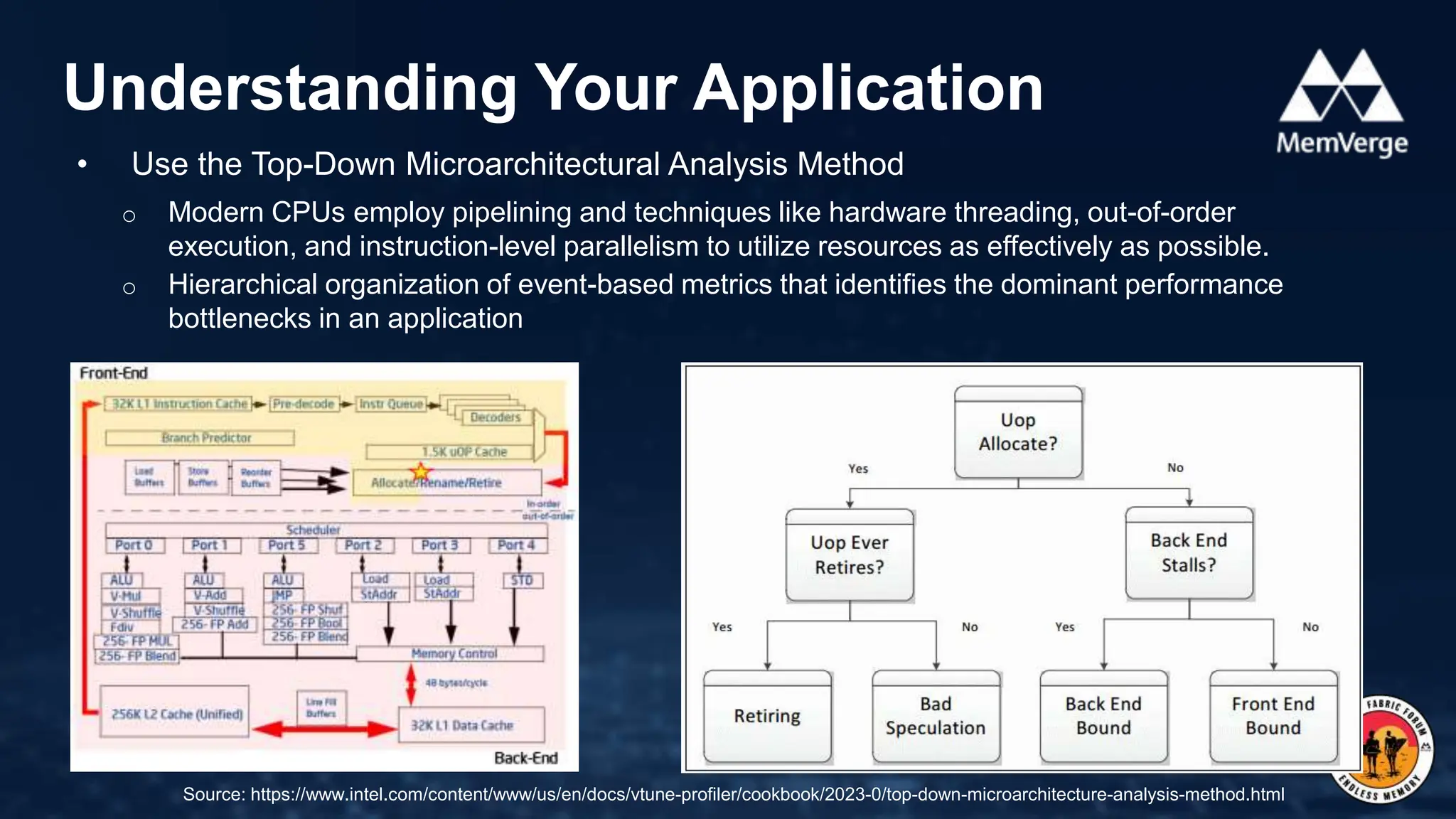
Understanding Your Application
12
$ toplev -l2 --nodes '!+Memory_Bound*/3,+Backend_Bound,+MUX' stream_c.exe --ntimes 1000
--ntimes 1000 --array-size 40M –malloc
<.... Generated application output ... >
# 4.7-full on Intel(R) Xeon(R) Gold 6438Y+ [spr/sapphire_rapids]
BE Backend_Bound % Slots 88.6 [20.0%]
BE/Mem Backend_Bound.Memory_Bound % Slots 62.1 [20.0%]<==
This metric represents fraction of slots the Memory
subsystem within the Backend was a bottleneck...
warning: 5 nodes had zero counts: DRAM_Bound L1_Bound L2_Bound L3_Bound Store_
Bound
Run toplev --describe Memory_Bound^ to get more information on bottleneck
Add --run-sample to find locations](https://image.slidesharecdn.com/memverge-usingcxlwithaiapplications-stevescargall-240215164239-d7cea8c9/75/Q1-Memory-Fabric-Forum-Using-CXL-with-AI-Applications-Steve-Scargall-pptx-12-2048.jpg)

















































































