Q1 Memory Fabric Forum: Advantages of Optical CXL for Disaggregated Compute Architectures
The document discusses the advantages of optical CXL technology in disaggregated compute architectures, highlighting the growing demand for memory-centric approaches due to the rise of AI and large language models. A case study demonstrates the efficiency of CXL memory offloading for LLM inference, showing significant performance improvements compared to traditional memory solutions. Key features of optical CXL technology are presented, including its ability to support high bandwidth and reduced latency in data center environments.
Overview of Optical CXL for disaggregated compute architectures with a focus on its advantages and the agenda involving AI and memory-centric shifts.
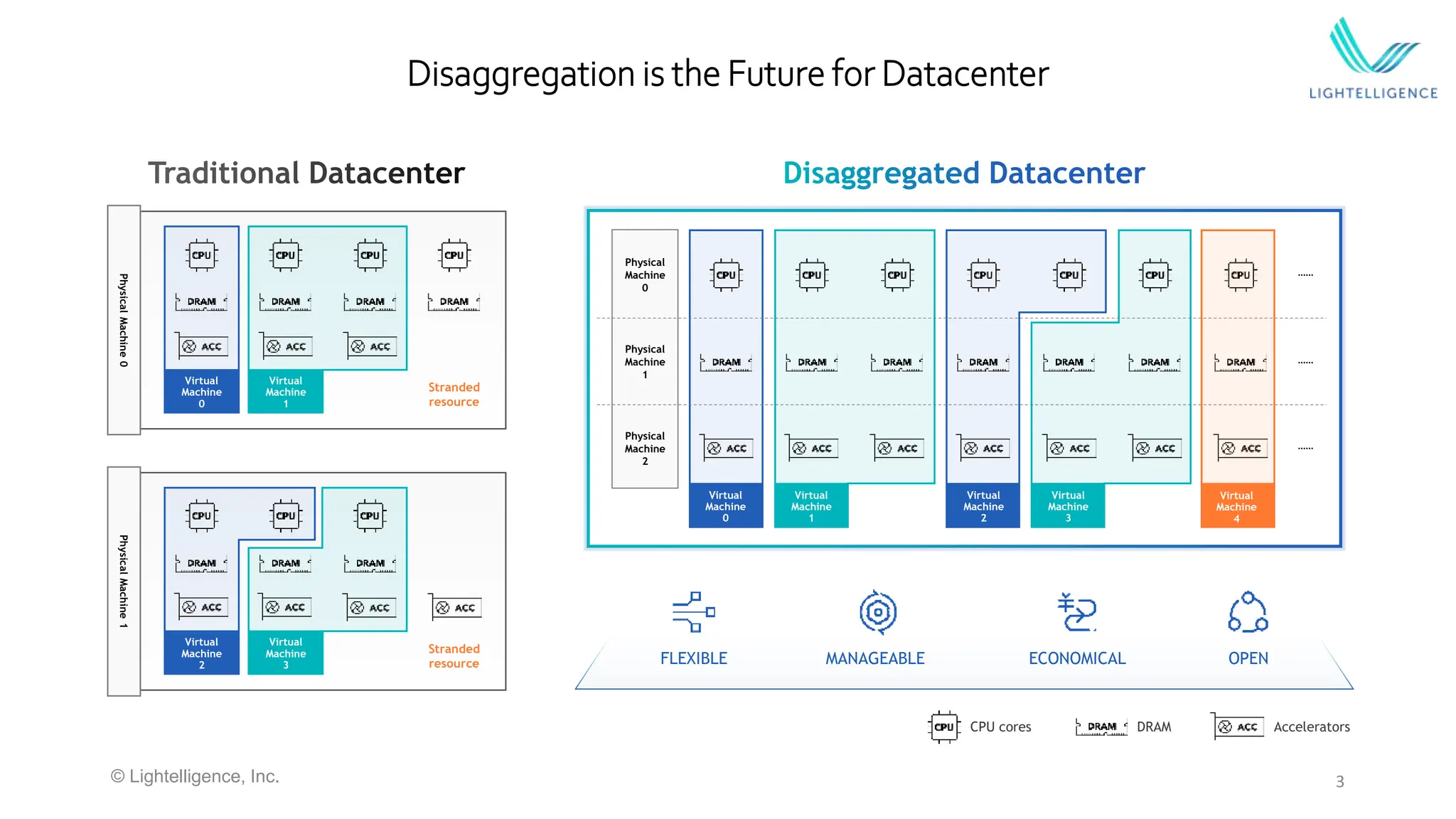
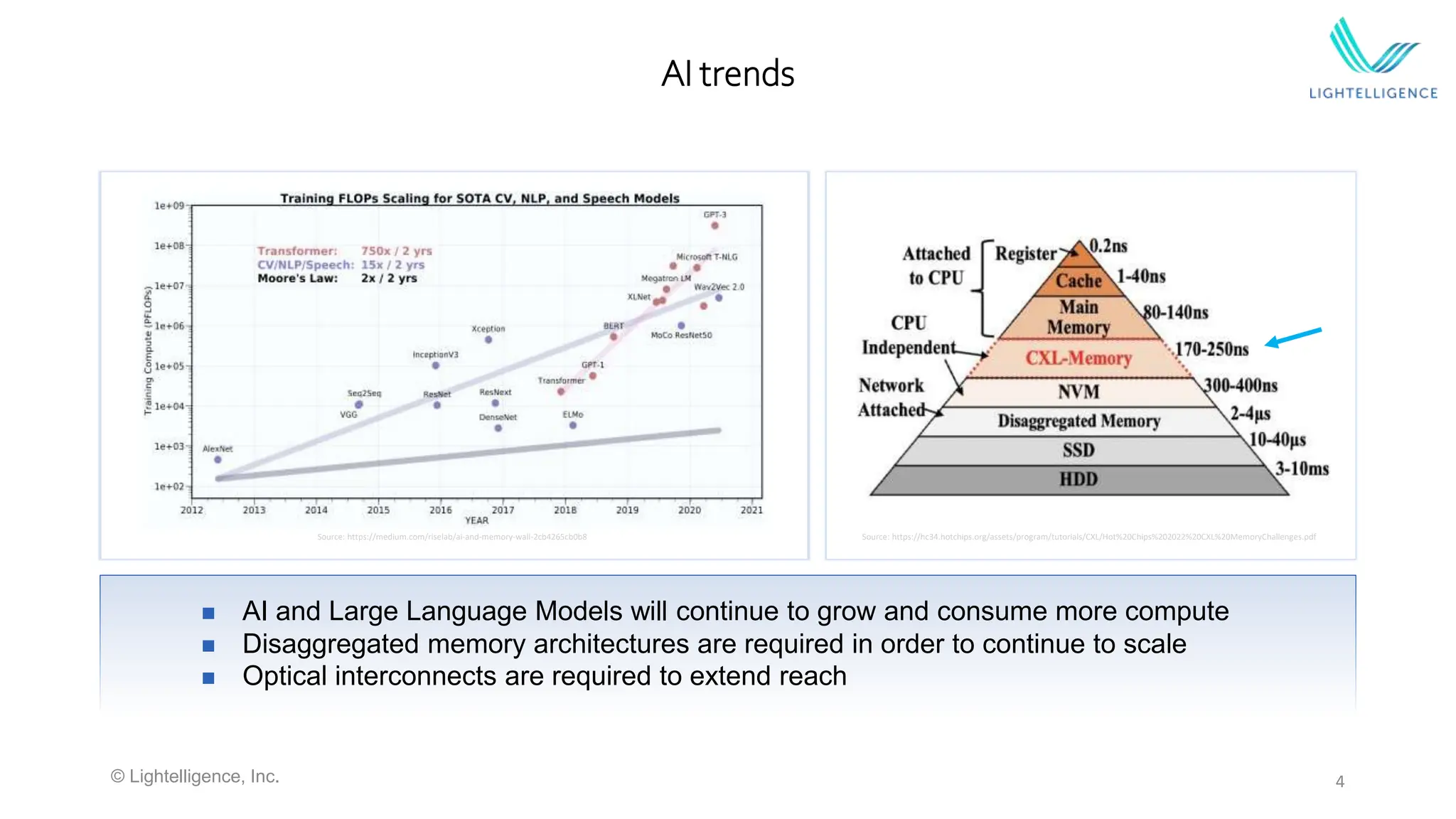
Emphasizes the future of data centers with disaggregation and the necessity of optical interconnects for scaling AI models.
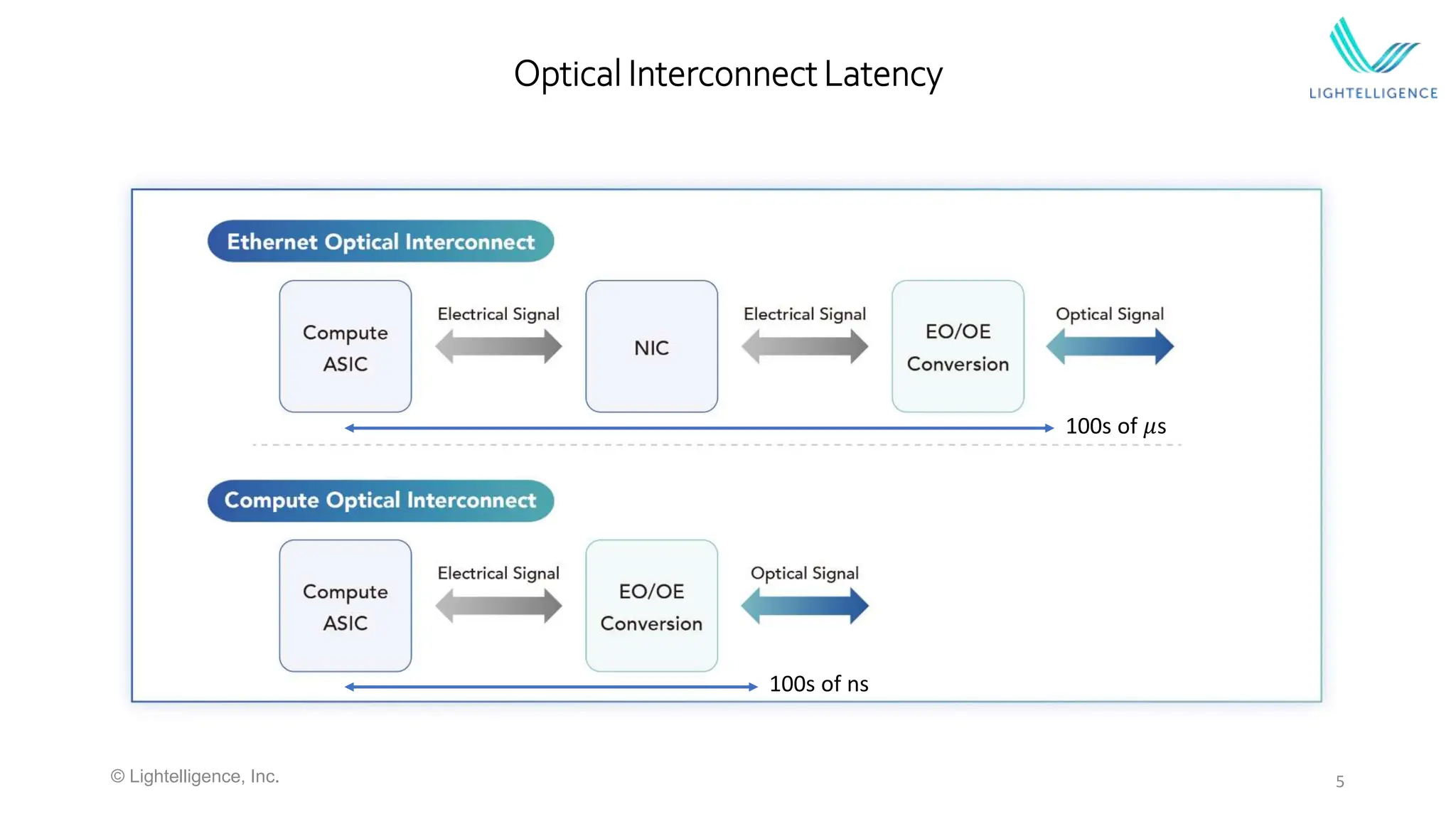
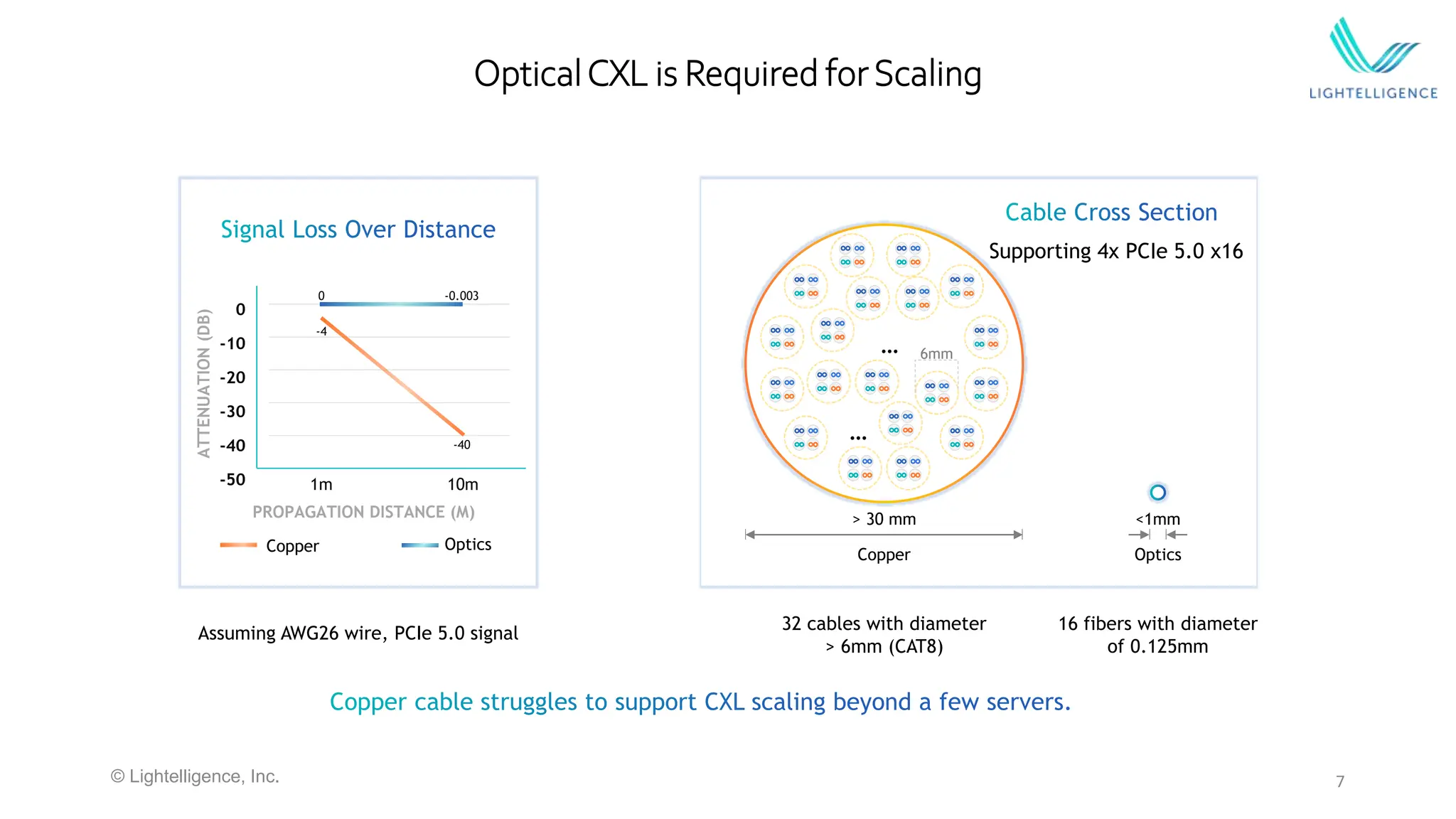
Discussion of optical interconnect latency and the essential role of Optical CXL in addressing challenges of disaggregated architectures in data centers.
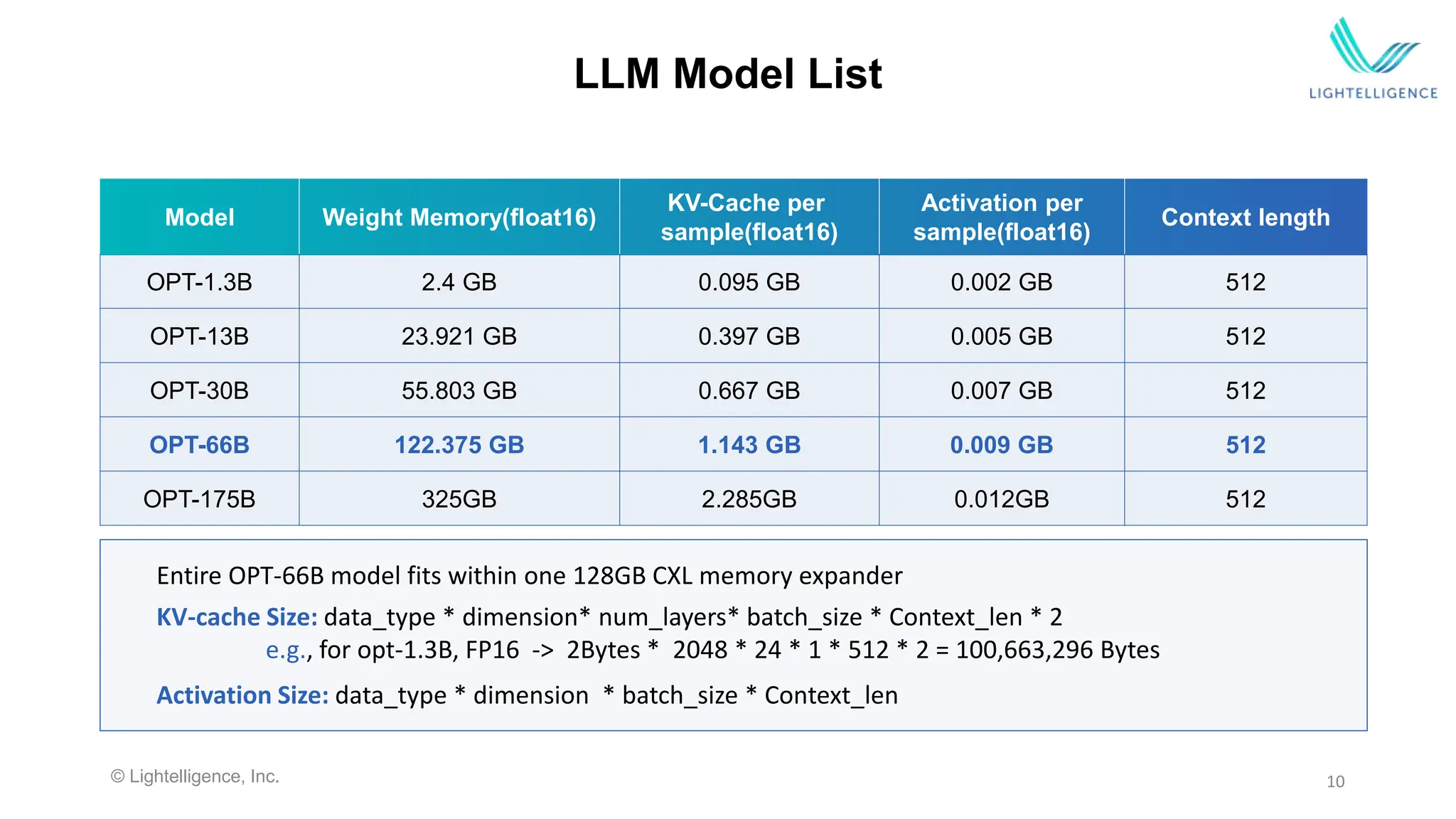
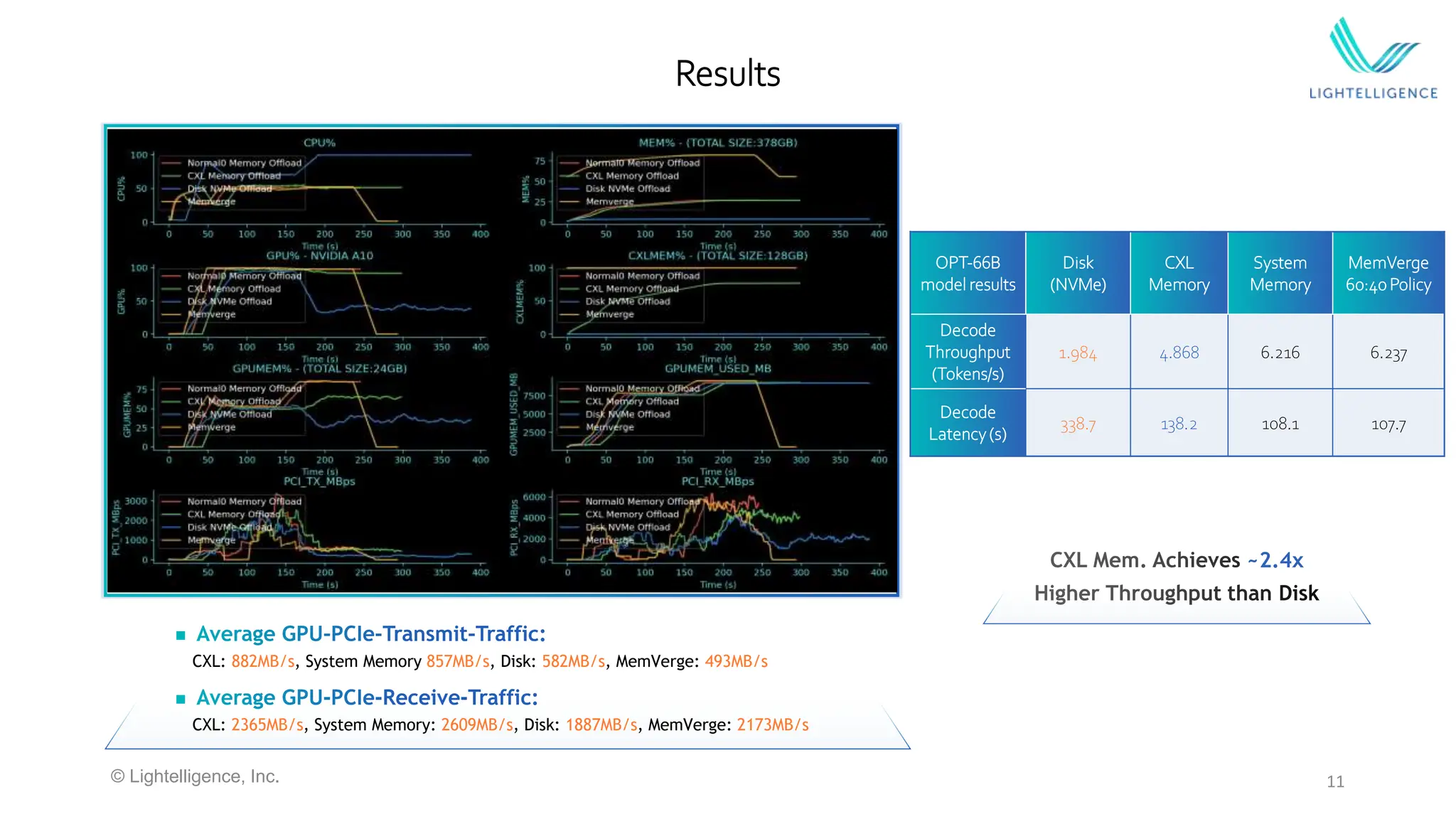
Details a case study on LLM inference utilizing CXL memory expanders, highlighting performance metrics and advantages over traditional systems.
Summarizes the performance benefits of CXL memory offloading compared to conventional memory, showing significant improvements in efficiency and cost.
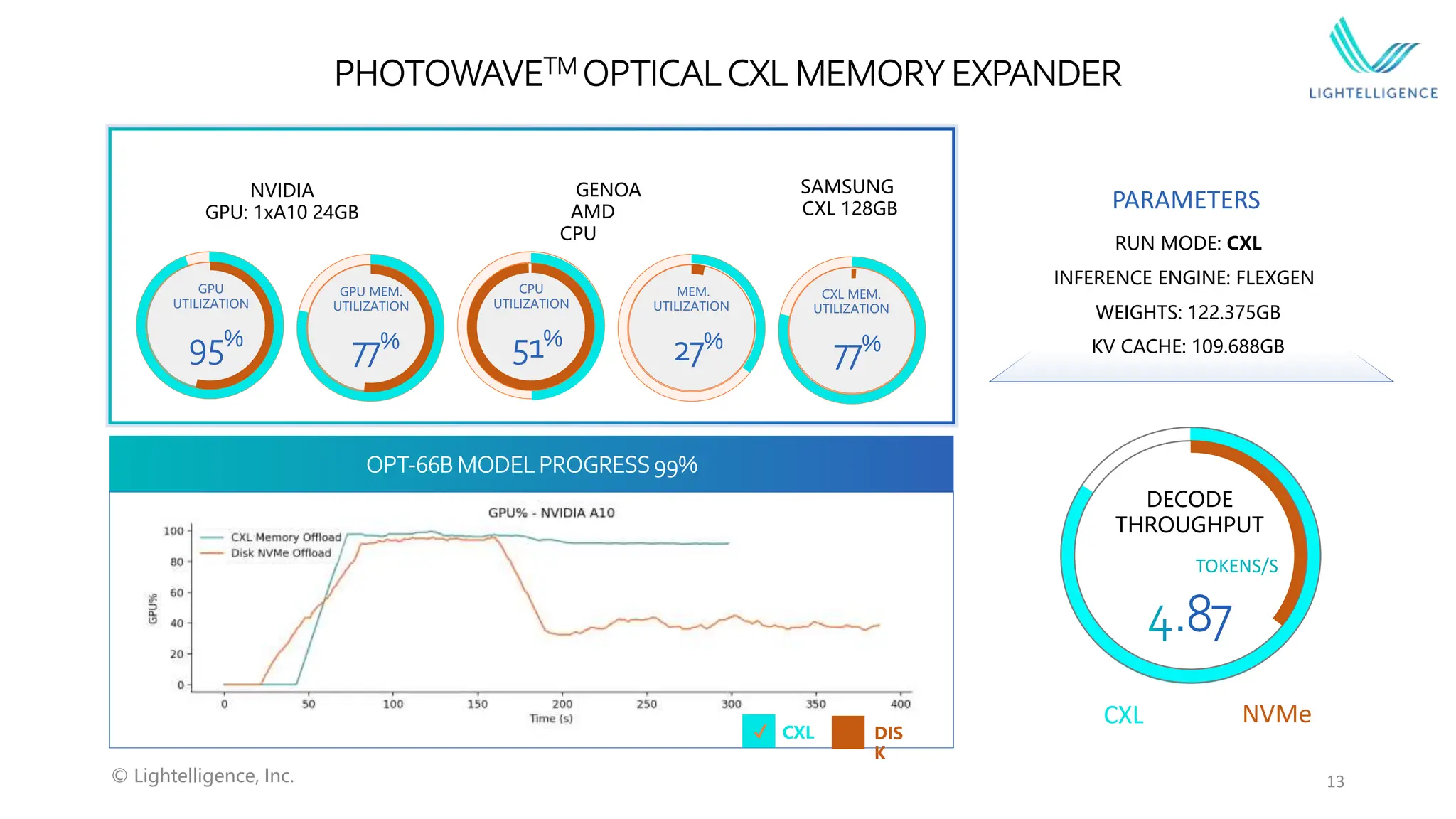
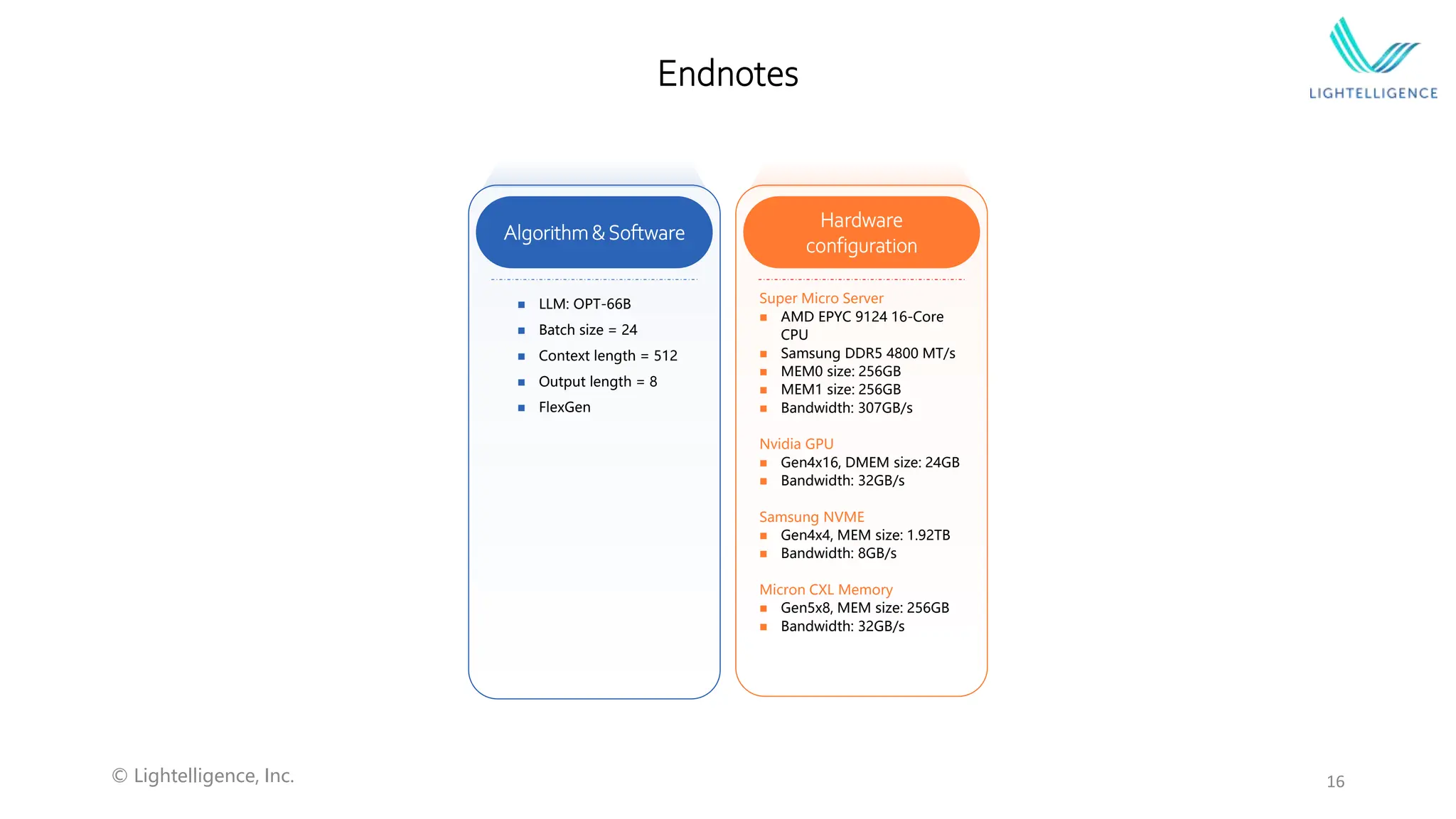
Information about Photowave's optical CXL memory expander features, hardware configurations, and endnotes highlighting system specifications.
Q1 Memory Fabric Forum: Advantages of Optical CXL for Disaggregated Compute Architectures
1.
Harnessing light topower new possibilities
Advantages of Optical CXL
for Disaggregated Compute Architectures
Ron Swartzentruber
Director of Engineering
#7 Key message: CXL is industry consensus for disaggregation
#12 MemVerge policy: System memory 60%, CXL Memory 40%
#14 What is CPU%
********************************************************************************
CPU%
mem 29.525
cxl 31.431000000000004
disk 81.46
main.py:36: MatplotlibDeprecationWarning: Calling gca() with keyword arguments was deprecated in Matplotlib 3.4. Starting two minor releases later, gca() will take no keyword arguments. The gca() function should only be used to get the current axes, or if no axes exist, create new axes with default keyword arguments. To create a new axes with non-default arguments, use plt.axes() or plt.subplot().
ax = plt.gca(facecolor='black')
********************************************************************************
MEM%
mem 27.2
cxl 27.2
disk 11.722000000000001
********************************************************************************
GPU%
mem 99.49
cxl 97.05
disk 53.01
********************************************************************************
CXLMEM%
mem 0.0016306192454823602
cxl 77.11430249904593
disk 0.1663918208702139
********************************************************************************
GPUMEM%
mem 45.17
cxl 49.0
disk 34.71
********************************************************************************
GPUMEM_USED_MB
mem 9213.4375
cxl 9213.4375
disk 8979.4375
********************************************************************************
PCI_TX_MBps
mem 274.2578125
cxl 191.357421875
disk 81.064453125
********************************************************************************
PCI_RX_MBps
mem 2007.3828125
cxl 1422.421875
disk 1158.056640625
(tfpy38) hussainazhar@Hussains-MacBook-Air T4gpu % python main.py
********************************************************************************
CPU%
mem 29.525
cxl 31.431000000000004
disk 81.46
main.py:36: MatplotlibDeprecationWarning: Calling gca() with keyword arguments was deprecated in Matplotlib 3.4. Starting two minor releases later, gca() will take no keyword arguments. The gca() function should only be used to get the current axes, or if no axes exist, create new axes with default keyword arguments. To create a new axes with non-default arguments, use plt.axes() or plt.subplot().
ax = plt.gca(facecolor='black')
********************************************************************************
MEM%
mem 27.2
cxl 27.2
disk 11.722000000000001
********************************************************************************
GPU%
mem 99.49
cxl 97.05
disk 53.01
********************************************************************************
CXLMEM%
mem 0.0016306192454823602
cxl 77.11430249904593
disk 0.1663918208702139
********************************************************************************
GPUMEM%
mem 45.17
cxl 49.0
disk 34.71
********************************************************************************
GPUMEM_USED_MB
mem 9213.4375
cxl 9213.4375
disk 8979.4375
********************************************************************************
PCI_TX_MBps
mem 274.2578125
cxl 191.357421875
disk 81.064453125
********************************************************************************
PCI_RX_MBps
mem 2007.3828125
cxl 1422.421875
disk 1158.056640625






































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















