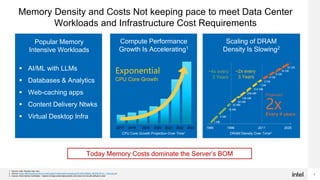
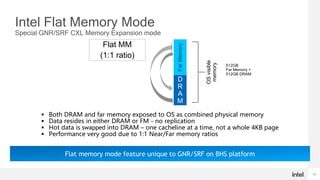
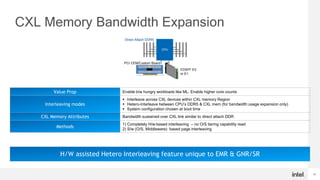
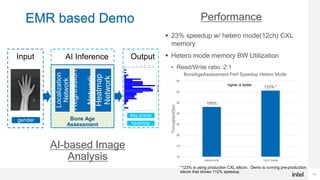
- Memory intensive workloads are dominating computing and increasing memory capacity just with CPU-attached DRAM is getting expensive.
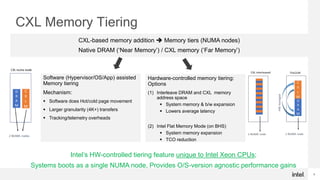
- CXL allows augmenting system memory footprint at lower cost by running over existing PCIe links to add memory outside of the CPU package.
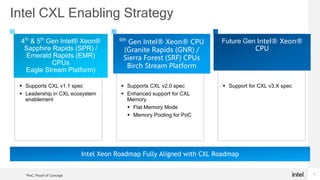
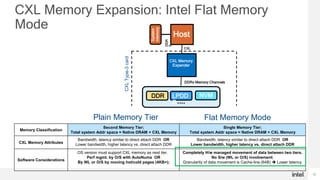
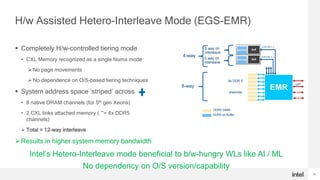
- Intel Xeon roadmap fully supports CXL starting with 5th Gen Xeons, and Intel CPUs offer unique hardware-based tiering modes between native DRAM and CXL memory without depending on the operating system.
- CXL has full industry support as the standard for coherent input/output.