Downloaded 96 times







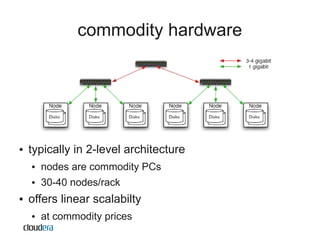







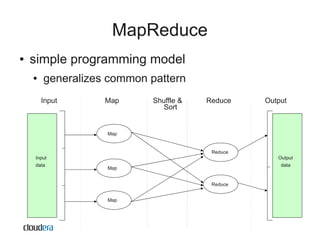






The document discusses Apache Hadoop as a scalable and cost-effective solution for processing large datasets on commodity hardware, addressing challenges like data storage and fault tolerance. It highlights the software's ability to efficiently manage petabytes of data while utilizing all available computing resources. Hadoop's open-source nature encourages community support and facilitates diverse applications, making it a valuable tool for companies across various sectors.






























































































