Download to read offline


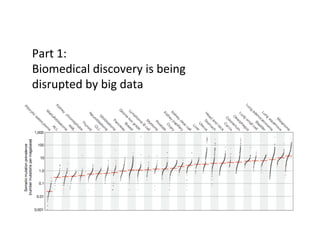
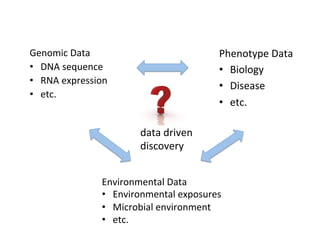


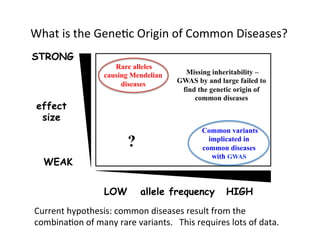



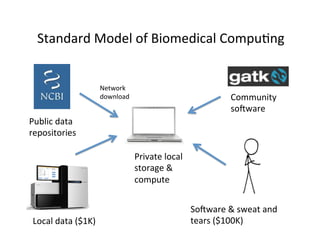

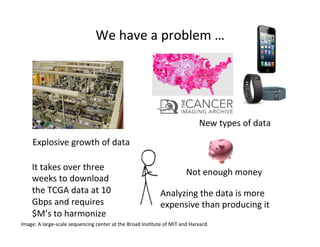

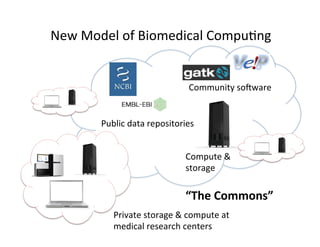
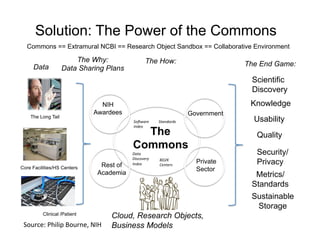


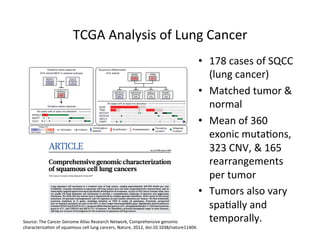
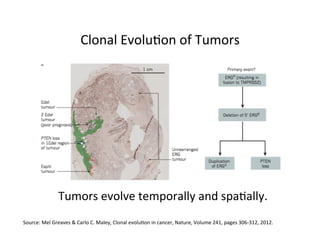
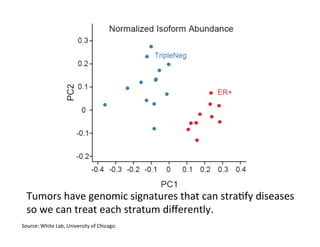






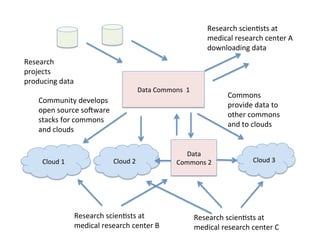
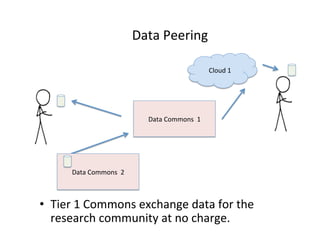
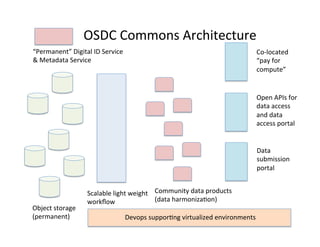

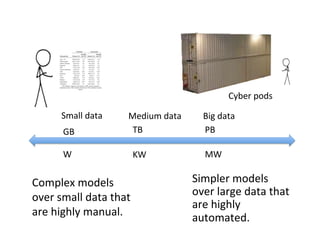

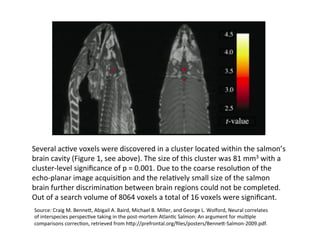


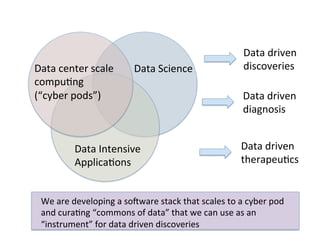

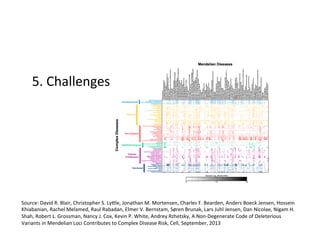










This document discusses how biomedical discovery is being disrupted by big data. Large genomic, phenotype, and environmental datasets are needed to understand complex diseases that result from combinations of many rare variants. However, analyzing large biomedical data is costly and difficult given the standard model of local computing. The document proposes creating large "commons" of community data and computing as an instrument for big data discovery. Examples are given of the Cancer Genome Atlas project, which has petabytes of research data on thousands of cancer patients, and how tumors evolve over time. Overall, the document argues that new models of shared biomedical clouds and commons are needed to enable cost-effective analysis of big biomedical data.






































![Trial spm penang_2013_maths_paper1_paper2_[q]](https://cdn.slidesharecdn.com/ss_thumbnails/trial-spm-penang-2013-maths-paper1-paper2-5bq-5d-131008111844-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














































