Download as PDF, PPTX


































![HPCAC-Switzerland (Mar ‘16) 55 Network Based CompuNng Laboratory
List of Supported Switch Counters
• The following counters are queried from the InfiniBand Switches
• Xmit Data
– Total number of data octets, divided by 4, transmi<ed on all VLs from the port
– This includes all octets between (and not including) the start of packet delimiter and the VCRC, and
may include packets containing errors
– Excludes all link packets.
• Rcv Data
– Total number of data octets, divided by 4, received on all VLs from the port
– This includes all octets between (and not including) the start of packet delimiter and the VCRC, and
may include packets containing errors
– Excludes all link packets.
• Max [Xmit Data/Rcv Data]: Maximum of the two values above](https://image.slidesharecdn.com/programmingmodelsforexascale-160322080901/85/Programming-Models-for-Exascale-Systems-55-320.jpg)
![HPCAC-Switzerland (Mar ‘16) 56 Network Based CompuNng Laboratory
List of Supported MPI Process Level Counters
• MVAPICH2-X collects addiRonal informaRon about the process’s network usage which can be displayed by OSU
INAM
• Xmit Data
– Total number of bytes transmi<ed as part of the MPI applicaRon
• Rcv Data
– Total number of bytes received as part of the MPI applicaRon
• Max [Xmit Data/Rcv Data]
– Maximum of the two values above
• Point to Point Send
– Total number of bytes transmi<ed as part of MPI point-to-point operaRons
• Point to Point Rcvd
– Total number of bytes received as part of MPI point-to-point operaRons
• Max [Point to Point Sent/Rcvd]
– Maximum of the two values above
• Coll Bytes Sent
– Total number of bytes transmi<ed as part of MPI collecRve operaRons
• Coll Bytes Rcvd
– Total number of bytes received as part of MPI collecRve operaRons](https://image.slidesharecdn.com/programmingmodelsforexascale-160322080901/85/Programming-Models-for-Exascale-Systems-56-320.jpg)
![HPCAC-Switzerland (Mar ‘16) 57 Network Based CompuNng Laboratory
List of Supported MPI Process Level Counters (Cont.)
• Max [Coll Bytes Sent/Rcvd]
– Maximum of the two values above
• RMA Bytes Sent
– Total number of bytes transmi<ed as part of MPI RMA operaRons
– Note that due to the nature of the RMA operaRons, bytes received for RMA operaRons cannot be counted
• RC VBUF
– The number of internal communicaRon buffers used for reliable connecRon (RC)
• UD VBUF
– The number of internal communicaRon buffers used for unreliable datagram (UD)
• VM Size
– Total number of bytes used by the program for its virtual memory
• VM Peak
– Maximum number of virtual memory bytes for the program
• VM RSS
– The number of bytes resident in the memory (Resident set size)
• VM HWM
– The maximum number of bytes that can be resident in memory (Peak resident set size or High water mark)](https://image.slidesharecdn.com/programmingmodelsforexascale-160322080901/85/Programming-Models-for-Exascale-Systems-57-320.jpg)






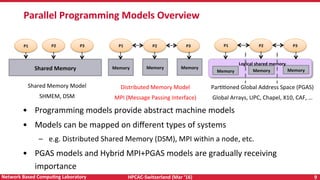
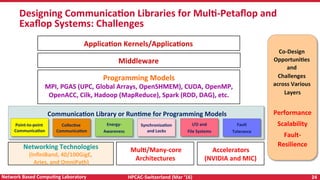
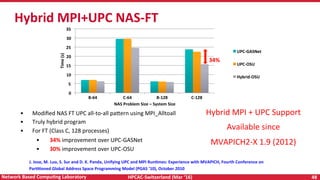
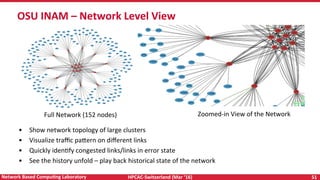
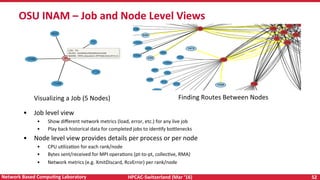
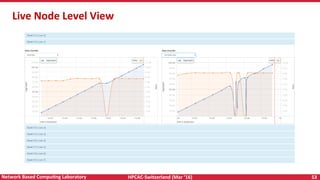
The document discusses high-performance computing (HPC) and programming models for exascale systems, focusing on advancements and challenges in machine design, architecture, and energy efficiency. It highlights the importance of the Message Passing Interface (MPI) and various parallel programming models, such as PGAS and hybrid approaches, while addressing the critical challenges faced in achieving exascale performance, including power, memory, resiliency, and concurrency. The content emphasizes the necessity for scalable communication libraries and efficient interconnects for future exascale systems.






















































































