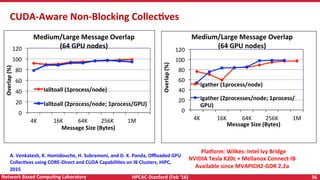
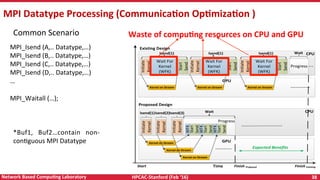
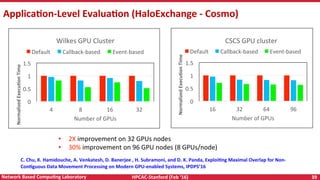
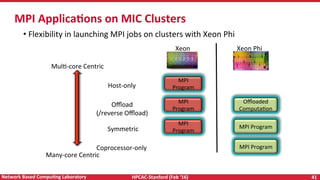
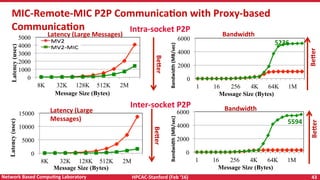
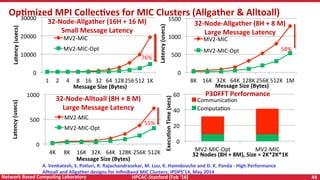
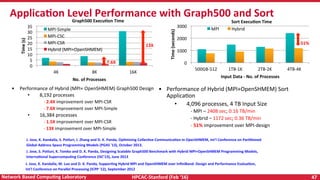
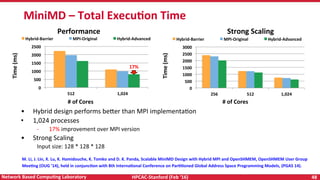
Downloaded 21 times



































![HPCAC-Stanford (Feb ‘16) 58 Network Based CompuNng Laboratory
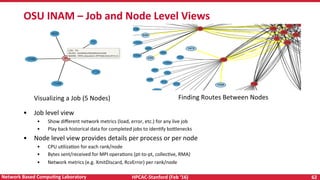
• An energy efficient runRme that
provides energy savings without
applicaRon knowledge
• Uses automaRcally and
transparently the best energy
lever
• Provides guarantees on
maximum degradaRon with
5-41% savings at <= 5%
degradaRon
• PessimisRc MPI applies energy
reducRon lever to each MPI call
MVAPICH2-EA: ApplicaNon Oblivious Energy-Aware-MPI (EAM)
A Case for ApplicaNon-Oblivious Energy-Efficient MPI RunNme A. Venkatesh, A. Vishnu, K. Hamidouche, N. Tallent, D.
K. Panda, D. Kerbyson, and A. Hoise, SupercompuNng ‘15, Nov 2015 [Best Student Paper Finalist]
1](https://image.slidesharecdn.com/exascaleprogrammingmodels-160225171932/85/Programming-Models-for-Exascale-Systems-58-320.jpg)









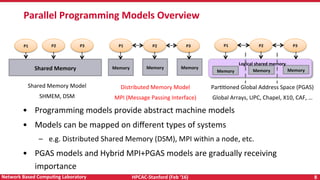
The document discusses programming models for exascale systems, highlighting the difference in architecture, performance, and scaling from current supercomputers to anticipated exascale systems. It outlines various programming approaches including MPI, PGAS, and hybrid models, as well as the challenges of designing communication libraries for high-performance computing. Additionally, it emphasizes the importance of scalability, fault tolerance, and energy efficiency in future computing architectures.


































































