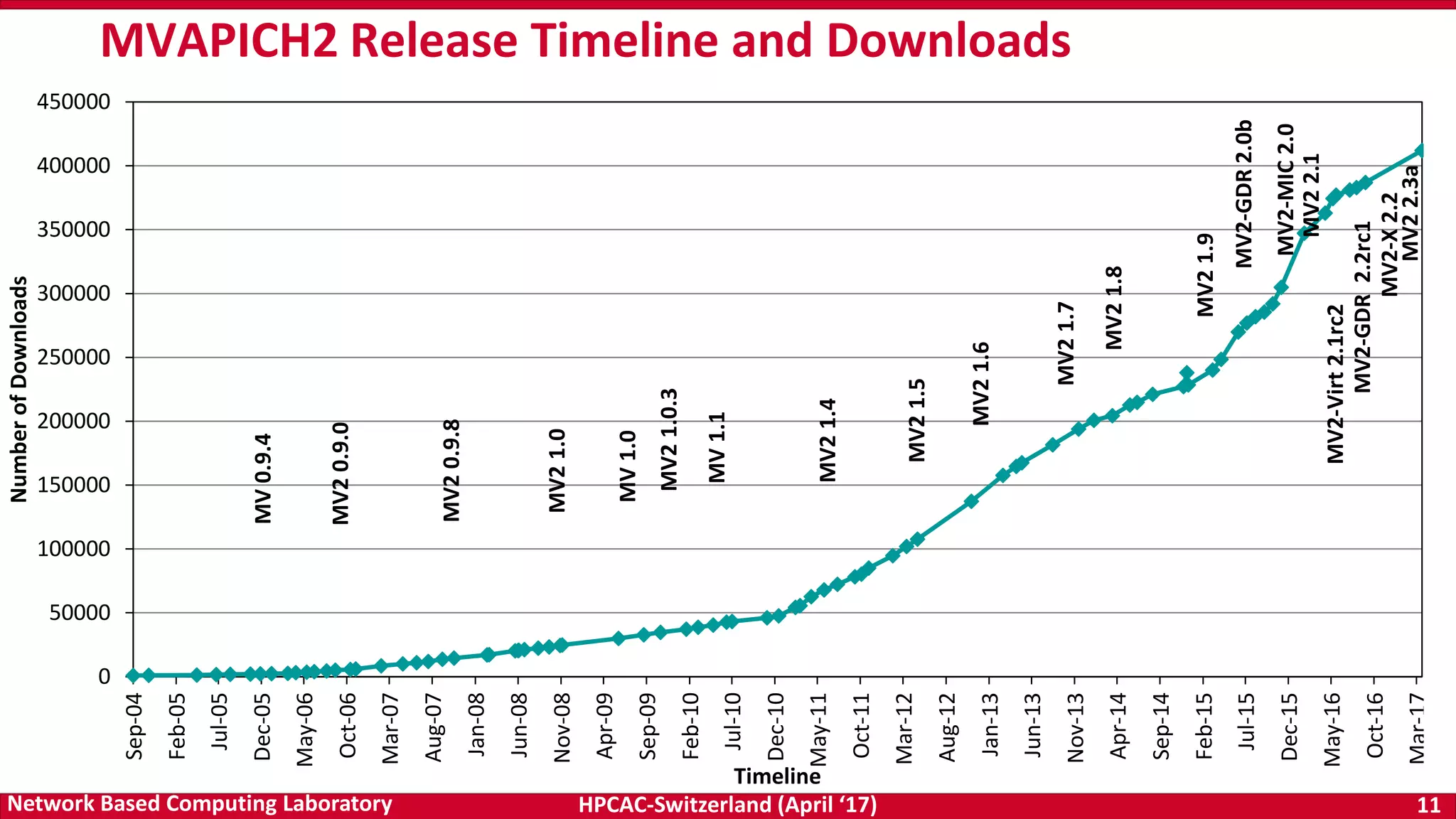
Downloaded 66 times






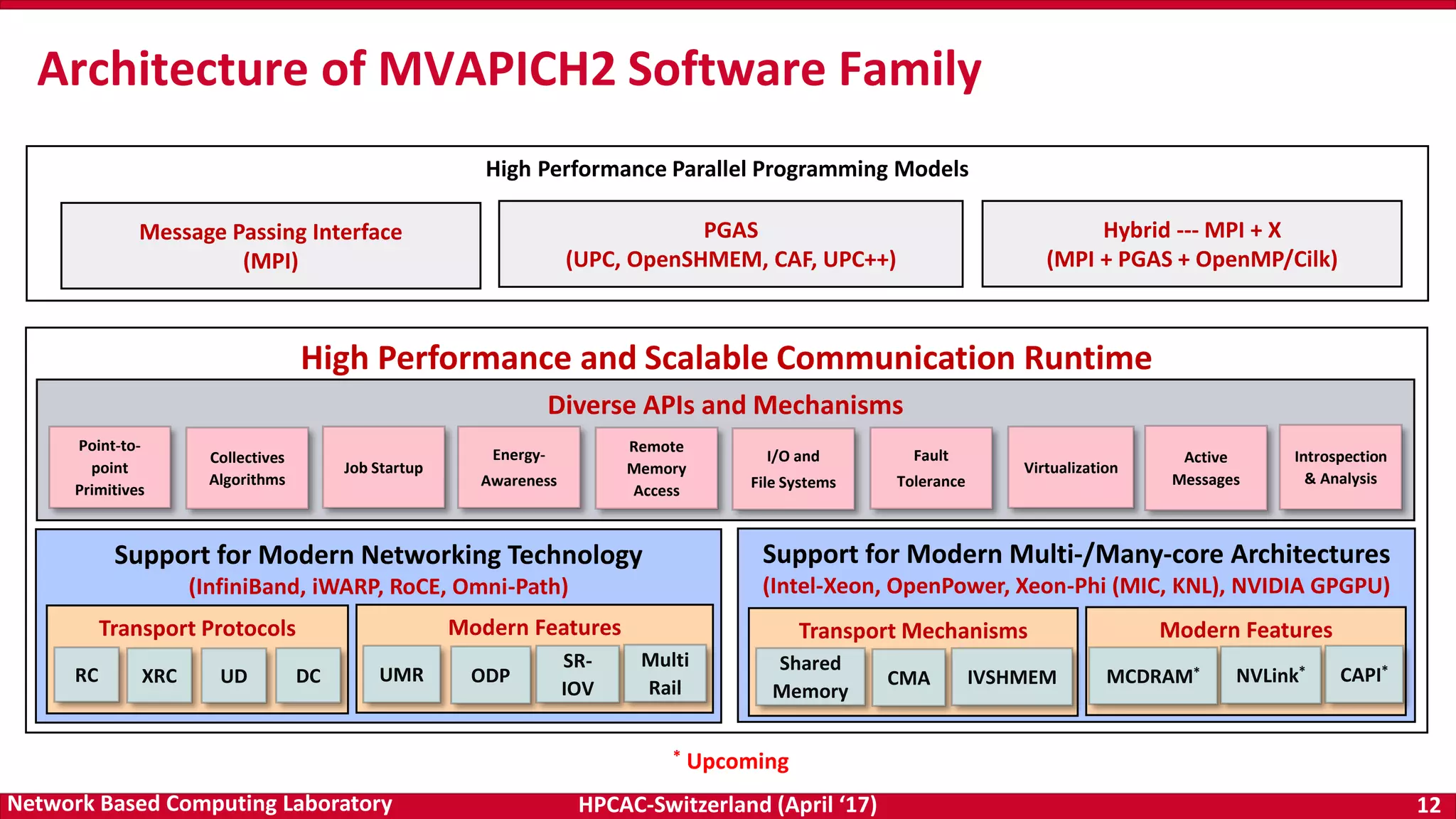
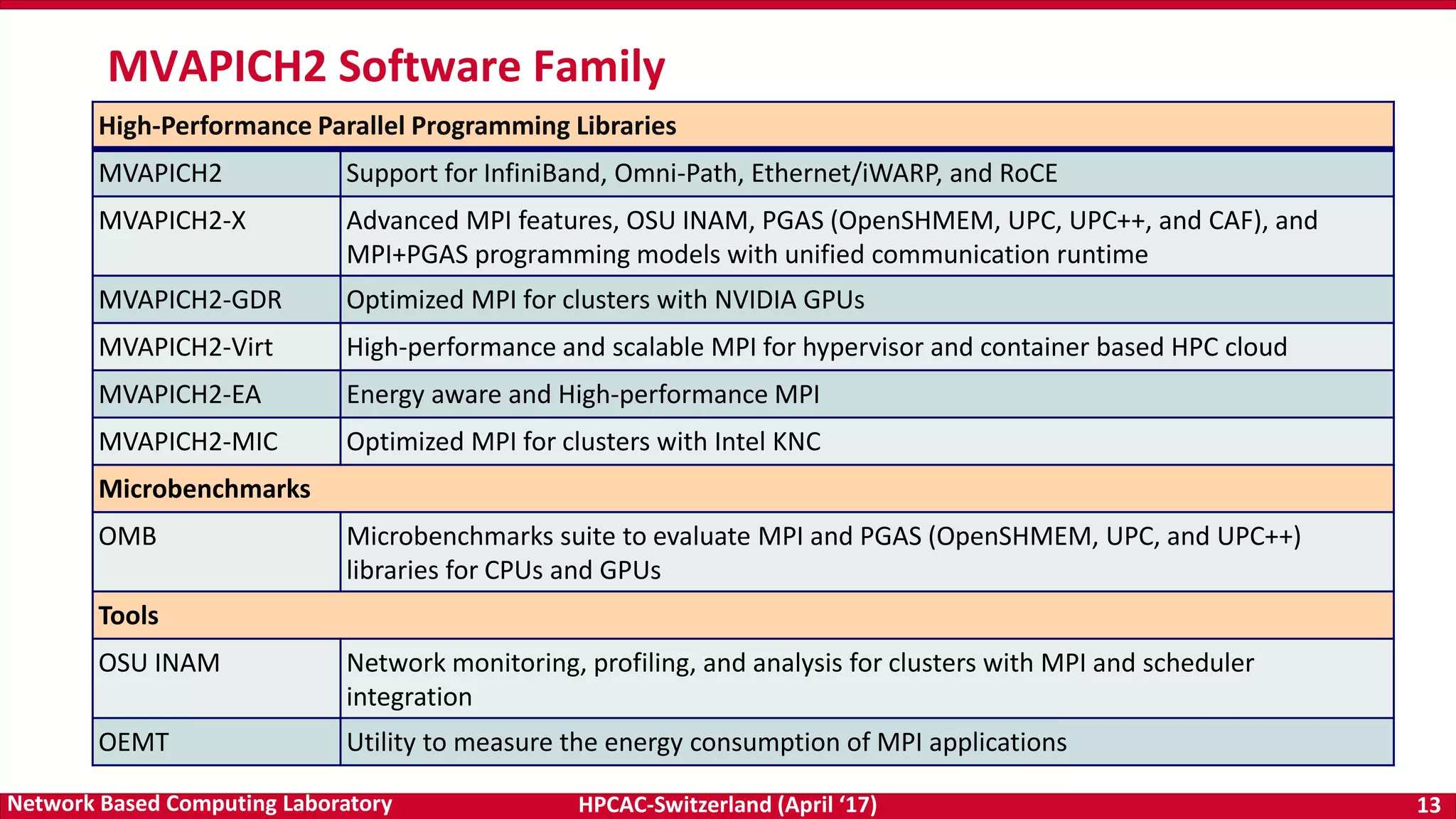


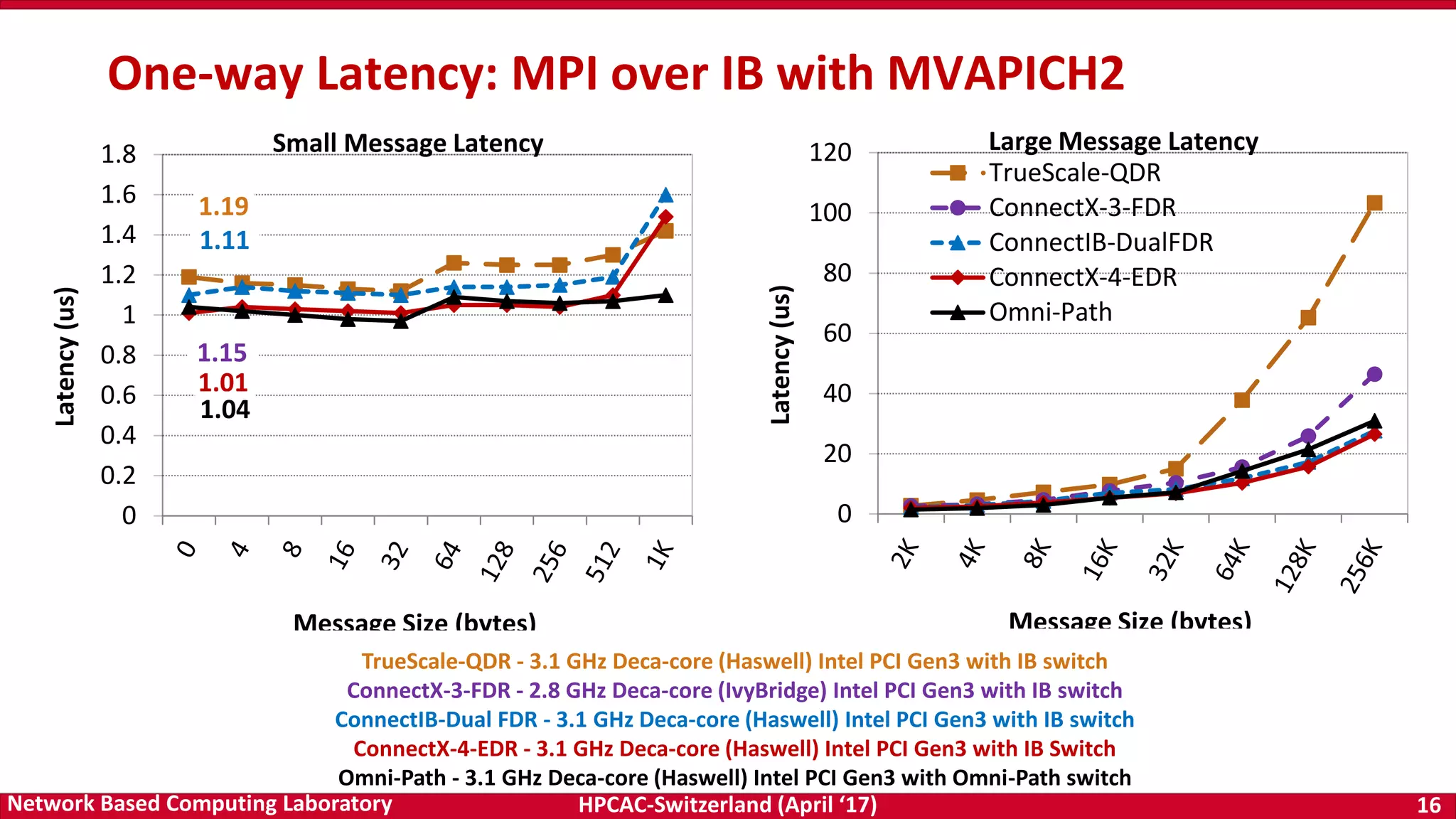
![HPCAC-Switzerland (April ‘17) 23Network Based Computing Laboratory
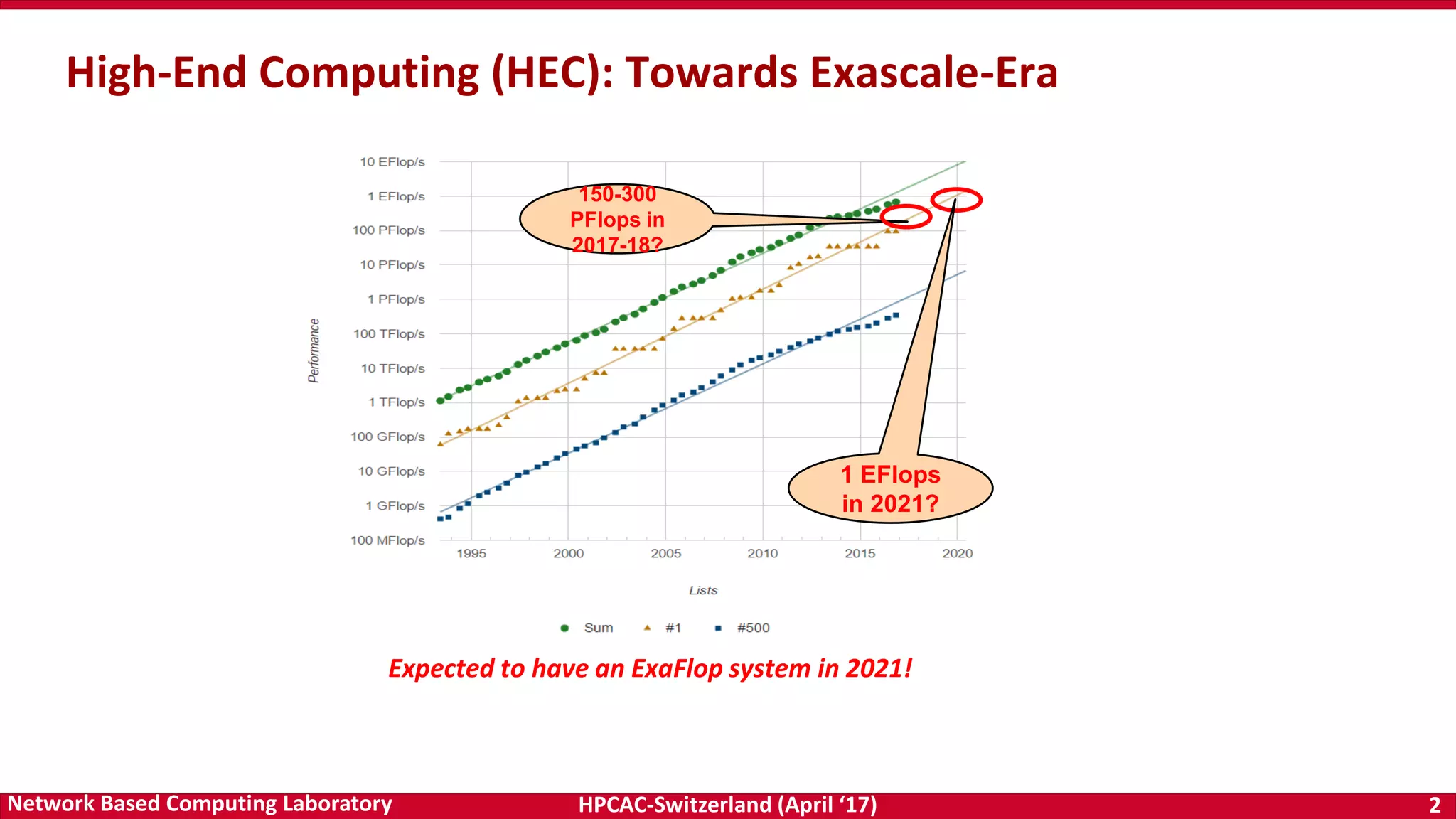
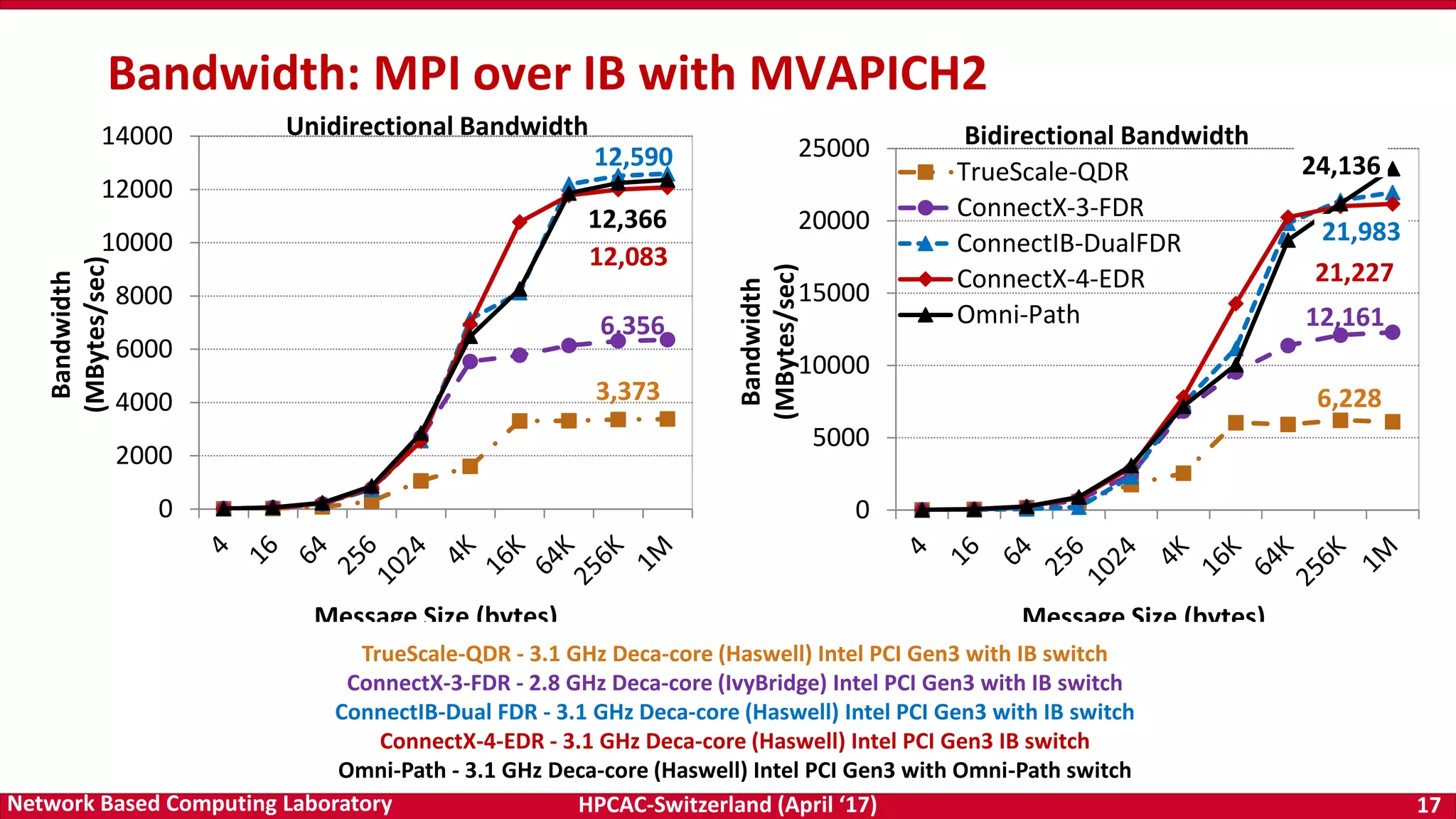
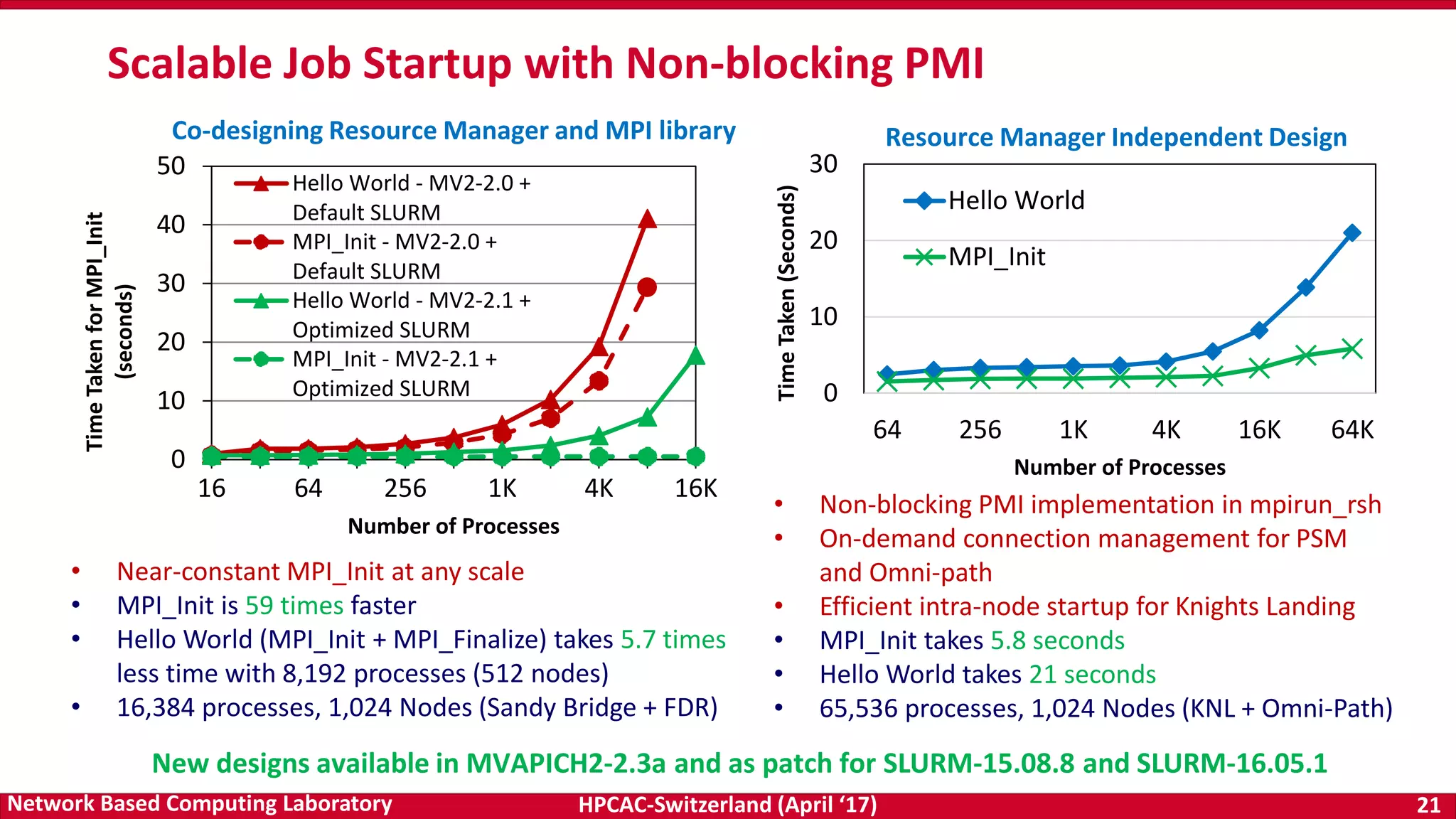
Dynamic and Adaptive Tag Matching
Normalized Total Tag Matching Time at 512 Processes
Normalized to Default (Lower is Better)
Normalized Memory Overhead per Process at 512 Processes
Compared to Default (Lower is Better)
Adaptive and Dynamic Design for MPI Tag Matching; M. Bayatpour, H. Subramoni, S. Chakraborty, and D. K. Panda; IEEE Cluster 2016. [Best Paper Nominee]
Challenge
Tag matching is a significant
overhead for receivers
Existing Solutions are
- Static and do not adapt
dynamically to
communication pattern
- Do not consider memory
overhead
Solution
A new tag matching design
- Dynamically adapt to
communication patterns
- Use different strategies for
different ranks
- Decisions are based on the
number of request object
that must be traversed
before hitting on the
required one
Results
Better performance than
other state-of-the art tag-
matching schemes
Minimum memory
consumption
Will be available in future
MVAPICH2 releases](https://image.slidesharecdn.com/dkpanda-170411093456/75/High-Performance-and-Scalable-Designs-of-Programming-Models-for-Exascale-Systems-23-2048.jpg)



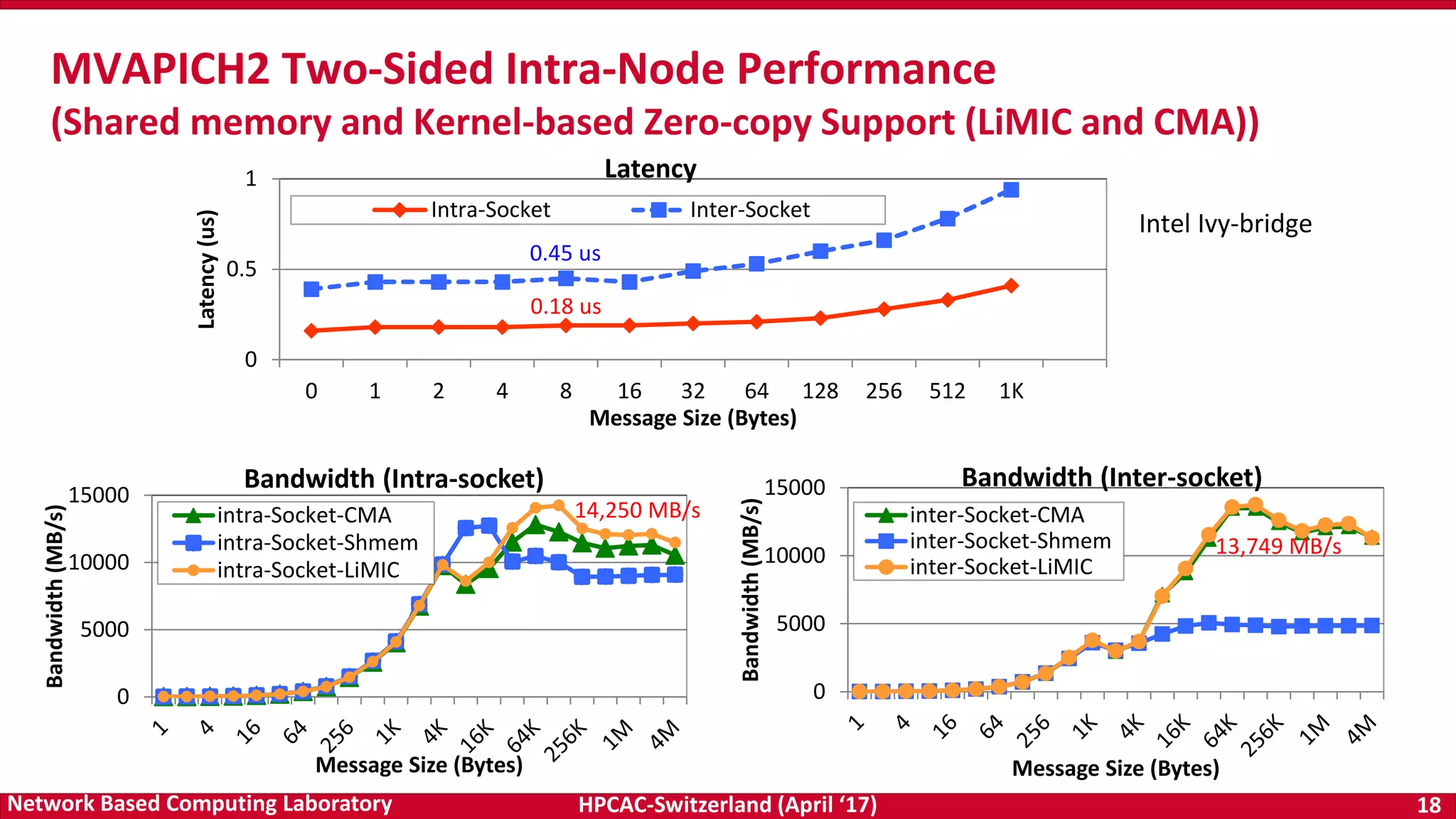
![HPCAC-Switzerland (April ‘17) 36Network Based Computing Laboratory
0
1000
2000
3000
4000
5000
6000
1
4
16
64
256
1K
4K
16K
64K
256K
1M
4M
Bandwidth(MB/s)
GDR=1 GDRCOPY=0
GDR=1 GDRCOPY=1
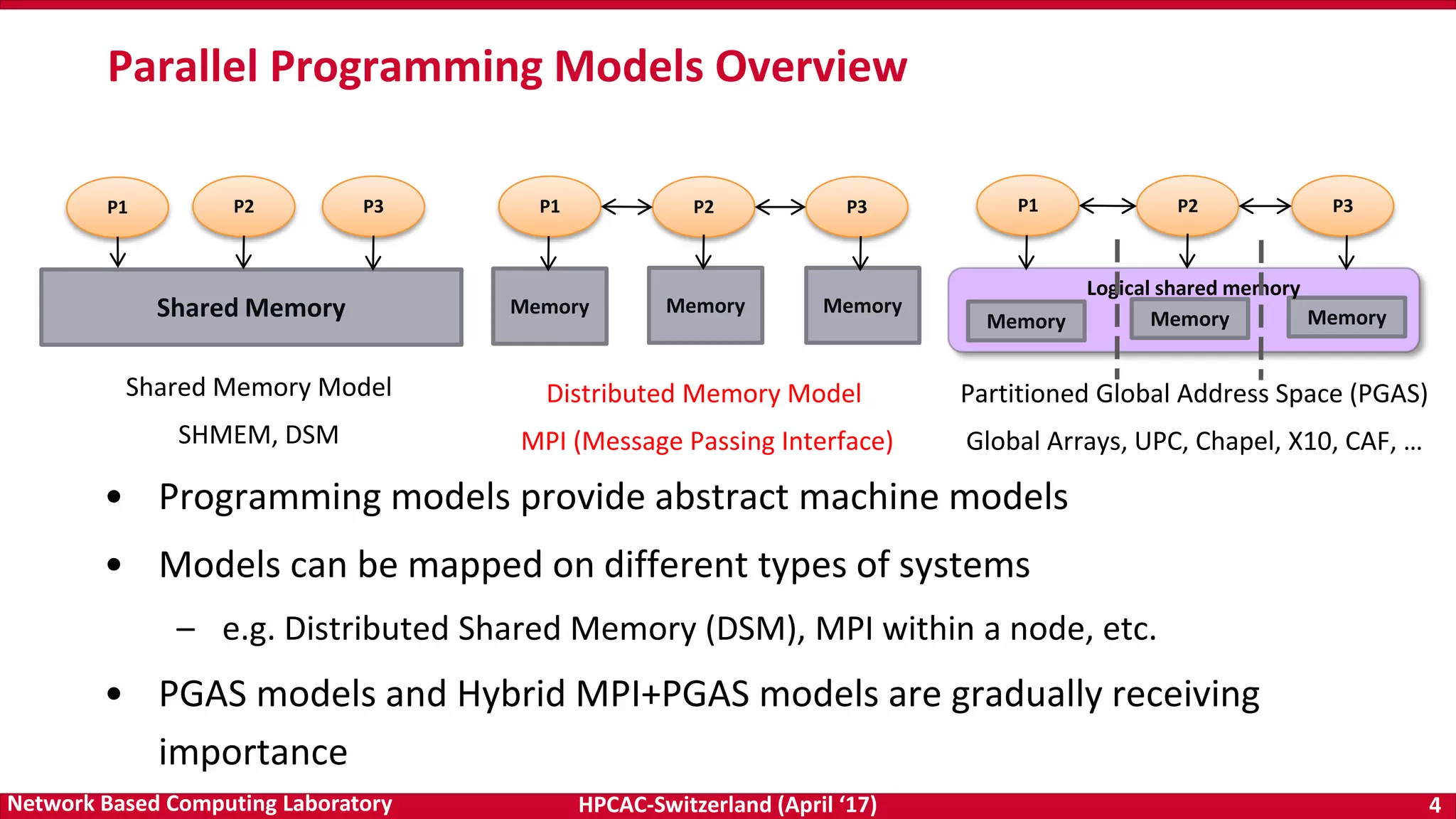
MVAPICH2-GDR on OpenPower (Preliminary Evaluation)
0
10
20
30
40
1
2
4
8
16
32
64
128
256
512
1K
2K
4K
8K
Latency(us)
GDR=1 GDRCOPY=0
GDR=1 GDRCOPY=1
osu_latency [D-D]
osu_bw [H-D]
0
5
10
15
20
1 4 16 64 256 1K 4K 16K 64K
Latency(us)
GDR=1 GDRCOPY=0
GDR=1 GDRCOPY=1
osu_latency [H-D]
POWER8NVL-ppc64le @ 4.023GHz
MVAPICH2-GDR2.2, MV2_USE_GPUDIRECT_GDRCOPY_LIMIT=32768
Intra-node Numbers (Basic Configuration)](https://image.slidesharecdn.com/dkpanda-170411093456/75/High-Performance-and-Scalable-Designs-of-Programming-Models-for-Exascale-Systems-36-2048.jpg)






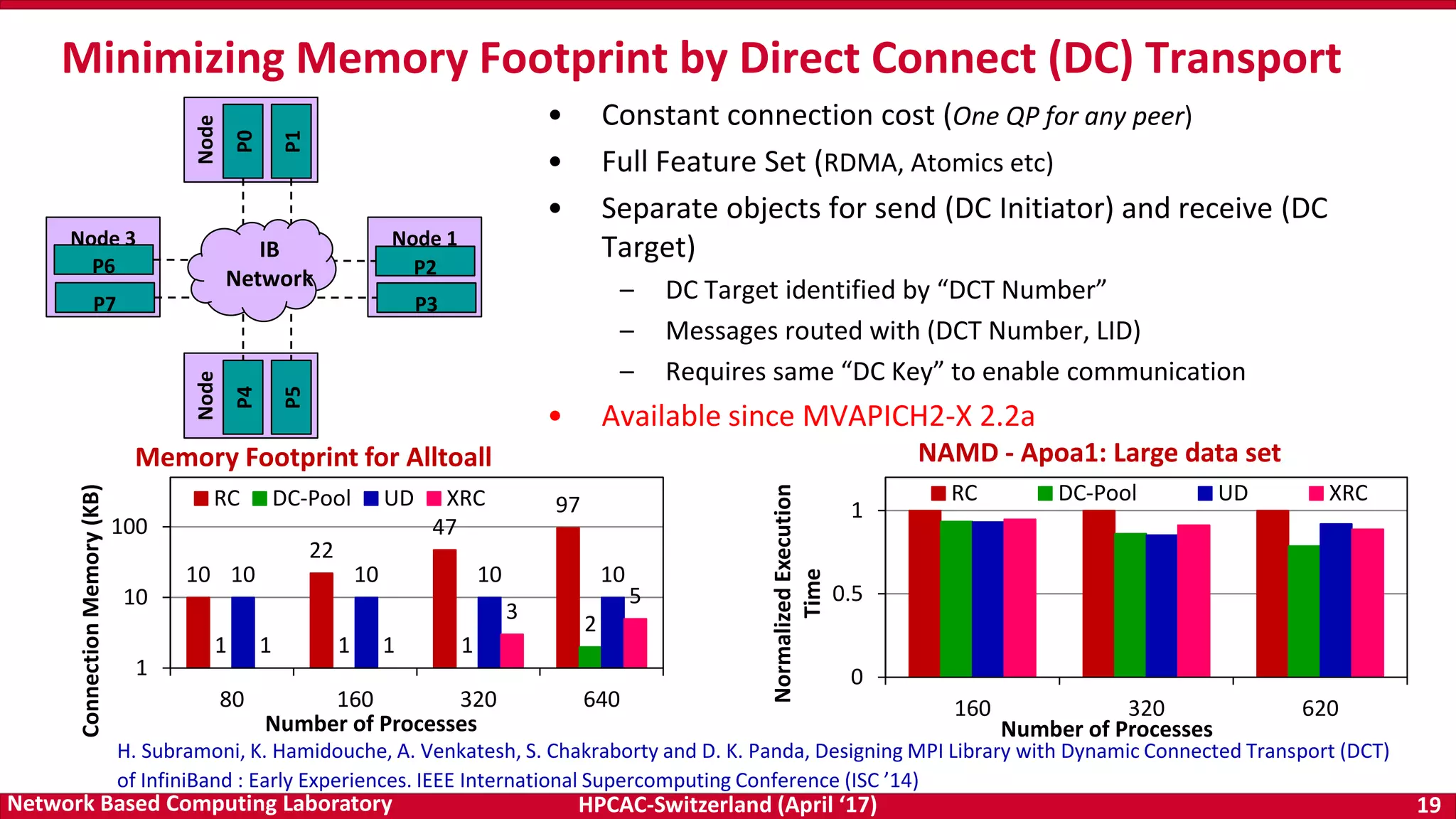
![HPCAC-Switzerland (April ‘17) 51Network Based Computing Laboratory
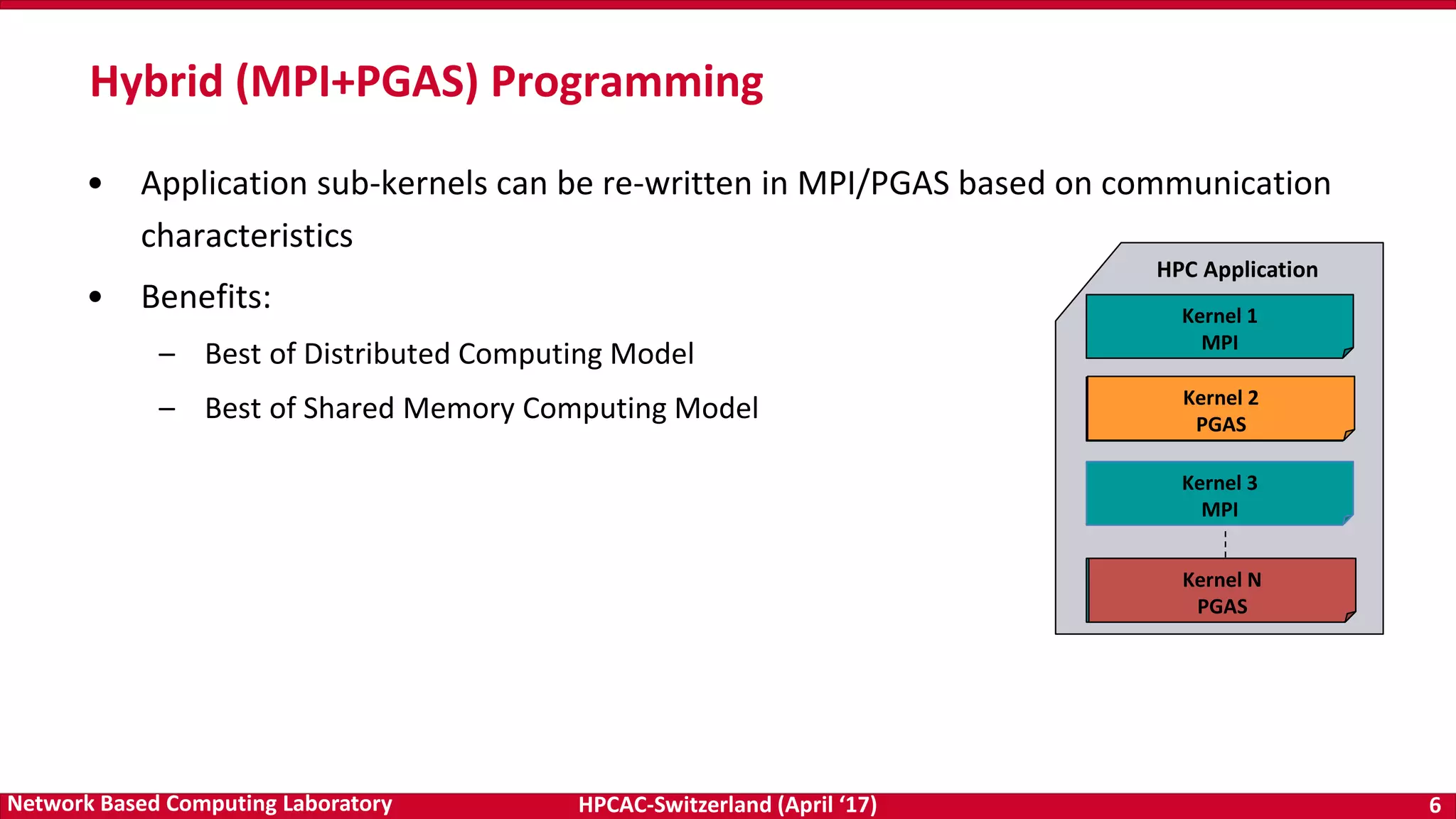
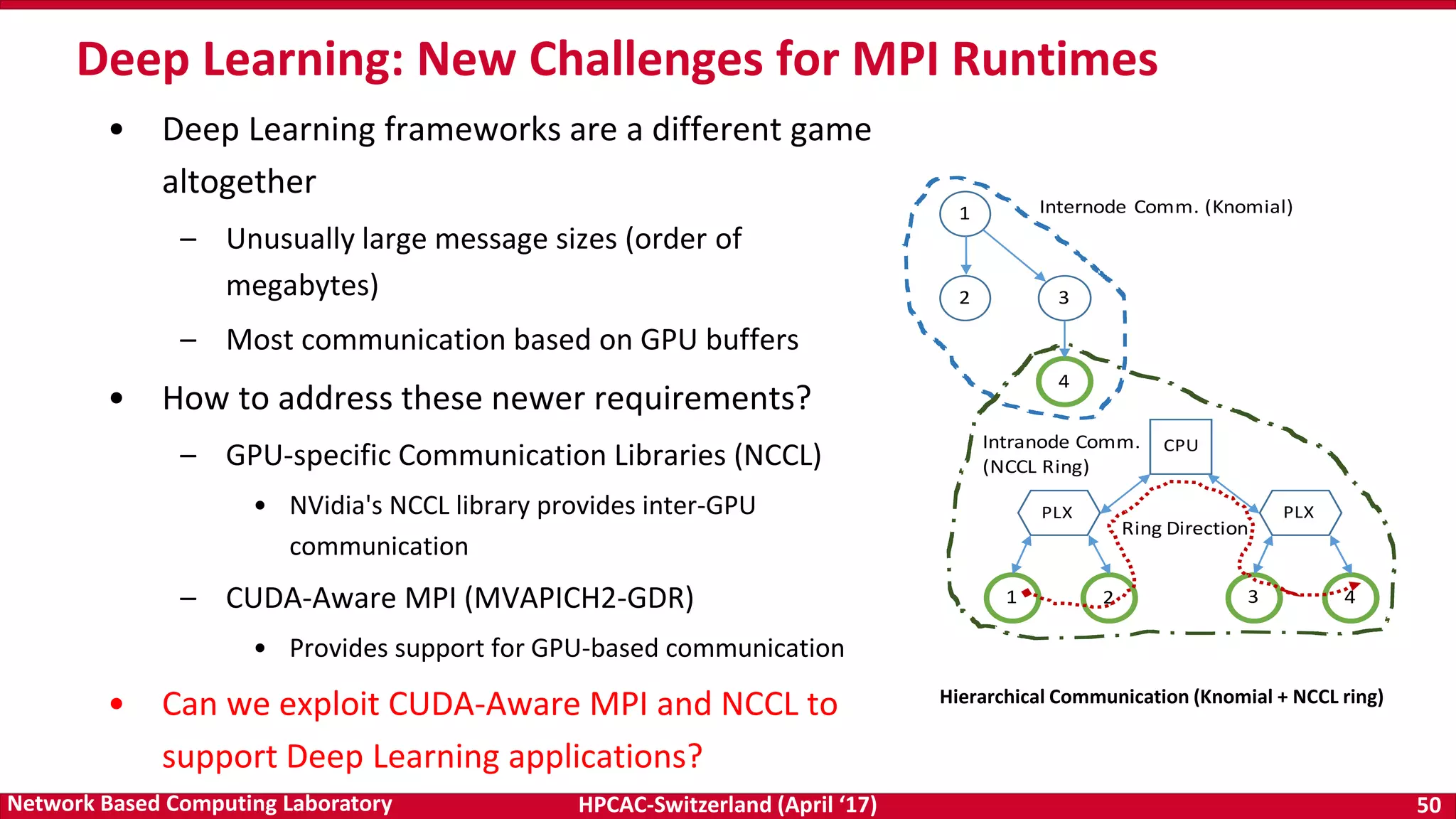
• NCCL has some limitations
– Only works for a single node, thus, no scale-out on
multiple nodes
– Degradation across IOH (socket) for scale-up (within a
node)
• We propose optimized MPI_Bcast
– Communication of very large GPU buffers (order of
megabytes)
– Scale-out on large number of dense multi-GPU nodes
• Hierarchical Communication that efficiently exploits:
– CUDA-Aware MPI_Bcast in MV2-GDR
– NCCL Broadcast primitive
Efficient Broadcast: MVAPICH2-GDR and NCCL
1
10
100
1000
10000
100000
1
8
64
512
4K
32K
256K
2M
16M
128M
Latency(us)
LogScale
Message Size
MV2-GDR MV2-GDR-Opt
100x
0
10
20
30
2 4 8 16 32 64
Time(seconds)
Number of GPUs
MV2-GDR MV2-GDR-Opt
Performance Benefits: Microsoft CNTK DL framework
(25% avg. improvement )
Performance Benefits: OSU Micro-benchmarks
Efficient Large Message Broadcast using NCCL and CUDA-Aware MPI for Deep Learning,
A. Awan , K. Hamidouche , A. Venkatesh , and D. K. Panda,
The 23rd European MPI Users' Group Meeting (EuroMPI 16), Sep 2016 [Best Paper Runner-Up]](https://image.slidesharecdn.com/dkpanda-170411093456/75/High-Performance-and-Scalable-Designs-of-Programming-Models-for-Exascale-Systems-51-2048.jpg)







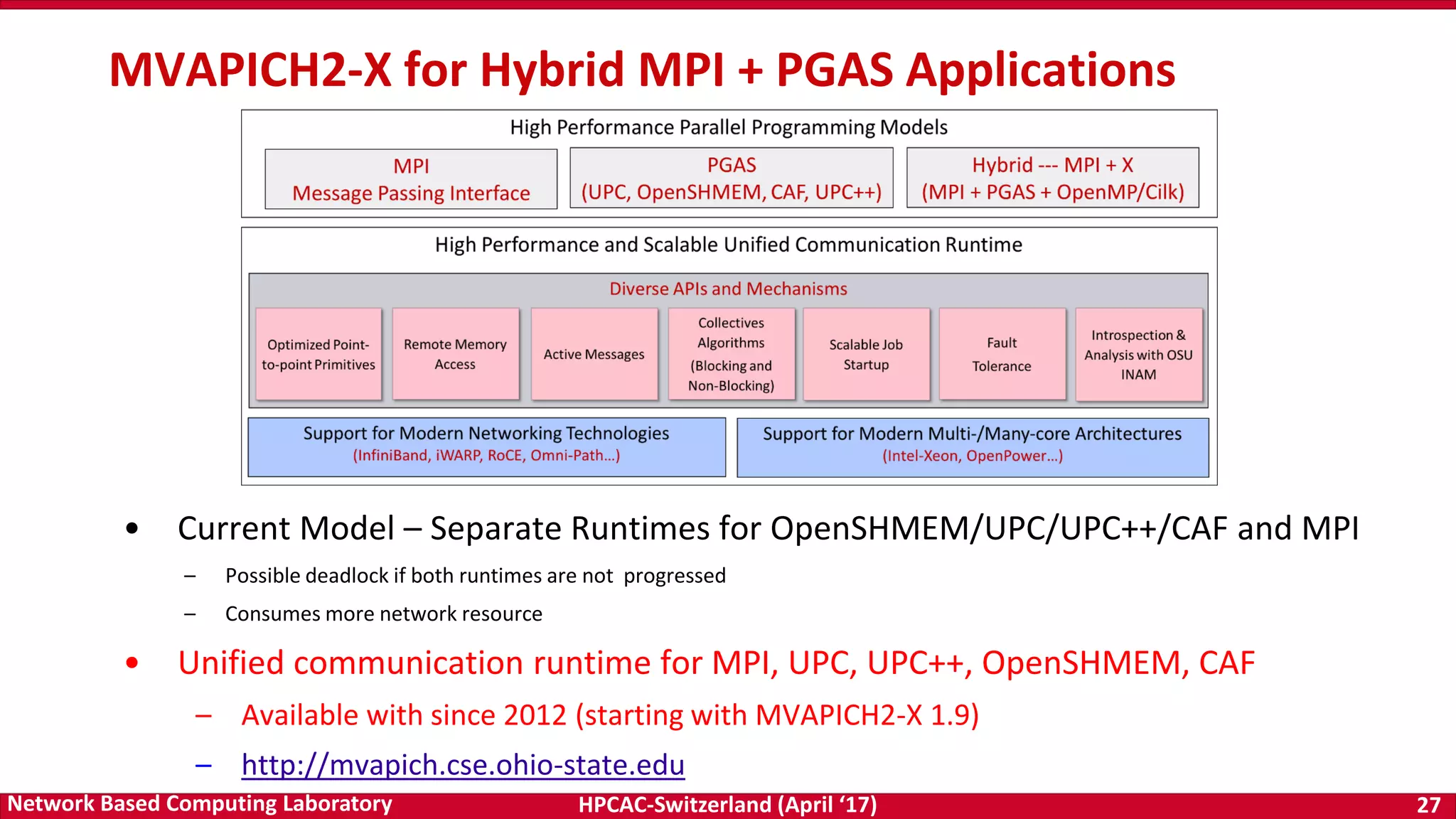
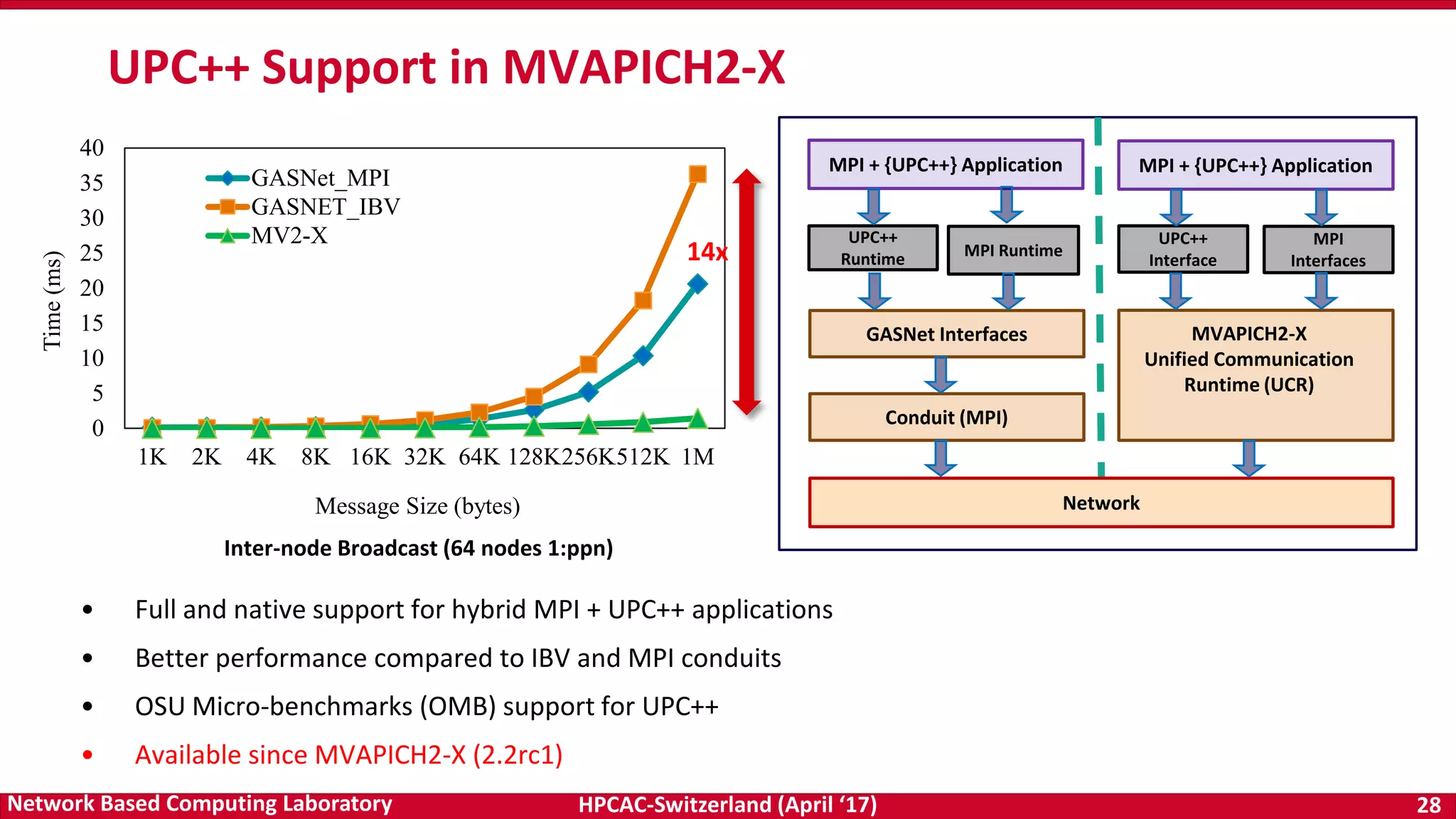
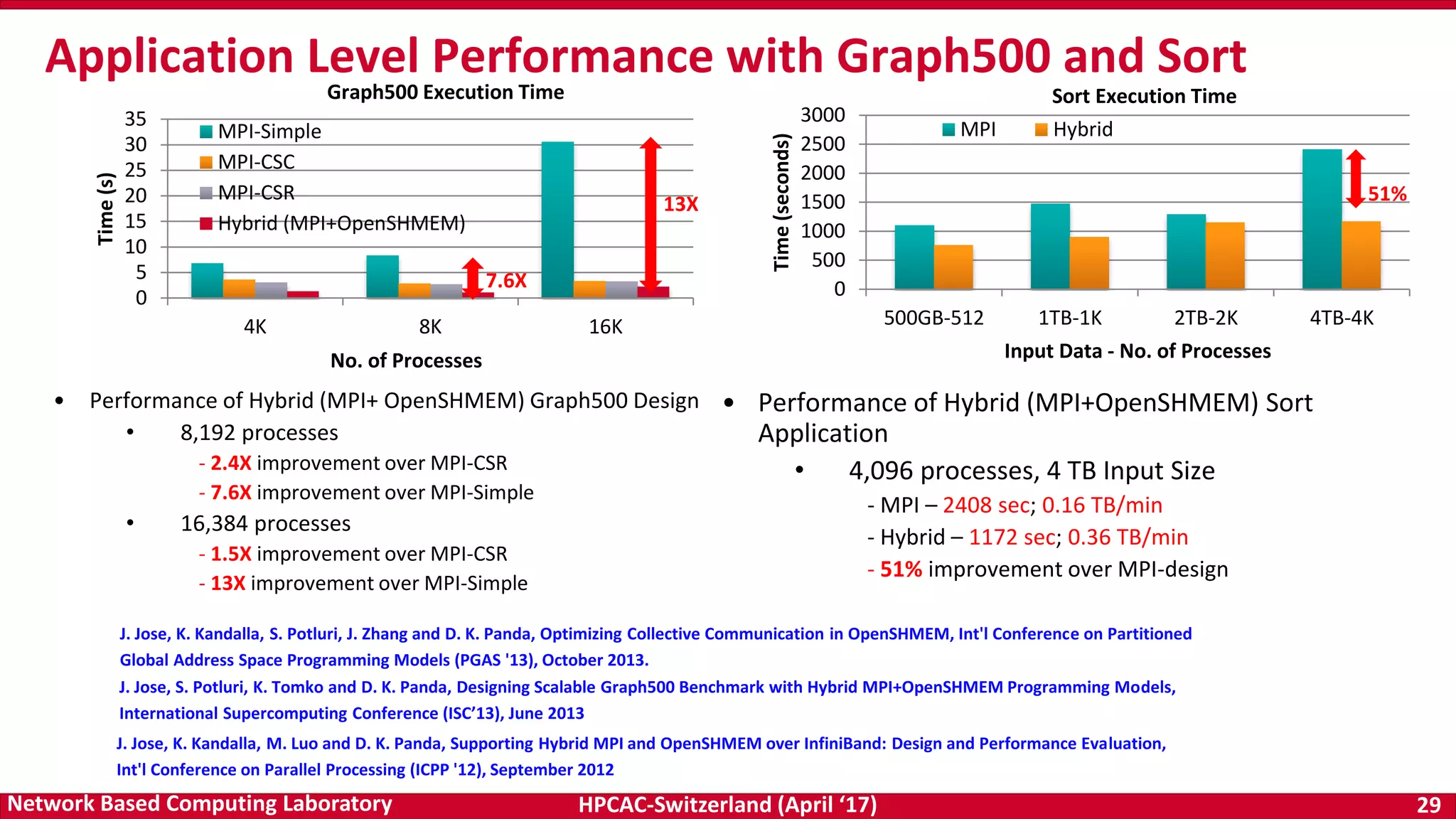
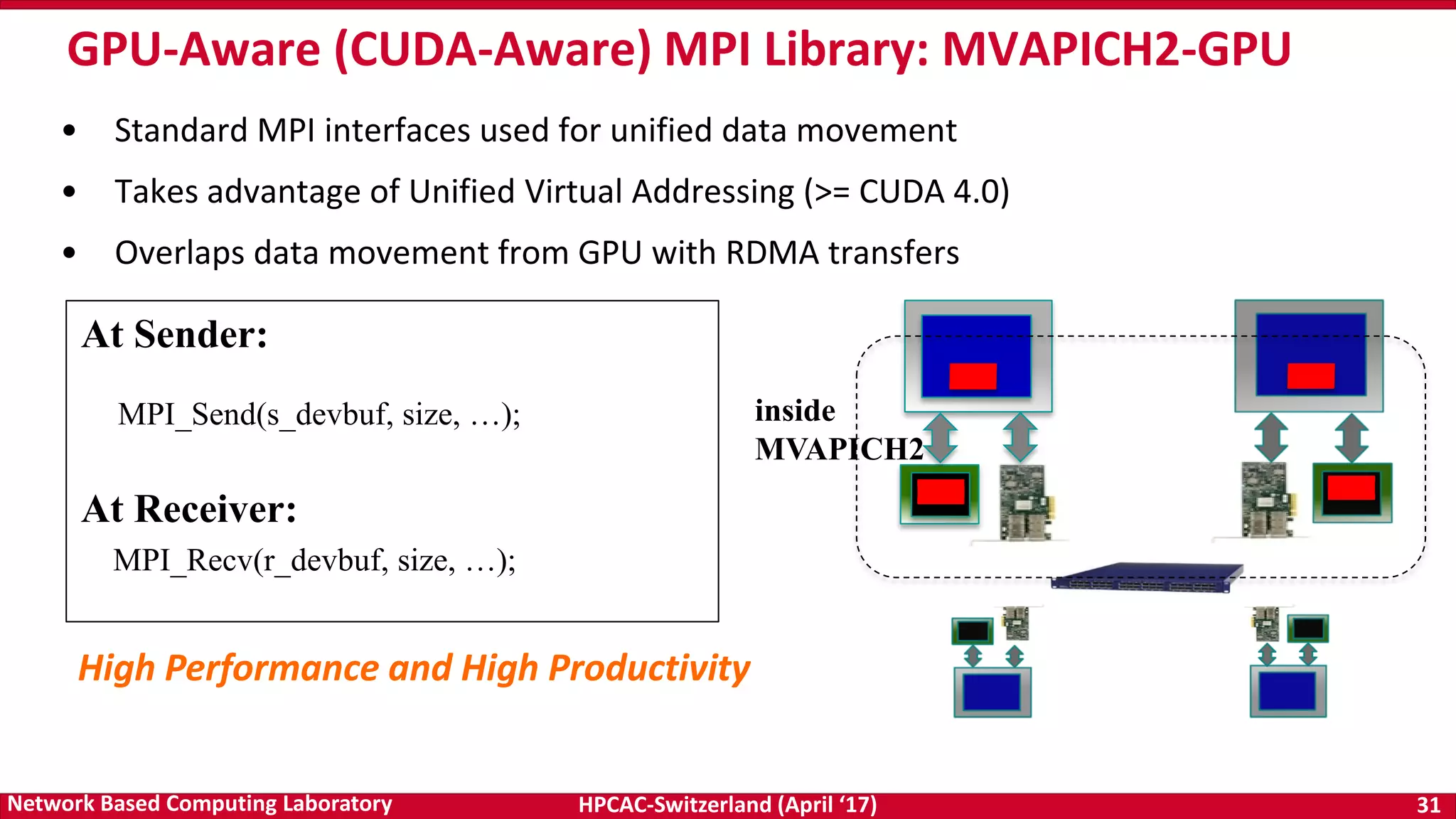
- The document discusses programming models and challenges for exascale systems. It focuses on MPI and PGAS models like OpenSHMEM. - Key challenges include supporting hybrid MPI+PGAS programming, efficient communication for multi-core and accelerator nodes, fault tolerance, and extreme low memory usage. - The MVAPICH2 project aims to address these challenges through its high performance MPI and PGAS implementation and optimization of communication for technologies like InfiniBand.



































![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















































