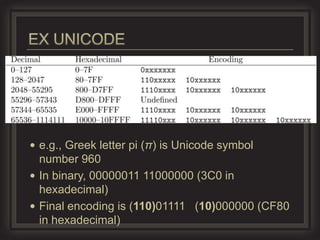
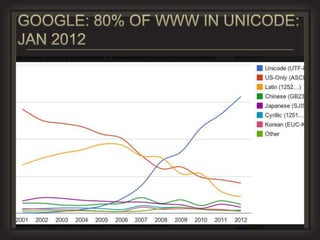
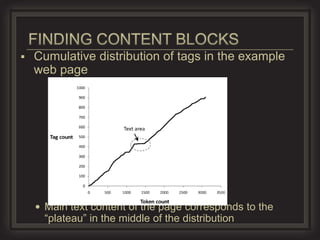
This document provides an overview of key concepts in information retrieval. It discusses issues with crawlers getting stuck in loops and storage issues. It also covers the basics of indexing documents, including creating an inverted index to speed up retrieval. Common techniques for detecting duplicate and near-duplicate documents are also summarized.







































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















