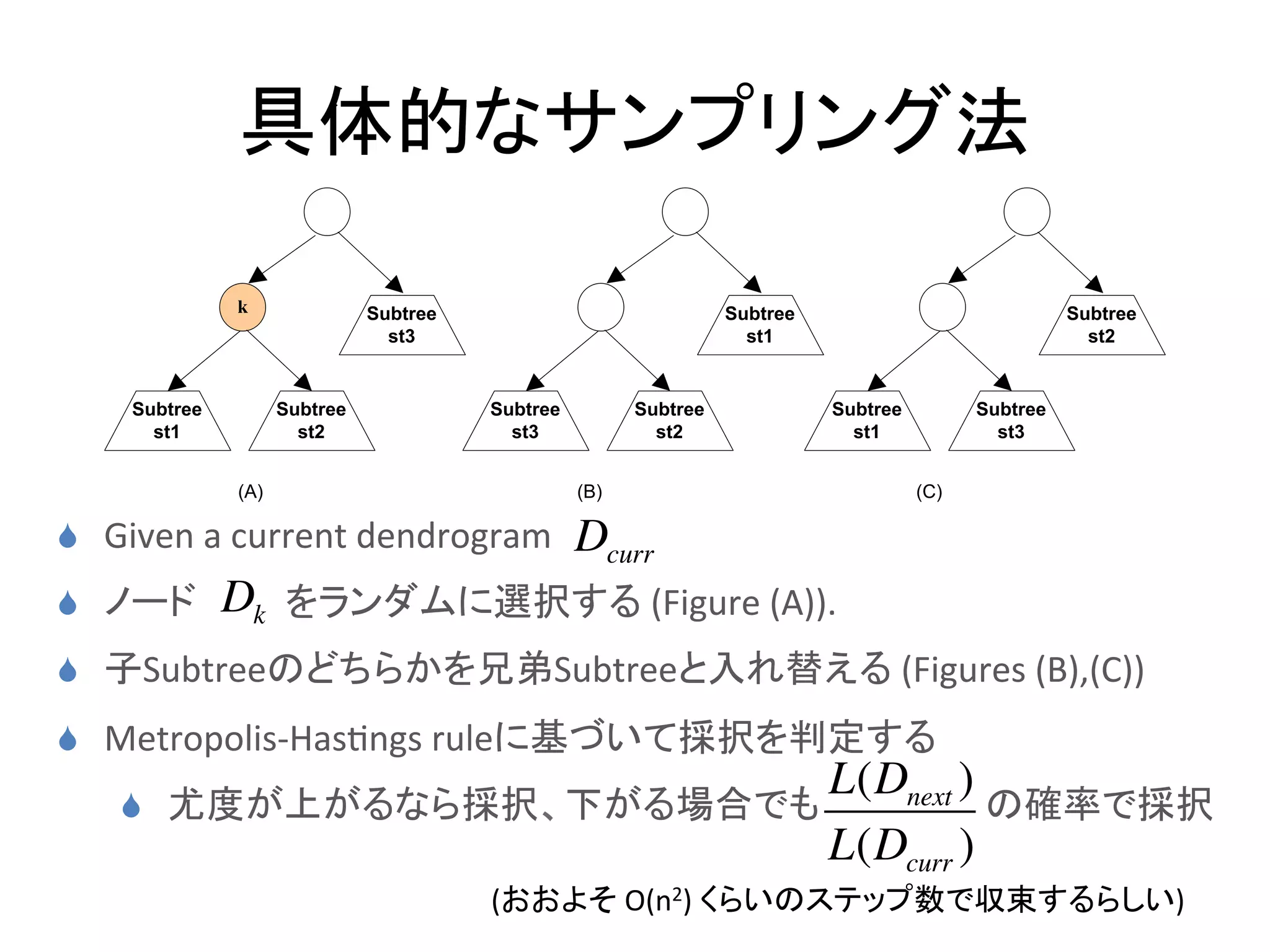
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010)
1.
Word
Sense
Induc-on
&
Disambigua-on
Using
Hierarchical
Random
Graphs
Ioannis
Klapa=is
&
Suresh
Manandhar
EMNLP
2010
発表者
:
M2
松田
2.
Abstract
• Unsupervised
WSD
– Known
as
Word
Sense
Induc-on(WSI)
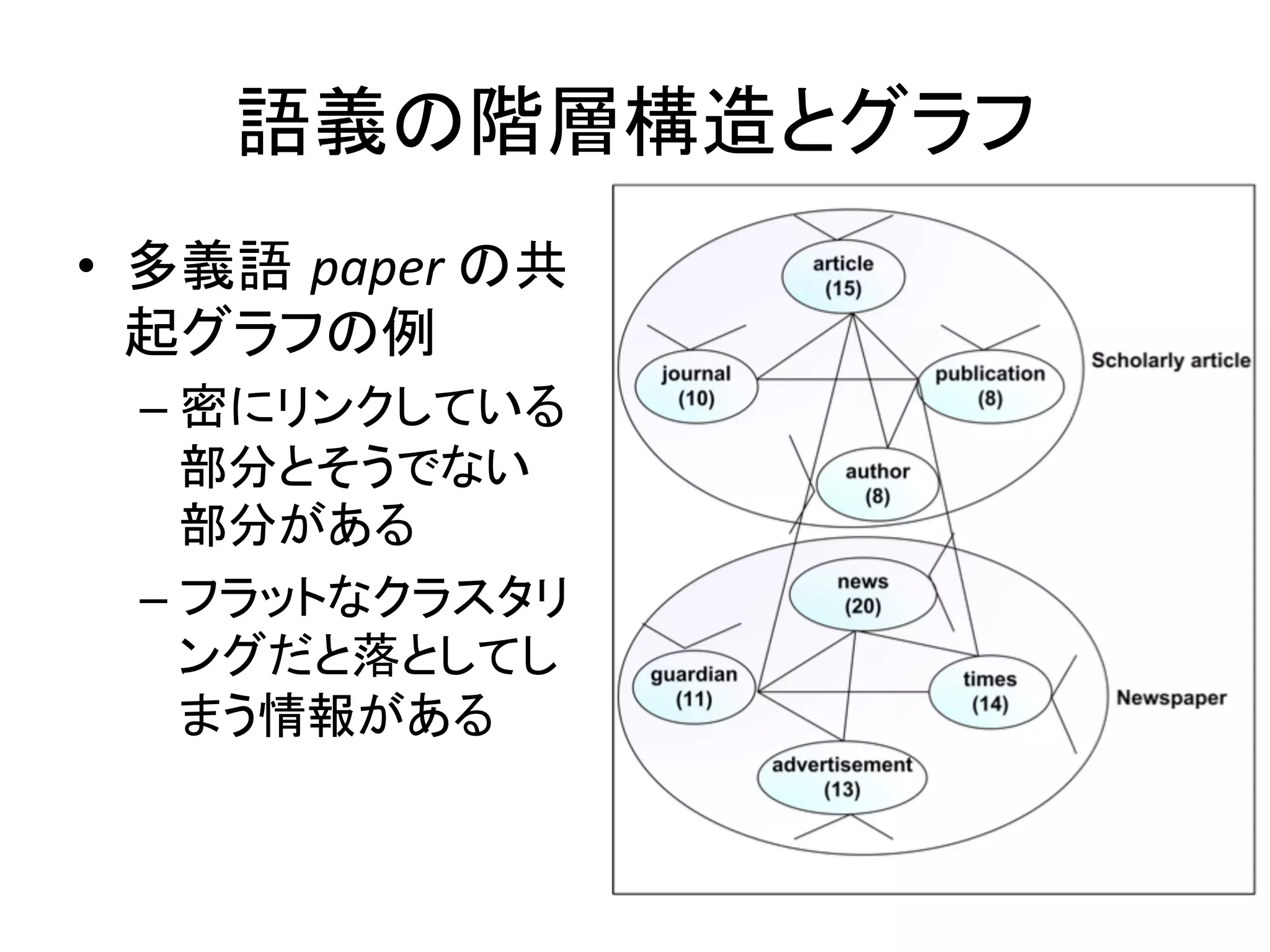
– クラスタリングに基づくWSD
• 本研究ではグラフをベースにしている
– 多くのWSIではグラフのノードをフラットにクラスタ
リングする
– 対して、本研究ではグラフに存在している階層構
造を用いることで性能を上げようと試みている
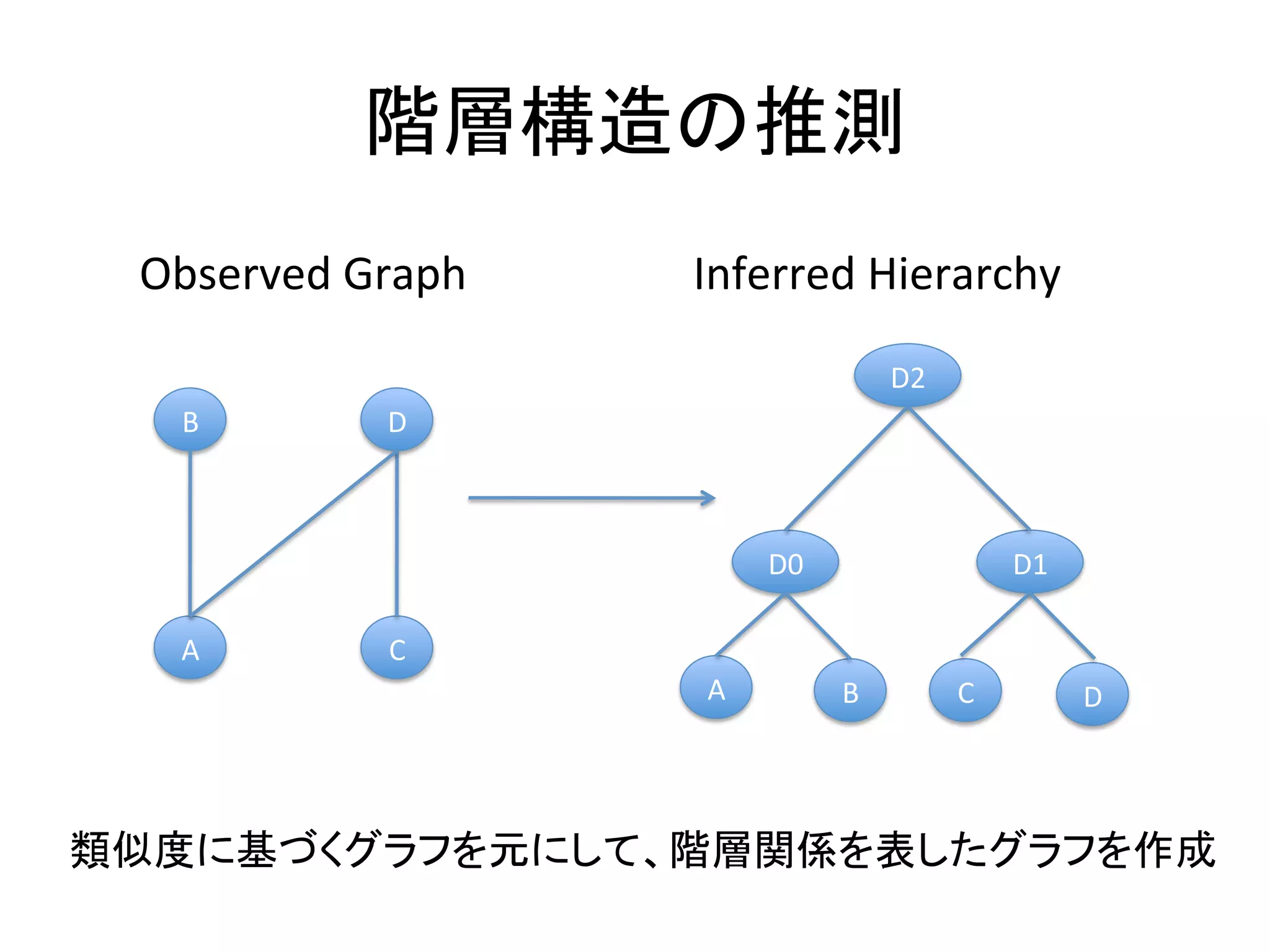
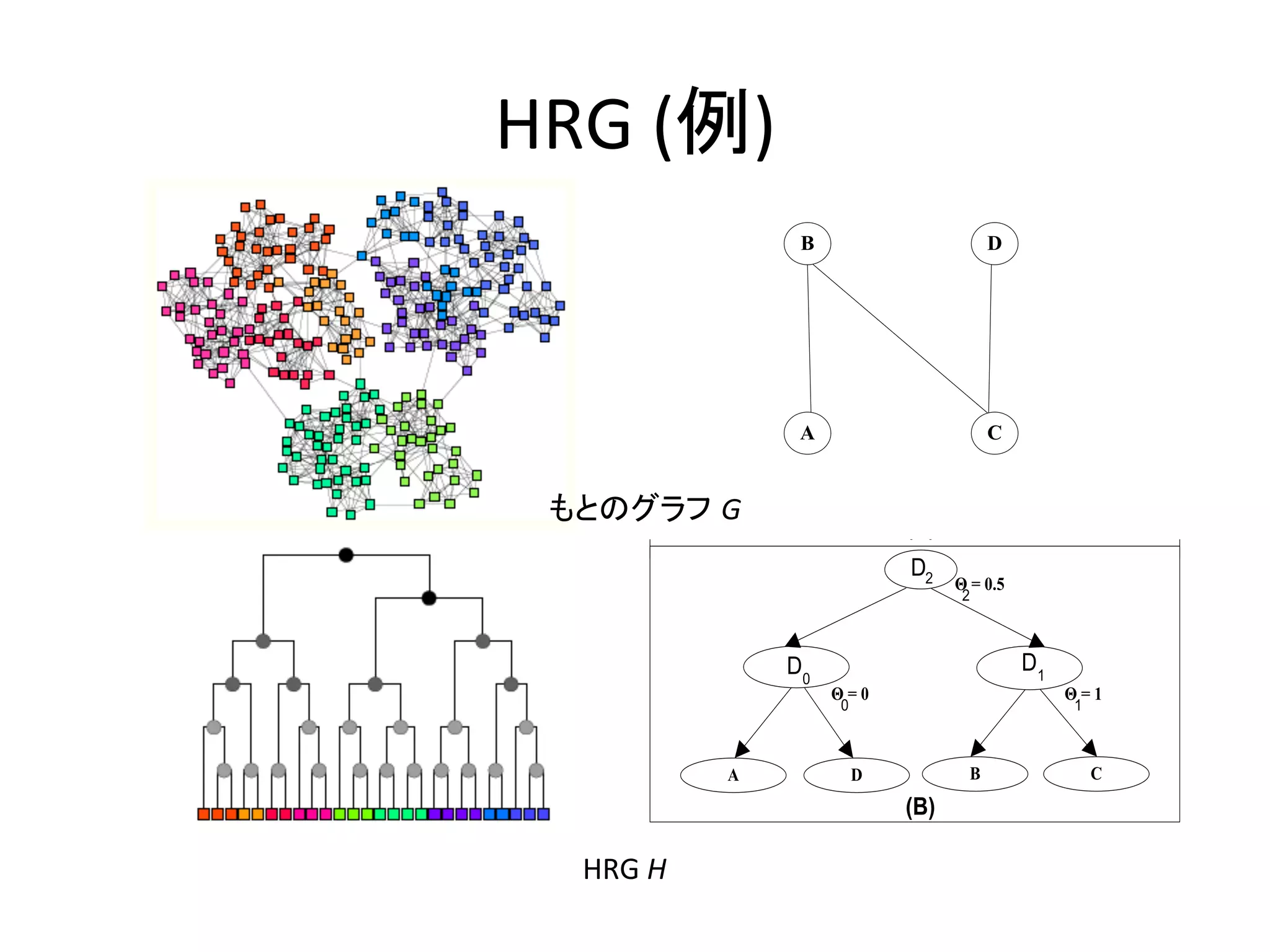
階層構造の推測
Observed
Graph
Inferred
Hierarchy
D2
B
D
D0
D1
A
C
A
B
C
D
類似度に基づくグラフを元にして、階層関係を表したグラフを作成
5.
研究の目的
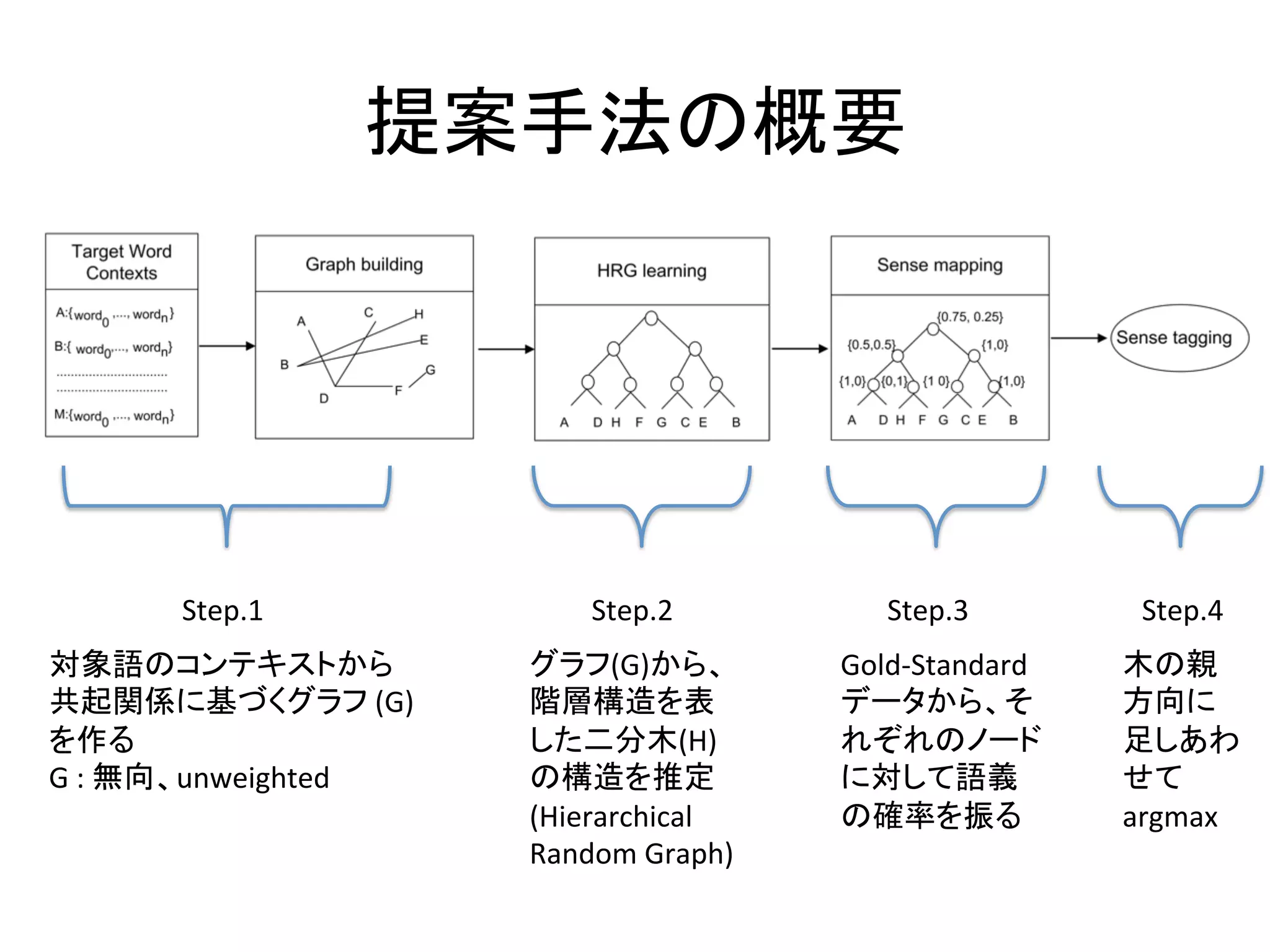
• Infer
the
hierarchical
structure
(binary
tree)
of
a
graph
made
by
the
contexts
of
a
polysemous
word.
– 多義語のコンテキストから作成されたグラフから、
階層構造(二分木)を推定する
• Apply
the
inferred
binary
tree
to
WSD
&
compare
with
flat
clustering.
– 推定された二分木をWSDに適用し、フラットなクラ
スタリングとの比較を行う
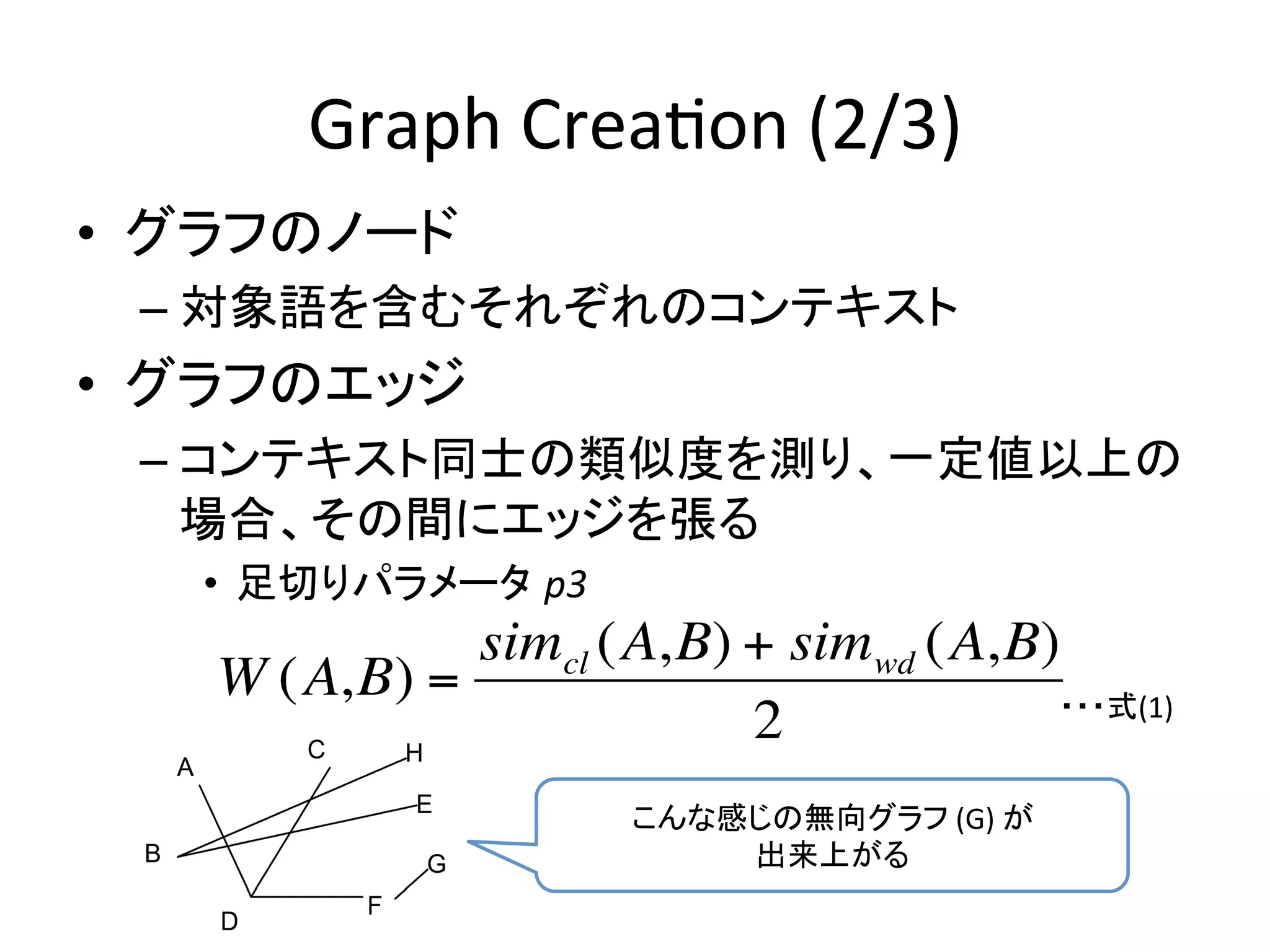
HRG
parameteriza-on
• 目標:もとのグラフ G
と統計的に類似した
!
HRGになるようなパラメータ D と ! を選ぶ
!
– !
は
Dのトポロジーさえ決まれば
MLE
で簡単に
求まる.
–
D
はsuper-‐exponen-alに組み合わせが大きくなる
!
ので、
MCMC
で求める.
!
左右どちらの二分木が、
元のグラフの性質を反映している?
15.
!
HRG
parameteriza-on
(!
)
• D
k
をHRGの内部ノードとする
• l(Dk ) r(D
)
をそれぞれ、 の左、右の
subtree
,
k Dk
に存在する葉ノードの個数とする
•
(D
k
を Dk の
subtree
同士を結ぶエッジのうち、
f
)
! もとのグラフ
G
に存在するものの数とする
!
• すると、 ! k の最尤推定値は
!
f (Dk )
!k =
l(Dk )r(Dk )
直感的に言うと・・・・
左の葉と右の葉を結ぶすべてのパスのうち、
G
に実際存在するものの割合
16.
!
HRG
parameteriza-on
(!
)
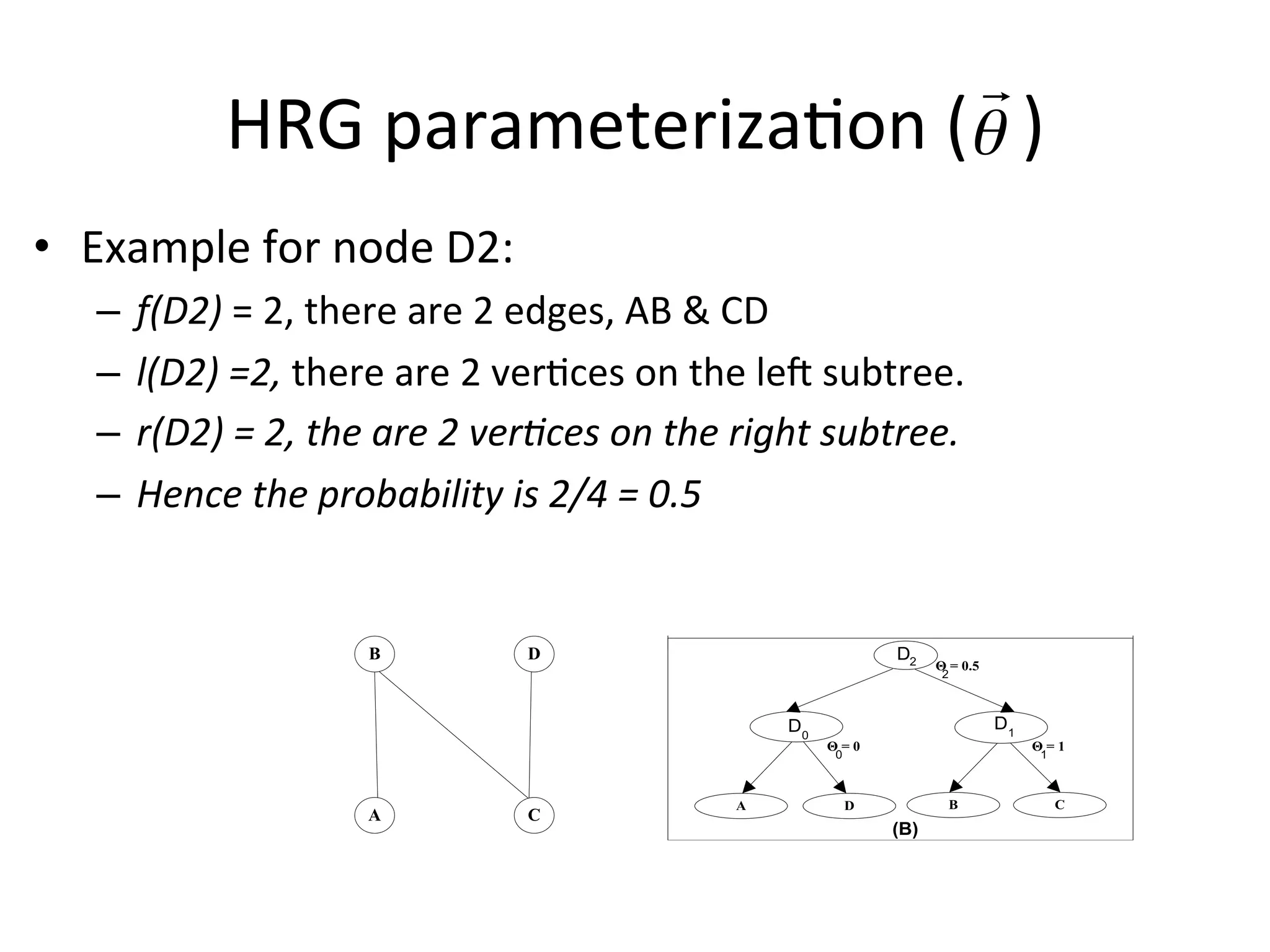
• Example
for
node
D2:
– f(D2)
=
2,
there
are
2
edges,
AB
&
CD
– l(D2)
=2,
there
are
2
ver-ces
on
the
le=
subtree.
– r(D2)
=
2,
the
are
2
ver8ces
on
the
right
subtree.
– Hence
the
probability
is
2/4
=
0.5
17.
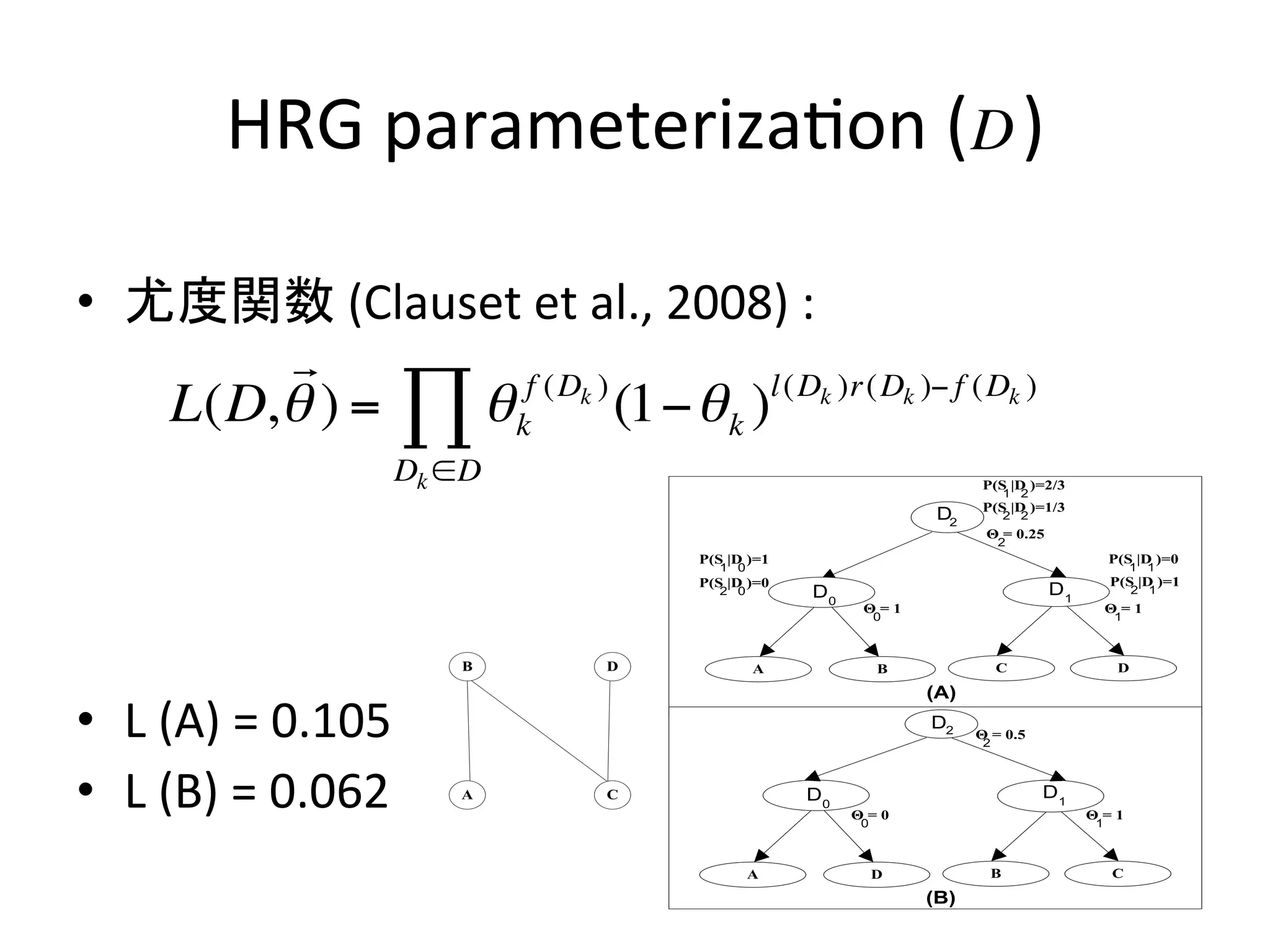
HRG
parameteriza-on
(
)
D
• 尤度関数
(Clauset
et
al.,
2008)
:
!
L(D, ! ) = " ! kf (Dk ) (1# !! l (Dk )r(Dk )# f (Dk )
k)
Dk !D
• L
(A)
=
0.105
• L
(B)
=
0.062
18.
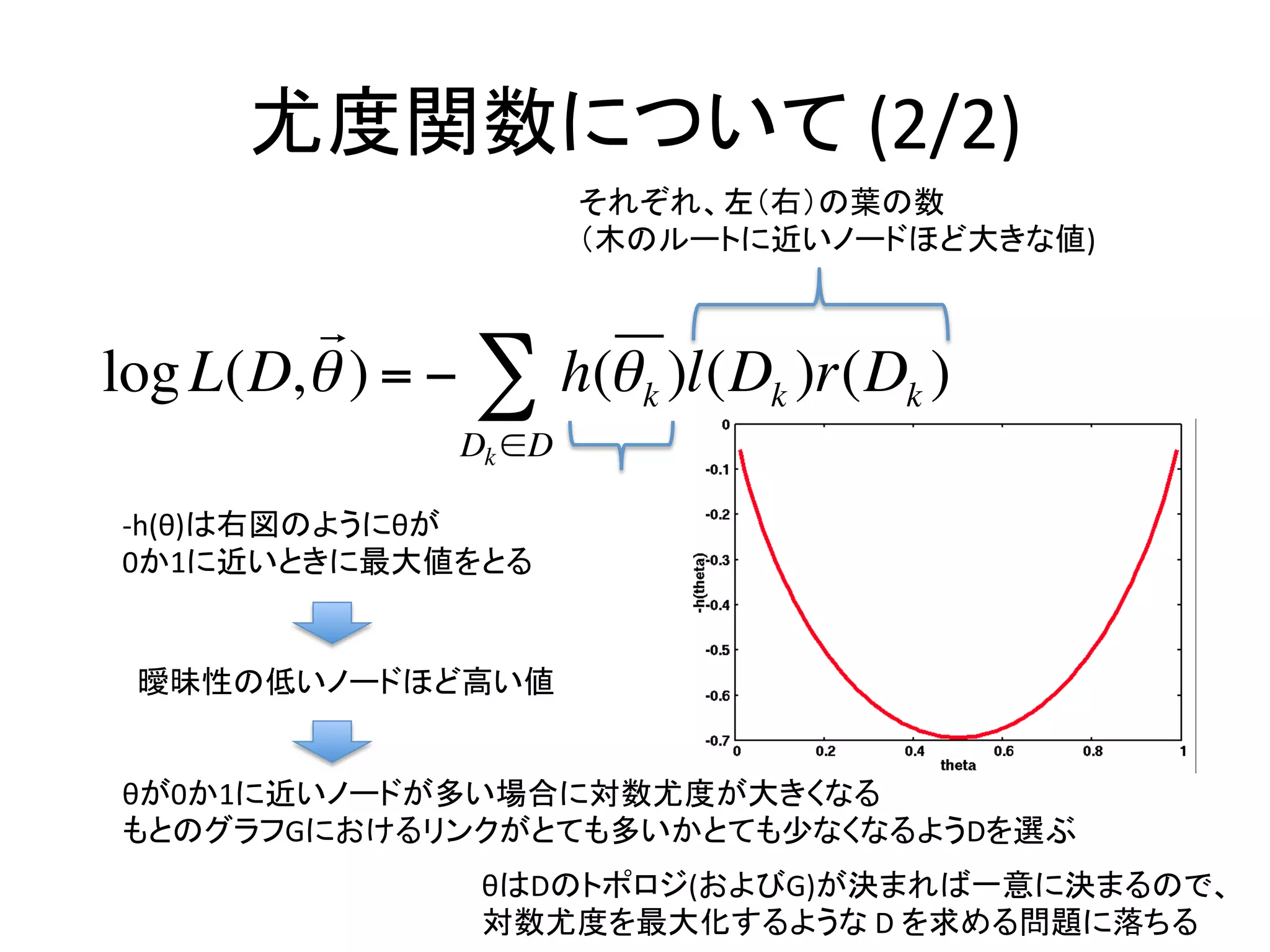
尤度関数について
(1/2)
!
L(D, ! ) = " ! kf (Dk ) (1# ! k )l (Dk )r(Dk )# f (Dk )
Dk !D
h(! k ) = !! k log! k ! (1! ! k )log(1! ! k ) とおいて対数をとると、
!
log L(D, ! ) = ! # h(! k )l(Dk )r(Dk )
Dk "D
対数尤度関数が導かれる。これを最大化するパラメータを見つけるのが目標
(対数をとるのは主にアンダーフローを防ぐため)
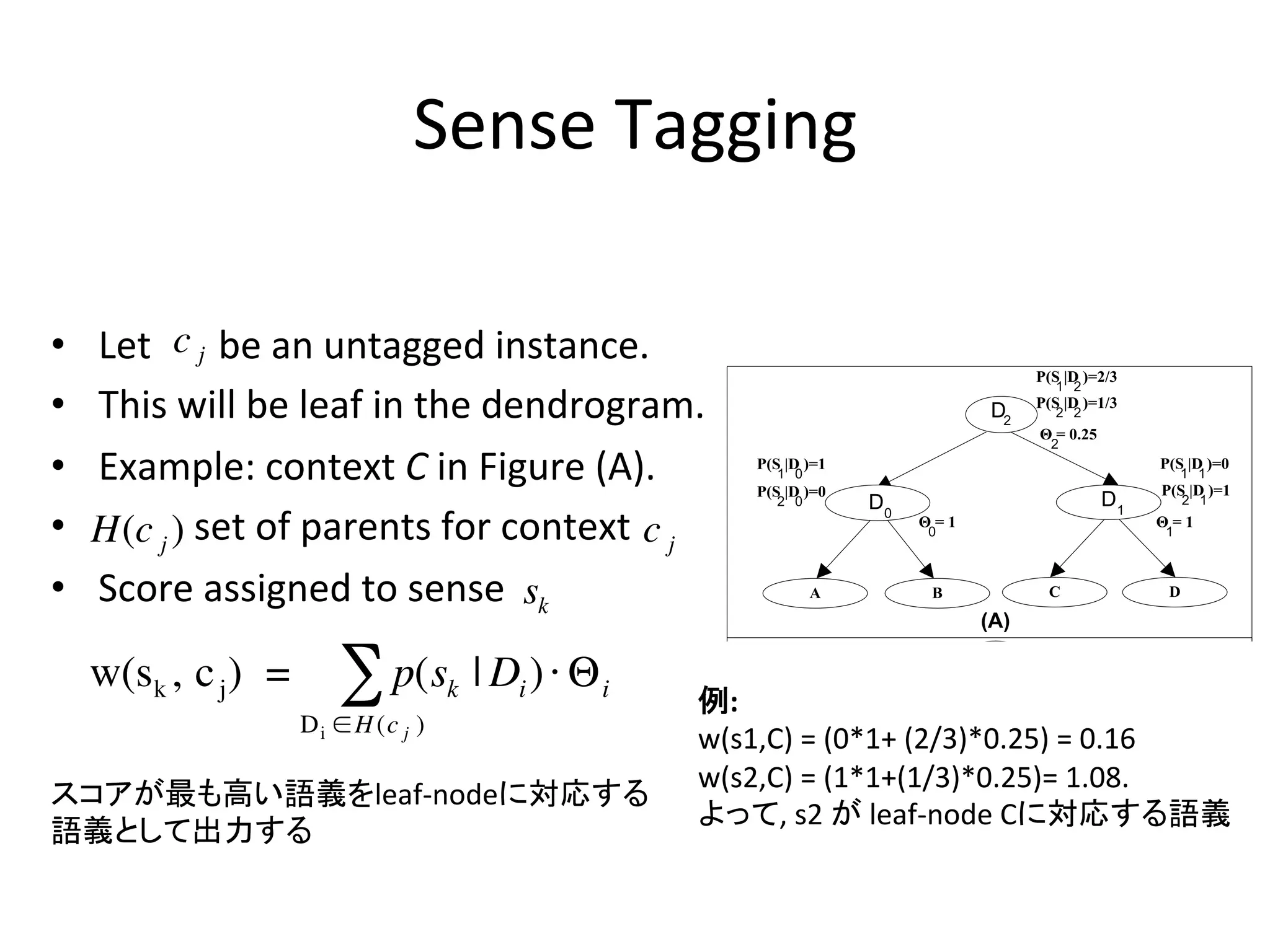
Sense
Tagging
• Let
c
j
be
an
untagged
instance.
• This
will
be
leaf
in
the
dendrogram.
• Example:
context
C
in
Figure
(A).
! • H(c
j
)
set
of
parents
for
context
c j
• Score
assigned
to
sense
sk
w(sk , c j ) = % p(s k | Di ) " # i
! 例:
D i $ H (c j )
w(s1,C)
=
(0*1+
(2/3)*0.25)
=
0.16
! w(s2,C)
=
(1*1+(1/3)*0.25)=
1.08.
スコアが最も高い語義をleaf-‐nodeに対応する
よって,
s2
が
leaf-‐node
Cに対応する語義
語義として出力する
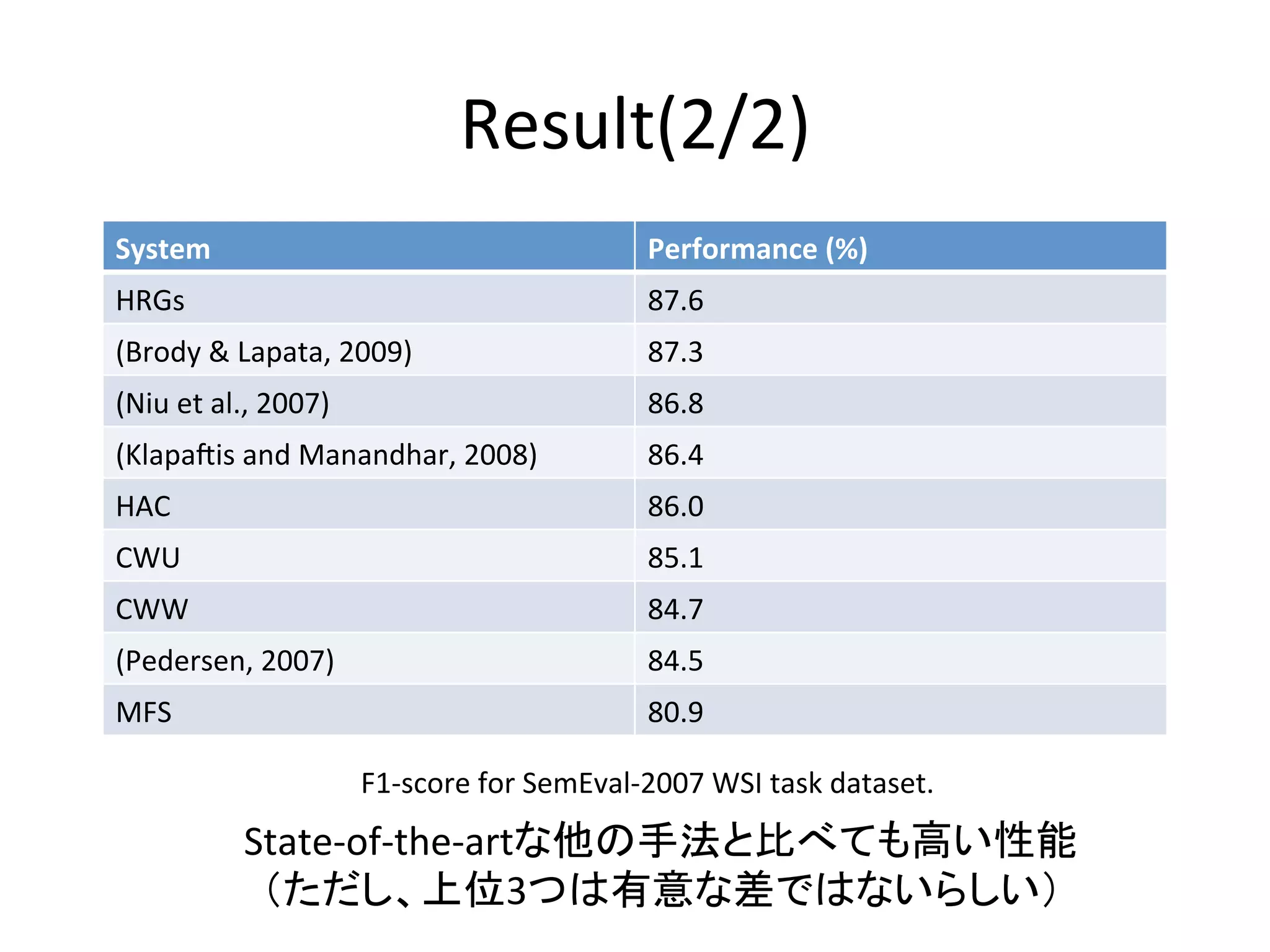
Result(2/2)
System
Performance
(%)
HRGs
87.6
(Brody
&
Lapata,
2009)
87.3
(Niu
et
al.,
2007)
86.8
(Klapa=is
and
Manandhar,
2008)
86.4
HAC
86.0
CWU
85.1
CWW
84.7
(Pedersen,
2007)
84.5
MFS
80.9
F1-‐score
for
SemEval-‐2007
WSI
task
dataset.
State-‐of-‐the-‐artな他の手法と比べても高い性能
(ただし、上位3つは有意な差ではないらしい)
30.
Conclusion
• Unsupervised
method
for
inferring
the
hierarchical
grouping
of
the
senses
of
a
polysemous
word.
• Graphs
exhibit
hierarchical
organiza-on
captured
by
HRGs,
in
effect
providing
improved
WSD
performance
compared
to
– Flat
graph
clustering.
– Hierarchical
Agglomera-ve
Clustering