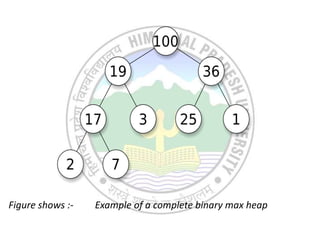
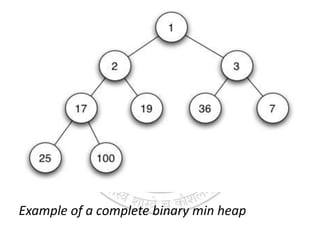
The document defines priority queues as data structures where elements are processed based on assigned priorities, detailing basic operations, including insertion and deletion, along with the concept of binary heaps as implementations of these queues. It also explains heap properties—such as min-heap and max-heap—along with various operations like find-max, extract-min, and heap creation. Additionally, the document outlines applications of priority queues in algorithms and processes such as A* search, Dijkstra's algorithm, and Huffman coding.









![Basic Heap Operation
The common operations are:
• Basic operations:-
Find-max (or find-min): find a maximum item of a
max-heap, or a minimum item of a min-heap,
respectively(peek operation) .
insert: adding a new key to the heap (push ).
extract-max (or extract-min): returns the node of
maximum value from a max heap [or minimum value
from a min heap] after removing it from the heap (pop
operation).
delete-max (or delete-min): removing the root
node of a max heap (or min heap), respectively.](https://image.slidesharecdn.com/priorityqueue-200810093330/85/Priority-queue-12-320.jpg)





























































![Attack surfaces and attack tress[inform]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture03-260108015941-a4dee53b-thumbnail.jpg?width=640&height=640&fit=bounds)









