Downloaded 11 times









![public class MinGraphScoring extends BaseOperation implements Buffer{
@Override
public void operate(FlowProcess flowProcess, BufferCall bufferCall) {
Iterator<TupleEntry> arguments = bufferCall.getArgumentsIterator();
Graph g = new Graph();
while( arguments.hasNext() )
{
TupleEntry tpe = arguments.next();
ByteBuffer b = ByteBuffer.wrap((byte[])tpe.getObject("field1"););//use kyro
serialization
g.put(b)
}
Node[] nodes = g.nodes;
//For each pair of nodes : i,j {
double minmaxscore = scoring(g,i,j)
Tuple t1 = new Tuple(nodes[i].id ,nodes[j].id ,minmaxscore);
bufferCall.getOutputCollector().add(t1);
}
}](https://image.slidesharecdn.com/cascadingtalk-140408130903-phpapp02/75/Cascading-talk-in-Etsy-http-www-meetup-com-cascading-events-169390262-13-2048.jpg)


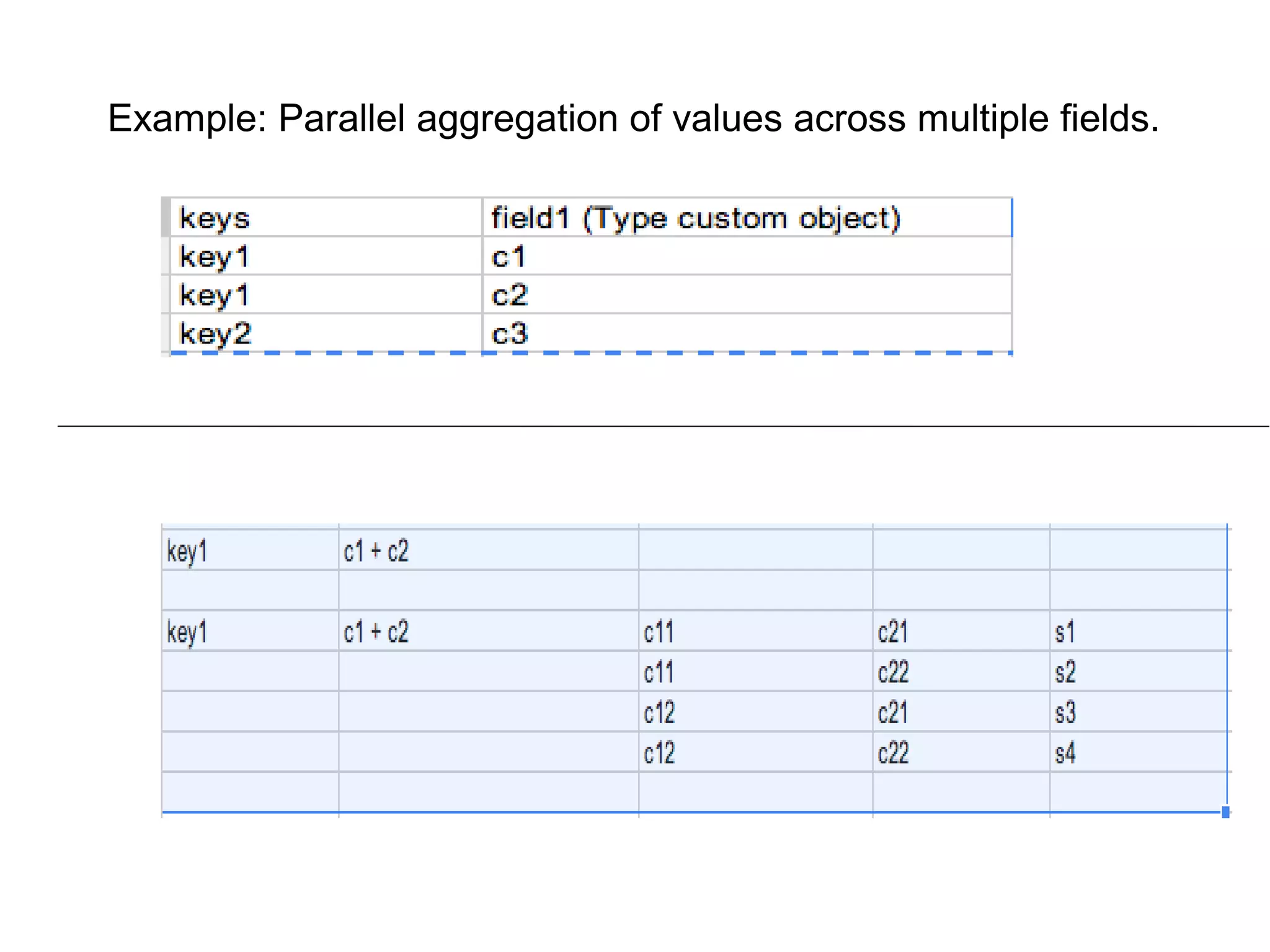
![Custom Src/Sink Taps
Cascading has good support to read/write to/from different form of
data sources. Slight tuning or change might be required but most of
code already exists.
− Hive (with different file formats), HBase, MySQL
− http://www.cascading.org/extensions/
− Set proper Config parameters while reading from source tap,
example while reading from Hbase Tap,
String tableName = "device_ids";
String[] familyNames = new String[] { "id:type1", "id:type2",
“id:type3”,...”id:typen” };
Scan scan = new Scan();
scan.setCacheBlocks(false);
scan.setCaching(10000);
scan.setBatch(10000);](https://image.slidesharecdn.com/cascadingtalk-140408130903-phpapp02/75/Cascading-talk-in-Etsy-http-www-meetup-com-cascading-events-169390262-16-2048.jpg)










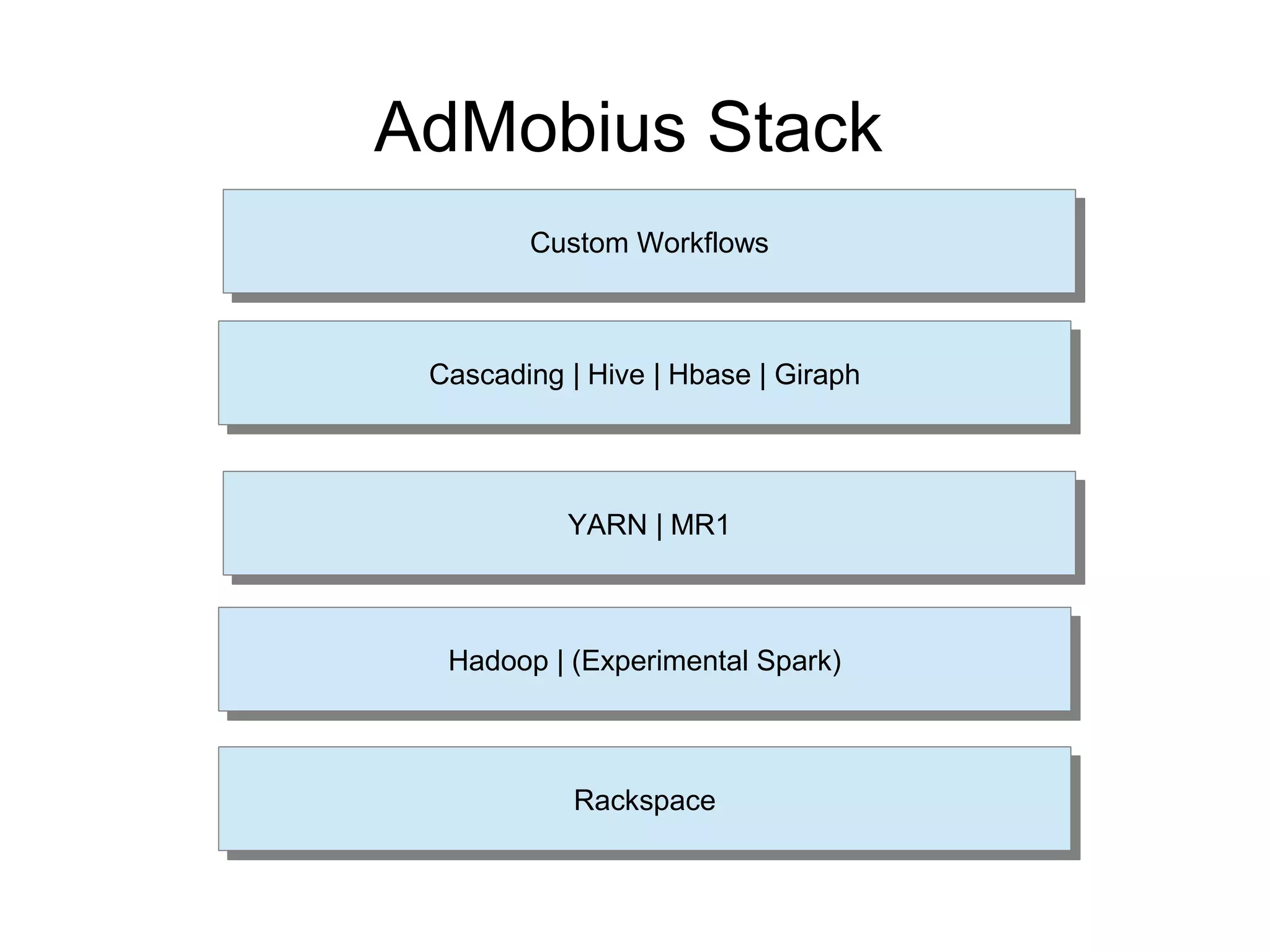
AdMobius is a mobile audience management platform that uses Cascading for complex data aggregation and processing in its tech stack. Cascading allows AdMobius to easily write custom aggregators and workflows for tasks like device graph building, scoring, and profiling audiences at scale across billions of mobile devices. Some key benefits of using Cascading include its support for custom joins, taps for various data sources, and best practices like checkpointing and compression to optimize performance.














![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt1580-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Paper Reading]Orca: A Modular Query Optimizer Architecture for Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/orca-211220090600-thumbnail.jpg?width=640&height=640&fit=bounds)















































