Download as PDF, PPTX








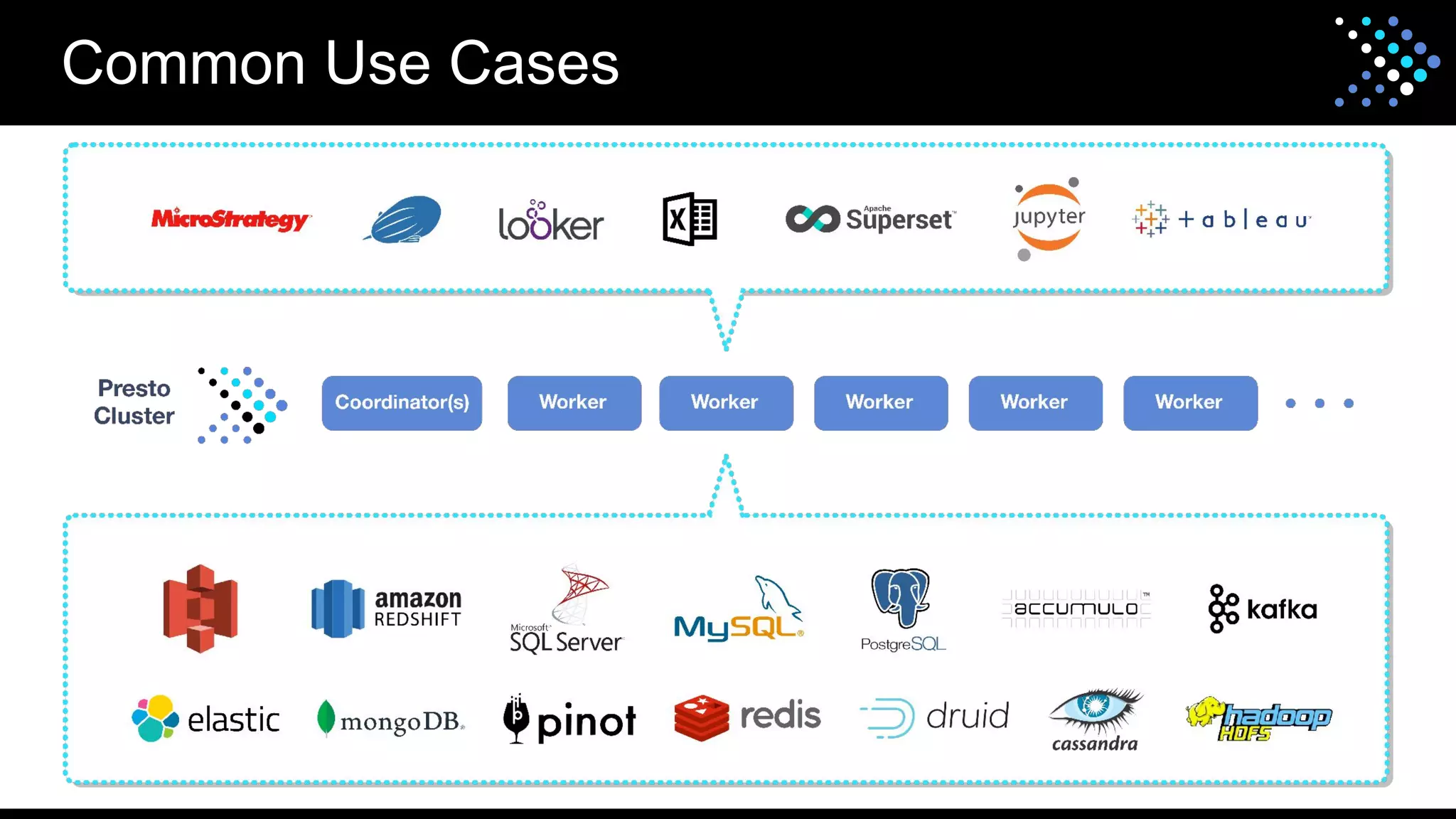




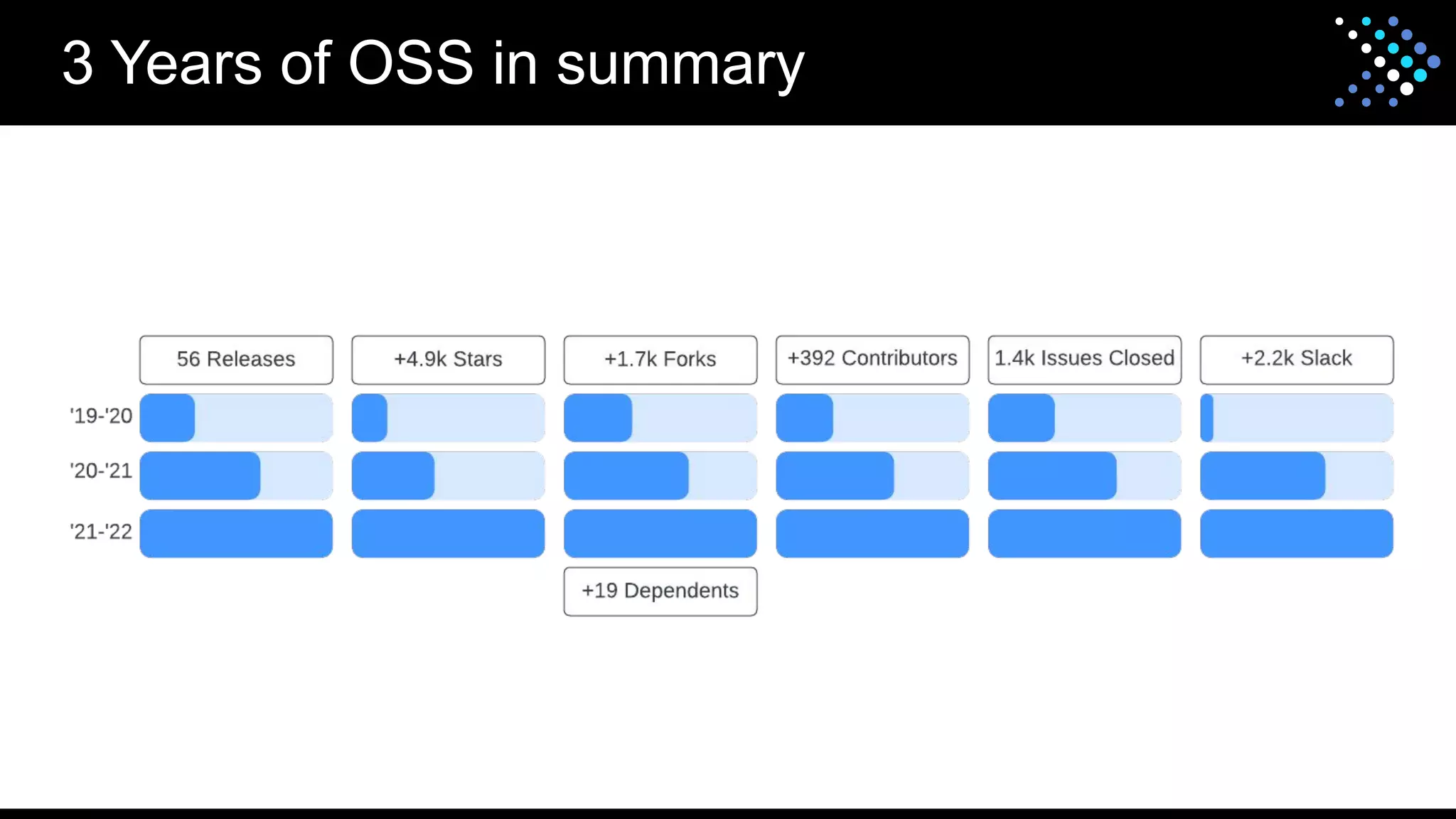


















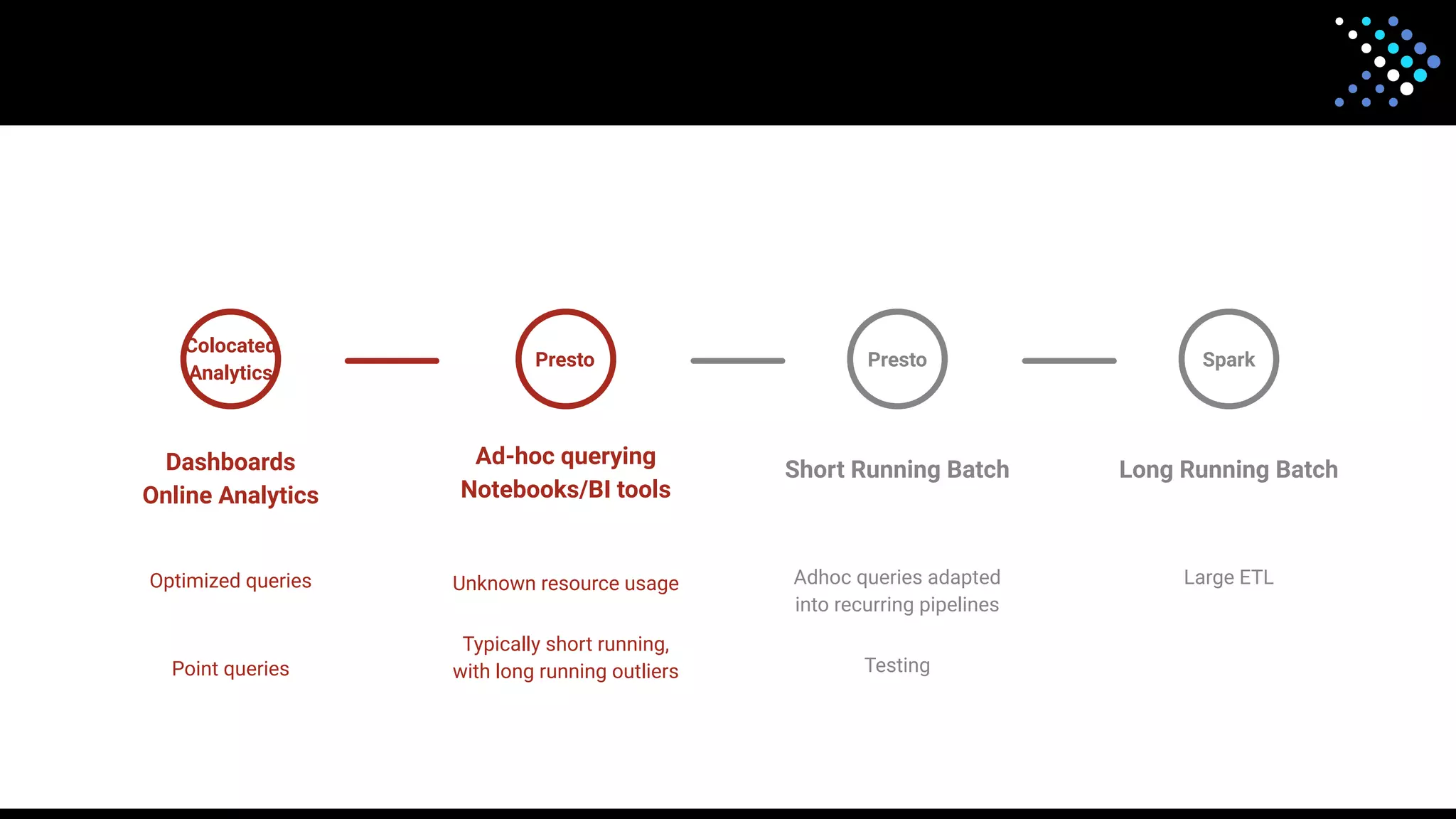

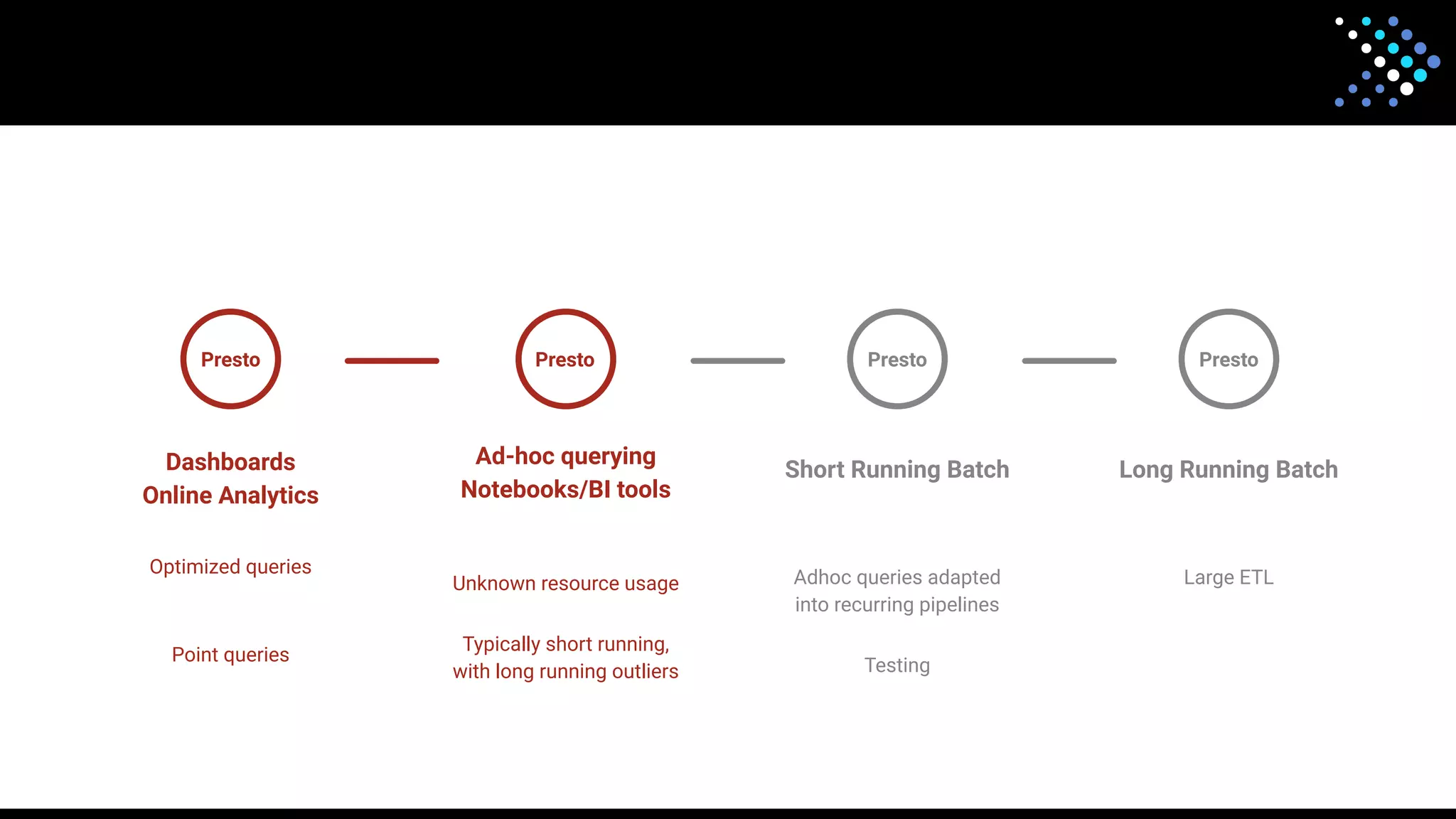



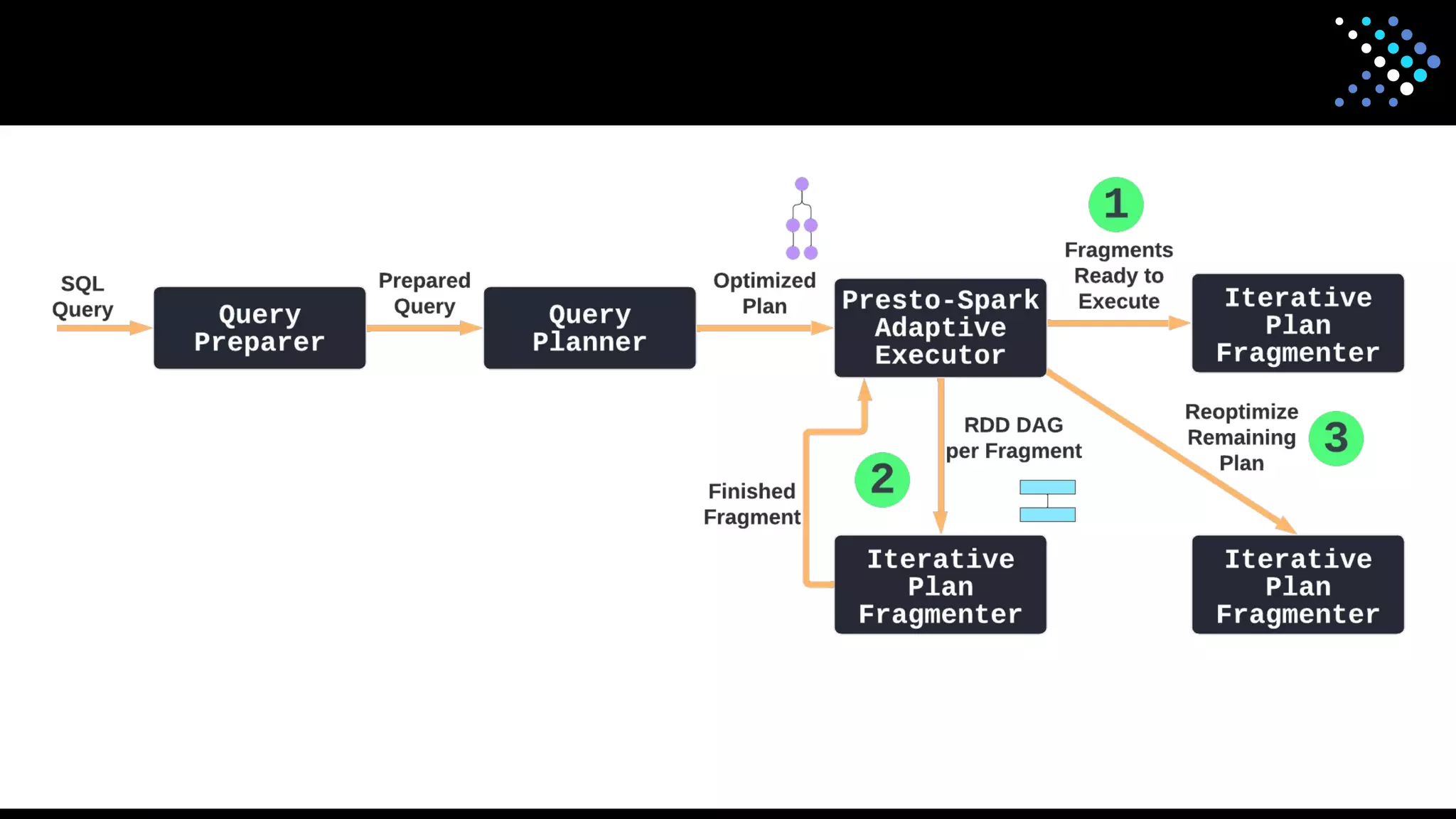

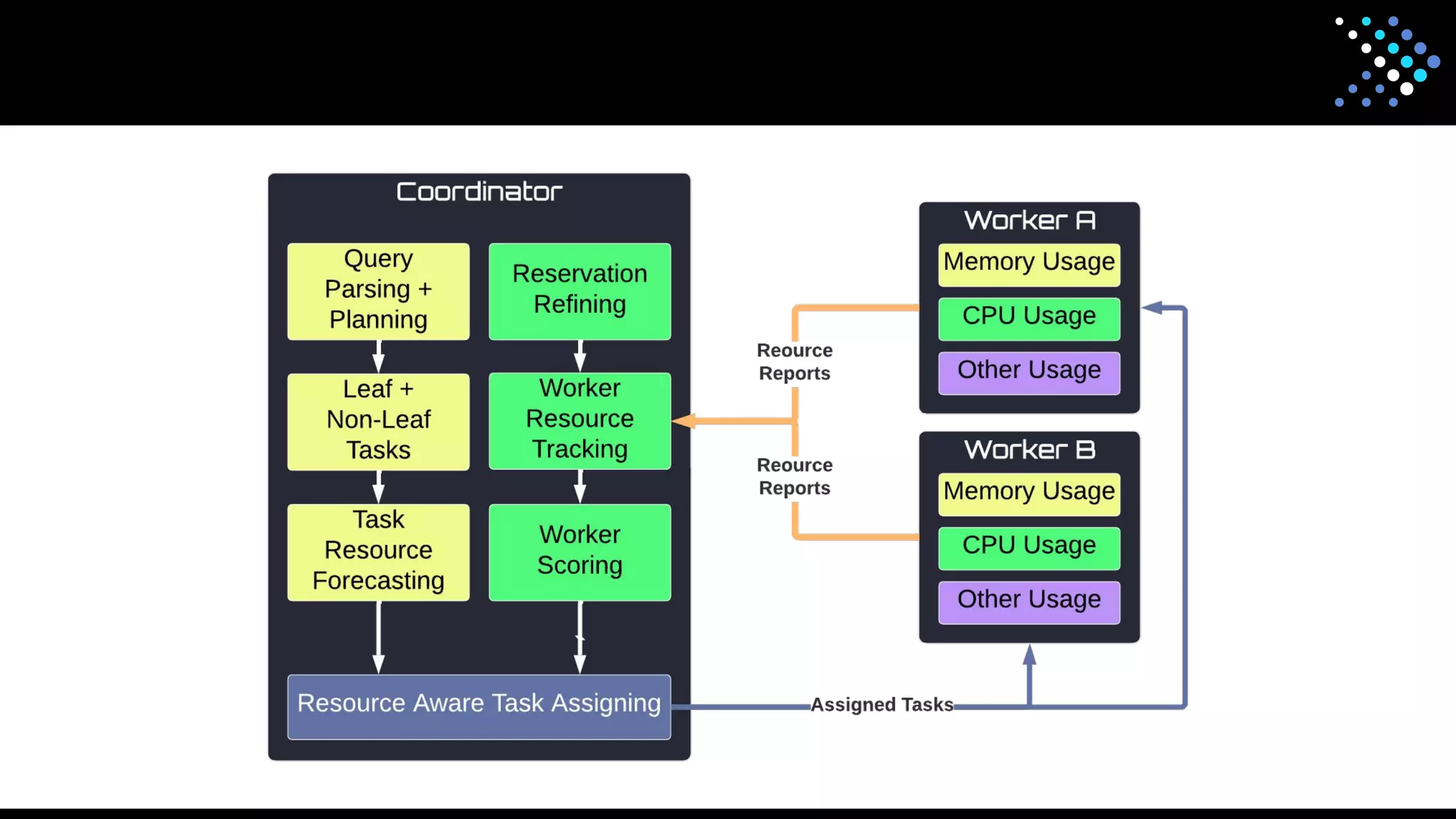









The document discusses the open-source SQL engine Presto, detailing its features, connectors, and ongoing developments aimed at enhancing performance and user experience. It highlights contributions from various organizations and outlines the goals for 2023 regarding improved reliability, scalability, and unified functionality for both batch and interactive processing. The document also encourages community involvement in the evolution of Presto through contributions and collaboration.

















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















