Downloaded 30 times

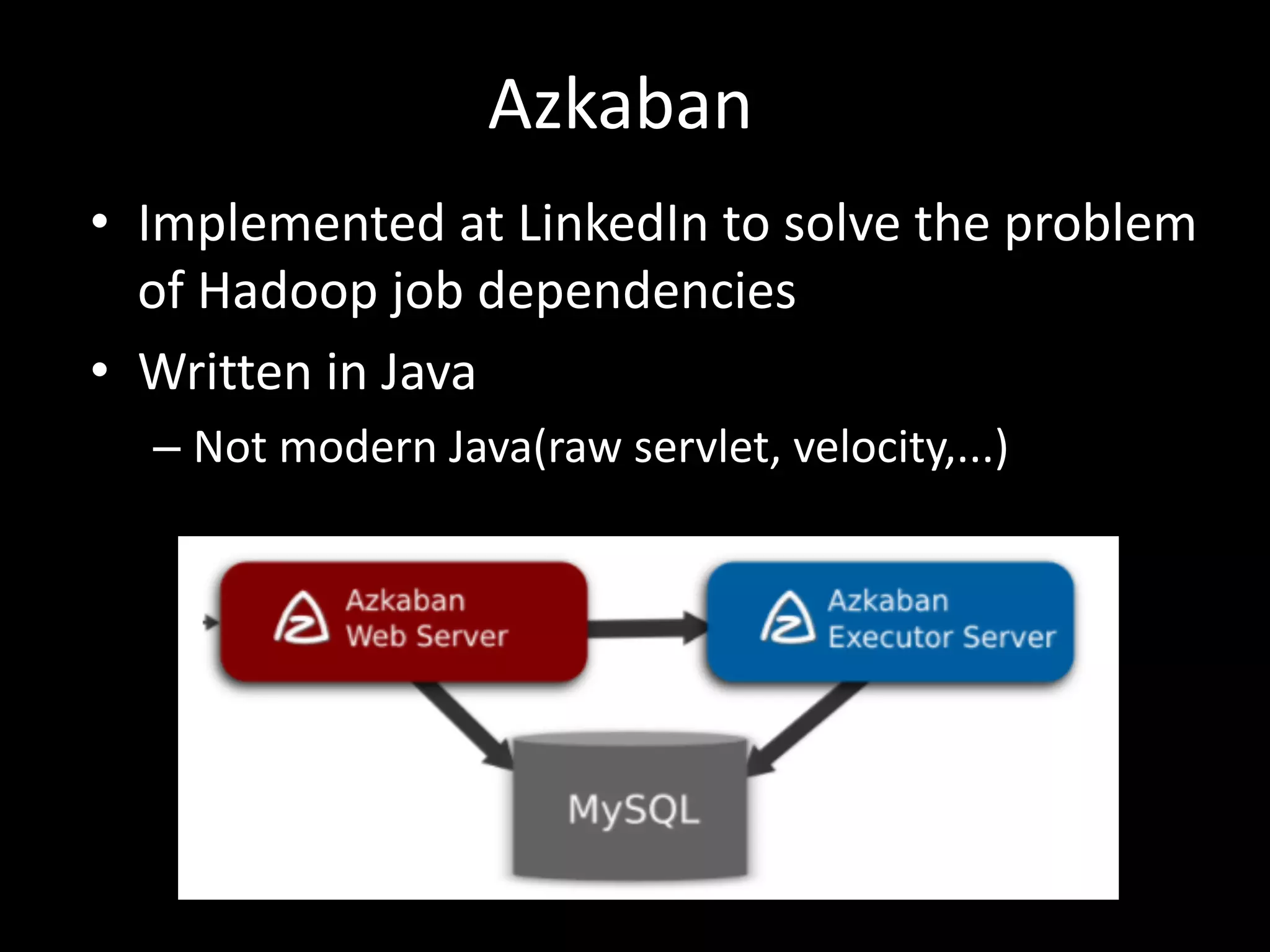







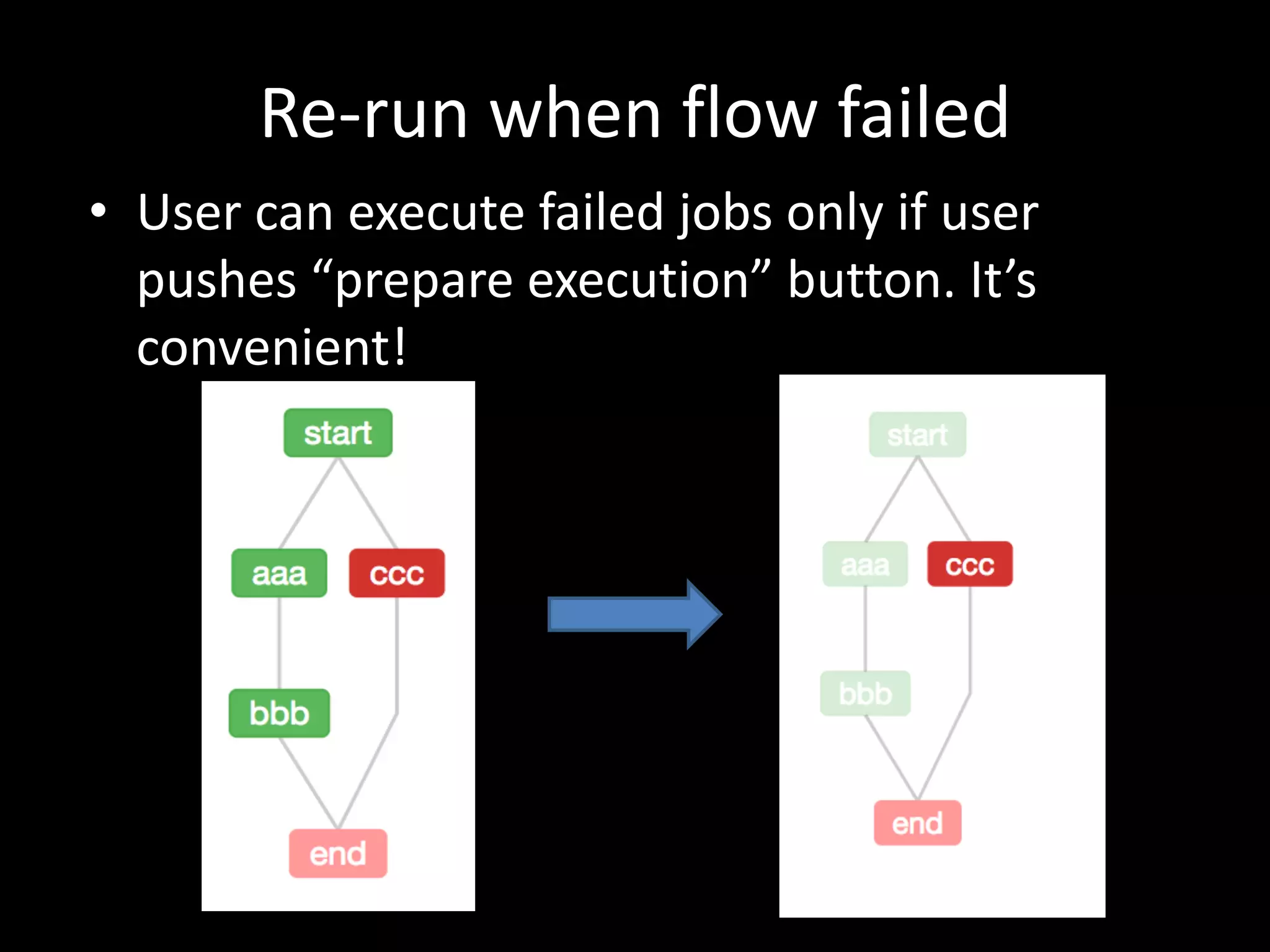













This document summarizes Azkaban, an open source workflow scheduler that was created at LinkedIn to manage Hadoop jobs and their dependencies. Key features of Azkaban include defining job dependencies in a simple interface, retry functionality, scheduling, and viewing logs and execution details in the web UI. The document also discusses how the author uses Azkaban to manage Python batch jobs at their company, including writing job files in YAML format and using the Azkaban API. In conclusion, the author finds Azkaban simple to use and sees no reason to replace it, though hopes for more active development.

































































