


















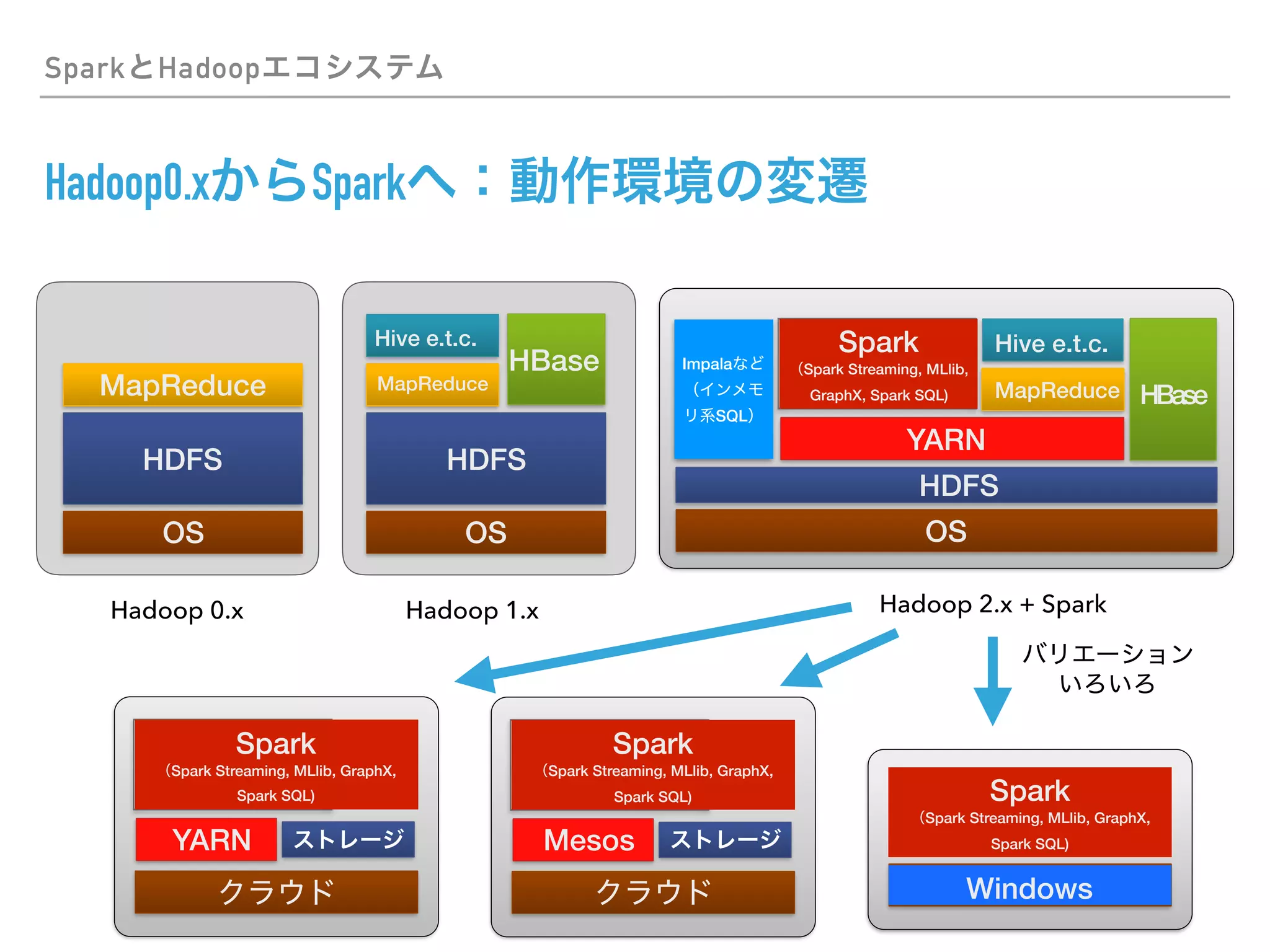
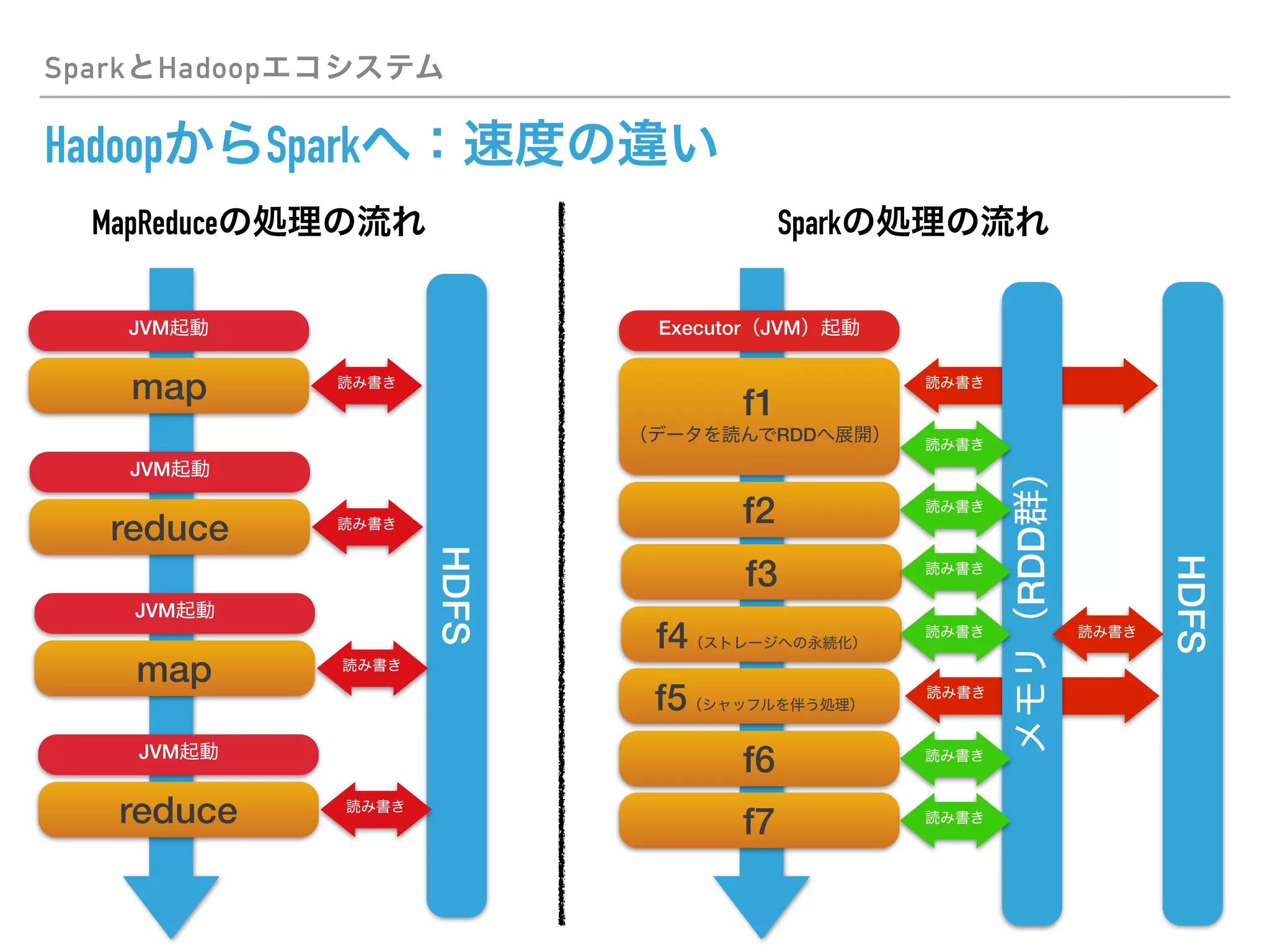

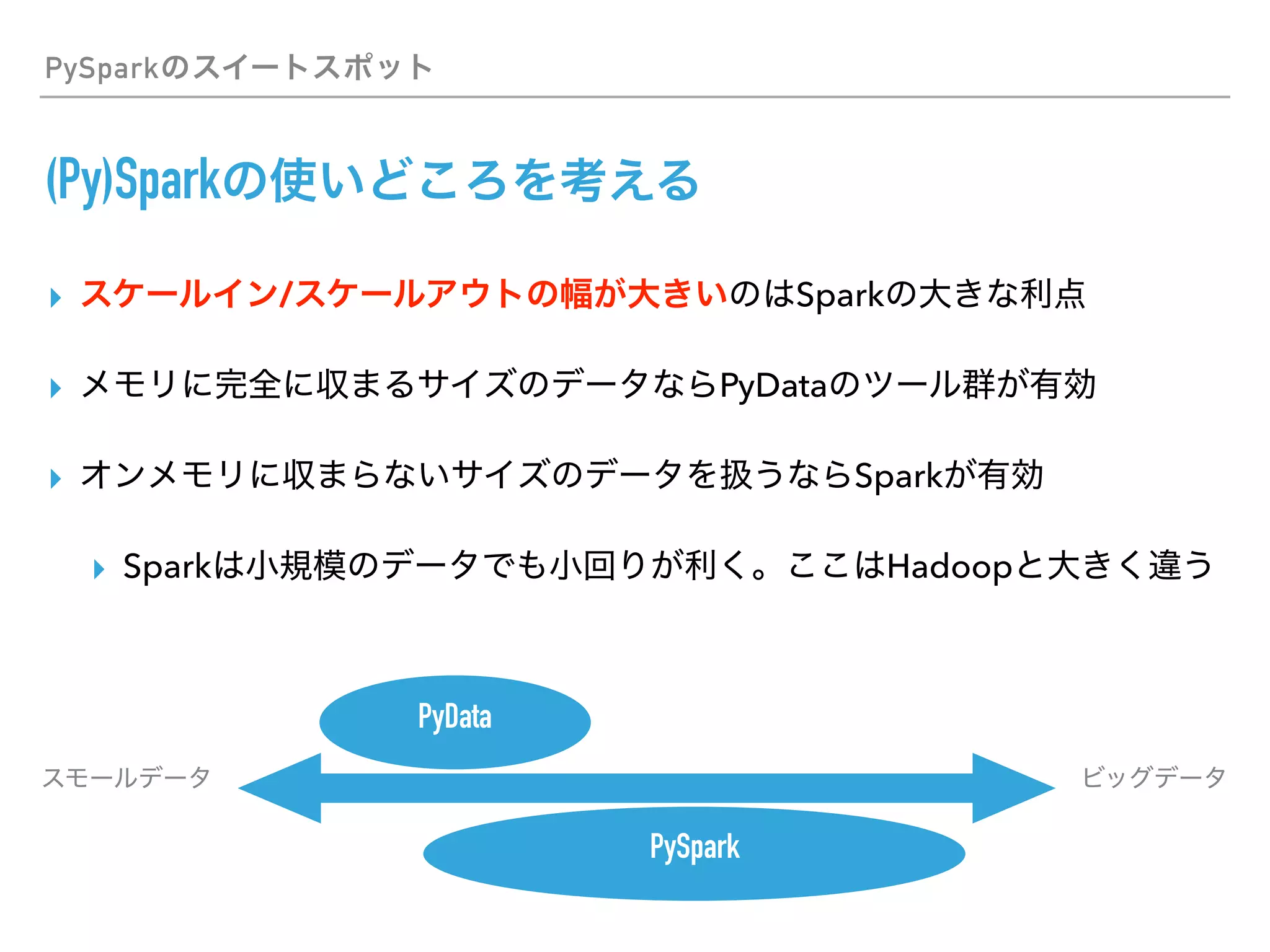



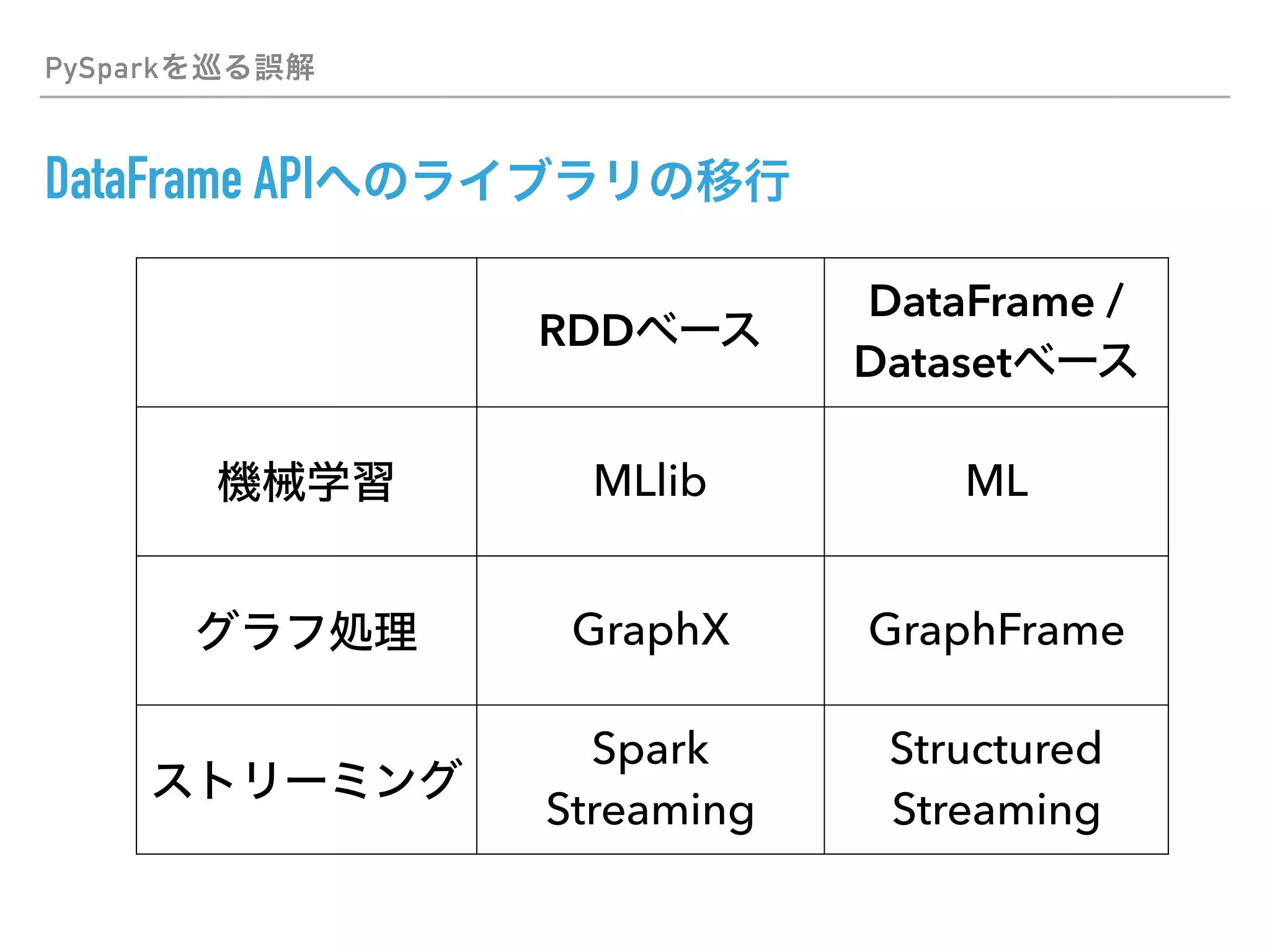
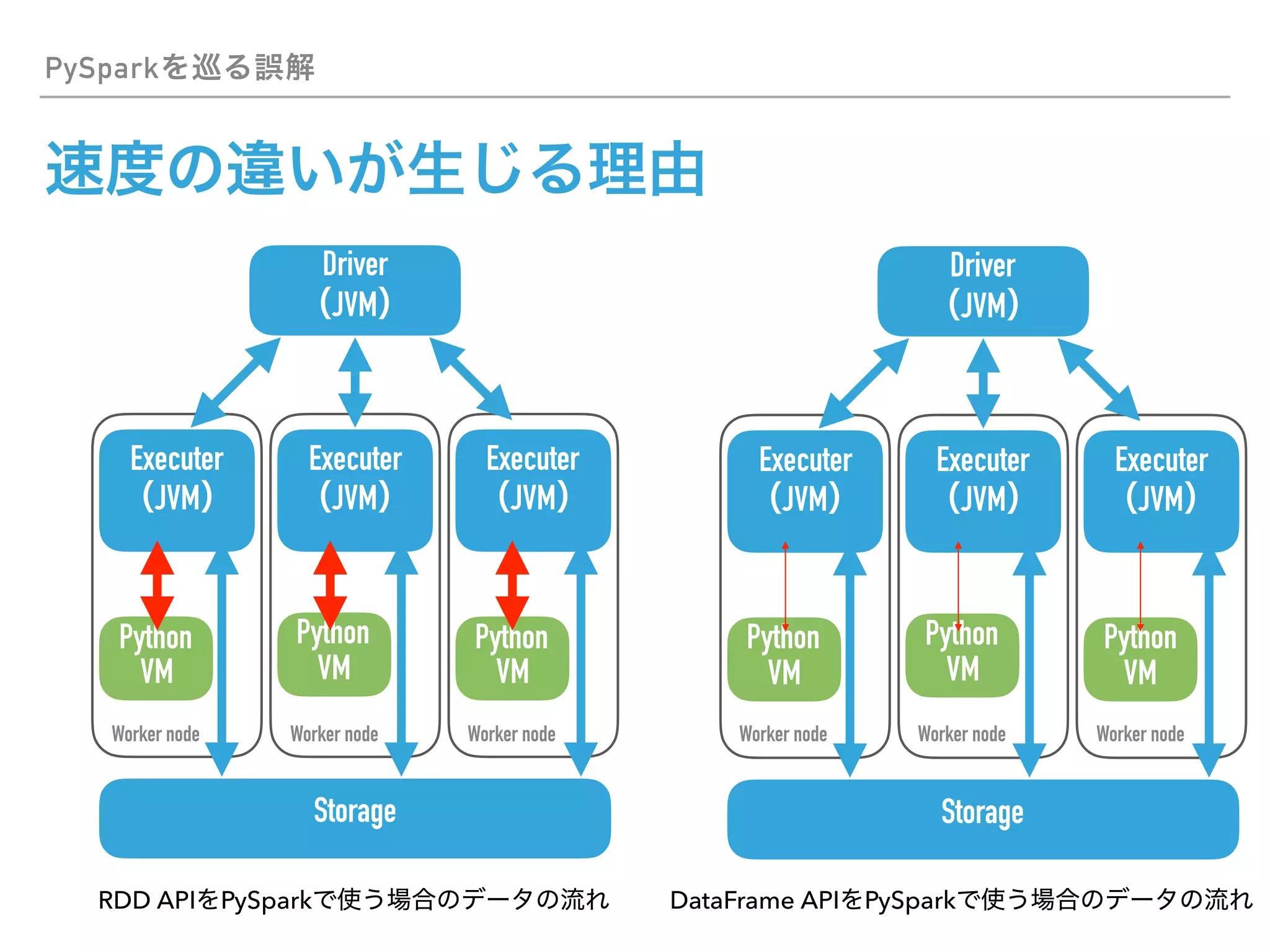




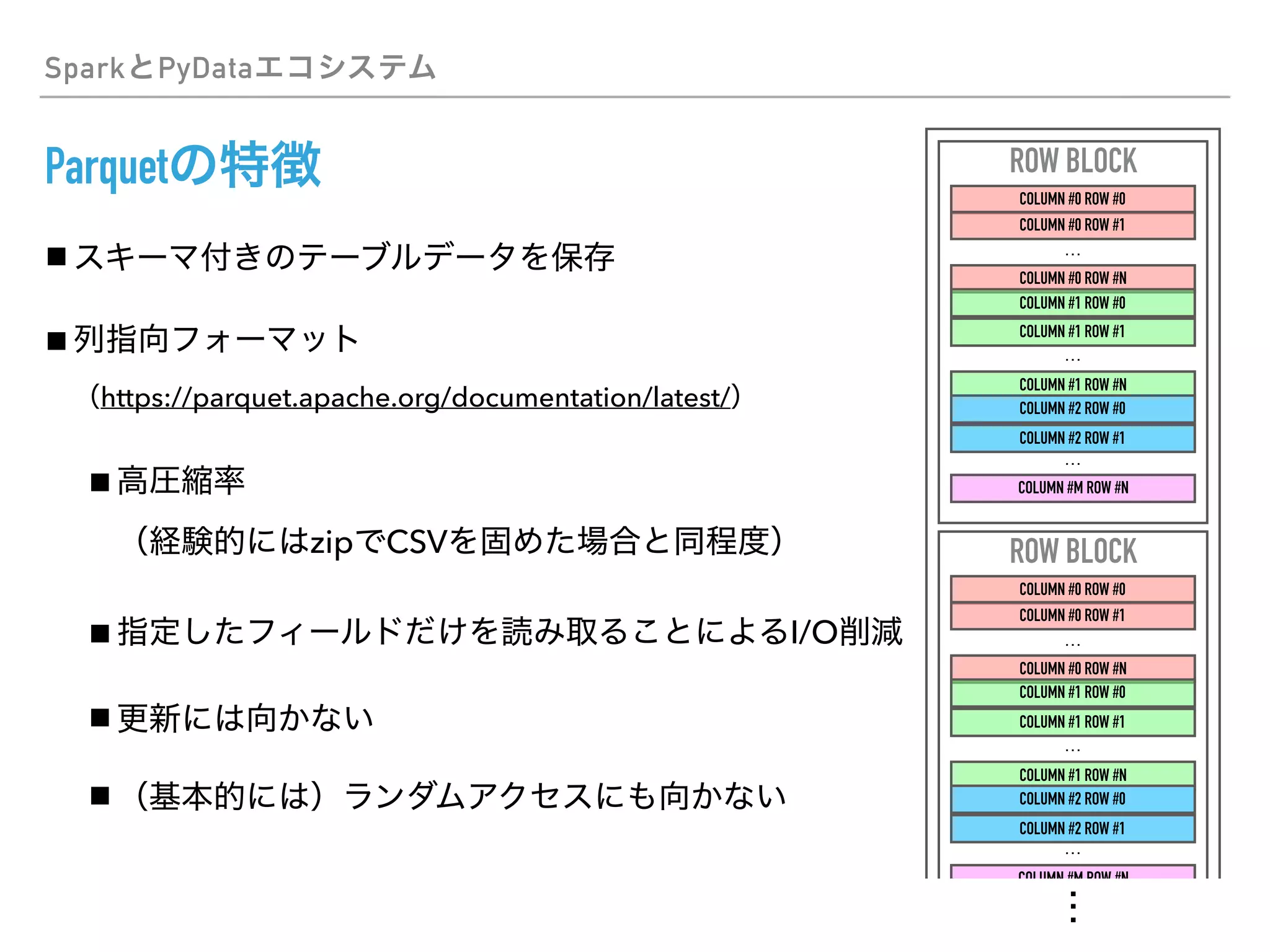
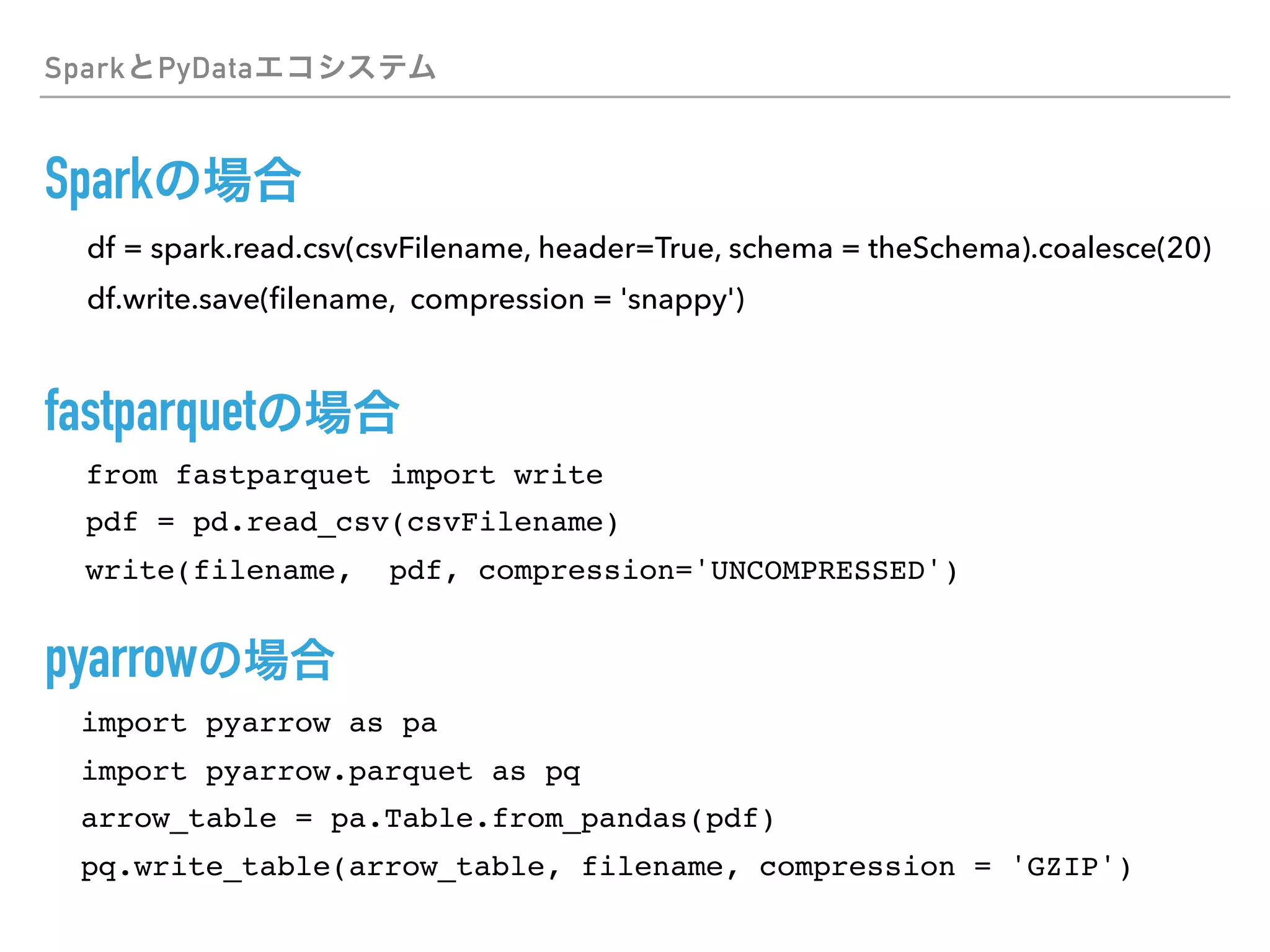

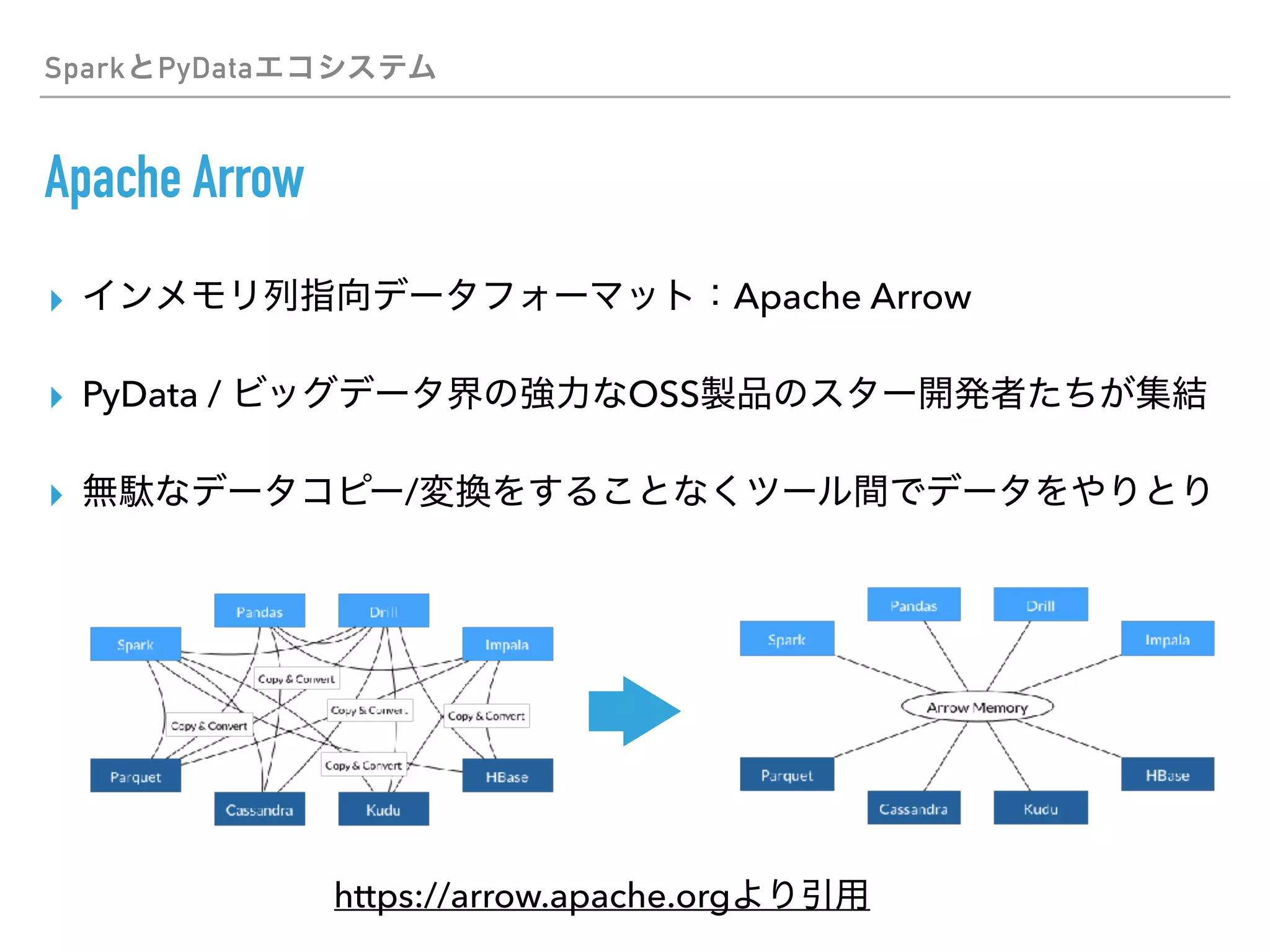



This document discusses PySpark and how it relates to Python, Spark, and big data frameworks. Some key points discussed include: - PySpark allows users to write Spark applications in Python, enabling Python users to leverage Spark's capabilities for large-scale data processing. - PySpark supports both the RDD API and DataFrame API for working with distributed datasets. It also integrates with Spark libraries like MLlib, GraphX, and Spark SQL. - The document discusses how PySpark fits into the broader Spark and Hadoop ecosystems. It also covers topics like Parquet and Apache Arrow for efficient data serialization between Python and Spark.




























![[db analytics showcase Sapporo 2017] A15: Pythonでの分散処理再入門 by 株式会社HPCソリューションズ ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase-sapporo-2017-iisaka-170707075724-thumbnail.jpg?width=640&height=640&fit=bounds)





































































