Download to read offline





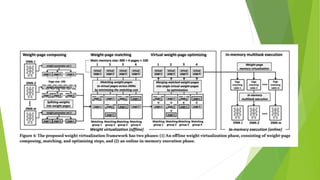
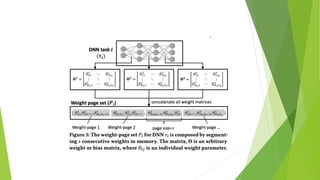



This document introduces neural weight virtualization, which enables fast and scalable in-memory multitask deep learning on memory-constrained systems. It proposes a two-phase approach involving virtualizing weight parameters and an in-memory execution framework. This allows packing multiple DNNs into main memory when their combined size is larger. It was implemented on an embedded GPU mobile robot and microcontroller IoT device, showing improvements in memory efficiency, execution time and energy efficiency of up to 4.1x, 36.9x and 4.2x respectively.























































