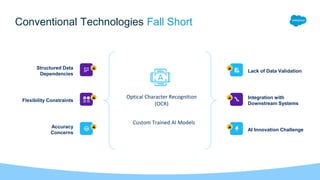
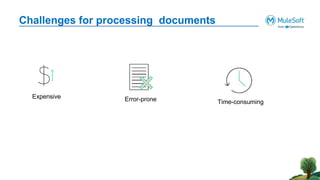
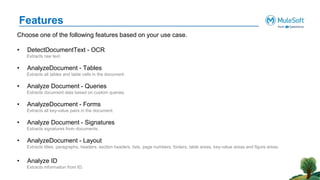
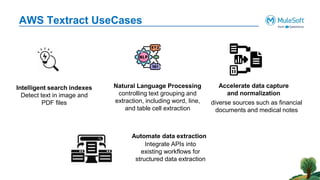
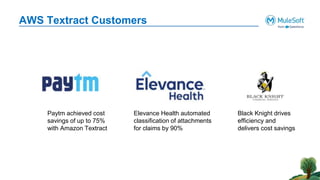
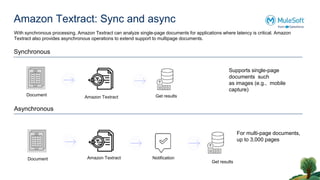
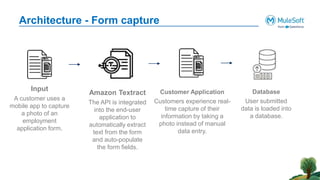
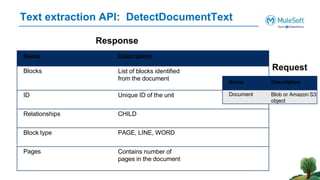
The document outlines the agenda for the AWS Cloud Native Mulesoft Meetup on May 11, 2024, focusing on AWS Textract and its capabilities for intelligent document processing. It highlights the challenges of conventional document processing methods, the need for scalable solutions, and showcases the features and use cases of AWS Textract for automating data extraction. The event includes a demo on Textract integration with Mulesoft, followed by Q&A and networking opportunities.








































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Part-1] Automating MuleSoft Deployment with Github Actions | MuleSoft Mysore...](https://cdn.slidesharecdn.com/ss_thumbnails/meetup-automatemulesoftdeploymentwithgithubactions-part12-240717083415-d4c0ece9-thumbnail.jpg?width=640&height=640&fit=bounds)




![MuleSoft Integration with AWS Lambda [Serverless Function] | MuleSoft Mysore ...](https://cdn.slidesharecdn.com/ss_thumbnails/awslambdapptupdated-240302064159-36cba569-thumbnail.jpg?width=640&height=640&fit=bounds)
![Munits in Mule 4 [Deep-Dive] | MuleSoft Mysore Meetup #40](https://cdn.slidesharecdn.com/ss_thumbnails/munitsinmule4-240113100118-3605f9d0-thumbnail.jpg?width=640&height=640&fit=bounds)




























