Downloaded 115 times







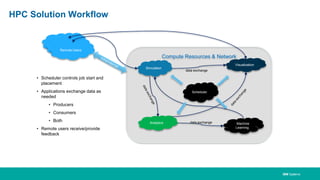





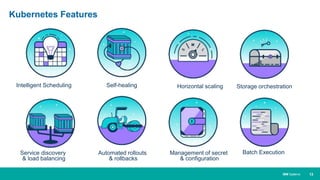
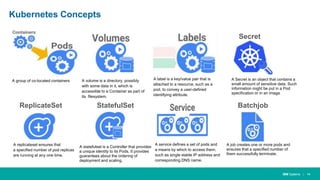
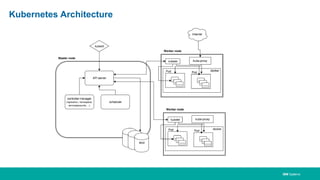


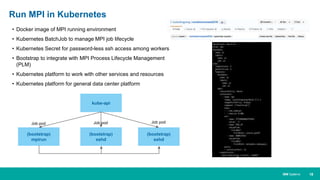
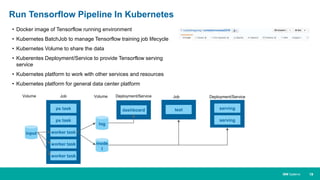
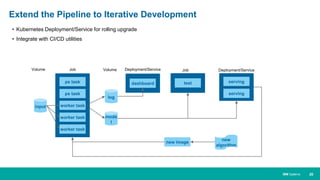


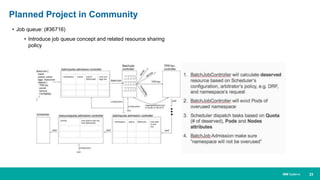




When HPC Meet ML/DL Machine learning and deep learning (ML/DL) are becoming important workloads for high performance computing (HPC) as new algorithms are developed to solve business problems across many domains. Container technologies like Docker can help with the portability and scalability needs of ML/DL workloads on HPC systems. Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications that can help run MPI jobs and ML/DL pipelines on HPC systems, though it currently lacks some features important for HPC like advanced job scheduling capabilities. Running an HPC-specific job scheduler like IBM Spectrum LSF on top of Kubernetes is one approach to address current gaps in















































