Downloaded 28 times







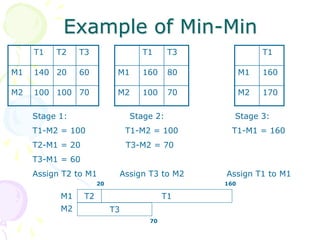

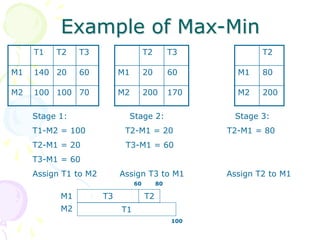

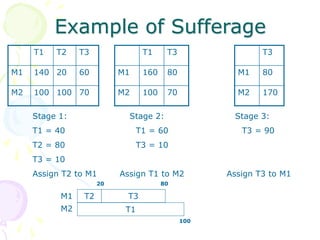

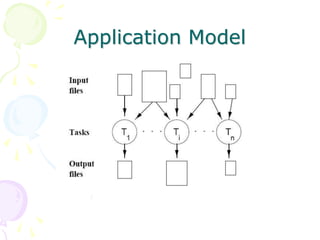
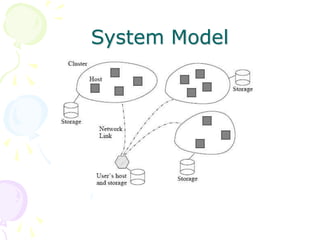

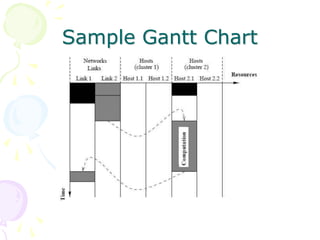



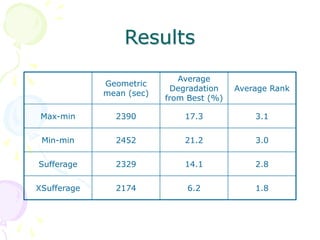
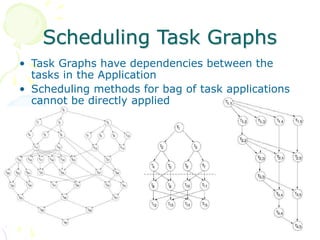
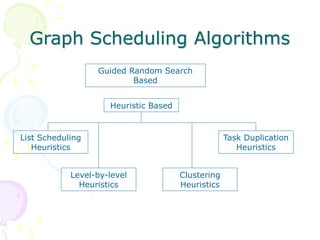


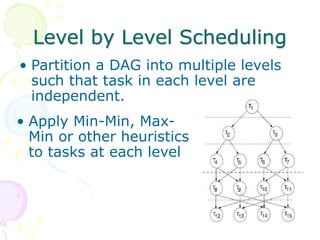
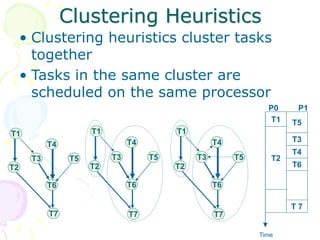


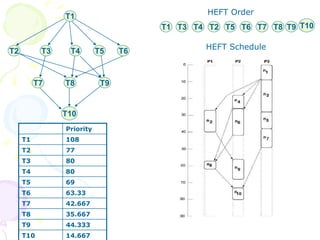


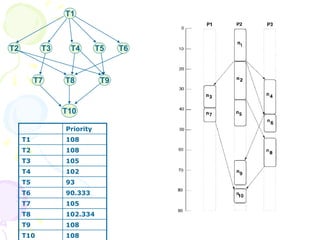


This document discusses scheduling in distributed systems. It covers: 1) Common scheduling techniques like min-min, max-min, and sufferage for scheduling independent tasks on dedicated systems. 2) Scheduling dependent tasks modeled as directed acyclic graphs (DAGs) using techniques like critical path on a processor (CPOP) and heterogeneous earliest finish time (HEFT). 3) The need for scheduling algorithms to adapt to dynamic grid environments where tasks may have dependencies on shared files and network transfer times vary.



































































