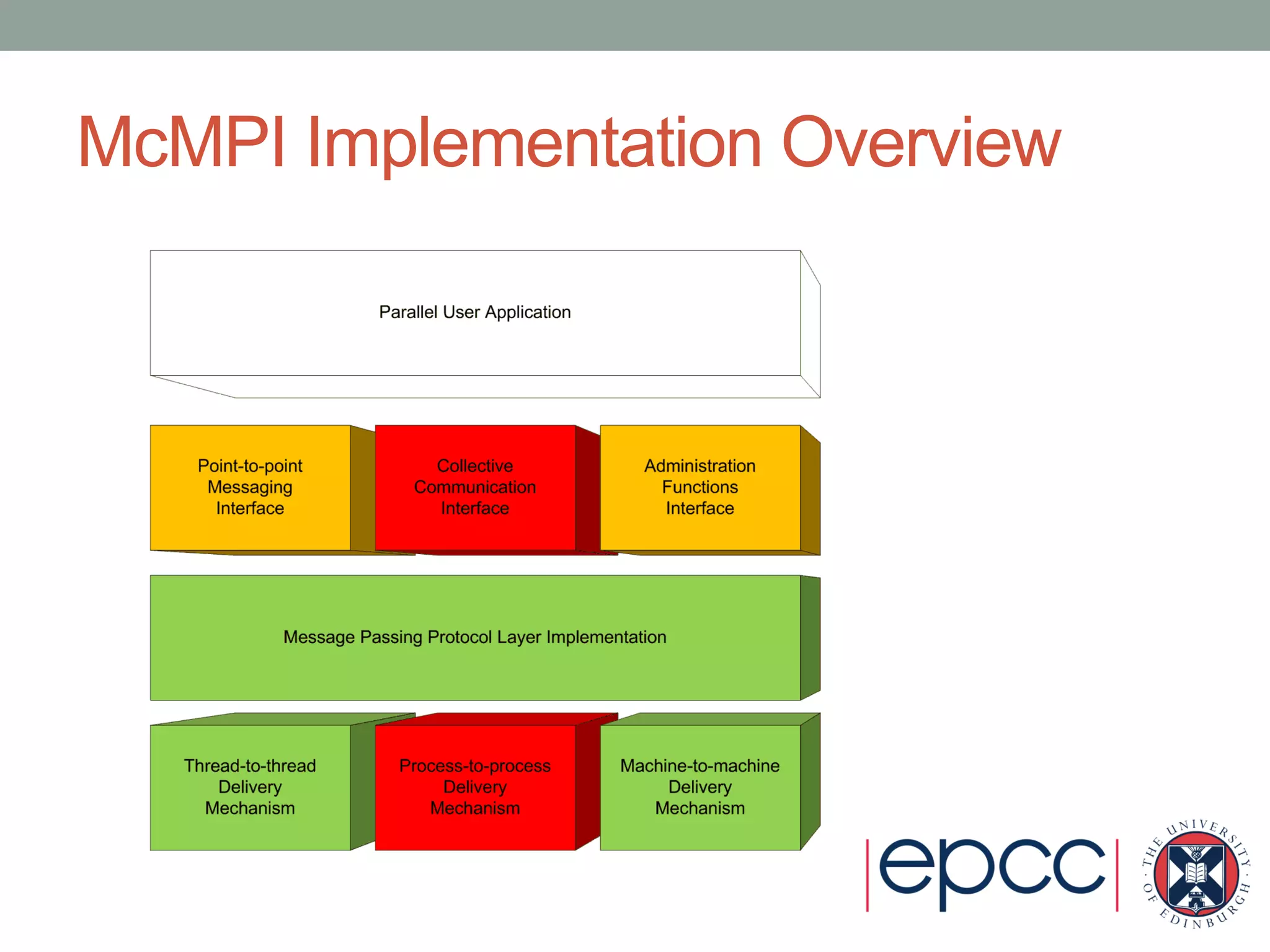
- McMPI is a managed-code (C#) MPI library that was implemented to remove overhead of inter-language function calls compared to using existing C-based MPI libraries in other languages like C++.
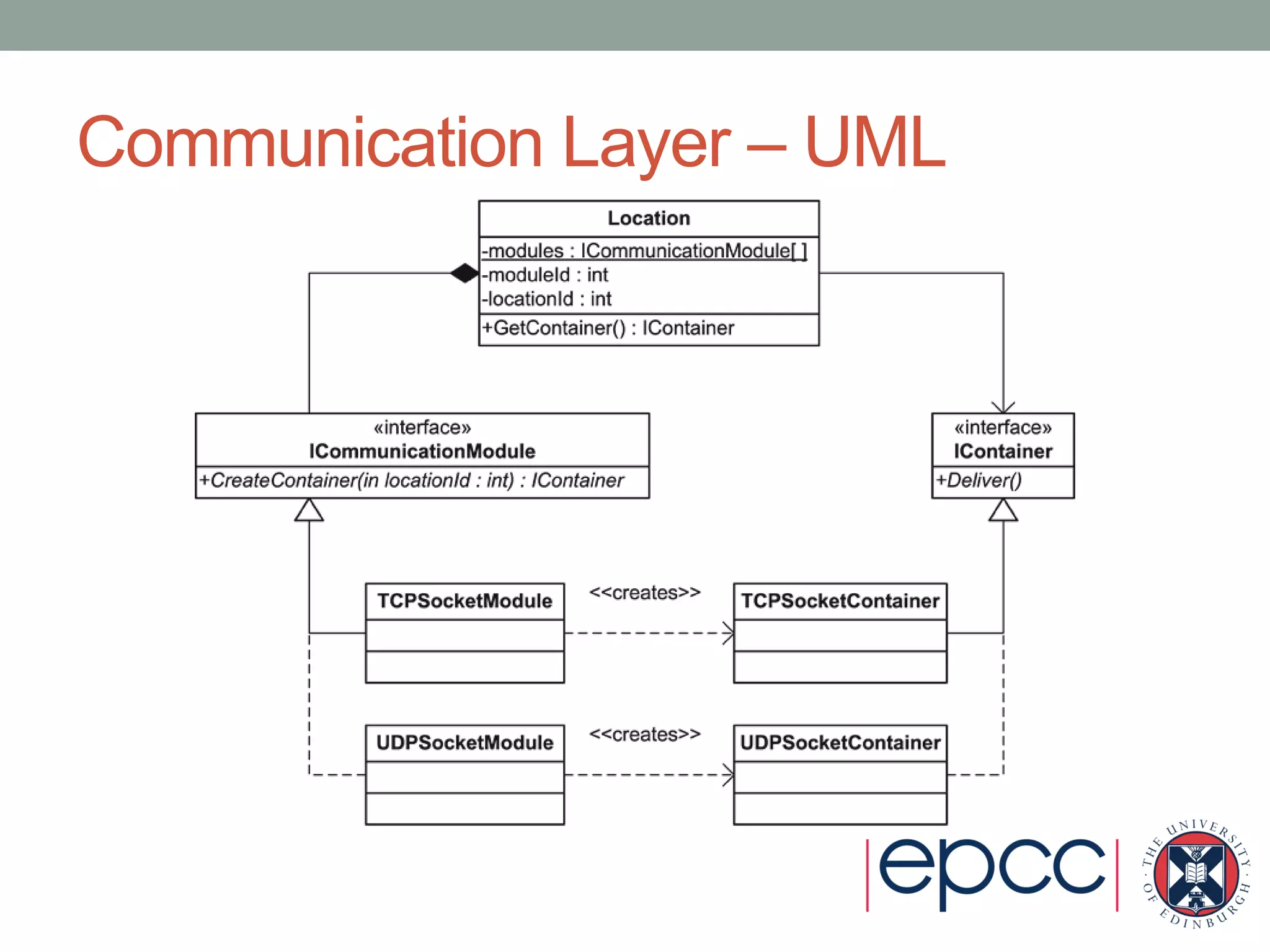
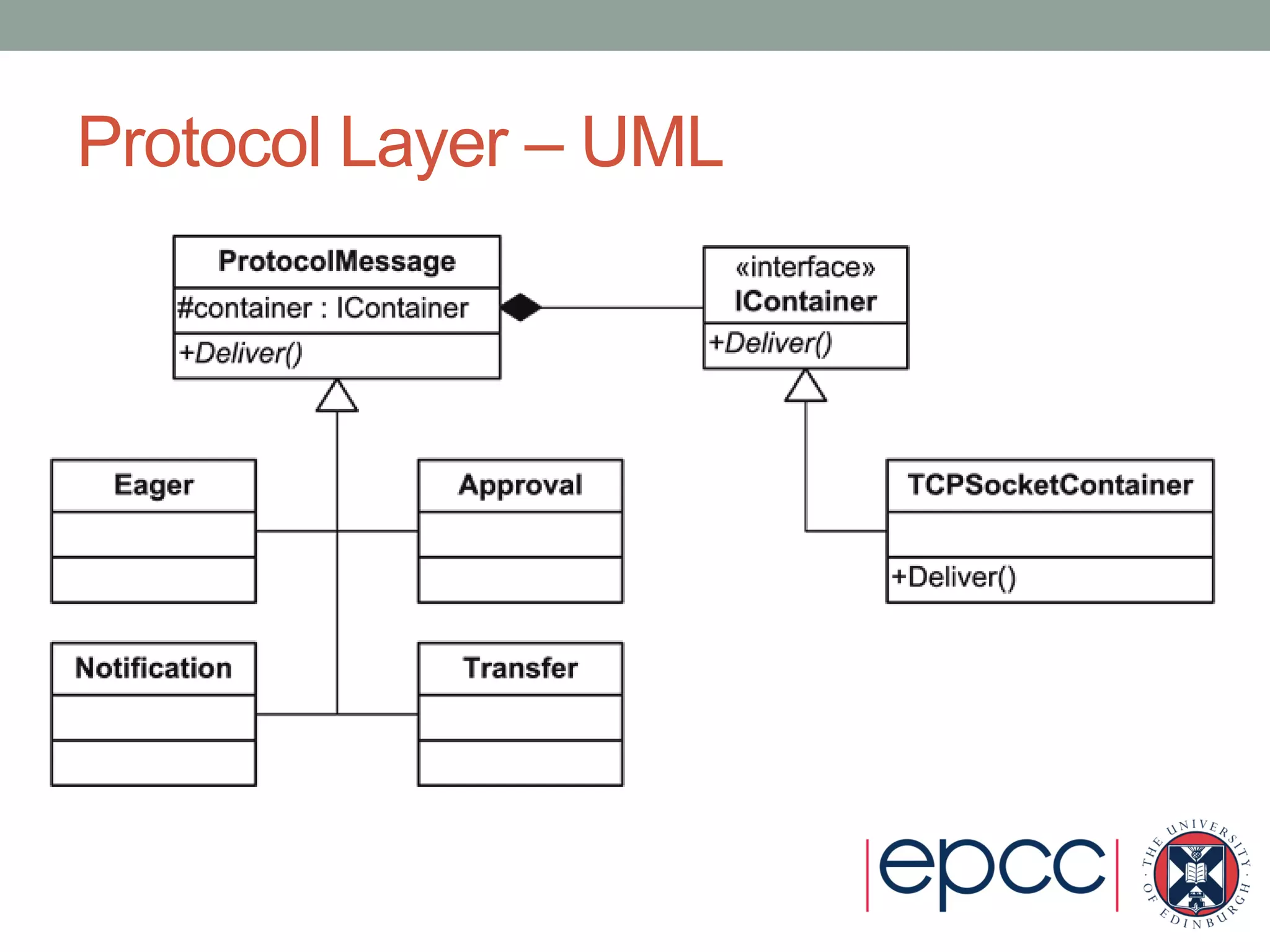
- It uses object-oriented design patterns like abstract factory and bridge to isolate concerns and enable extensibility.
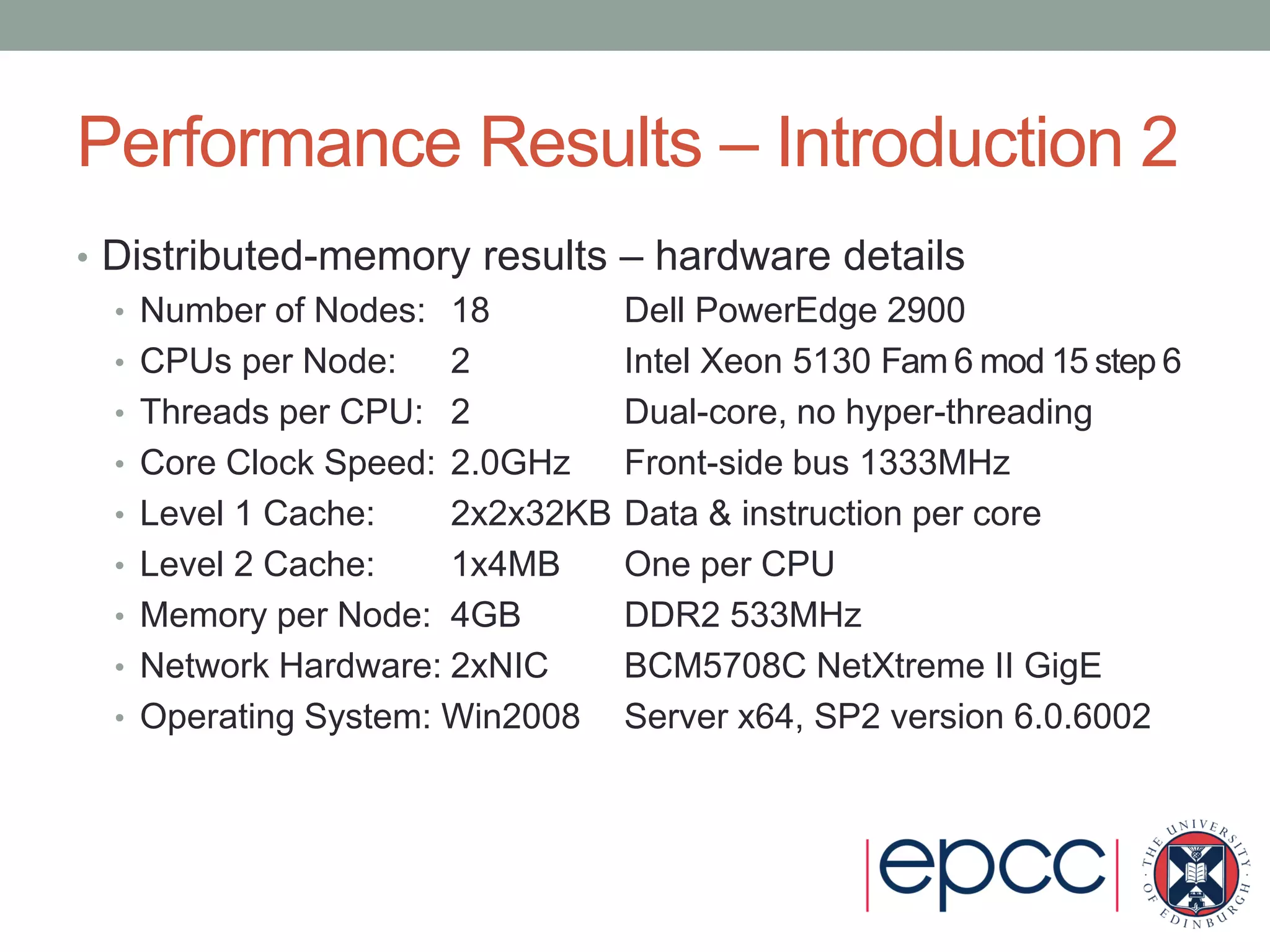
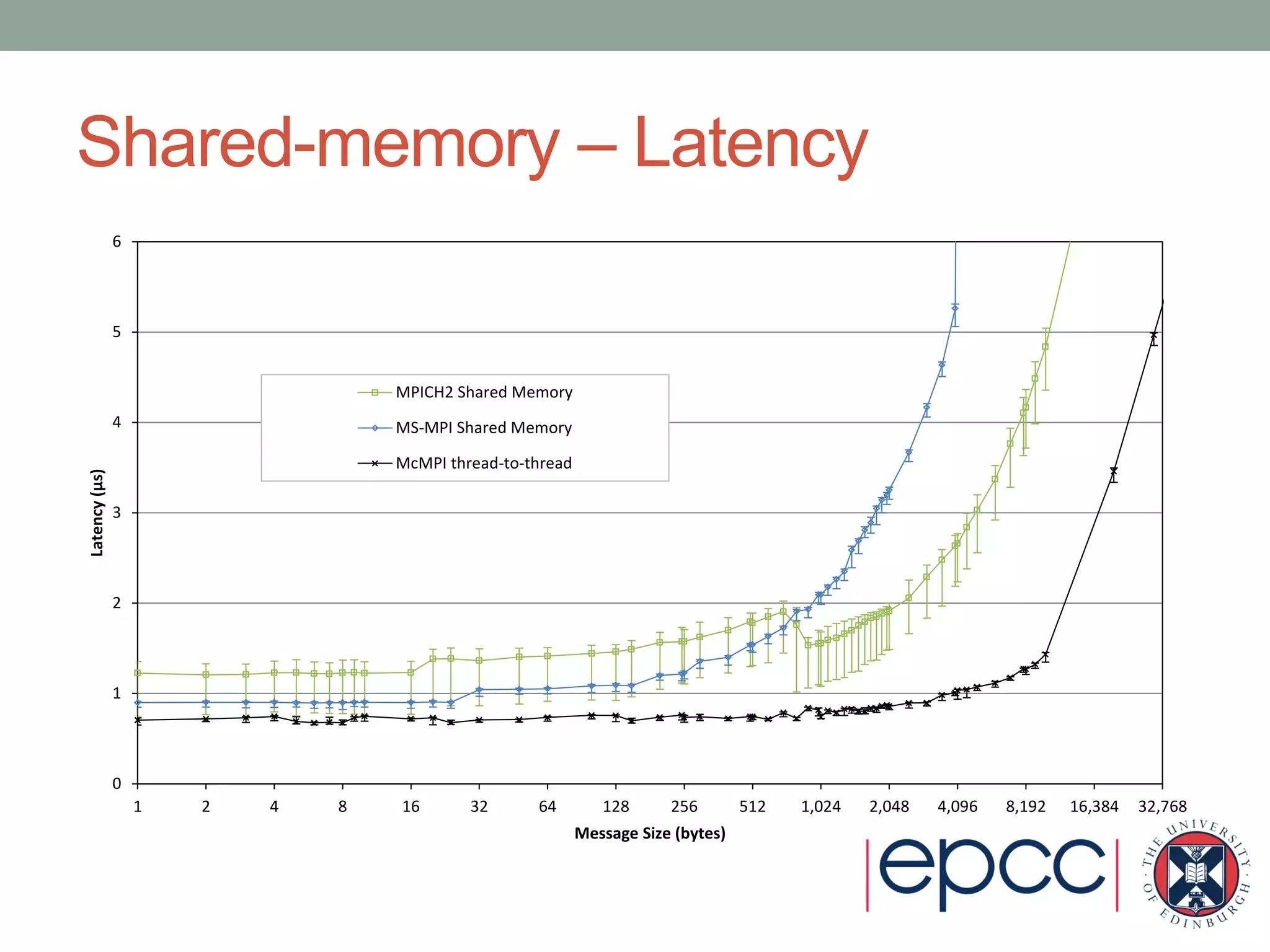
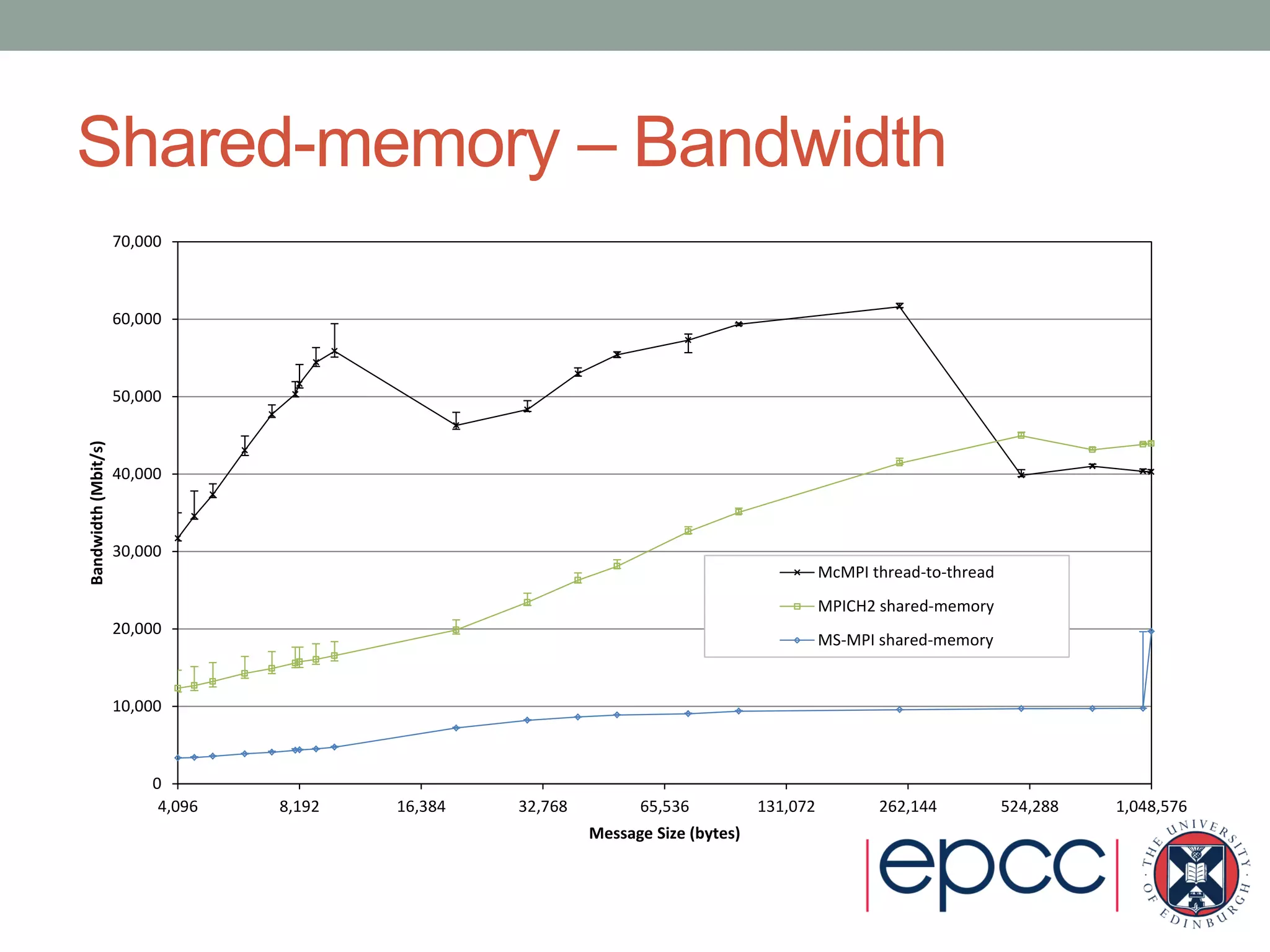
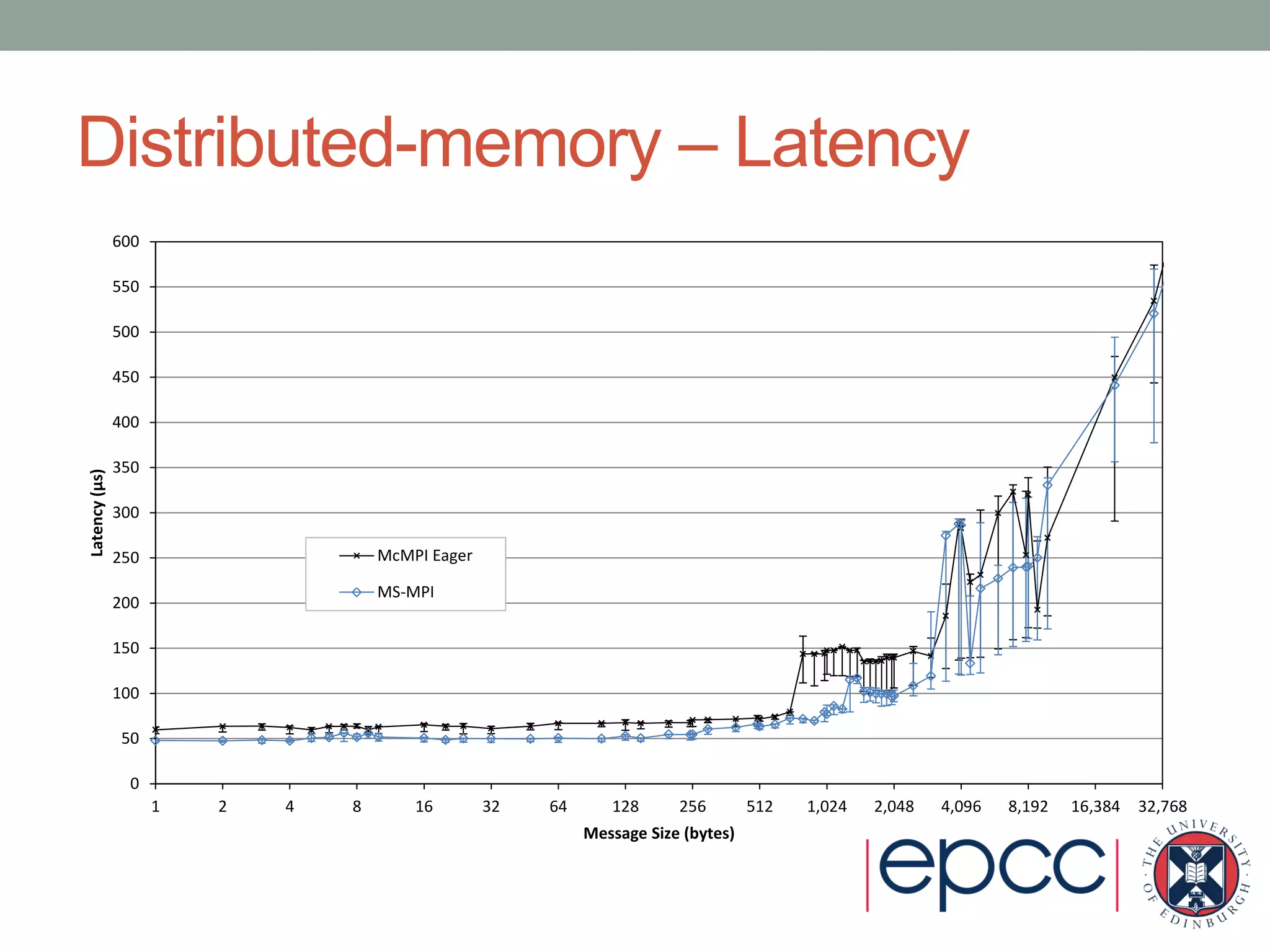
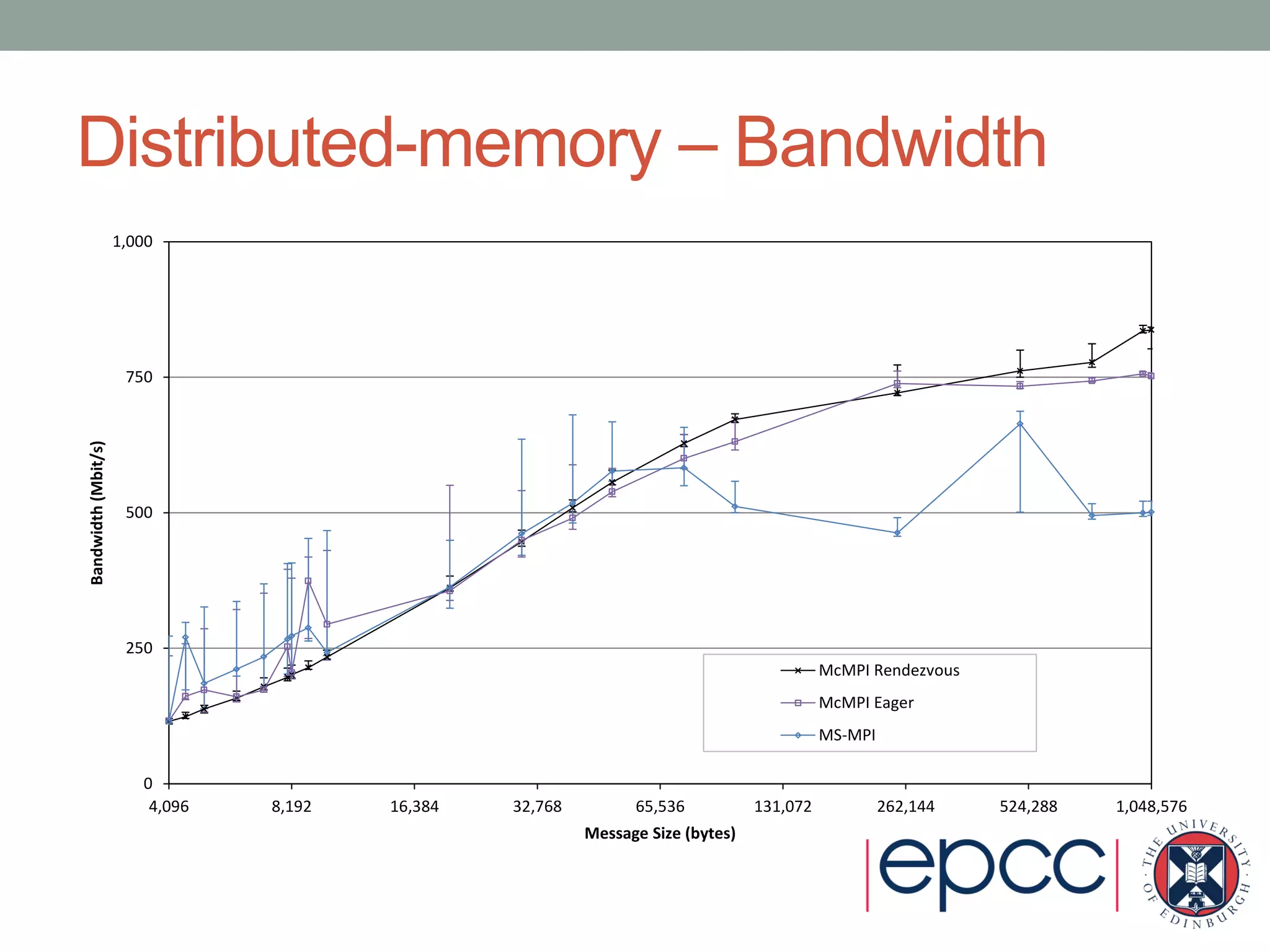
- Performance results show its shared-memory latency and bandwidth is comparable to other MPI implementations, while its distributed-memory latency is higher but bandwidth is comparable.
















![[HK Roni] C Programming Lectures](https://cdn.slidesharecdn.com/ss_thumbnails/00-210225054412-thumbnail.jpg?width=640&height=640&fit=bounds)



















































