Download as PDF, PPTX




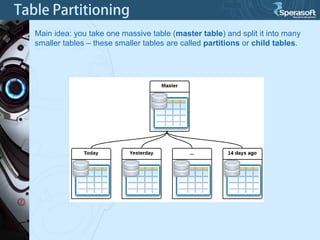






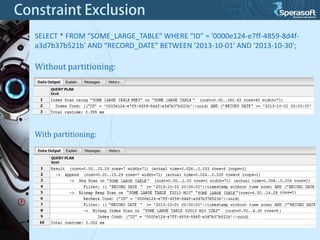




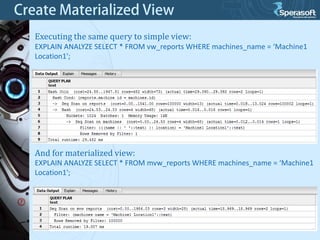
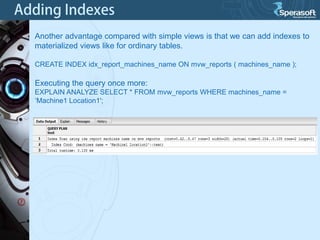
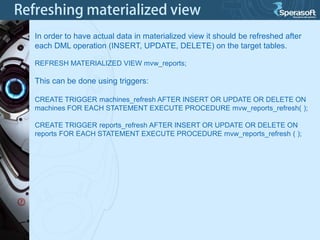


Table partitioning and aggregated data tables (such as materialized views) are two approaches to improve PostgreSQL database performance as data volumes grow large over time. Table partitioning involves splitting a large table into multiple smaller tables (partitions) based on a partition function and key, while aggregated data tables pre-compute query results to avoid repeated computation. Both can improve query performance but come with caveats such as increased planning time for partitions or expensive refresh costs for materialized views. The best approach depends on each unique situation and data access patterns.









































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

