1. 발표자 소개
윤성재(공작명왕, gongjak@gmail.com )
리눅스 엔지니어,
Service Administrator,
Database 운영 Administrator
Cloud Solutions Architecture (AWS / GCP)
1984년 Apple II 와 만남
1994년 Linux (Slackware)와 만남
1997년 070 서비스 개발자로 IT 업무 시작
2009년 DBA로 업무 시작
2013년 Cloud 세상에 첫걸음 (AWS/GCP)
2015년 PostgreSQL을 실제 서비스에 처음 적용해 봄
2016년 처음으로 책을 써 봄
2018년 Cassandra로 No SQL 운영
2020년 GCP Solutions Architect로 근무 중
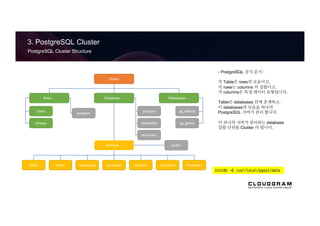
3. PostgreSQL Cluster
PostgreSQLCluster Structure
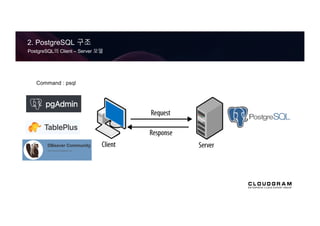
- PostgreSQL 공식 문서 :
각 Table은 rows의 모음이고,
각 rows는 columns 의 집합이고,
각 columns은 특정 데이터 유형입니다.
Table은 databases 안에 존재하고,
이 databases의 모음을 하나의
PostgreSQL 서버가 관리 합니다.
이 하나의 서버가 관리하는 database
집합 단위를 Cluster 라 합니다.
initdb -D /usr/local/pgsql/data
8.
3. PostgreSQL Cluster
Roles
•Roles는 Users/Groups를 모두 포괄하는 개념
• PostgreSQL 8.1 이전 버전에서는 사용자와
그룹이 별개의 개체였지만 이후에 Role로 통합됨.
• 유저 생성, 그룹 생성, 권한 부여 등이 모두 role
기반
• 설정 방법에 따라 사용자 또는 그룹으로 가능
• 모든 Role은 사용자, 그룹 또는 둘 다의 역할을 할
수 있습니다.
• 처음 설치 시 기본으로 postgres 유저가 생성됨
du
du+
SELECT * FROM pg_user;
9.
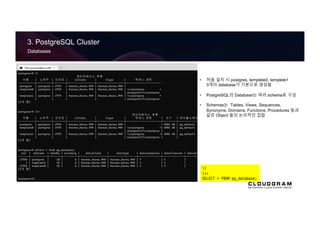
3. PostgreSQL Cluster
Databases
•처음 설치 시 postgres, templete0, templete1
3개의 database가 기본으로 생성됨
• PostgreSQL의 Database는 여러 schema로 구성
• Schemas는 Tables, Views, Sequences,
Synonyms, Domains, Functions, Procedures 등과
같은 Object 들의 논리적인 집합
l
l+
SELECT * FROM pg_database;
10.
3. PostgreSQL Cluster
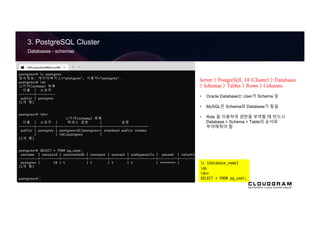
Databases- schemas
Server > PostgreSQL 14 (Cluster) > Databases
> Schemas > Tables > Rows > Columns
• Oracle Database는 User가 Schema 임
• MySQL은 Schema와 Database가 동일
• Role 을 이용하여 권한을 부여할 때 반드시
Database > Schema > Table의 순서로
부여해줘야 함
c {database_name}
dn
dn+
SELECT * FROM pg_user;
11.
3. PostgreSQL Cluster
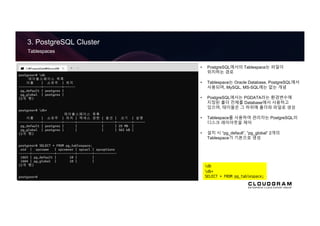
Tablespaces
•PostgreSQL에서의 Tablespace는 파일이
위치하는 경로
• Tablespace는 Oracle Database, PostgreSQL에서
사용되며, MySQL, MS-SQL에는 없는 개념
• PostgreSQL에서는 PGDATA라는 환경변수에
지정된 폴더 전체를 Database에서 사용하고
있으며, 테이블은 그 하위에 폴더와 파일로 생성
• Tablespace를 사용하여 관리자는 PostgreSQL의
디스크 레이아웃을 제어
• 설치 시 “pg_default”, “pg_global” 2개의
Tablespace가 기본으로 생성
db
db+
SELECT * FROM pg_tablespace;
12.
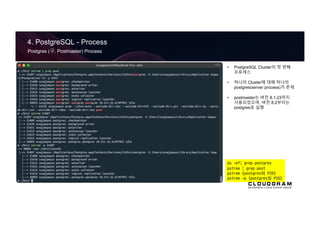
4. PostgreSQL -Process
Basic Architecture
1. postgres(Daemon) process
2. Background(Utility) process
3. Backend process
4. Client process
Client postgres
(구.Postmaster)
Backend
Processes
Shared Memory
Shared Buffers
WAL Buffers
CLOG Buffers Temp Buffers
Other Buffers
Physical Files
Background(Utility) Processes
Writer
Check
pointer
WAL
Writer
Archiver
Process
Logging
Collector
Stats
Collector
Autovacuum
Launcher
WAL Files
Data Files
Log Files
Archive Files
fork()
참조: https://dbsguru.com/postgresql-architecture-process/
13.
4. PostgreSQL -Process
Postgres (구. Postmaster) Process
• PostgreSQL Cluster의 첫 번째
프로세스
• 하나의 Cluster에 대해 하나의
postgres(server process)가 존재
• postmaster는 버전 8.1.23까지
사용되었으며, 버전 8.2부터는
postgres로 실행
ps -ef| grep postgres
pstree | grep post
pstree {postgres의 PID}
pstree -p {postgres의 PID}
14.
4. PostgreSQL -Process
Background (Utility) Processes
• Logging Collector
stderr로 전송된 로그 메시지를 캡처하고 로그 파일로 재전송
설정 파일의 logging_collector 매개변수로 설정하며, 기본값은 off.
적용을 위해 재시작 필요.
• Stats Collector
DBMS의 세션 정보, 테이블 통계 같은 정보를 수집
통계 정보는 운영중에 pg_stat_tmp 폴더의 파일에 저장하고, DB가
중지되면 pg_stat 폴더로 복사하고, DB가 시작되면 pg_stat 폴더에 있는
것을 pg_stat_tmp 폴더로 복사함.
15버전에서는 이 절차가 사라짐.
• Autovacuum Launcher
Vacuum 이 필요할 때 autovacuum worker를 fork 함
설정 파일의 매개변수 autovacuum 으로 설정하며, 기본값은 on.
• WAL(Write-Ahead Logging) writer
WAL Buffers의 내용을 WAL files에 기록
• Archiver
Archiving 모드일 경우, 재활용할 WAL 파일을 archive_command에서
지정한 방식으로 처리함.
설정 파일의 매개변수 archive_mode 로 설정하며, 기본값은 off.
적용을 위해 재시작 필요.
15.
4. PostgreSQL -Process
Background (Utility) Processes
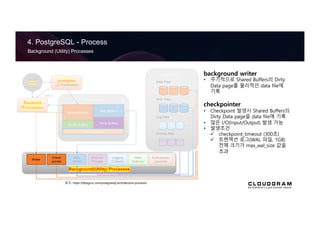
background writer
• 주기적으로 Shared Buffers의 Dirty
Data page를 물리적인 data file에
기록
checkpointer
• Checkpoint 발생시 Shared Buffers의
Dirty Data page을 data file에 기록
• 많은 I/O(Input/Output) 발생 가능
• 발생조건
ü checkpoint_timeout (300초)
ü 트랜잭션 로그(WAL 파일, 1GB)
전체 크기가 max_wal_size 값을
초과
Client postgres
(구.Postmaster)
Backend
Processes
Shared Memory
Shared Buffers
WAL Buffers
CLOG Buffers Temp Buffers
Other Buffers
Physical Files
Background(Utility) Processes
Writer
Check
pointer
WAL
Writer
Archiver
Process
Logging
Collector
Stats
Collector
Autovacuum
Launcher
WAL Files
Data Files
Log Files
Archive Files
fork()
참조: https://dbsguru.com/postgresql-architecture-process/
16.
4. PostgreSQL -Process
Background (Utility) Processes
WAL(Write-Ahead Logging) writer
• WAL Buffers의 내용을 WAL files에
기록
Archiver
• Archiving 모드일 경우, 재활용할 WAL
파일을 archive_command에서 지정한
방식으로 처리
• 설정 파일의 매개변수 archive_mode
로 설정 (기본값은 off. 적용시 재시작
필요)
Client postgres
(구.Postmaster)
Backend
Processes
Shared Memory
Shared Buffers
WAL Buffers
CLOG Buffers Temp Buffers
Other Buffers
Physical Files
Background(Utility) Processes
Writer
Check
pointer
WAL
Writer
Archiver
Process
Logging
Collector
Stats
Collector
Autovacuum
Launcher
WAL Files
Data Files
Log Files
Archive Files
fork()
참조: https://dbsguru.com/postgresql-architecture-process/
17.
4. PostgreSQL -Process
Background (Utility) Processes
Logging Collector
• stderr로 전송된 로그 메시지를 캡처하고
로그 파일로 재전송
• 설정 파일의 logging_collector 로 설정
(기본값은 off. 변경시 재시작 필요)
Stats Collector
• DBMS의 세션 정보, 테이블 통계 같은
정보를 수집
• DB 운영 중: pg_stat_tmp 폴더의 파일에
저장
• DB가 중지 : pg_stat 폴더로 복사
• DB가 시작 : pg_stat 폴더에 있는 것을
pg_stat_tmp 폴더로 복사
• 15버전에서는 이 절차가 사라짐.
Autovacuum Launcher
• Vacuum 이 필요할 때 autovacuum
worker를 fork 함
• 설정 파일의 매개변수 autovacuum 으로
설정하며, 기본값은 on.
Client postgres
(구.Postmaster)
Backend
Processes
Shared Memory
Shared Buffers
WAL Buffers
CLOG Buffers Temp Buffers
Other Buffers
Physical Files
Background(Utility) Processes
Writer
Check
pointer
WAL
Writer
Archiver
Process
Logging
Collector
Stats
Collector
Autovacuum
Launcher
WAL Files
Data Files
Log Files
Archive Files
fork()
참조: https://dbsguru.com/postgresql-architecture-process/
18.
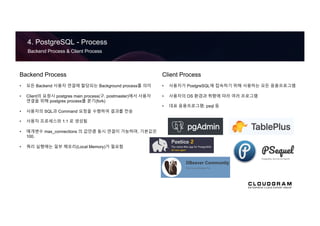
4. PostgreSQL -Process
Backend Process & Client Process
Client Process
• 사용자가 PostgreSQL에 접속하기 위해 사용하는 모든 응용프로그램
• 사용자의 OS 환경과 취향에 따라 여러 프로그램
• 대표 응용프로그램: psql 등
Backend Process
• 모든 Backend 사용자 연결에 할당되는 Background process를 의미
• Client의 요청시 postgres main process(구. postmaster)에서 사용자
연결을 위해 postgres process를 분기(fork)
• 사용자의 SQL과 Command 요청을 수행하여 결과를 전송
• 사용자 프로세스와 1:1 로 생성됨
• 매개변수 max_connections 의 값만큼 동시 연결이 가능하며, 기본값은
100.
• 쿼리 실행에는 일부 메모리(Local Memory)가 필요함
19.
5. PostgreSQL –Memory
Memory Components of PostgreSQL
Shared Memory
Shared Buffers
WAL Buffers
CLOG Buffers
Lock Space
Other Buffers
Per backend memory
Maintanance_work_mem
temp_Buffer
work_mem
catalog_cache
Optimizer / executor
OS Cache
PostgreSQL 메모리 구성요소 2가지
Share Memory
• 데이터베이스의 캐싱 및 트랜잭션 로그 캐싱을
위해 예약된 메모리
• 모든 프로세스가 공유하여 사용하는 공간
• 설정(config)의 매개변수 4개 영역
ü Shared Buffers
ü WAL(Write-Ahead Logging) Buffers
ü Clog(Commit log) Buffer
ü Lock Space (Memory for Locks)
Backend Memory (Process Memory)
• Backend process가 요청 받은 Query를 실행하기
위한 메모리( = Local Memory )
• 설정(config)의 매개변수
ü work_mem(기본값 4MB)
ü Maintenance_work_mem(기본값 64MB)
ü temp_buffers(기본값 8MB)
20.
6. PostgreSQL –File Layout
환경변수 PGDATA에 의해 저장됨
아이템 설명
PG_VERSION PostgreSQL 의 major 버전 번호가 포함된 파일
base 데이터베이스별 하위 디렉터리를 포함하는 하위 디렉터리
current_logfiles 로깅 수집기가 현재 기록한 로그 파일을 기록하는 파일
global pg_database와 같은 클러스터 전체 테이블을 포함하는 하위 디렉토리
pg_commit_ts 트랜잭션 커밋 타임스탬프 데이터가 포함된 하위 디렉터리
pg_dynshmem 동적 공유 메모리 하위 시스템에서 사용하는 파일을 포함하는 하위 디렉터리
pg_logical 논리적 디코딩을 위한 상태 데이터를 포함하는 하위 디렉토리
pg_multixact 다중 트랜잭션 상태 데이터를 포함하는 하위 디렉터리 (공유 행 잠금에 사용됨)
pg_notify LISTEN/NOTIFY 상태 데이터를 포함하는 하위 디렉토리
pg_replslot 복제 슬롯 데이터를 포함하는 하위 디렉토리
pg_serial 커밋된 직렬화 가능한 트랜잭션에 대한 정보를 포함하는 하위 디렉토리
pg_snapshots 내보낸 스냅샷이 포함된 하위 디렉토리
21.
6. PostgreSQL –File Layout
환경변수 PGDATA에 의해 저장됨
아이템 설명
pg_stat 통계 하위 시스템에 대한 영구 파일을 포함하는 하위 디렉터리
pg_stat_tmp 통계 하위 시스템에 대한 임시 파일을 포함하는 하위 디렉토리
pg_subtrans 하위 트랜잭션 상태 데이터를 포함하는 하위 디렉토리
pg_tblspc 테이블스페이스에 대한 심볼릭 링크를 포함하는 하위 디렉토리
pg_twophase 준비된 트랜잭션에 대한 상태 파일을 포함하는 하위 디렉토리
pg_wal WAL(Write Ahead Log) 파일을 포함하는 하위 디렉토리
pg_xact 트랜잭션 커밋 상태 데이터를 포함하는 하위 디렉터리
postgresql.auto.conf ALTER SYSTEM에서 설정한 구성 매개변수를 저장하는 데 사용되는 파일
postmaster.opts 서버가 마지막으로 시작된 명령줄 옵션을 기록하는 파일
postmaster.pid
현재 포스트마스터 프로세스 ID(PID), 클러스터 데이터 디렉토리 경로, 포스트마스터
시작 타임스탬프, 포트 번호, Unix 도메인 소켓 디렉토리 경로(비어 있을 수 있음), 첫
번째 유효한 listen_address(IP 주소 또는 *, 그렇지 않은 경우 비어 있음)를 기록하는
잠금 파일 TCP에서 수신 대기) 및 공유 메모리 세그먼트 ID(이 파일은 서버 종료 후
존재하지 않음)
22.
[참고] PostgreSQL 15:Stats Collector Gone?
이제 통계 수집기가 사라졌습니다.
What?
• 쿼리 플랜에 사용되는 table-level statistics
collection(ANALYZE)와 혼동하는 기능
• 테이블이나 인덱스가 스캔한 횟수, 테이블에서 마지막 vacuum
또는 autovacuum이 실행된 횟수 등과 같은 누적 통계를 얻기
위해 각 프로세스의 모든 활동을 추적
• pg_stat_* 를 통해 확인
Wrong?
• 세션의 Backend process는 수행한 활동을 UDP 소켓을 통해
전송
ü 오래된 통계
ü 통계 수집기가 실행되지 않음
ü autovacuum이 작동하지 않거나 시작하지 않음
• pg_stat_tmp 폴더에 대량의 IO가 발생할 수 있음
New
• PostgreSQL 15에서 통계는 파일과 파일 시스템 대신 동적
공유 메모리를 사용
• 이제 통계 수집기는 제거 대상임
• 참조 : Andres Freund의 commit 내용
(https://git.postgresql.org/gitweb/?p=postgresql.git;h=5891c7a
8e)
• 재 시작시 종료 직전에 체크포인터 프로세스에 의해 파일
시스템에 기록되고 시작 프로세스에 의해 시작하는 동안 다시
로드됨.
• 충돌이 발생하면 통계가 삭제됨
Getting Better
• 통계 수집기의 오버헤드와 유지관리가 사라지면서
autovacuum과 같은 하위 시스템의 할 일이 줄어듬
• 통계 정보를 자주 조회하는 모니터링 도구는 시스템 부하를
훨씬 덜 유발할 것으로 예상됨













![[참고] PostgreSQL 15: Stats Collector Gone?
이제 통계 수집기가 사라졌습니다.
What?
• 쿼리 플랜에 사용되는 table-level statistics
collection(ANALYZE)와 혼동하는 기능
• 테이블이나 인덱스가 스캔한 횟수, 테이블에서 마지막 vacuum
또는 autovacuum이 실행된 횟수 등과 같은 누적 통계를 얻기
위해 각 프로세스의 모든 활동을 추적
• pg_stat_* 를 통해 확인
Wrong?
• 세션의 Backend process는 수행한 활동을 UDP 소켓을 통해
전송
ü 오래된 통계
ü 통계 수집기가 실행되지 않음
ü autovacuum이 작동하지 않거나 시작하지 않음
• pg_stat_tmp 폴더에 대량의 IO가 발생할 수 있음
New
• PostgreSQL 15에서 통계는 파일과 파일 시스템 대신 동적
공유 메모리를 사용
• 이제 통계 수집기는 제거 대상임
• 참조 : Andres Freund의 commit 내용
(https://git.postgresql.org/gitweb/?p=postgresql.git;h=5891c7a
8e)
• 재 시작시 종료 직전에 체크포인터 프로세스에 의해 파일
시스템에 기록되고 시작 프로세스에 의해 시작하는 동안 다시
로드됨.
• 충돌이 발생하면 통계가 삭제됨
Getting Better
• 통계 수집기의 오버헤드와 유지관리가 사라지면서
autovacuum과 같은 하위 시스템의 할 일이 줄어듬
• 통계 정보를 자주 조회하는 모니터링 도구는 시스템 부하를
훨씬 덜 유발할 것으로 예상됨](https://image.slidesharecdn.com/pgday2022-postgresql-20221112-221114014106-bbfb1955/85/pgday-Seoul-2022-PostgreSQL-22-320.jpg)

![[Pgday.Seoul 2020] SQL Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-201117134901-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)



![[오픈소스컨설팅]RHEL7/CentOS7 Pacemaker기반-HA시스템구성-v1.0](https://cdn.slidesharecdn.com/ss_thumbnails/rhel-centos7-pacemaker-based-ha-admin-guidev1-151215000535-thumbnail.jpg?width=640&height=640&fit=bounds)


![[pgday.Seoul 2022] 서비스개편시 PostgreSQL 도입기 - 진소린 & 김태정](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql-221121085744-f0fb1a8a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[pgday.Seoul 2022] POSTGRES 테스트코드로 기여하기 - 이동욱](https://cdn.slidesharecdn.com/ss_thumbnails/postgres-221114014538-b9df2ddf-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2021] 1. 예제로 살펴보는 포스트그레스큐엘의 독특한 SQL](https://cdn.slidesharecdn.com/ss_thumbnails/sql-211217063145-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 2. PostgreSQL을 위한 리눅스 커널 최적화 - 김상욱](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106040432-thumbnail.jpg?width=640&height=640&fit=bounds)






![[pgday.Seoul 2022] PostgreSQL with Google Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-postgresqlwithgooglecloud-221114013605-5def484f-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Pgday.Seoul 2018] 이기종 DB에서 PostgreSQL로의 Migration을 위한 DB2PG](https://cdn.slidesharecdn.com/ss_thumbnails/04-pgdaydb2pgv1-181112042107-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Pgday.Seoul 2021] 2. Porting Oracle UDF and Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/oracleudfmigration20211203-211227052428-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Pgday.Seoul 2017] 8. PostgreSQL 10 새기능 소개 - 김상기](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-seoul-2017-pg10-new-features-171106041845-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 7. PostgreSQL DB Tuning 기업사례 - 송춘자](https://cdn.slidesharecdn.com/ss_thumbnails/cjsongpostgresqldbtuningexam-20171102-171106043044-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Foss4 g2013 korea]postgis와 geoserver를 이용한 대용량 공간데이터 기반 일기도 서비스 구축 사례](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2013koreapostgisgeoserver-140325221011-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/231-171017003147-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Pgday.Seoul 2018] replacing oracle with edb postgres](https://cdn.slidesharecdn.com/ss_thumbnails/01-replacingoraclewithedbpostgres20181023-181112040354-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] PostgreSQL 11 새 기능 소개](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2018-pg11-181112042714-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Pgday.Seoul 2017] 3. PostgreSQL WAL Buffers, Clog Buffers Deep Dive - 이근오](https://cdn.slidesharecdn.com/ss_thumbnails/pgday171104-171106041604-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2019] Citus를 이용한 분산 데이터베이스](https://cdn.slidesharecdn.com/ss_thumbnails/citus20191207studypgday-191218045308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 6. GIN vs GiST 인덱스 이야기 - 박진우](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106044702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 1. PostGIS의 사례로 본 PostgreSQL 확장 - 장병진](https://cdn.slidesharecdn.com/ss_thumbnails/postgispostgresqlpgday2017-171103060406-171106044046-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] Greenplum의 노드 분산 설계](https://cdn.slidesharecdn.com/ss_thumbnails/02-20181103pgdayseminarv1-181112041352-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] PostgreSQL 성능을 위해 개발된 라이브러리 OS 소개 apposha](https://cdn.slidesharecdn.com/ss_thumbnails/06-pgdayseoul2018sangwook-181112042505-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Pgday.Seoul 2018] AWS Cloud 환경에서 PostgreSQL 구축하기](https://cdn.slidesharecdn.com/ss_thumbnails/03-pgday-flytothecloudkimdongsu-181112041825-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Pgday.Seoul 2019] Advanced FDW](https://cdn.slidesharecdn.com/ss_thumbnails/tarantulav2-191218044914-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] PostgreSQL Authentication with FreeIPA](https://cdn.slidesharecdn.com/ss_thumbnails/05-20181103pgdayseoulpostgresqlauthenticationwithfreeipa-181112042327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 5. 테드폴허브(올챙이) PostgreSQL 확장하기 - 조현종](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql-171106044405-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2019] AppOS 고성능 I/O 확장 모듈로 성능 10배 향상시키기](https://cdn.slidesharecdn.com/ss_thumbnails/appos-2019-191218045825-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2020] 포스트그레스큐엘 자국어화 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/postgresqli18nko-201117135339-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 4. Composite Type/JSON 파라미터를 활용한 TVP구현(with C#, JAVA) - 지현명](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106042708-thumbnail.jpg?width=640&height=640&fit=bounds)