


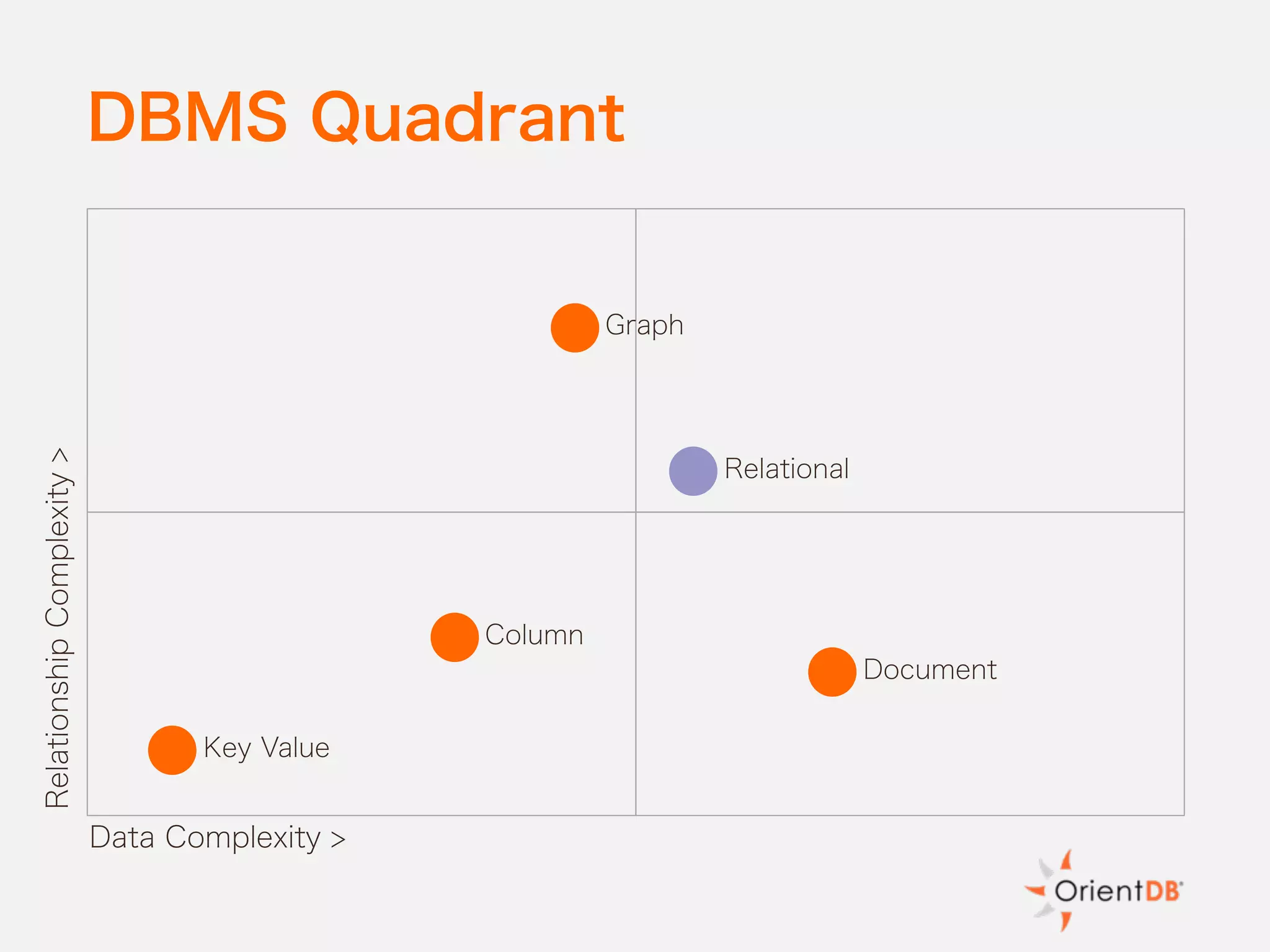

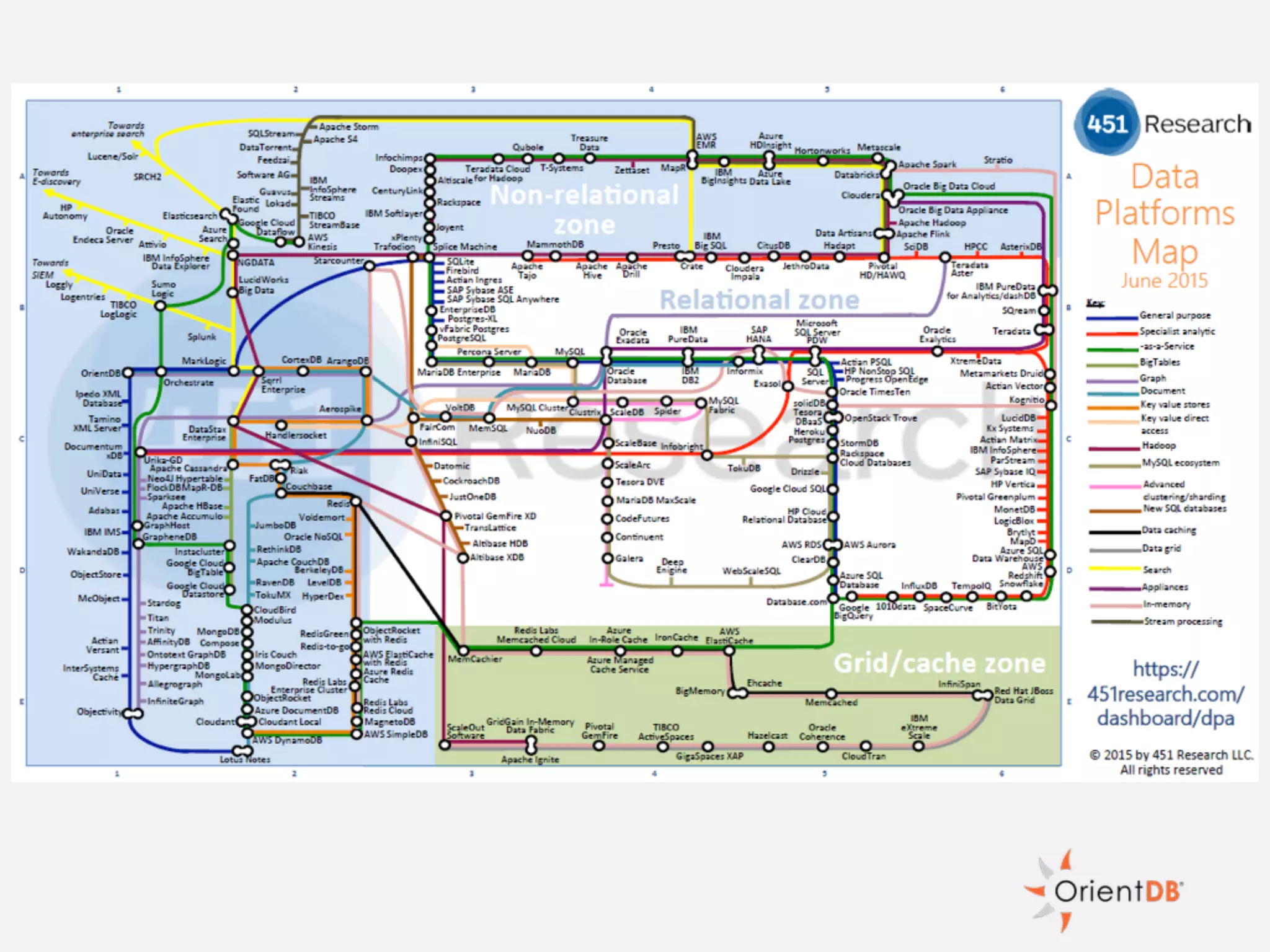

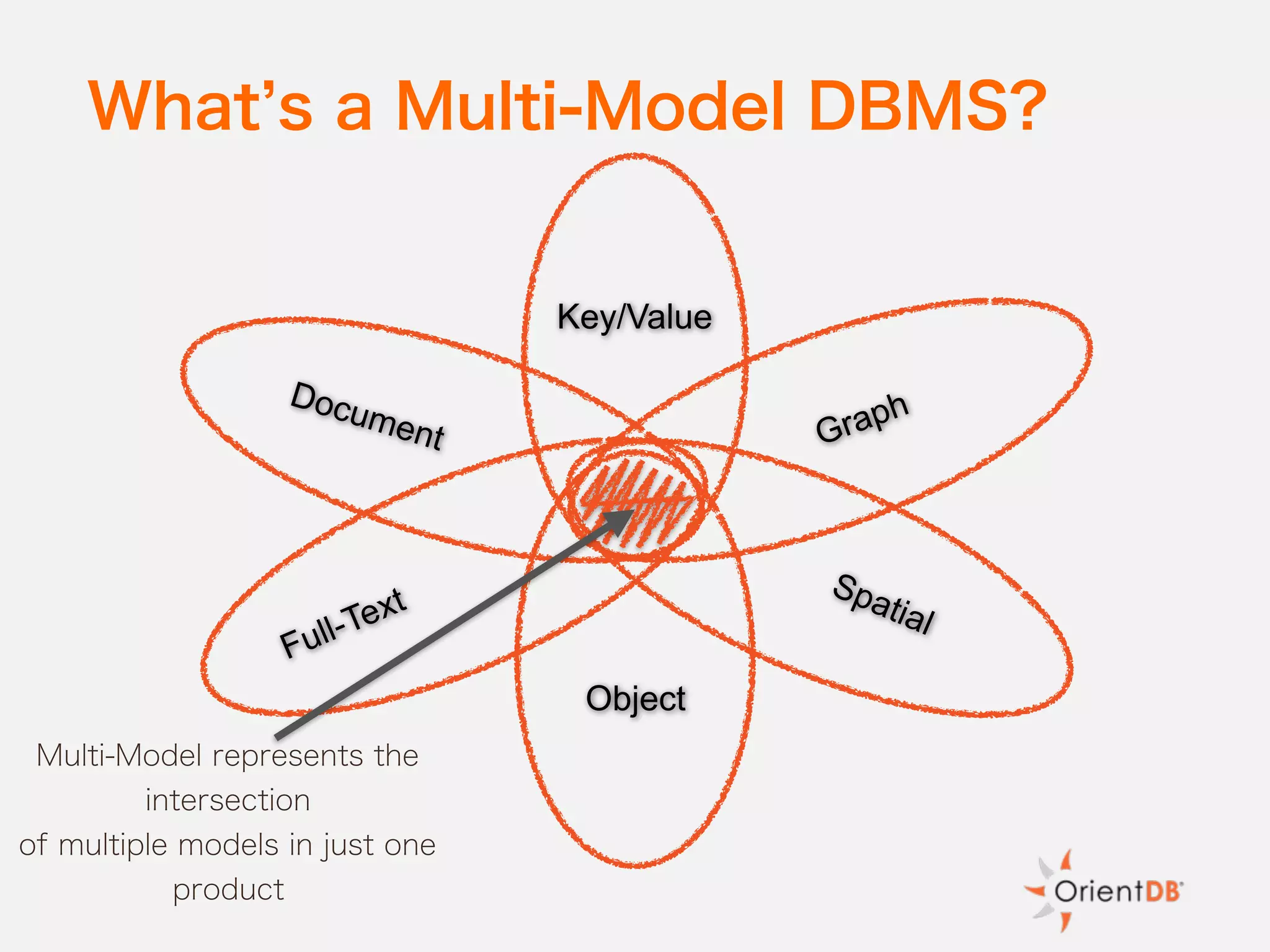
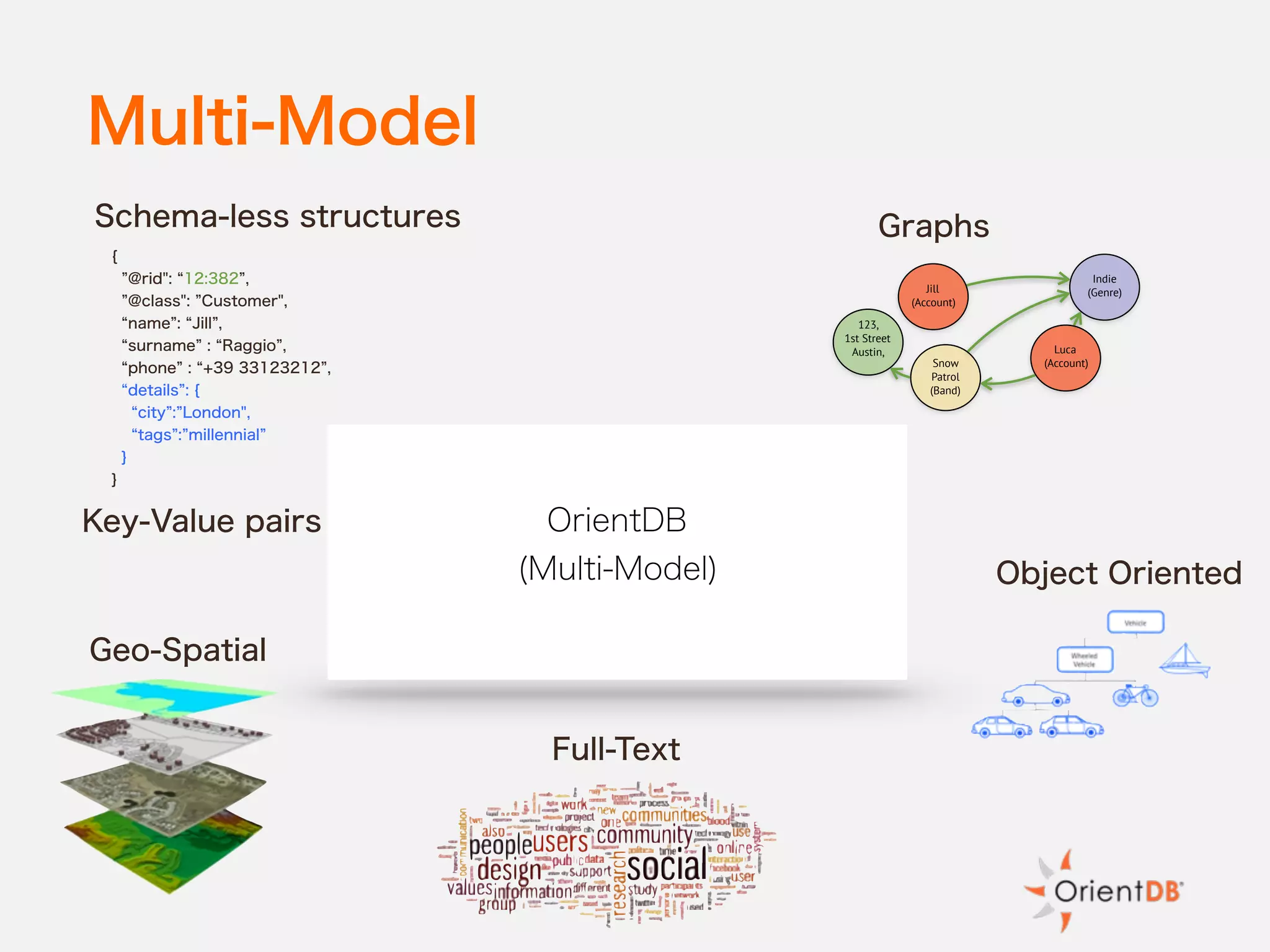
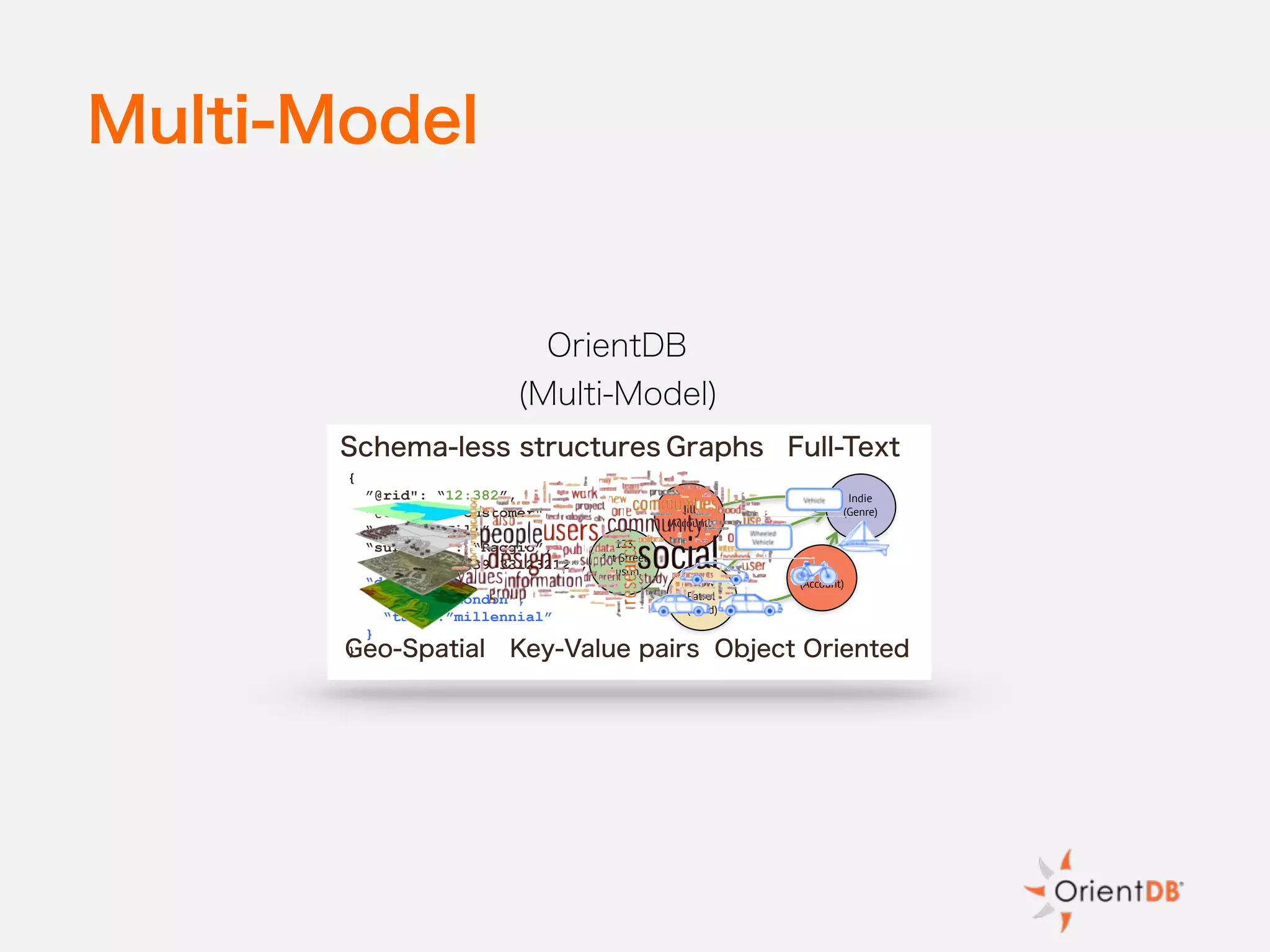
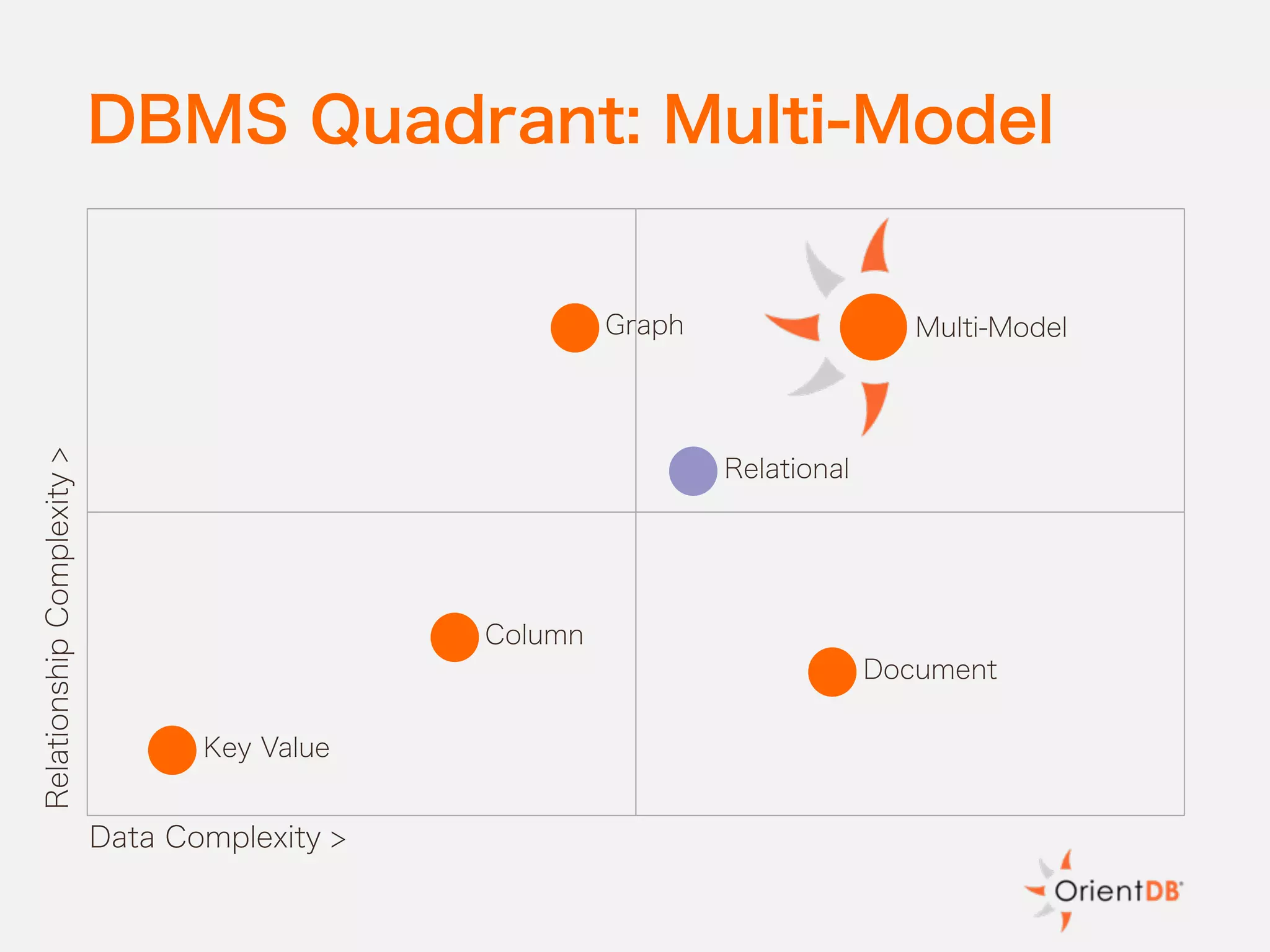


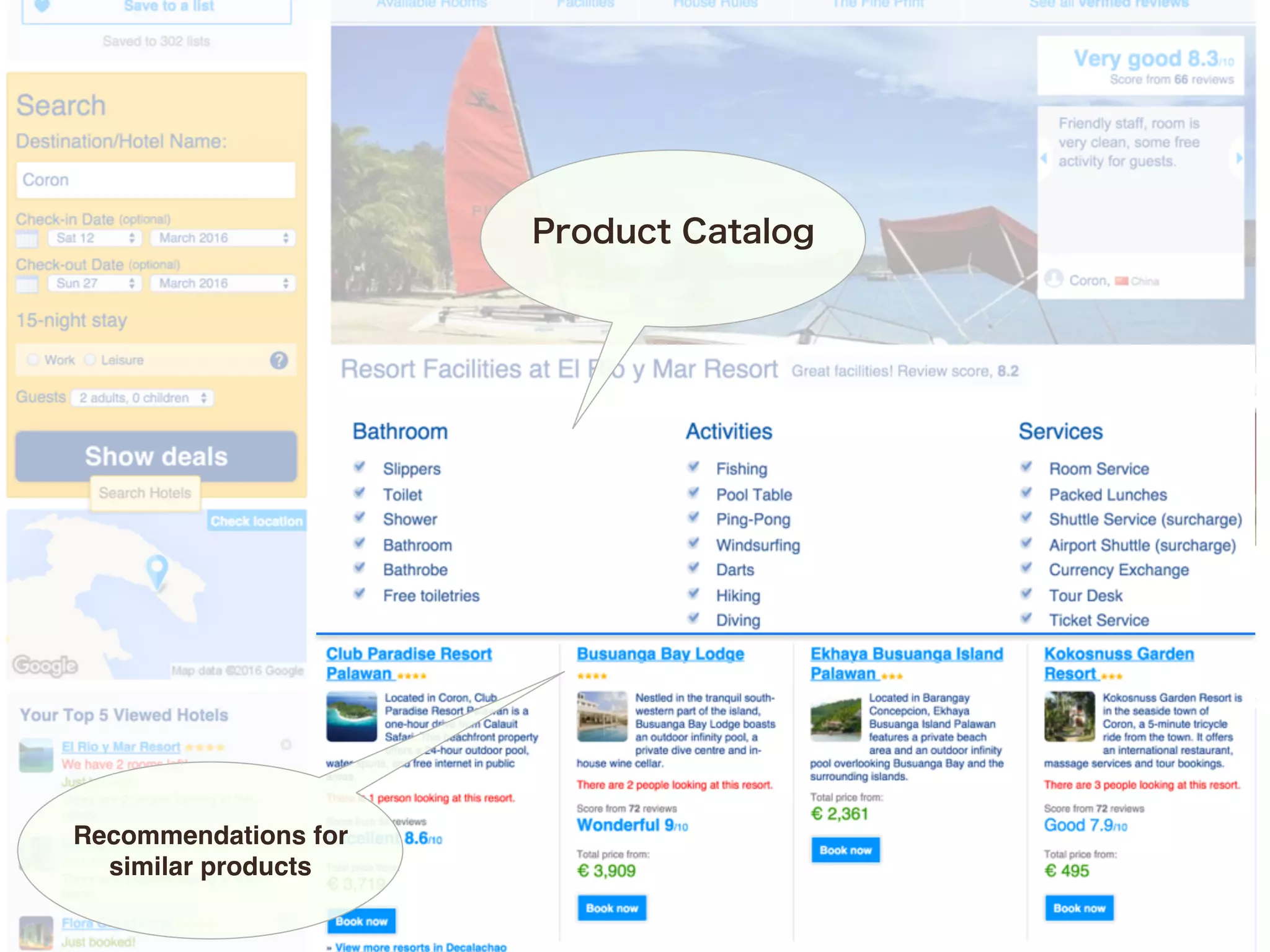
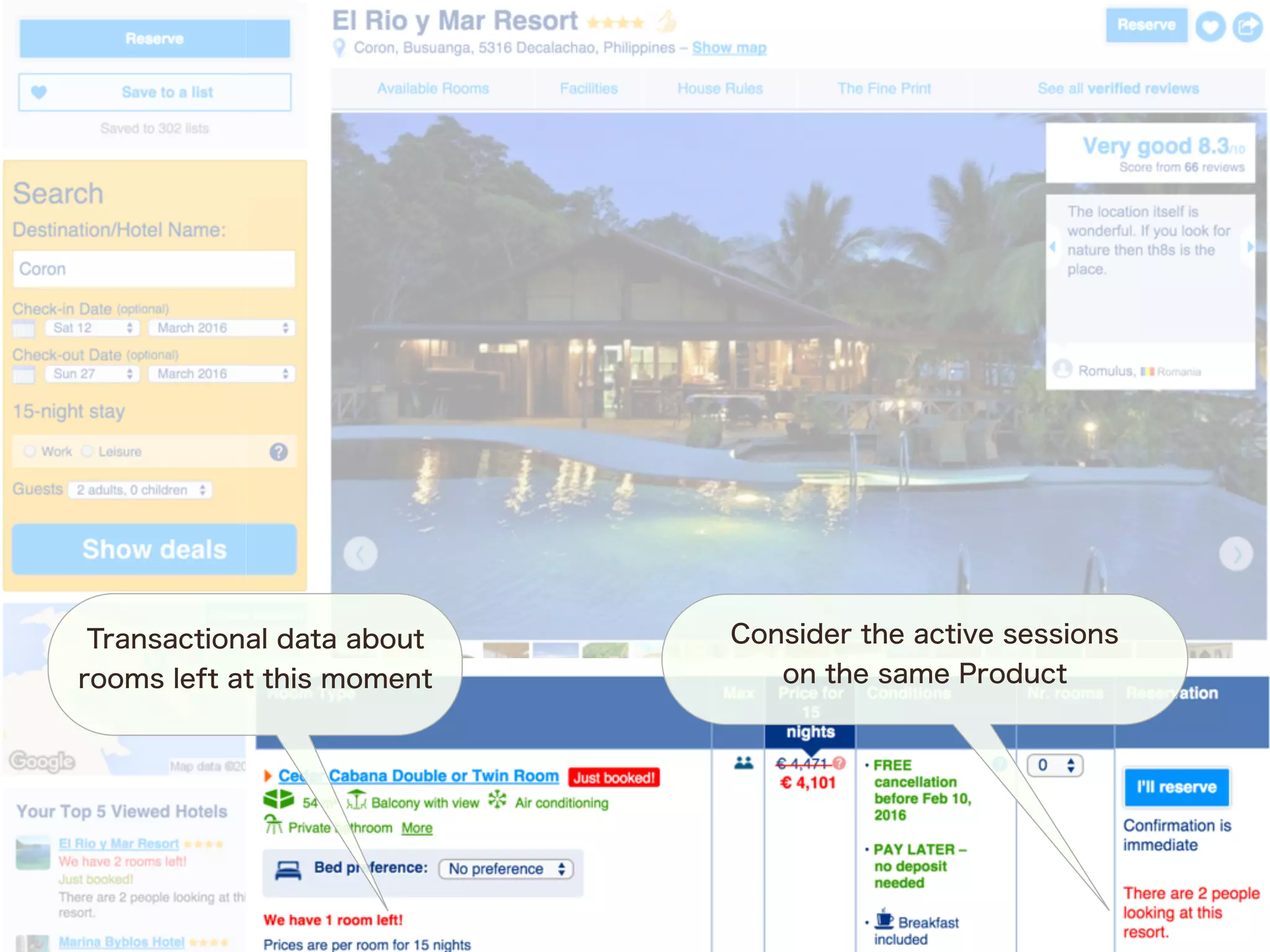



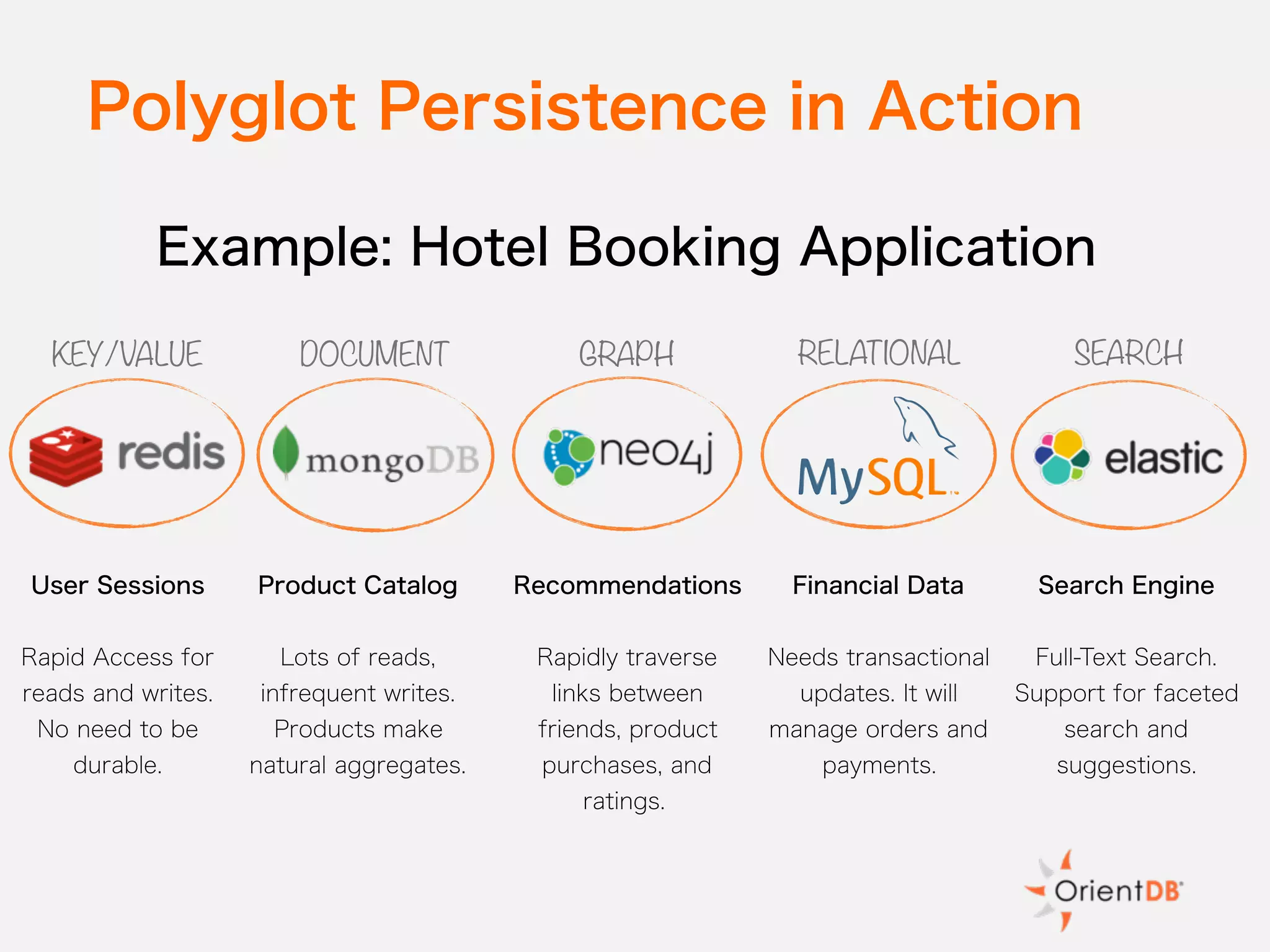
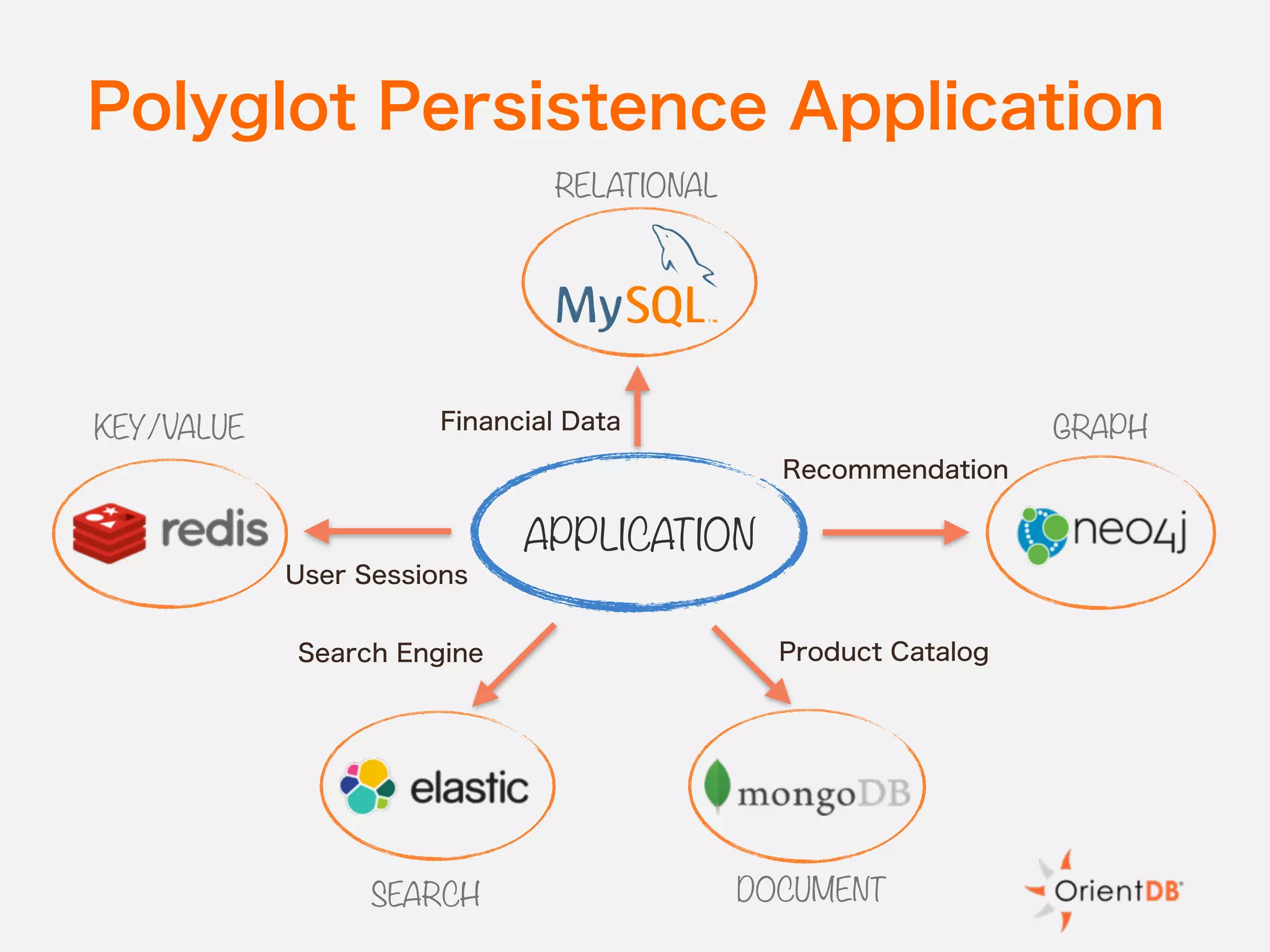
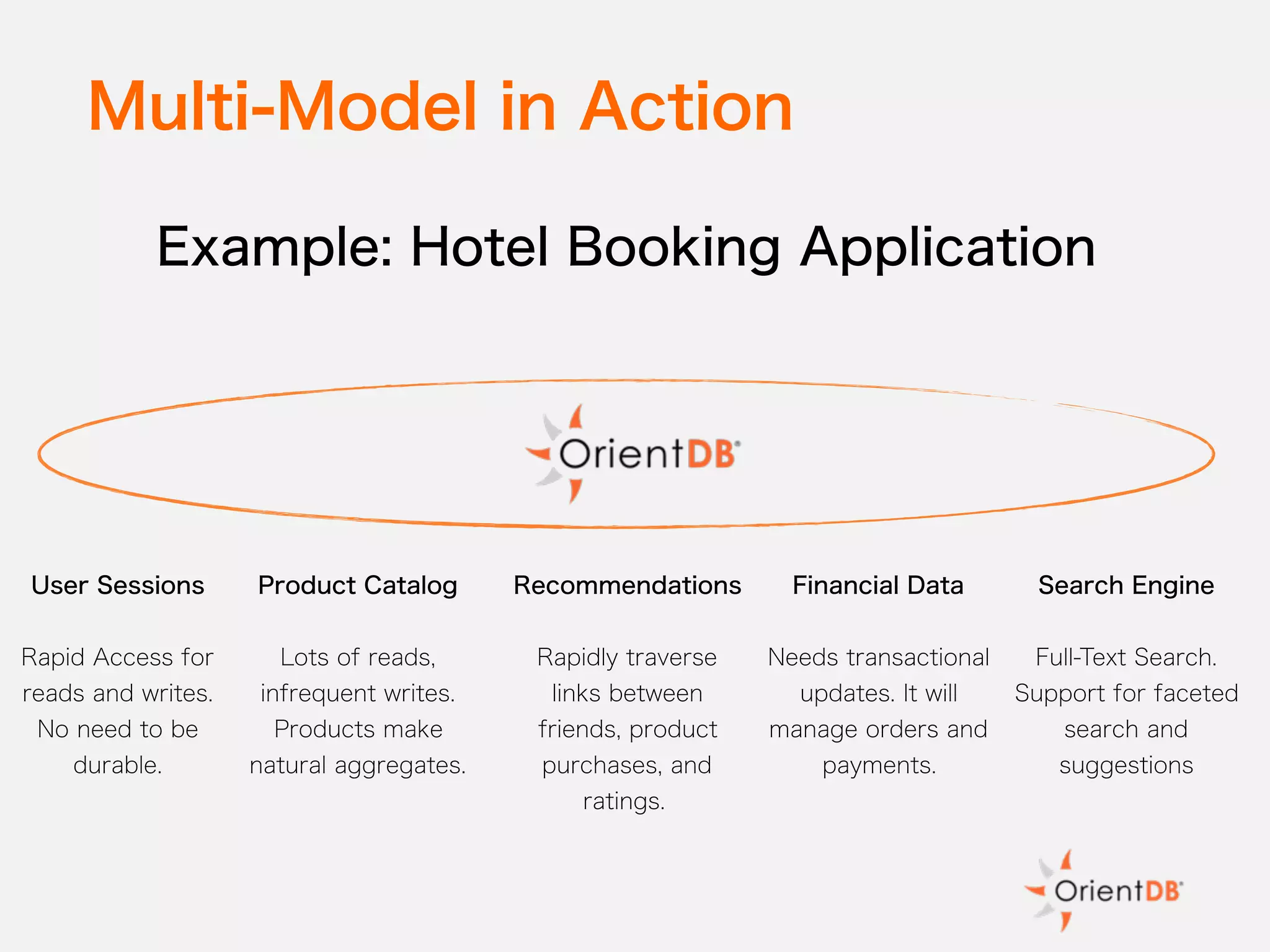
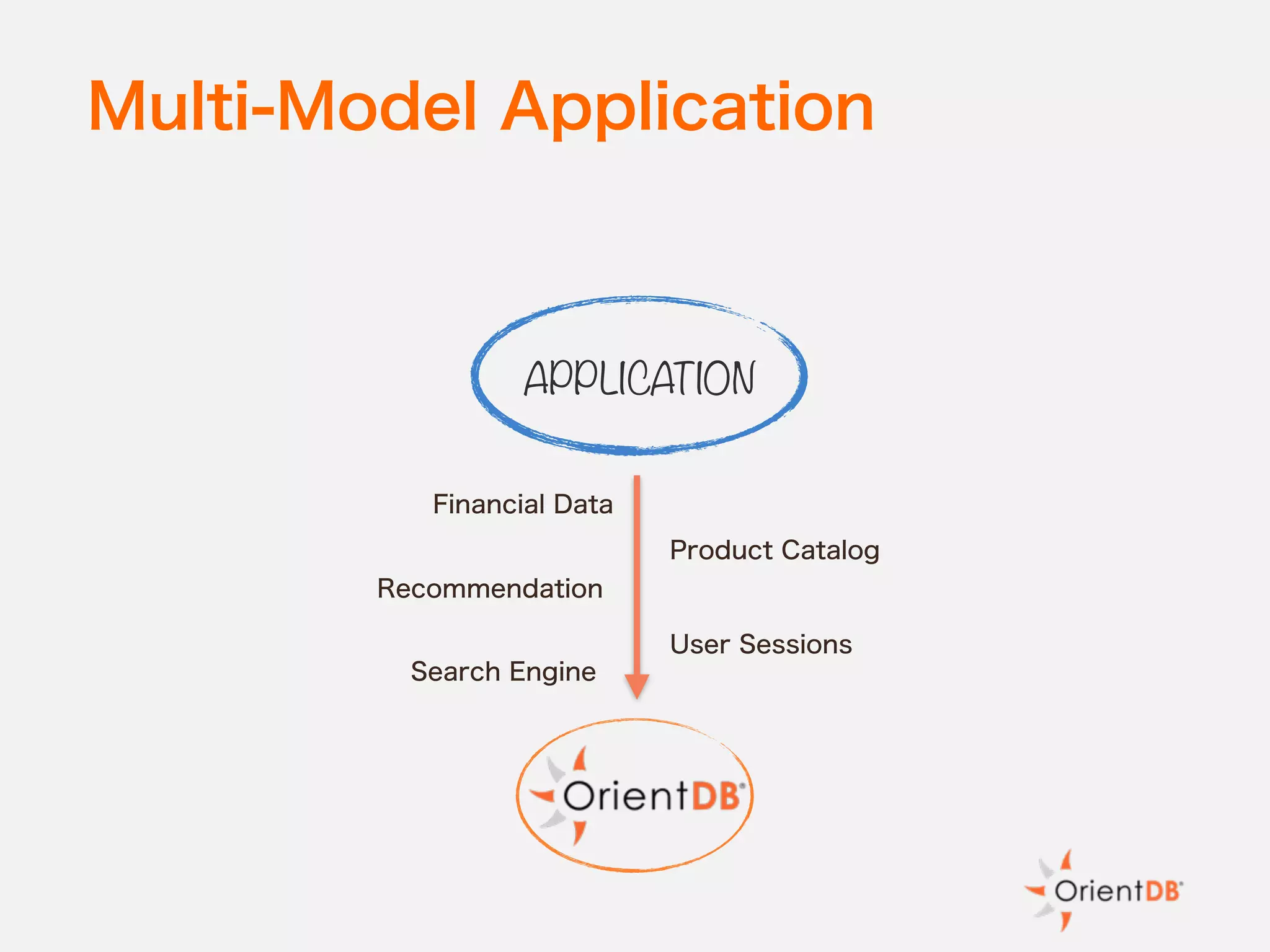
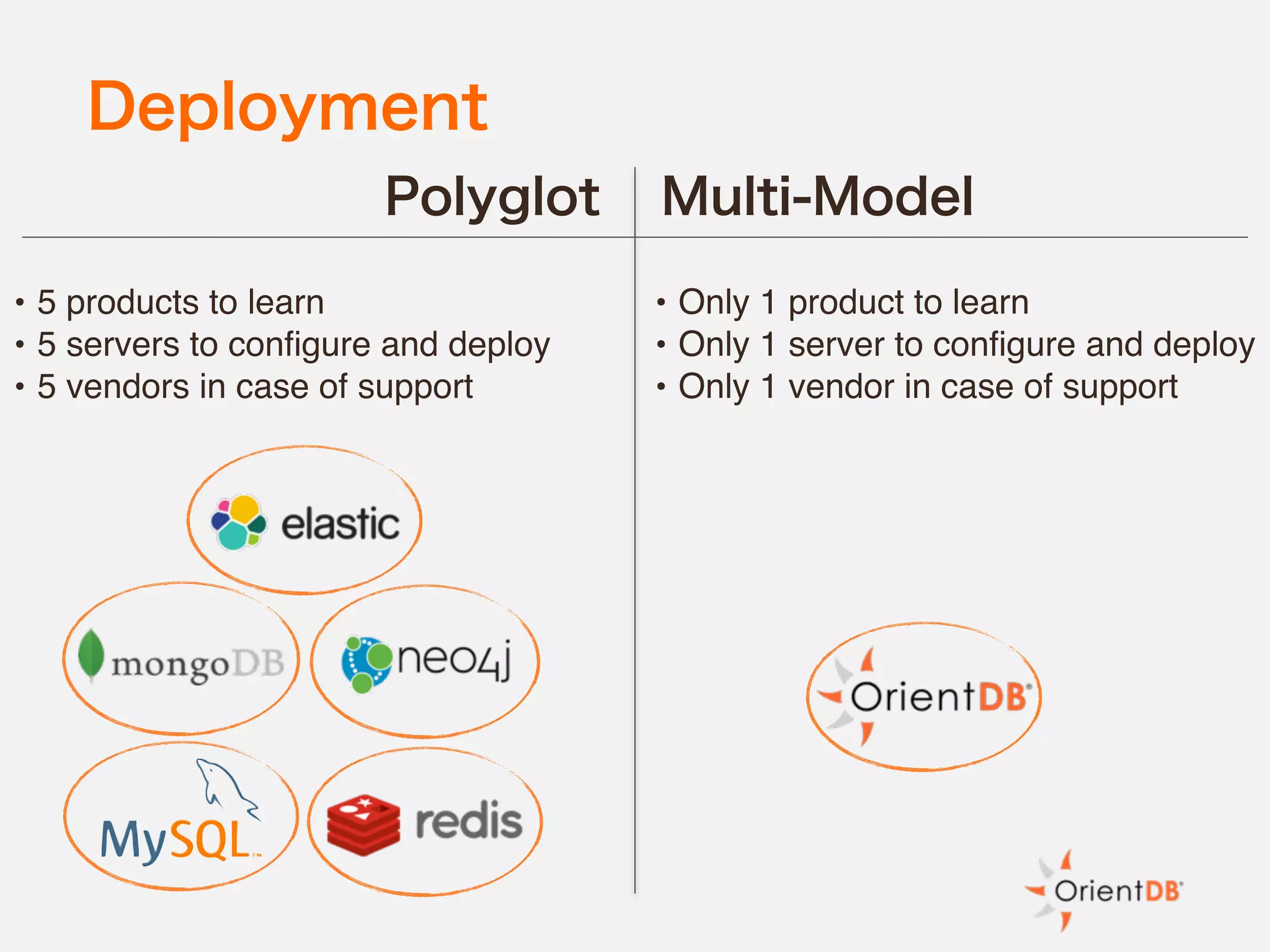


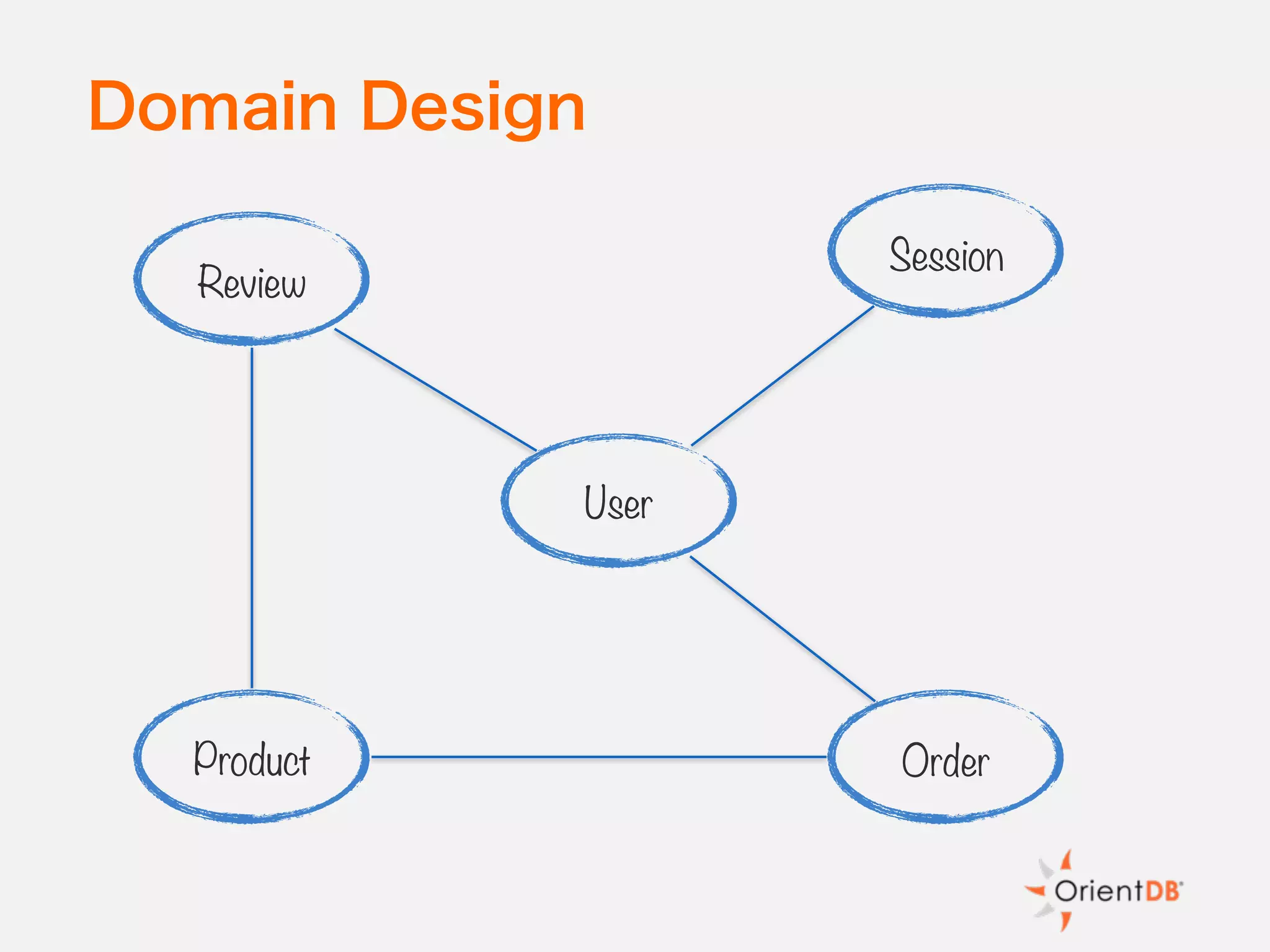
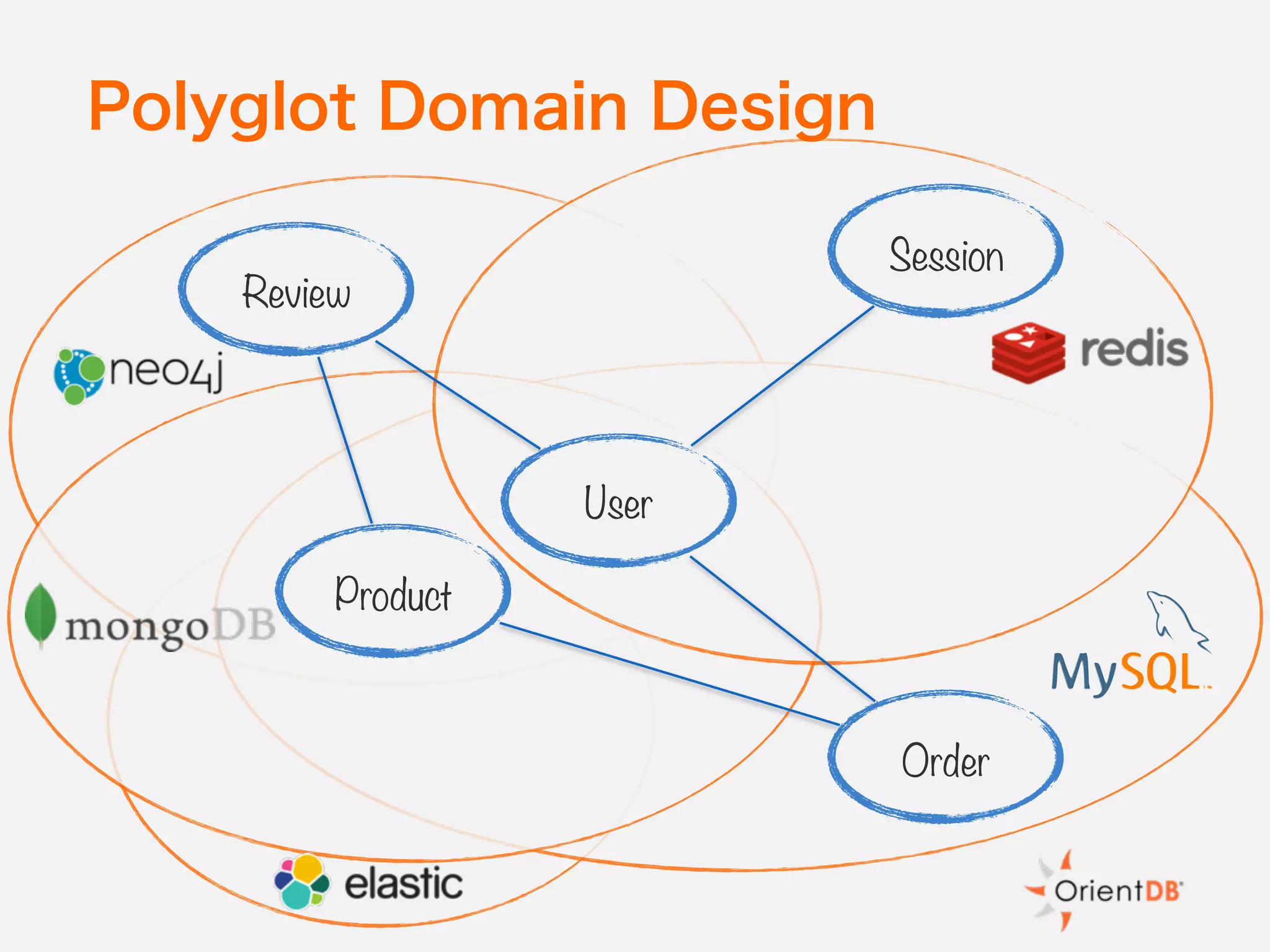
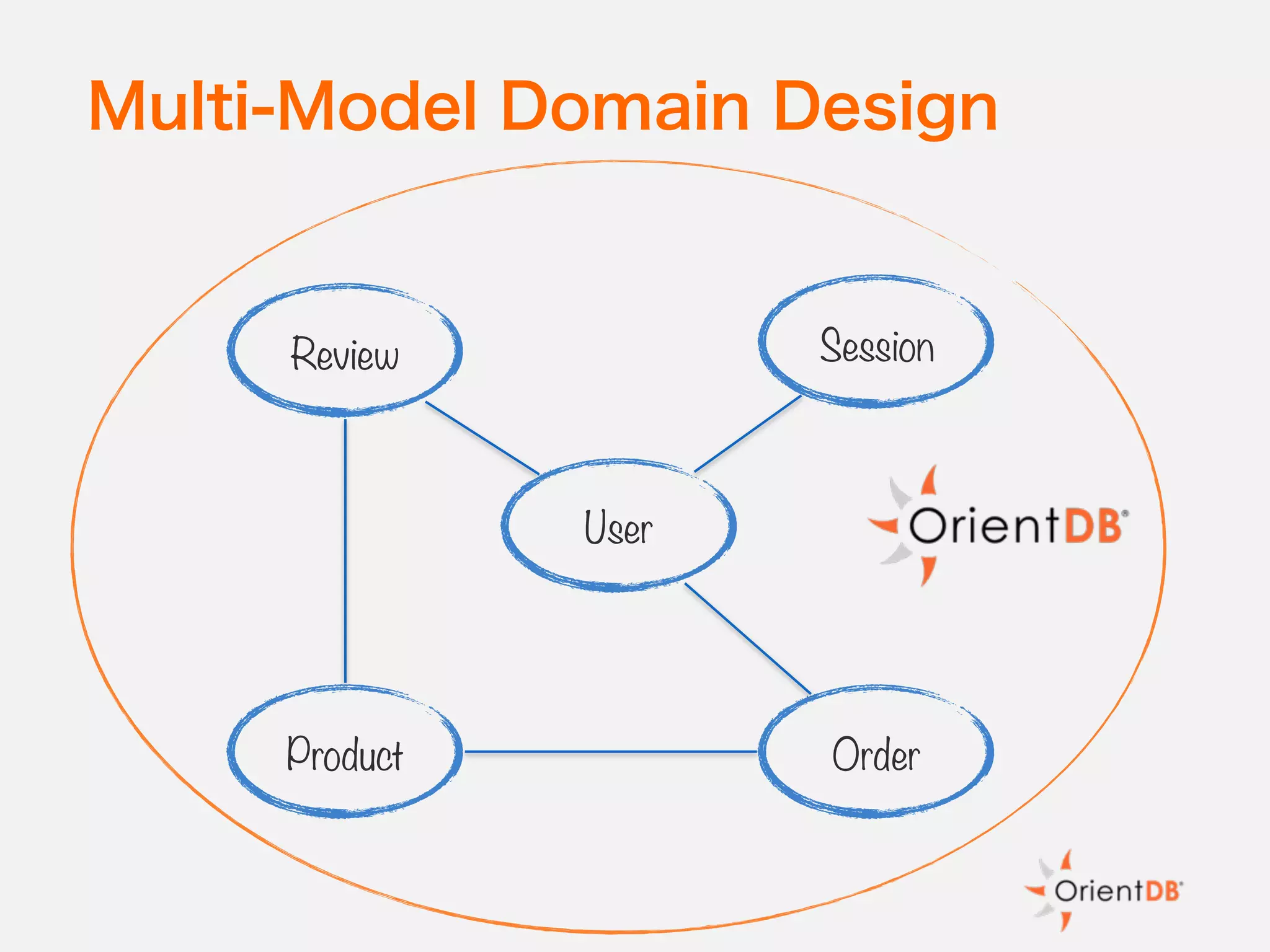
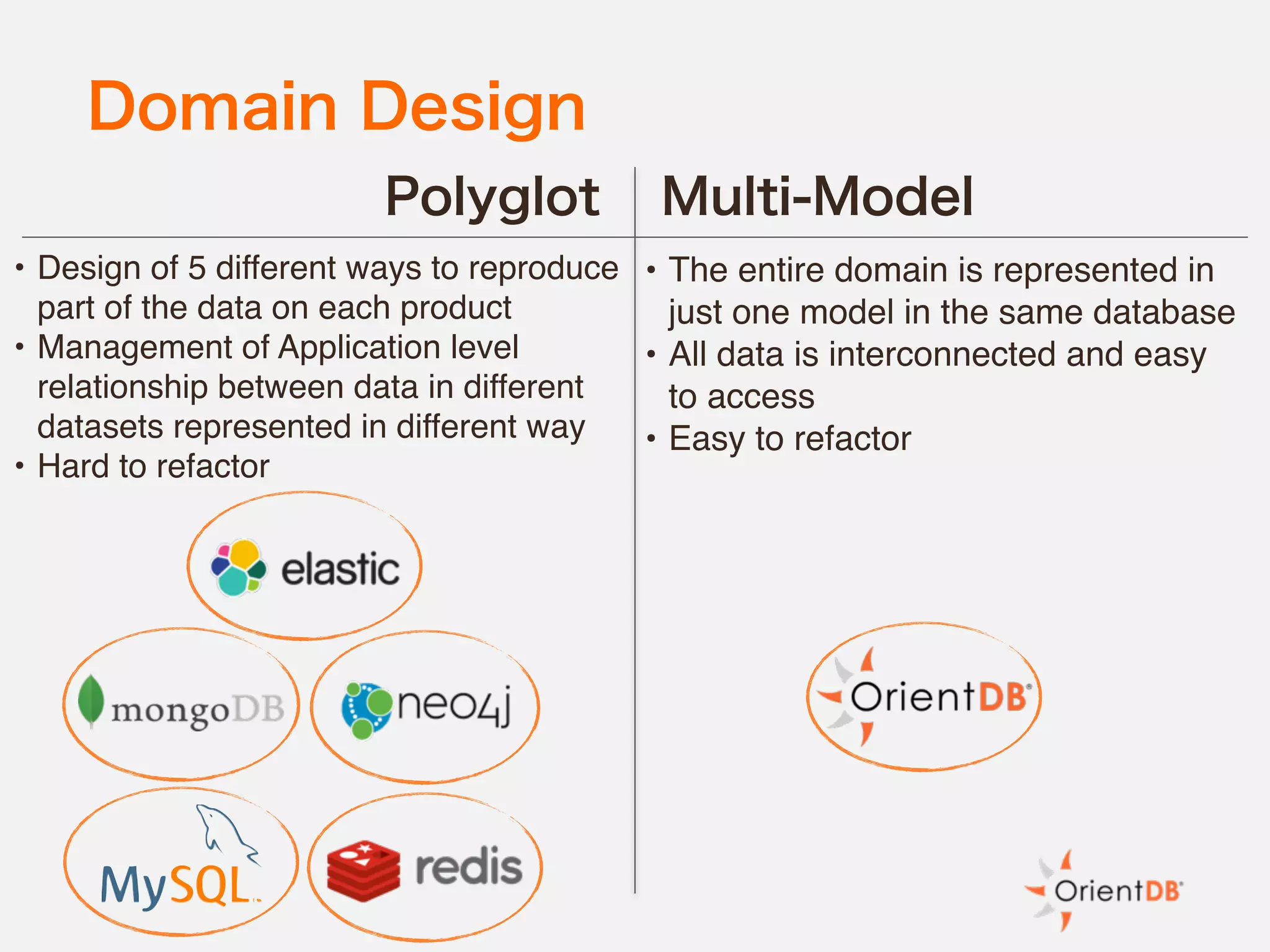

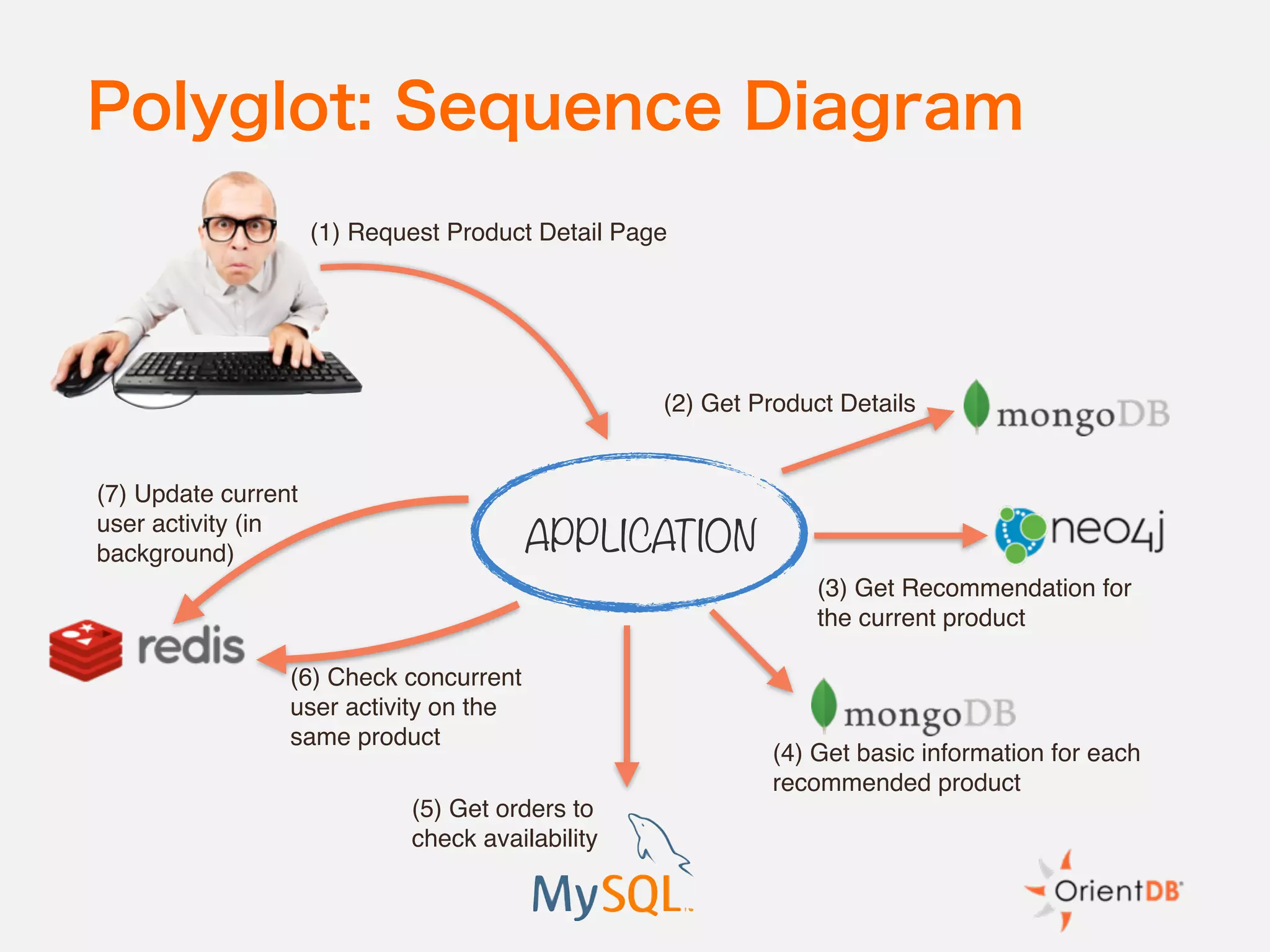
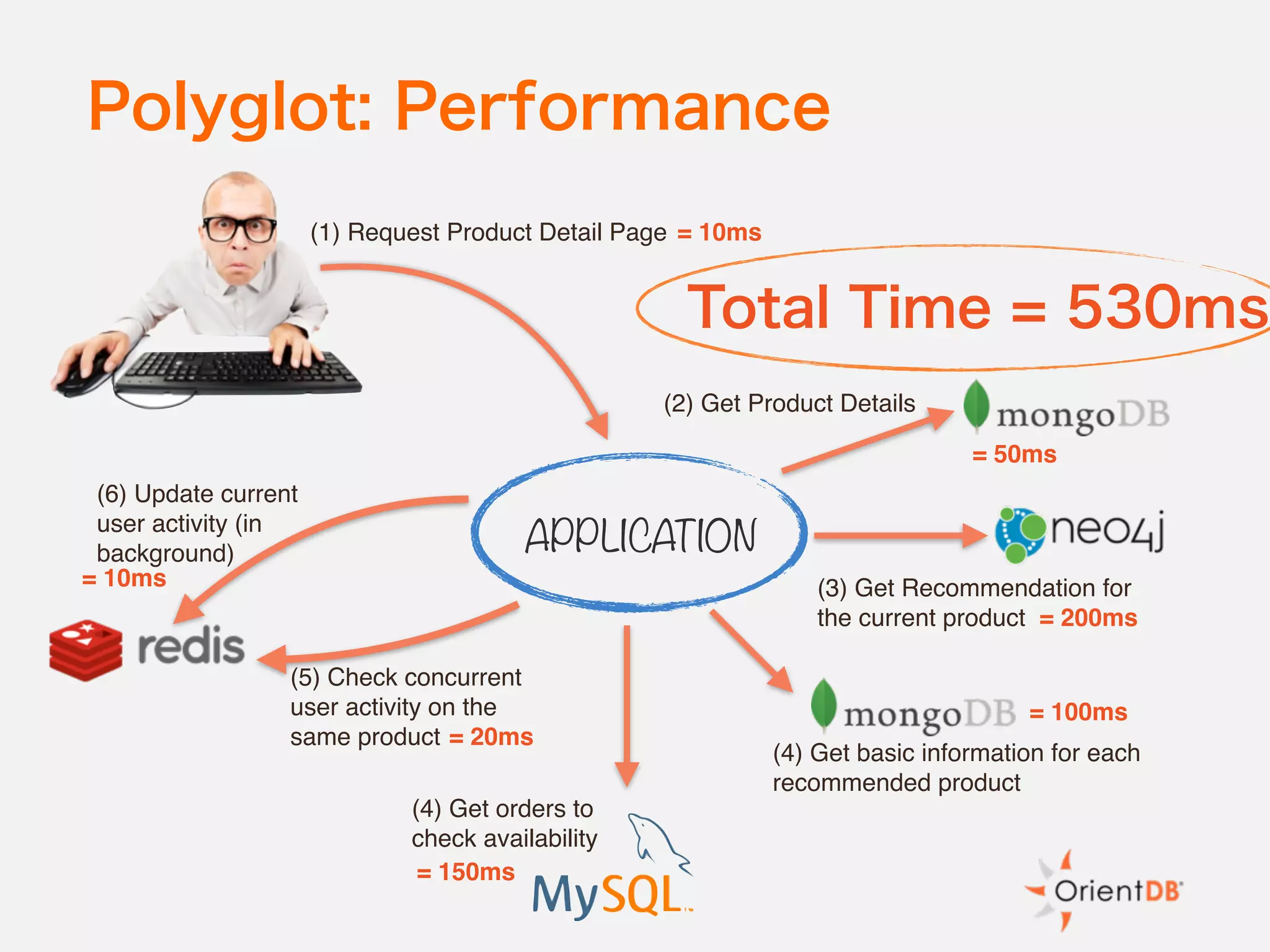



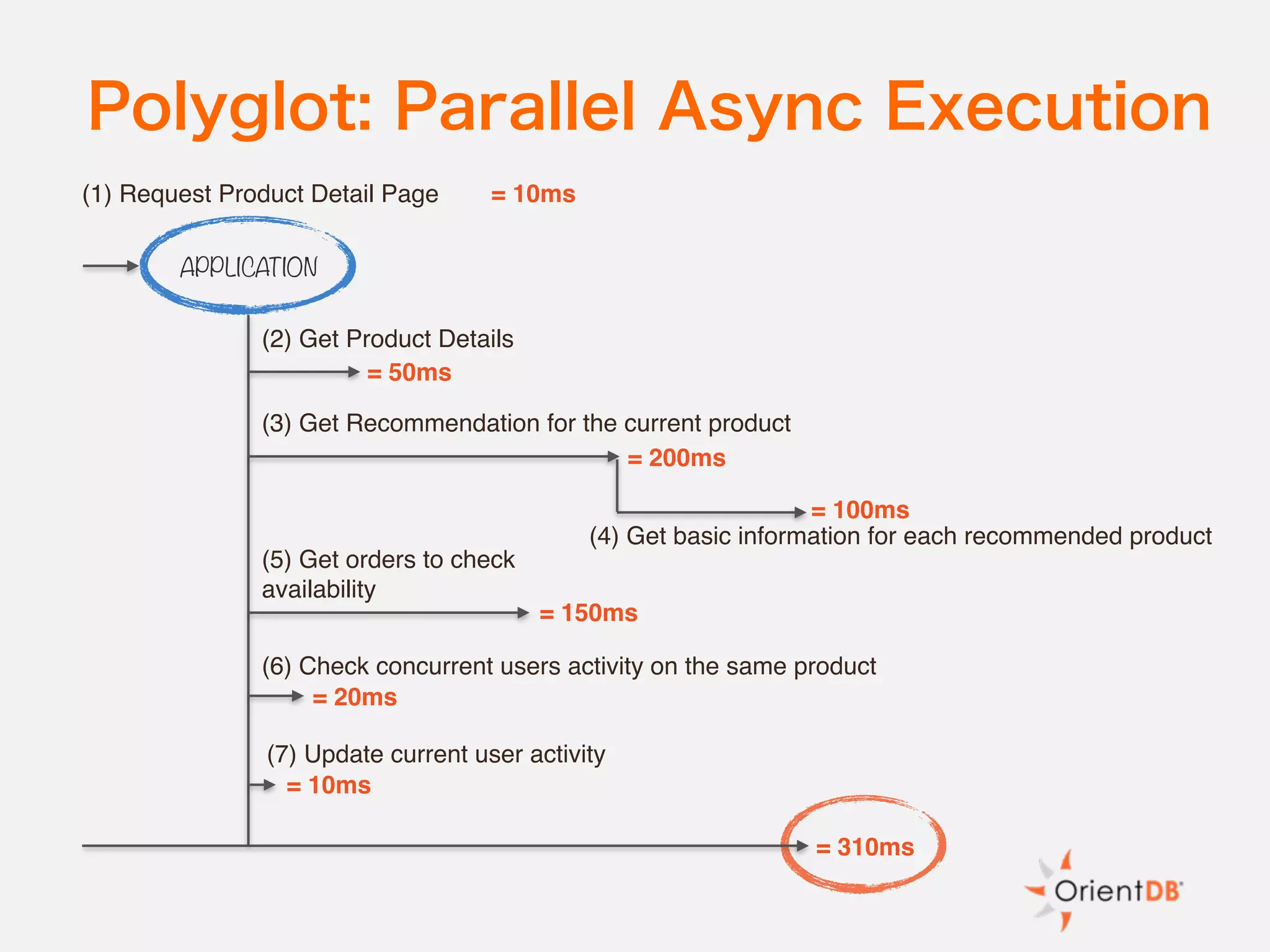





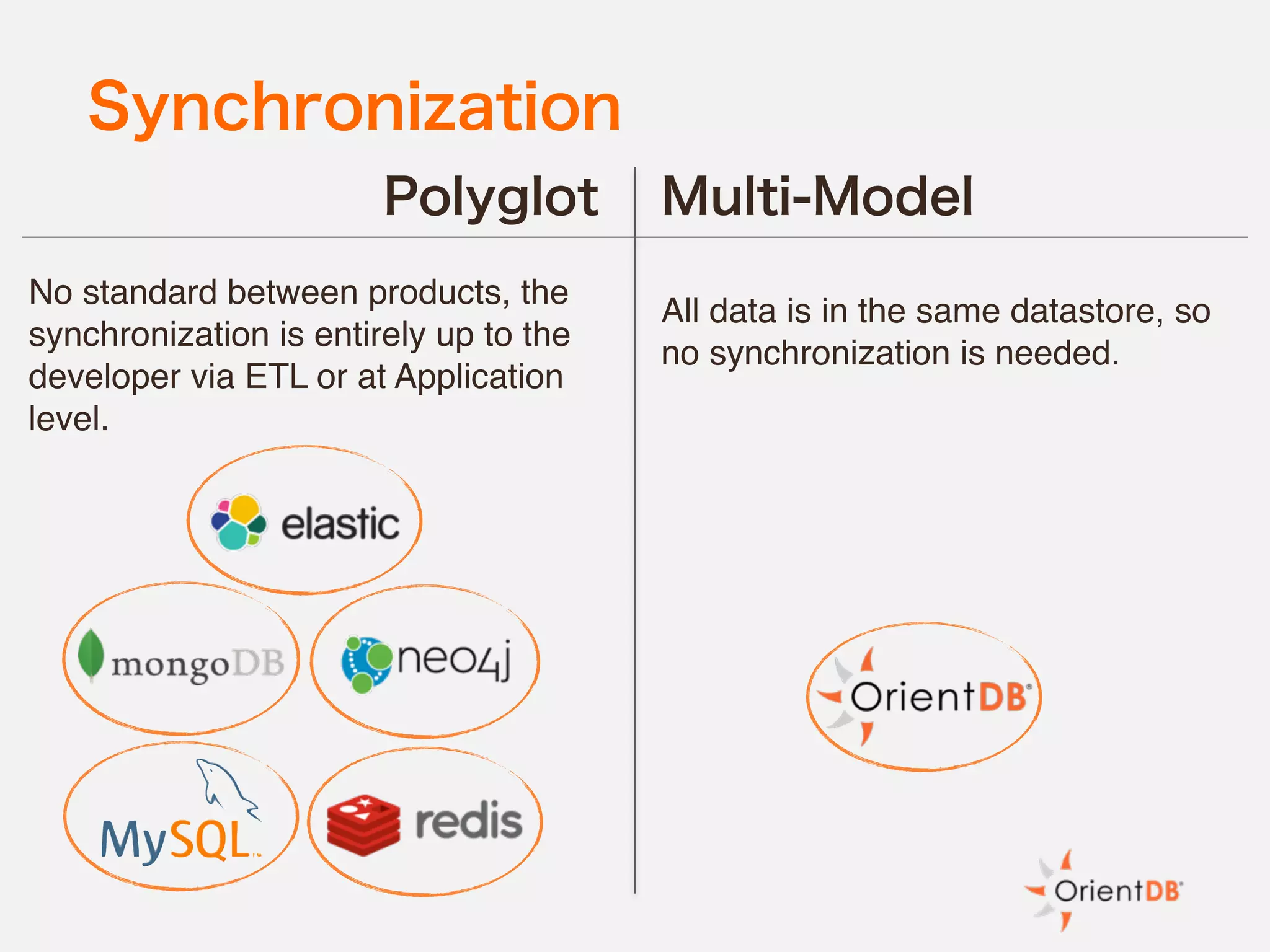

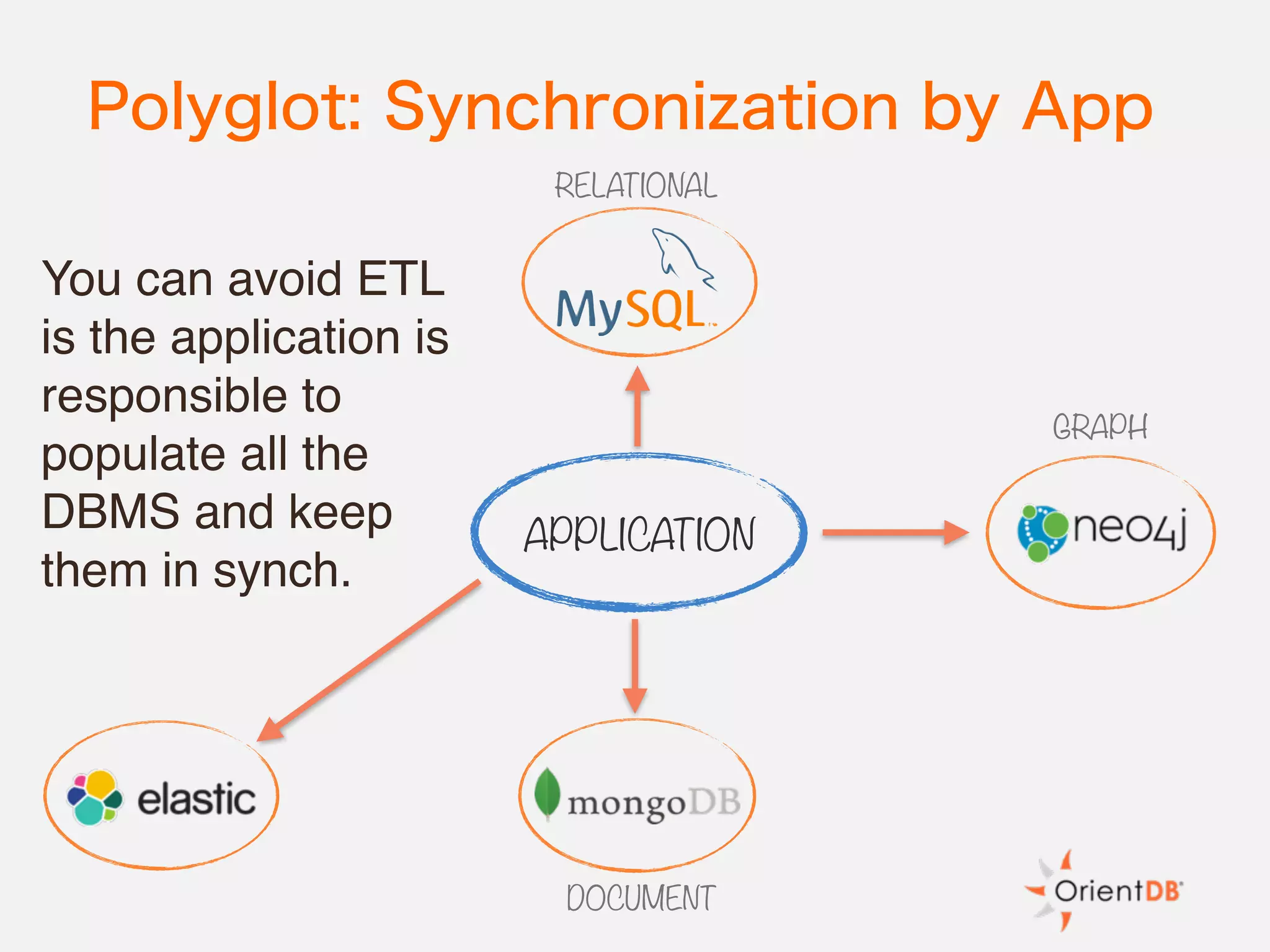


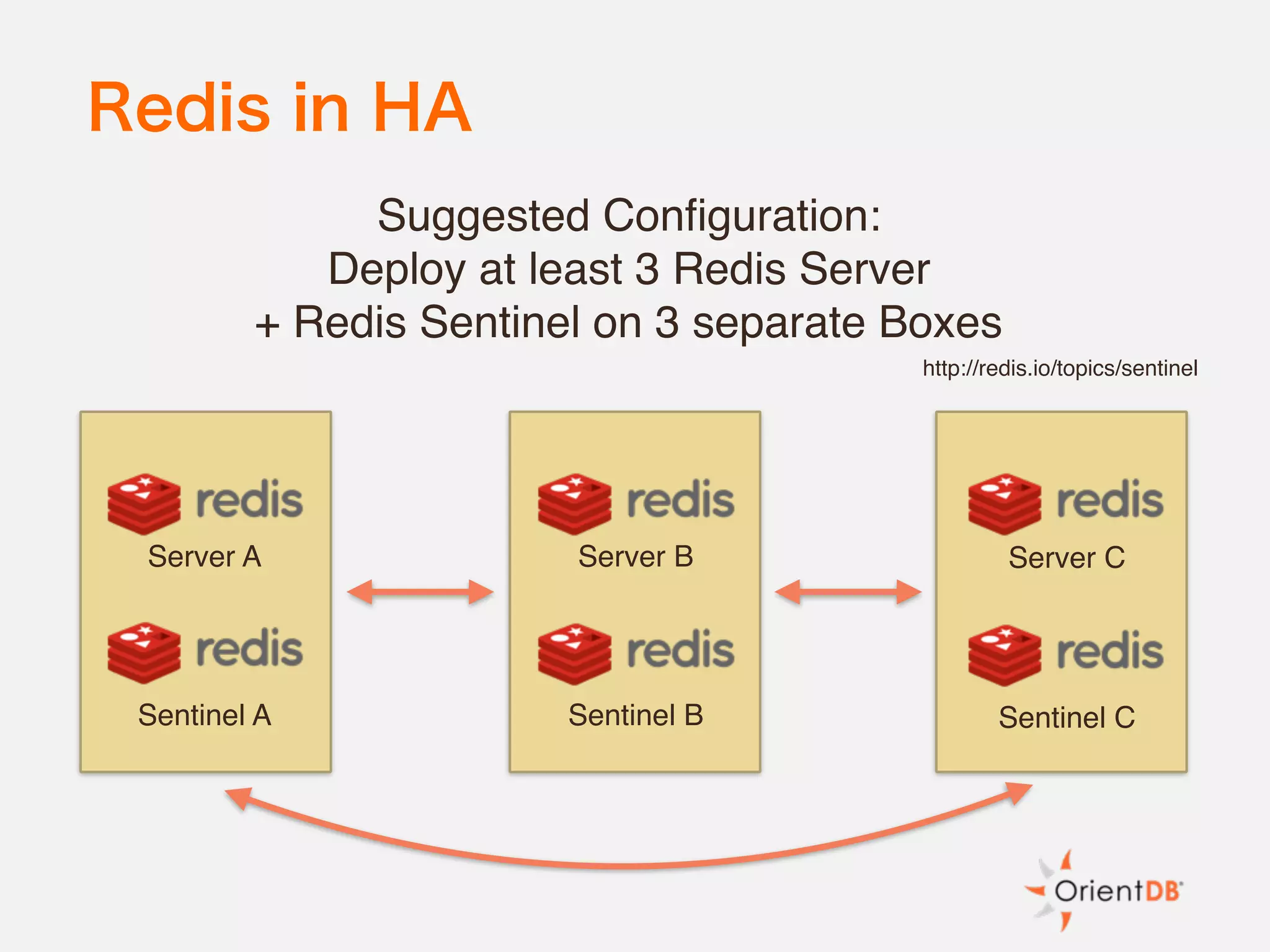
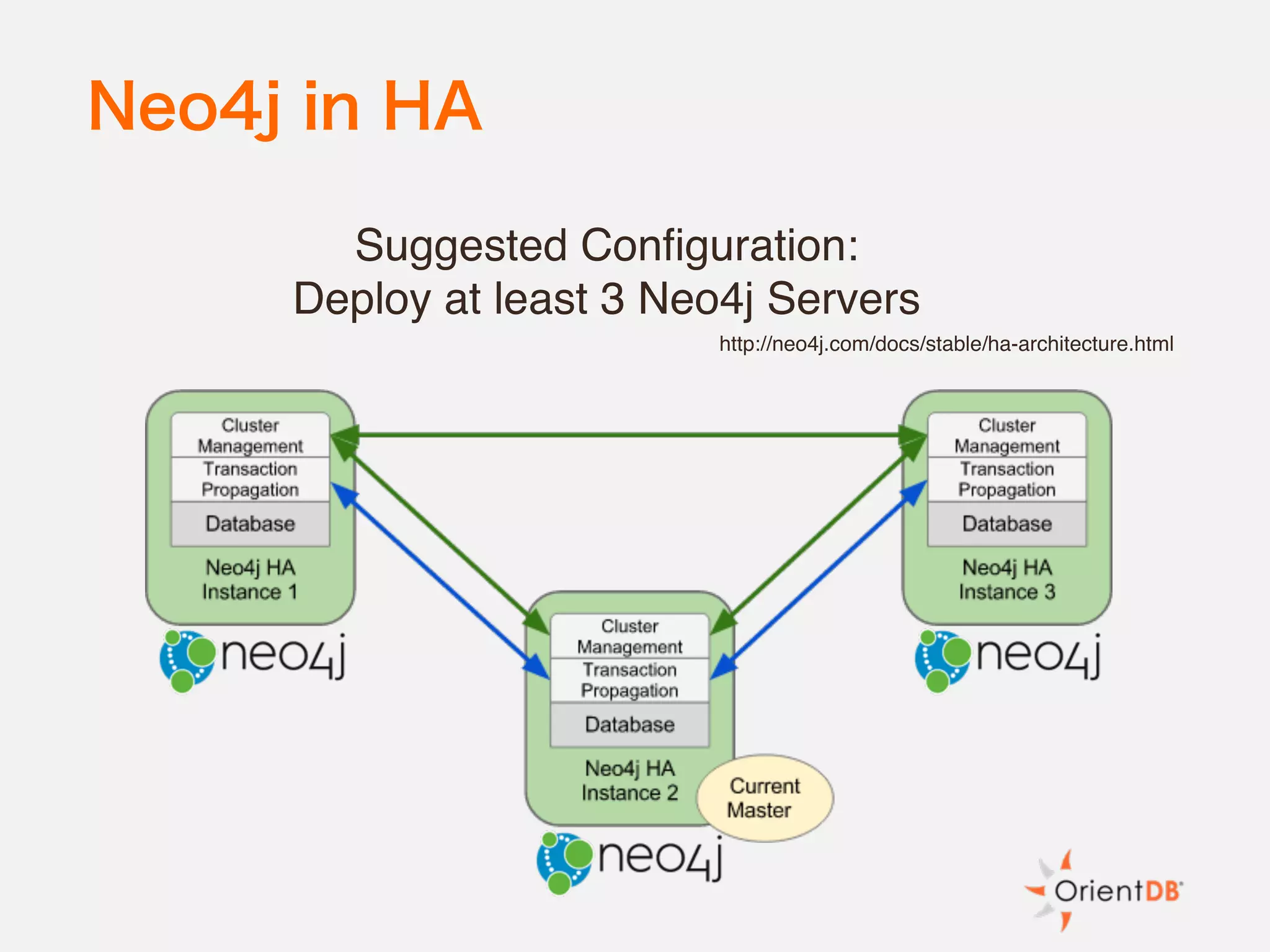
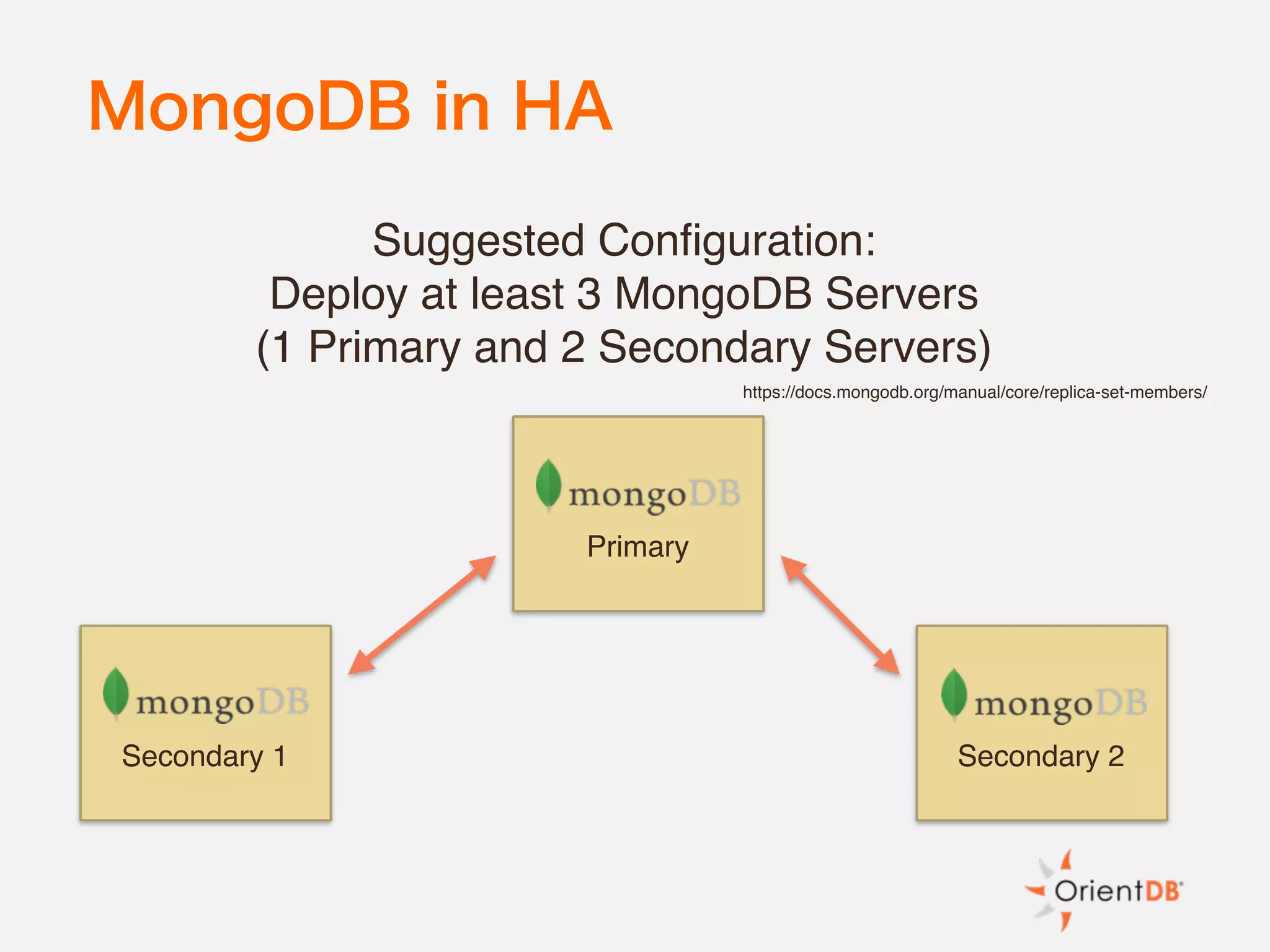

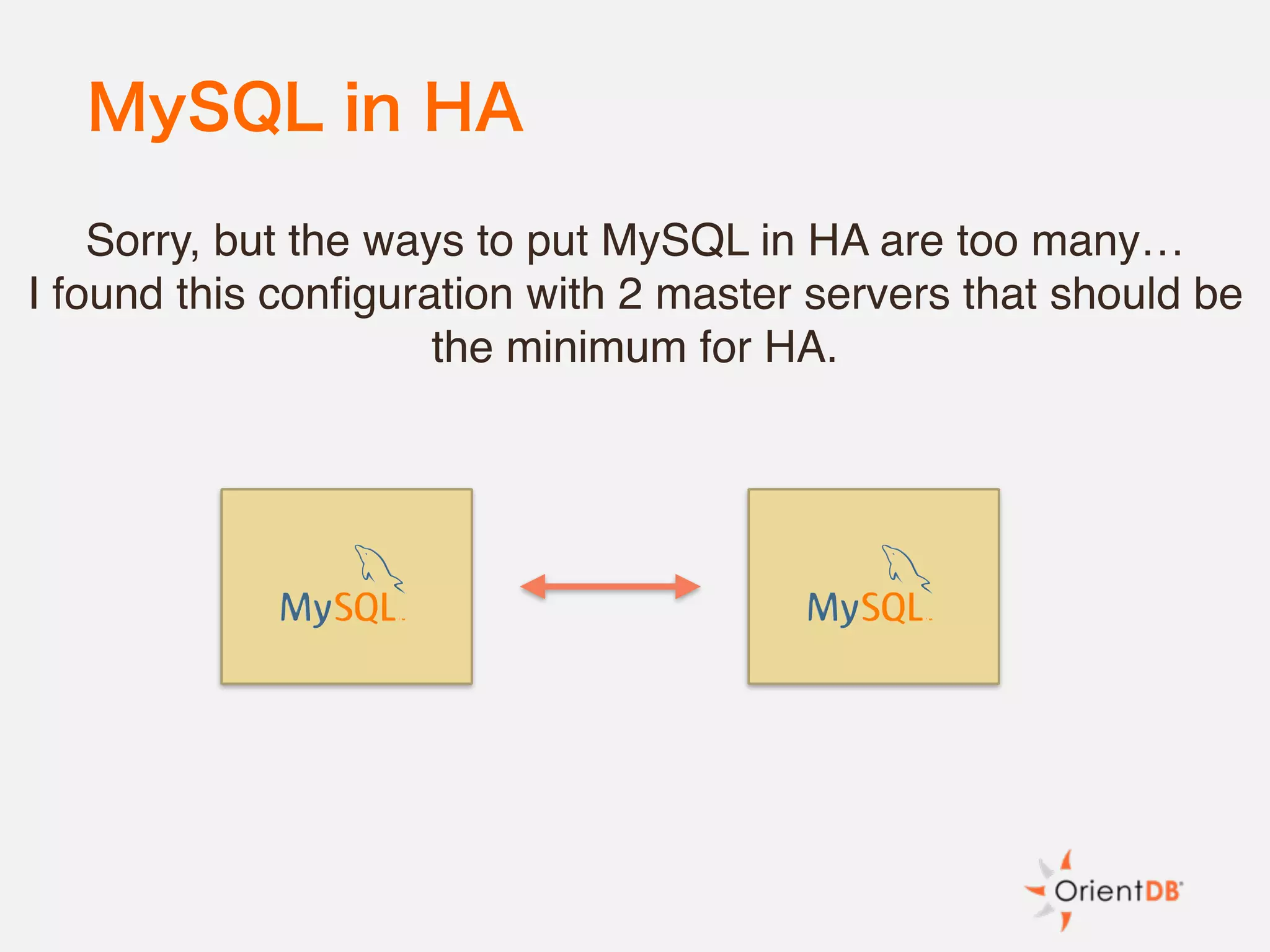
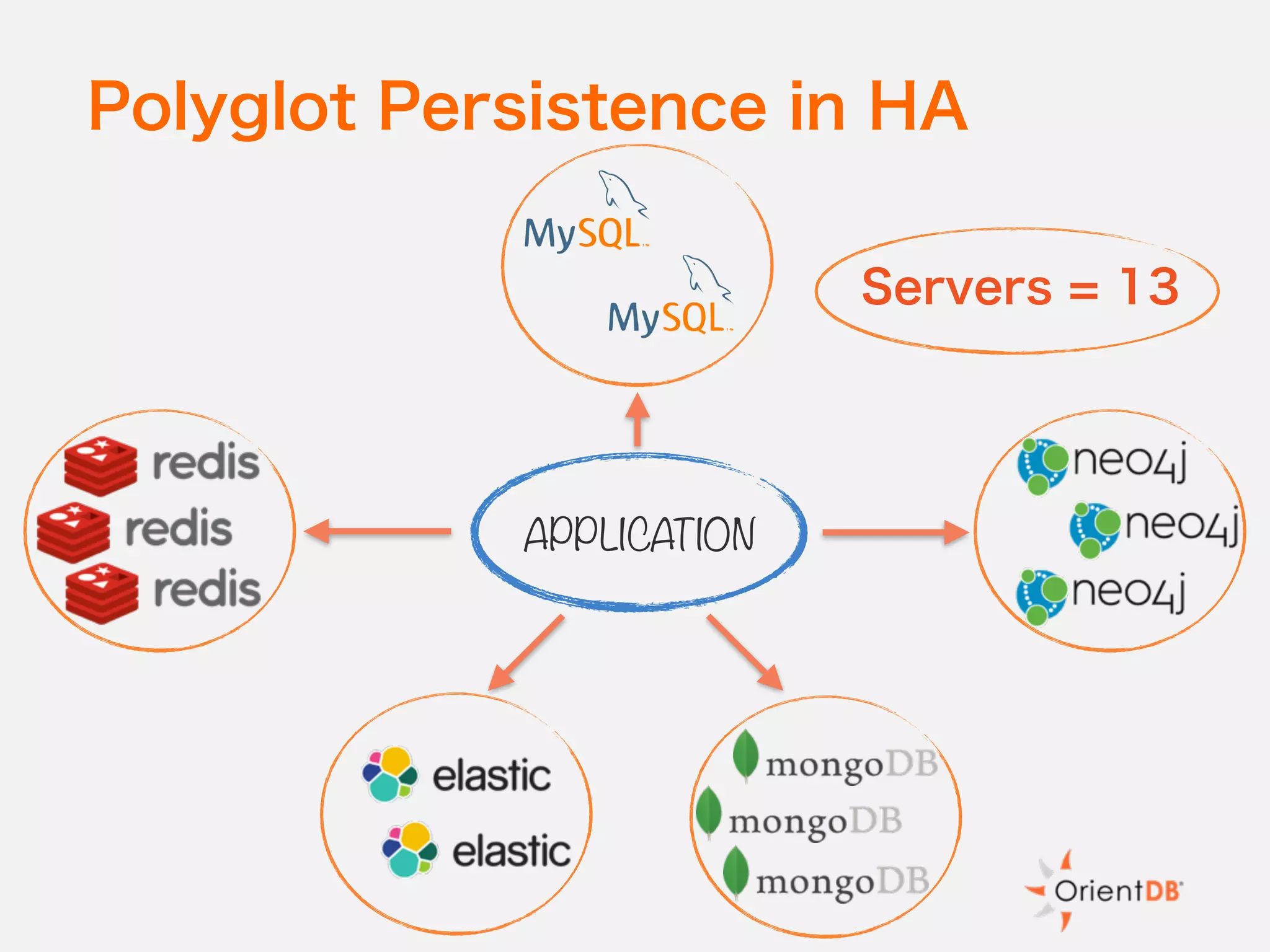


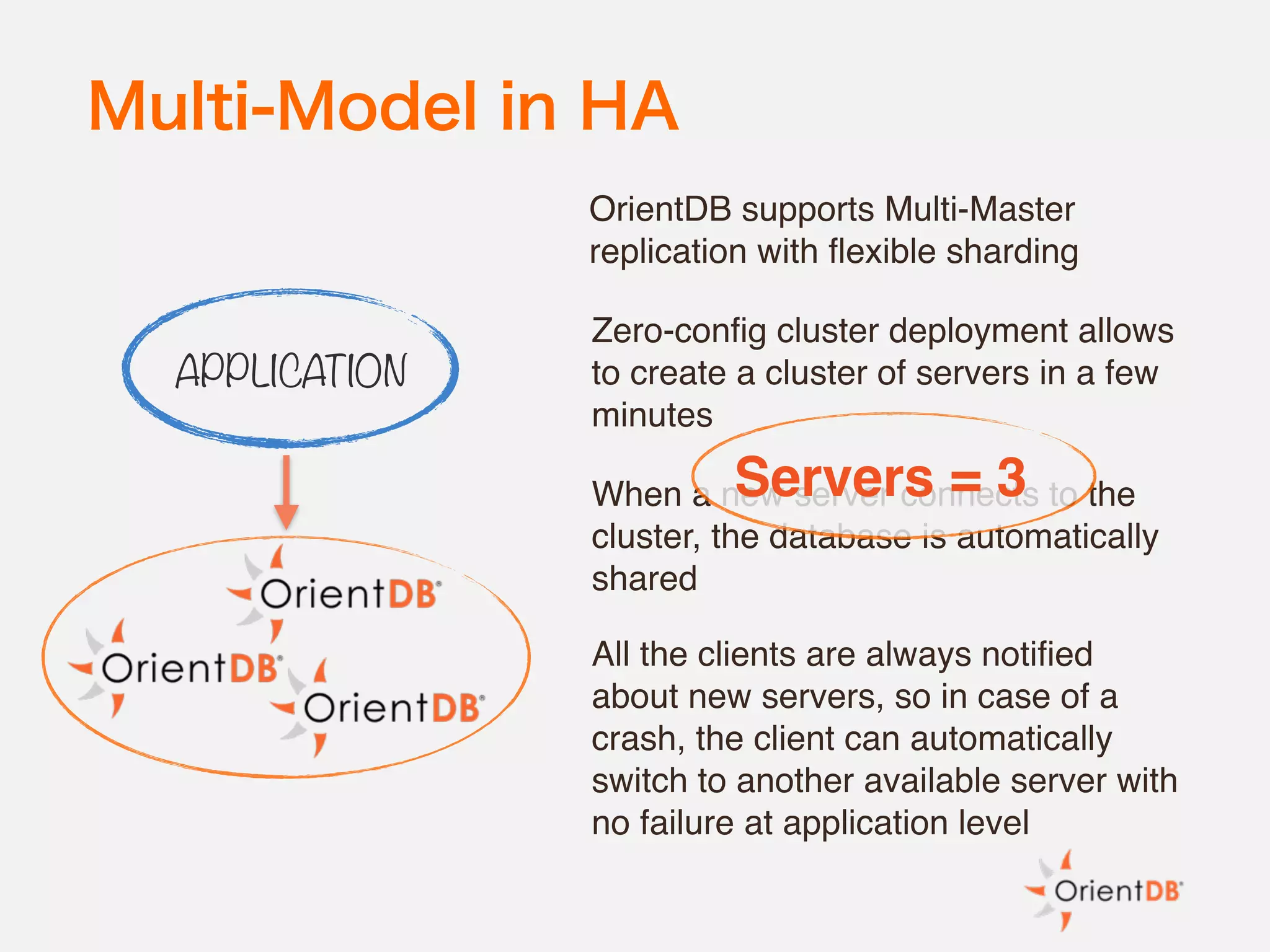

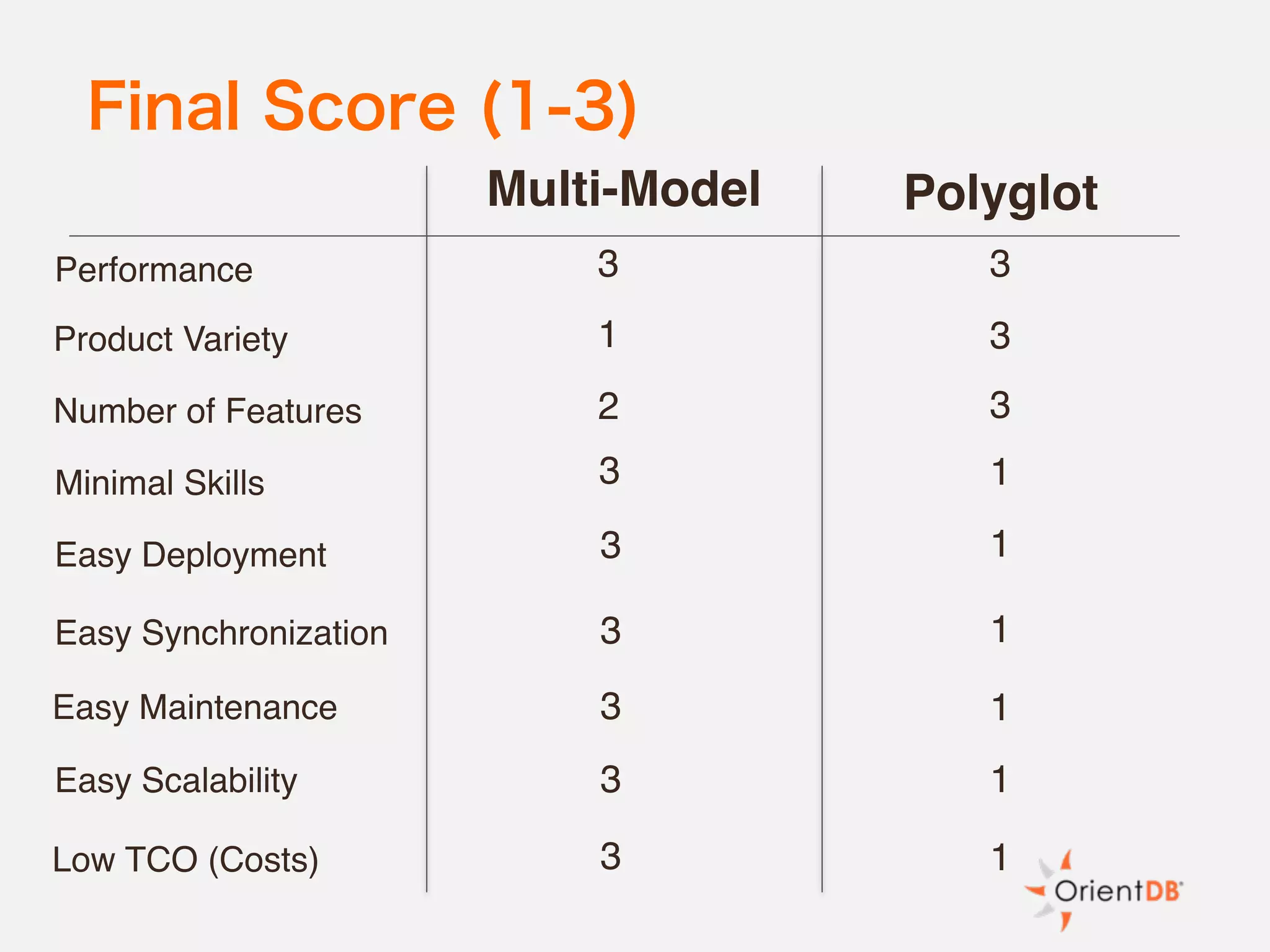
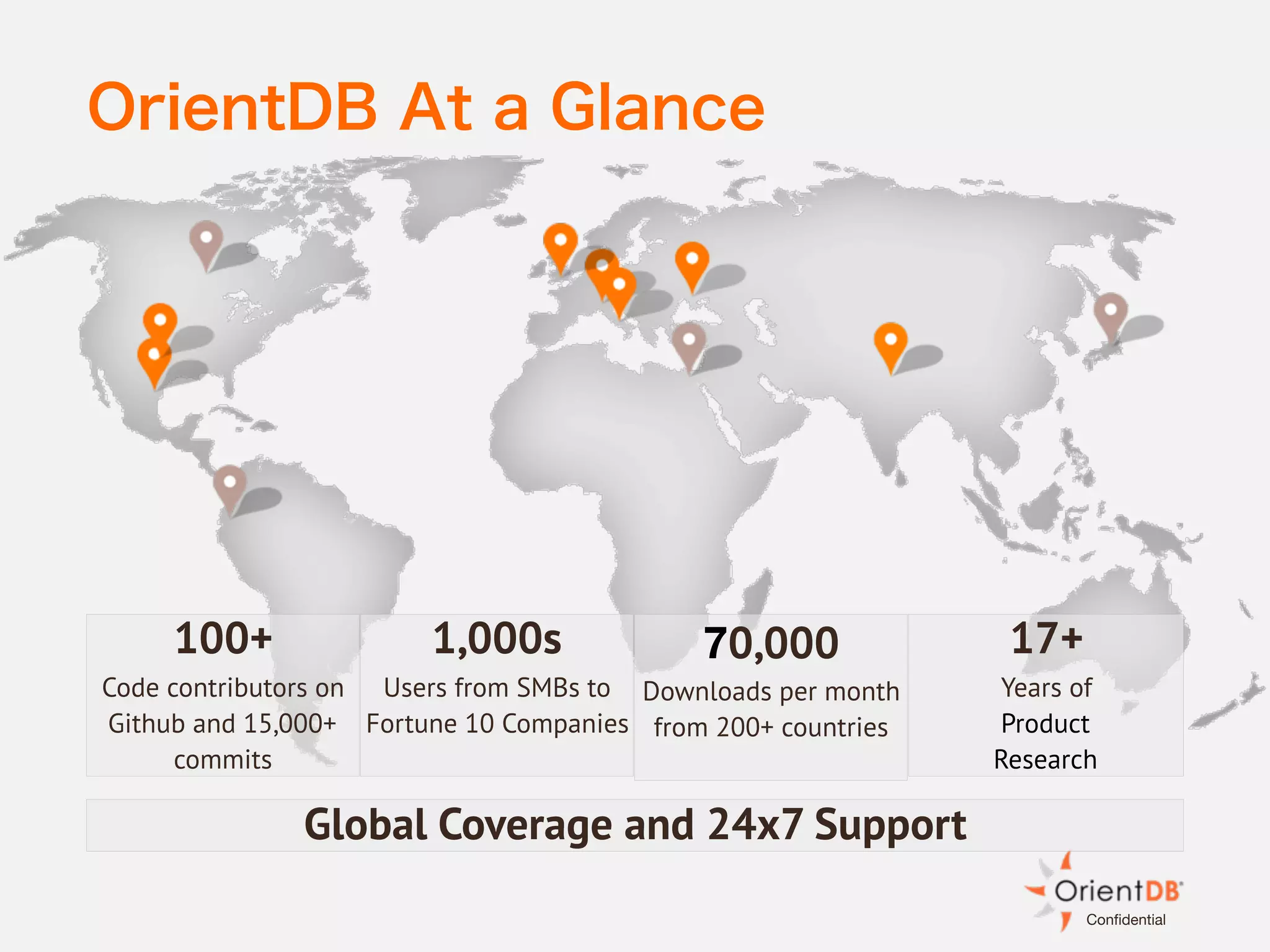

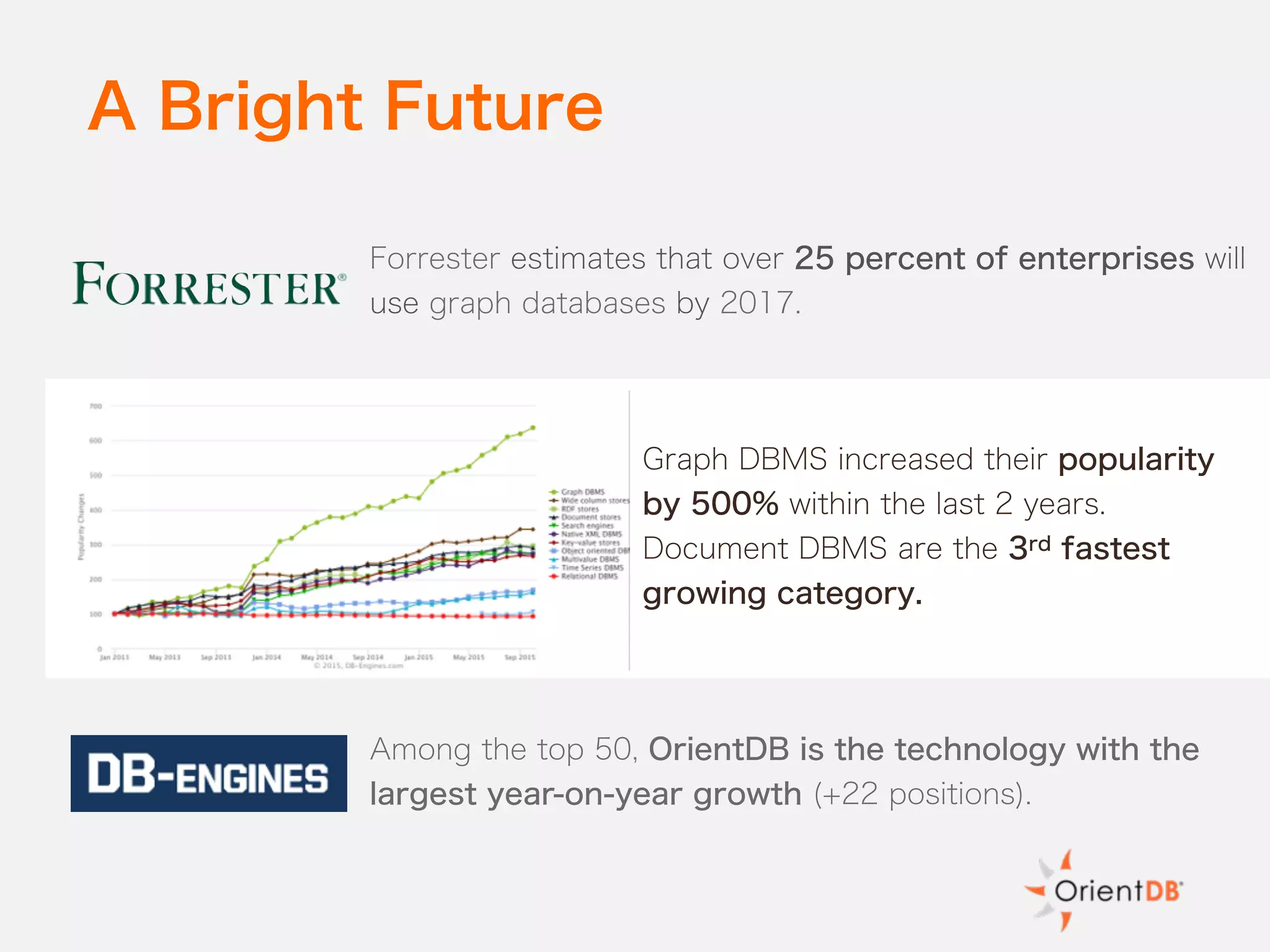



The document discusses the evolution and benefits of polyglot persistence and multi-model databases, emphasizing how these approaches allow the use of various data storage technologies tailored to specific application needs. Polyglot persistence offers developer freedom and flexibility, while multi-model databases streamline complexity by integrating multiple data models into a single backend. OrientDB is highlighted as a leading multi-model database that merges features of document and graph databases, promoting efficiency and ease of management.







































































































